1. 引言
我们将可对图像中的目标进行识别和定位的技术称之为目标检测,这些目标包括人物、动物以及日常生活中常见的物品。目标检测技术应用广泛,在建筑工地用于监视以确保安全施工,在工业零件的生产中可用于检测出瑕疵产品,在医疗场景中可进行辅助诊断,在汽车行业可用于自动驾驶。在现实生活中,由于光照、遮挡所造成的阴影、成像品质等诸多因素,使目标检测具有更大的挑战性 [1] 。
目标检测算法大概发展为两个阶段,第一个阶段为传统的目标检测算法,人为进行提取特征和指定分类器来实现目标检测。特征提取主要采用尺度不变特征变换SIFT [2] 、局部二值模式LBP [3] 和方向梯度直方图HOG [4] ,分类器一般选择支持向量机SVM [5] 与Adaboost [6] 算法来实现任务分类功能。但是,传统的目标检测存在以下缺陷:(1) 虽然思路简洁,但实则计算开销巨大;(2) 图像语义信息非常复杂,人工提取难以获得,导致特征表达能力不足,不同任务之间鲁棒性较差 [7] 。
第二个阶段为基于深度学习的目标检测算法。随着卷积神经网络快速发展,人们提出用卷积神经网络提取图像特征 [8] ,对比传统的目标检测算法,基于深度学习的目标检测算法不仅漏检率和错误率低,检测精度还更高。现在,基于深度学习的目标检测算法主要分为两大类别。一类是双阶段目标检测,将候选框提取和分类顺序进行,先使用RPN [9] 提取目标的候选框,再对区域位置校准后进行分类得到最终的检测结果。由于这种目标检测网络分两步执行,注重高准确率,复杂的结构导致检测速度较慢,其中典型代表有第一次将候选区与卷积神经网络相结合的R-CNN [10] 、基于R-CNN改进,添加金字塔池化层的SPPNet [11] 等;另一类是单阶段目标检测,其抛弃了生成候选区域的阶段,将目标检测当作回归问题来解决,经过单次检测即可产生类别概率和位置坐标。由于这种目标检测网络在结构设计上进行简化,更加注重实时性,导致检测精度较低 [12] ,其中典型代表有YOLO [13] [14] [15] [16] 和Retina-Net [17] 等。
本文针对在YOLOv5s的基础上进行了研究和改进,提出了特征重构模块,减少特征损失,提高特征信息的利用率,并将特征重构模块移入YOLOv5s网络中,使用特征模块,保留更多的特征信息,提高了检测的准确率。
2. 相关工作
古人云:“知秋一叶,尝鼎一脔”,其中就蕴含着采样的思想。采样,顾名思义,就是从特定的概率分布中抽取相应样本点的过程。而在深度学习中,它可以将复杂的分布简化为离散的样本点,用于对样本集进行调整以更好的适应后期的模型学习。采样又可以分成下采样和上采样。
在卷积神经网络中,由于输入图像通过卷积神经网络(CNN)提取特征后,输出的尺寸往往会变小,而有时我们需要将图像恢复到原来的尺寸以便进行进一步的计算(如图像的语义分割),这个使图像由小分辨率映射到大分辨率的操作,叫做上采样。下采样就是指的是成比例缩小特征图宽和高的过程,比如从(W, H)变为(W/2, H/2),即对卷积得到的Feature Map进行进一步压缩。下采样的作用有很多,包括:降低维度、减少网络要学习的参数数量、防止过拟合、增大感受野,使得后面的卷积核能够学到更加全局的信息。
池化操作是最早接触到的下采样方式。其中平均池化和最大池化两种池化方式最为常见。平均池化有种平滑滤波的味道,通过求取滑窗内的元素平均值作为当前特征点,根据滑窗的尺寸控制下采样的力度,尺寸越大采样率越高,但是边缘信息损失越大。最大池化类似锐化滤波,突出滑窗内的细节点。但是不论哪种池化操作,都是以牺牲部分信息为代价,换取数据量的减少。
步长大于1的卷积也可以实现下采样的作用。卷积操作可以获得图像像素之间的特征相关性,采用步长大于1的跳跃可以实现数据降维,但是跳跃采样造成的相邻像素点特征丢失可能影响最终效果。卷积实现的下采样和池化相比,池化操作提供了一种非线性,这种非线性需要较深的卷积叠加才能实现,因此当网络比较浅的时候,池化有一定优势;但是当网络很深的时候,多层叠加的卷积可以学到池化所能提供的非线性,甚至能根据训练集学到比池化更好的非线性,因此当网络比较深的时候,不使用池化没多大关系,甚至更好。另外,池化下采样比较粗暴,可能将有用的信息滤除掉,而卷积下采样过程控制了步进大小,信息融合比较好,现在池化操作大部分被卷积所替代。
在老版本的YOLOv5中,也出现过一种结构叫做Focus。Focus模块采用切片操作把高分辨率的图片(特征图)拆分成多个低分辨率的图片(特征图),即隔列采样 + 拼接,再经过一次1 × 1卷积操作,用来改变通道数,最终图片尺寸下降一半,通道数变为卷积后的输出通道数。原作者设计Focus的目的是减少参数量,并增加计算速度,并不会提升目标检测模型精度。
3. 模型
3.1. YOLOv5s网络
本文在YOLOv5s网络基础上改进。YOLOv5s的网络结构分为Backbone、Neck、Head,如图1所示。
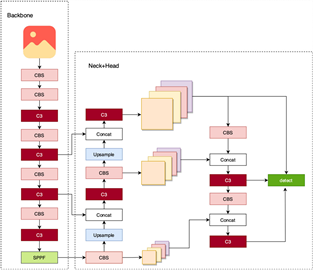
Figure 1. YOLOv5s network architecture
图1. YOLOv5s网络结构
Backbone由CBS、C3以及SPPF构成,通过五次CBS提取输入的图像特征,每次卷积后利用C3模块进行特征堆叠加深网络,并在Backbone末尾添加SPPF模块进行池化特征。
CBS卷积模块由Conv卷积、Batch Norm标准化和Silu激活函数组成,主要作用是增加模型的非线性拟合能力。
C3模块一共包含三次CBS卷积与若干次Bottle Neck,借鉴ResNet残差网络思想,将输入特征层拆分为两部分处理。主干部分利用CBS与Bottle Neck逐步提取层内特征,加深网络并增加网络的感受野,分支部分仅用单次CBS调整空间分辨率,最后再由第三个CBS提取Concat后的新特征层。
在SPPF模块中,特征图串行通过一个CBS和三个5x5池化层,用Concat模块堆叠前面四个结果后再经过一个CBS层处理,将同一特征图不同尺度下的特征融合到一起,丰富特征图的语义特征。
Neck部分采用了FPN [18] 与PAN [19] 结构来进行融合,PAN结构中采用自底向上和从上到下的两条路径上的特征融合。自底向上的路径为通过CBS卷积和上采样,由20 × 20的深层次特征通过Concat进行堆叠至40 × 40、80 × 80的中低层次特征。从上到下的路径则相反,将低层次特征通过CBS卷积进行提取并下采样到中高层次特征,再利用C3层将Concat堆叠后的特征进行特征融合,使深层次的语义特征与浅层次的位置信息特征相互补充,提高模型的特征表达能力。
Head部分根据Neck的三种不同尺度的特征图将图片划分成不同的网格尺度,在每个网格中设置不同宽高比和不同大小的三个Anchor (先验框)来检测目标物,一共聚类得到9个不同尺寸的先验框。由于分辨率最低的特征图由深层网络卷积得来,局部感受野最大,适合大物体检测,分辨率中等的特征图适合检测中等大小物体,相反的,分辨率最高的特征图是由浅层网络卷积得来,其感受野最小,因而比较适合小物体检测,最后根据位置信息调整Anchor宽高比,生成真实检测框。
3.2. F-YOLOv5s网络
YOLOv5s目标检测模型遵循近几年下采样的方式,采用了步长大于1的卷积的形式进行下采样。Backbone中有5个单独的CBS模块,代表下采样了五次,设计在3个不同尺度的特征图上来进行物体检测,取下采样倍数分别为32倍、16倍和8倍的输出张量输入到FPN结构中,采取上采样的形式进行特征融合,之后再进入到PAN结构,采取下采样的形式进行增强特征融合。
虽然步长大于1的卷积操作比池化操作的带来的信息损失要小,但面对大物体时,感受野最大的依然可能会丢失高级语义信息,面对小物体时,下采样最小的输出尺度也可能丧失强定位特征。因此,为了获取更加全面的更加丰富的特征信息,本文借鉴Focus的思想提出了特征重构(Feature_Reconstruction)模块,它是一种特殊的下采样方式,如图2所示,将4 × 4 × 3的Tensor通过间隔采样拆分成4分,在通道维度上拼接生成2 × 2 × 2的Tensor,这样宽高减半,通道为原来的四倍,采用这种方式可以减少下采样带来的信息损失,更详细得来说,是对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,这样再对其后续操作,得到没有信息丢失后的新图片。
结合特征重构模块,对YOLOv5s网络模型的改进思路有主要有两方面,改进后的网络结构如图3所示。
一方面是对Backbone进行改进。首先把第一层的6 × 6的CBS模块换成Focus模块,在理论上来说,6 × 6的CBS模块和Focus模块是等价的,它们的计算量和参数量是相等的,其实,这里的替换是和特征重构模块有关,经过实验比较,Focus模块和特征重构模块一起使用,能达到更好的性能。其次,在每个C3模块前面添加特征重构模块,C3模块是Backbone对残差特征进行学习的主要模块,在每个C3模块前面添加特征重构模块,能使输入C3模块的特征信息更加丰富,这样C3学到的特征信息也会更多,不管是低层次语义特征,还是高层次定位特征都会有所增加,能全方面提升目标检测模型的精度。除此之外,还修改Backbone中所有CBS模块的卷积的步长为1,使得CBS模块只用来进行提取特征,把下采样的任务交给特征重构模块进行。
另一方面是对PAN结构的改进。为了能更加充分的利用浅层特征图的有效信息,本文在PAN结构中的每个Concat模块前面加入特征重构模块,在新的特征融合结构下,待检测特征图包含更多的几何信息,这些低级的几何信息可以帮助物体更准确地定位。
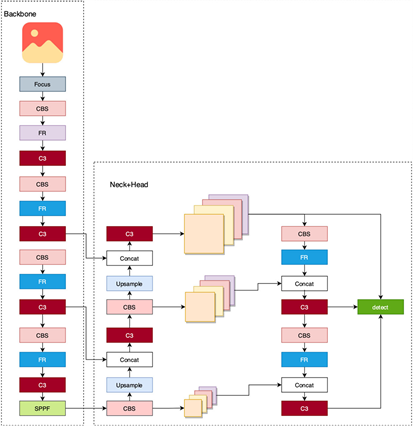
Figure 3. F-YOLOv5s network architecture
图3. F-YOLOv5s网络结构
4. 实验
4.1. 数据集和参数设置
为了验证本文提出的F-YOLOv5s的有效性,进行实验,使用PASCAL VOC数据集进行训练和测试。在本实验中,图片采用640 × 640作为网络输入,训练集选用PASCAL VOC 2007和PASCAL VOC 2012数据集中的trainval部分,共16551张图片;测试集选用VOC 2007数据集中的test部分,共4952张图片。
本文的实验是在一台Ubuntu16.04系统的GPU服务器上进行,显卡为RTX A5000,开发语言是Python,框架是PyTorch,续联采用了Amd优化器进行参数优化。训练网络时,超参数的设置为选择hyp.scratch-high.yaml文件,batch_size为32,迭代总批次为300,学习率采用余弦退火衰减来保证模型更好的收敛。
4.2. 改进前后结果对比
将训练后的网络在PASCAL VOC 2007测试集上进行测试,绘制了召回率–精确度曲线图,如图4、图5所示。横坐标Recall表示召回率,纵坐标Precision表示精度,精确率与召回率这两个评估指标通常是相互矛盾的,通常情况下,会使用PR曲线来表示分类器在精确率与召回率之间的平衡。改进后的模型对各个类别的精度均有提升,并且数据集中所有类别的平均准确率达到了78.5%。
为了证明所提出模块的有效性,分别对YOLOv5s、YOLOv5s + Focus、F-YOLOv5s三种模型在数据集上的map以及其他性能指标进行了测试。如表1所示,其中最优值已被加粗显示。

Table 1. Performance comparison table
表1. 性能对比表
实验结果表明,本文提出的F-YOLOv5s模型相较于其他两种模型在性能指标方面均有所提升。当IOU阈值为0.5时,本文方法相较于原始YOLOv5s模型的map上升了2.9%,相较于YOLOv5s + Focus模型的map上升了3.1%。当IOU阈值在区间[0.5:0.95]时,本文提出模型比另外两种模型分别提升了3.2%、3.1%。在检测精度方面,本文提出模型比另外两种模型分别提升了2.5%、2.3%。在召回率方面,也是有较大提升,分别为2.6%、3%。
4.3. 与其他算法结果对比
为了体现出本文算法的优越性,本文将改进后的网络与近年来其他目标检测网络进行对比,结果如表2所示,其中最优值已被加粗。
其中,以ResNet-152为Backbone的PS-DK网络,鉴于使用了相当大且深层的Backbone网络,使得自身的检测准确率到了最高,为79.5%,本文提出的网络的准确率比其低了1%,但网络的参数量更少,仅仅大约为PS-DK网络参数量的1/9。对于YOLOv7tiny + CIOU来说,本文所提出网络的参数量虽然有所增加,但检测准确率比其提高了14.06%。综合结果表明,改进后的目标检测网络与近年来其他的先进目标检测网络对比,也能展现出不错的性能。
Table 2. Comparison table of different object detection algorithms
表2. 不同目标检测算法的对比表
5. 结束语
本文研究基于YOLOv5s,提出来一种改进的目标检测算法F-YOLOv5s,提高检测网络的准确度。提出特征重构模块进行来进行下采样操作,使得特征信息不会丢失,提高特征信息的利用率。YOLOv5s目标检测网络的骨干网络和脖颈部分引入特征重构模块,大幅度提高网络的准确率。改进后的网络在PASCAL VOC数据集上测试,较原始网络其准确率提升了2.9%,达到了78.5%,以及其他性能指标也均有所上升。接下来将继续优化改进该网络,研究注意力机制对该网络的影响。
参考文献