1. 引言
时间序列预测方法在商业、金融、计算机科学、工程、医学、物理、化学等许多跨学科领域都有广泛的应用。经典的统计时间序列方法侧重于各种精确的数据集。然而,在现实世界中,许多概念不能用精确的值来表示。对于这种情况,模糊时间序列模型在过去几十年中由于其在统计学和工程学中的广泛应用而获得了相当大的关注,例如招生 [1] ,股票指数价格 [2] ,温度 [3] ,财务预测 [4] 和农产品 [5] 等。
Song and Chissom [6] 首先提出了模糊时间序列的概念,并针对精确数据给出了模糊时间序列模型求解方法。模糊时间序列预测模型主要分为三个步骤。首先第一步划分论域,通过在模糊分区中将“话语范围”从精确时间序列中划分出来,对精确数据进行模糊化,其次,第二步通过识别模糊逻辑关系对预测值进行转换。最后,使用去模糊化方法将模糊量转换为精确值 [7] 。第二步对所提模型的预测性能起着重要作用。此后,第二步中的模糊逻辑关系识别技术引起了许多研究者的兴趣,并得到了广泛的研究。模糊逻辑关系识别技术主要包括模糊逻辑关系群和模糊逻辑关系矩阵 [8] 、软计算技术 [9] 以及采用模糊逻辑的统计技术等 [10] 。
对于非模糊时间序列数据,这些方法首先提供一些模糊时间序列预测值,然后将其去模糊化为精确预测值作为最终目标。其他方法依赖于模糊时间序列数据和模糊预测。在这些方法中,假设可用的时间序列数据可以用模糊数据而不是精确值来报告,其目标是用模糊量来预测未来。在这方面,Tseng和Tzeng [11] 提出了模糊季节性ARIMA模型,该模型提出了未来预测的模糊置信区间。Hesamian和Akbari [12] 提出了一种基于模糊数据的统计时间序列模型。他们提出了一个具有模糊数据、非模糊系数和模糊平滑函数的半参数时间序列模型。Zarei et al. [13] 对Hesamian和Akbari [12] 模型进行了拓展,对模糊数据采用了不同的距离度量。Hesamia et al. [14] 提出了基于模糊数据的模糊非参数时间序列模型,将非参数和核平滑方法进行了有效结合。受非参数回归模型和核平滑方法的启发,Hesamian et al. [15] 将非参数回归模型和核平滑方法结合,提出了一种基于三阶段非参数核函数法的估计程序,用于未知非线性模糊平滑函数的中心以及左右展形。
值得注意的是,在Hesamian和Akbari [12] 的方法中,提出了一种带有模糊数据的半参数时间序列模型。该方法依赖于线性回归分析中常用的最小二乘误差技术。然而,在存在异常值的情况下,最小二乘法可能提供较差的预测。在这种情况下,与最小二乘技术相比,稳健方法可以提供更高程度的准确性,因为它们使用加权机制来加权异常值。为此,本文提出了一个简单的加权最小二乘目标,以减少异常值对预测的影响,而且将数据的变化序列分成三个分量,同时还考虑了不确定性大小和模糊程度之间可能存在的关系。然后用一些常见的拟合优度准则来检验改进方法的性能,并且通过一个实际例子来验证了所提模型的效果,数值结果清楚地表明,与其他方法相比,该方法提供了足够精确的结果,特别是在数据集中存在异常值时。
本文的其余部分组织如下:第2节回顾了模糊数和模糊时间序列、模糊自回归分布滞后模型、模糊半参数时间序列模型的一些必要概念。在第3节中,提出了一种基于半参数技术的自适应模糊自回归分布滞后(ARDL)时间序列模型。第4节利用一个实际生活中的例子进行了一些比较研究,同时以一些常见的性能度量来评估所提出方法的性能。最后,第5节将对本文的主要贡献进行总结。
2. 预备知识
本节将介绍模糊数和模糊时间序列、模糊自回归分布滞后模型和模糊半参数时间序列模型的基本概念。
2.1. 模糊数和模糊时间序列
给定论域
,模糊集
由其隶属函数
定义,对于
,
称为模糊集
的
–水平集,并记作
,如果对于
,
是有限闭区间,则实数域
上的模糊集
称为
上的一个模糊数。LR–型模糊数是比较常用的模糊变量,一个LR–型模糊数
由其隶属函数定义得到 [16] :
(1)
其中,中心值
,左展形
和右展形
,
,
是严格递减的形状函数,且满足
。一个LR–型模糊数可以记为
。当
时,LR型模糊数退化为清晰值a。
当
且
时,LR–型模糊数为对称模糊数,记为
。当形状函数
时,LR–型模糊数为三角模糊数,记作
,若
,LR–型模糊数为对称三角模糊数,记作
。
设
的子集
是定义在模糊集
的论域,
是
的集合,则
称为
上的模糊时间序列 [1] 。
根据Coppi et al. [17] ,本文给出了基于LR–型模糊数之间偏差平方的距离的定义,假设
和
,则
与
之间偏差平方距离定义如下:
(2)
其中,
。
当
和
是对称模糊数时,即
和
距离定义为:
(3)
特别地,当
和
是对称三角模糊数时,距离定义为:
(4)
2.2. 模糊自回归分布滞后模型
考虑
是模糊时间序列,是响应变量,
是解释变量,Eren [18] 提出了模糊自回归分布滞后模型,该模型是一种包含因变量和解释变量以模糊线性函数形式的滞后的标准最小二乘回归模型,模糊自回归分布滞后模型(ARDL)具体如下 [18] :
(5)
其中,
是自变量向量,
是模糊系数向量,表示为对称三角模糊数,记作
,其中
为中心值,c为展形,
是随机模糊误差项。Eren [18] 通过线性规划问题来确定模糊线性回归中的未知参数,具体如下:
(6)
在上述表达式中,
,h是控制展形宽度的阈值,且
。
2.3. 模糊半参数时间序列模型
我们考虑
是模糊时间序列,可以建立模糊半参数时间序列模型:
(7)
其中,
是待估计的未知实值系数,
是未知的模糊光滑函数,且
,
是协变量,
是随机模糊误差。为了估计系数和模糊光滑函数, Hesamian and Akbari [12] 提出了一种基于核拟合方法和平方误差距离的两步法。第一步首先选择核函数,其次利用交叉验证法求解最优带宽,第二步利用平方误差距离求解未知系数。
3. 建立模型
在本节中,我们考虑了一种基于半参技术的自适应模糊ARDL时间序列模型,并考虑了加权最小二乘法去估计未知参数,给出了一些经典评价指标去评估模型效果。
3.1. 基于半参数技术的自适应模糊ARDL时间序列模型
假设我们有一组模糊时间序列数据
,其中
。在实际应用中,与参数和非参数统计推断相比,半参数统计推断通常会产生更稳健和灵活的结果。为此,我们考虑以下基于半参数技术的自适应模糊ARDL时间序列模型:
(8)
其中,
,
为需要估计的未知实值系数,
分别是中心,左展形,右展形的误差项,
是
的估计值,
是未知的光滑函数,
是协变量。
为了准确估计系数和光滑函数,我们引入了一个两阶段的方法,首先根据Wang et al. [19] ,未知光滑函数的估计值
为:
(9)
其中,
,且
为核函数
的带宽。
将(8)式代入(7)式中的第一个表达式中,可以得到
的估计值
,具体如下:
(10)
第二阶段中,为了减少异常值的影响,本文采用加权最小二乘法估计未知系数
,
,
,
,具体如下:
(11)
其中,
是
和
之间的平方误差距离,
是第t个残差对应的权重,由该式可以看出,残差
越大的时间序列数据得到越低的权重,这样可以减弱异常值对模型的影响。
3.2. 估计模型未知参数的算法
由于提出的模型(7)中,要想估计未知系数和未知光滑函数,就必须确定中心,左展形和右展形的最优滞后阶数
,
和
以及最优带宽
,为此,本文提出了以下迭代算法来确定最优滞后阶数以及最优带宽,进而得到时间序列模型中的未知参数:
步骤1:选择一个核函数,选择一个滞后阶数
,
,
,其中,中心,左展形和右展形的滞后阶数的上限由样本自相关系数决定;
步骤2:假定初始带宽
;
步骤3:利用初始带宽
和式(10)计算此时未知系数
;
步骤4:计算CV值,当CV值达到下确界时,此时
即为最优带宽
,否则,令
,回到步骤3,重复以上步骤。
(12)
其中,
是中心,左展形和右展形滞后阶数分别为
,且带宽为
时
的估计值。
步骤5:选择另一组滞后阶数
,其中,
,
,
,回到步骤2,并重复以上步骤,模型的拟合优度达到最大时就得了最优的系数估计值。
3.3. 时间序列模型的评价指标
为了评价所提出的基于半参数技术的自适应模糊ARDL时间序列模型的拟合优度,本文使用了一些指标来评价模糊回归模型的性能 [20] [21] :
(13)
(14)
其中,
(15)
(16)
在上述表达式中,
是[0,1]的任意分区,
和
是
的
–水平截集的左端点和右端点。
越大,说明模糊时间序列模型的观测值与估计值越接近,MD越大,则说明模糊时间序列模型的观测值与估计值的拟合效果越差。
此外,贴近度指标具体形式如下:
(17)
其中,
和
分别表示模糊数空间中的交集算子和并算子,
表示
的基数。当贴近度S较大时,说明模糊时间序列模型的观测值与估计值更接近,因此,S越大,说明模型拟合效果越好。
4. 算例分析
本节中,我们考虑1900年至2022年全球陆地–海洋温度指数数据集(见https://data.giss.nasa.gov/gistemp),来验证所提出模型的可行性和有效性。该数据集包含123个观测时间序列数据。本文使用He et al. [22] 描述的模糊化方法,将全球陆海温度指数转换为三角模糊数,得到模糊时间序列数据。假设存在实数
,我们可以得到三角模糊数
,
可由以下表达式确定:
(18)
其中,c服从均值为
,方差为
的正态分布,
,
。
利用本文提出的半参技术和加权最小二乘法对这些数据进行处理,各残差的权重估计值见表1,由表1可知,该数据集包含3个异常点,分别为第115,第116和第120个数据。

Table 1. Estimated weights in example analysis
表1. 算例分析中的权重估计值
同时,本文与D’Urso [23] ,Li et al. [24] ,Hesamianand Akbari [12] ,Zarei et al. [13] 和Hesamian et al. [18] 提出的模型进行了比较,比较结果见图1。从图1可以看出,在异常值存在的情况下,本文提出的方法获得很好的拟合效果,具有可行性和明显的拟合优势。
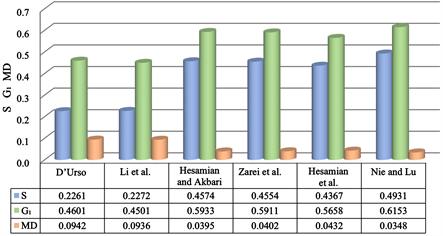
Figure 1. Fitting performances from the models in in example analysis
图1. 算例分析中各模型的拟合指标
5. 总结与展望
在模糊环境中提出的许多统计预测模型依赖于误差平方技术。然而,这种方法在异常数据的存在下可能表现不佳。然而,统计加权可以解决这些缺点。本文提出一种基于半参数技术的自适应模糊ARDL时间序列模型。该模型将数据的变化序列分成中心、左展形和右展形三个部分,以及不确定性大小和模糊程度之间可能存在的关系。本文利用半参数技术建立了自适应回归模型中各元素之间的模糊关系。此外,提出了一种简单有效的加权最小二乘目标来控制异常值,以提高模糊时间序列模型的预测精度。通过与现有模型的比较以及一些常见的拟合优度标准,验证了在异常值存在情况下,所提出模型仍具备可行性和有效性。
在未来的工作中,研究将侧重于改进模糊时间序列的不同稳健算法,如最小中位数平方法、最小截平方和以及切尾绝对偏差等,以优化每个序列的关系分解。在现有模糊关系的基础上,提出了一种新的模糊关系,可以适应各种类型的序列。为了进一步提高预测系统对异常值的稳健性,可以考虑多个异常值的组合。最后,提出的模型也将应用于不同领域的具体问题。
致谢
在此,我要感谢陆老师为改进这篇论文提出的宝贵意见。
NOTES
*通讯作者。