1. 引言
脑机接口(BCI)是一种能在人类大脑与外部计算机或其他外部设备之间建立直接通信渠道的技术 [1] ,基于运动想象(Motor Imagery, MI)的脑机接口是一种流行的脑机接口范式,该范式无需外界的刺激。当受试者自发想象左手运动时,μ (8~12 Hz)和β (12~30 Hz)节律的功率谱密度在大脑的左半球的感觉运动区会升高,而在大脑的右半球的感觉运动区则会降低,而当自发想象右手运动时功率谱密度变化则情况则相反 [2] 。通过检测受试者脑电信号的μ和β节律的功率谱密度变化,可以初步获取被试的运动意图 [3] ,从而将其转化为机器指令控制外部设备 [4] 。为进一步提高脑电信号的解码精度,MÜLLER等人用共空间模式(Common Spatial Pattern, CSP)提取脑电信号空间特征输入到贝叶斯分类器得到分类结果。其中CSP算法的原理是通过矩阵的对角化来找到一组最优的空间滤波器,该空间滤波器可以最大化两种类型脑电信号方差值之间的差异,从而获得有更高区分度的特征向量用于后续分类 [5] 。然而CSP算法没有利用到多频带的信息,脑电信号解码精度并不是太理想。于是Novi等人 [6] 提出了子带共空间模式(SBCSP)算法来提取脑电信号不同频带的CSP特征,然后将不同频带的特征拼接输入到(Linear Discriminant Analysis, LDA)分类器进行分类。但多频带的CSP特征可能会有冗余信息,对此Ang等人 [7] 提出了基于滤波器组的共空间模式(FBCSP)算法来解决该问题,该方法计算多个子带的CSP特征的互信息来选择最具辨识性的特征输入到支持向量机(Support Vector Machine, SVM)进行分类。但是上述传统的机器学习十分依赖手工提取特征,而脑电信号具有信噪比低和非平稳随机性的特点,且不同受试者的脑电信号之间差异大。这些因素使得手工提取的特征不够精确和稳定,影响后续脑电分类任务。
近年来,深度学习模型在医疗健康领域取得了不错的效果 [8] [9] ,研究人员已经将深度学习应用到脑电信号的解码之中 [10] [11] 。Schirrmeister [12] 等人在2017年提出了Deepconvnet模型,这是一个参数量大的深层卷积模型,在运动想象脑电信号识别任务中的准确率超过了传统的FBCSP [7] 算法。但是该网络模型的参数量庞大,训练时间长。对此,Lawhern [13] 等人在2018年提出了EEGnet模型,这是一种高效紧凑的卷积模型,该模型使用了深度可分离卷积使得网络参数大大减少,节省了很多训练的时间。然而,脑电信号易受噪声影响且空间分辨率低,这给深度学习模型提取特征带来了不小的挑战。而Song等人 [14] 提出了用于运动想象脑电识别的VIT模型,该模型先用卷积对脑电信号进行编码,然后将编码特征输入到自注意力模块提取关键的全局特征。虽然上述深度学习模型相比传统机器学习模型,在脑电信号解码上有更加优秀的性能,但是EEGnet [13] 和Deepconvnet [12] 都使用一经训练参数就固定的静态卷积,当被试人员之间个体差异较大时,该类模型很难自适应地提取不同个体的脑电特征导致识别精度不高。
为了解决上述的问题,本文设计了一个基于多维动态卷积的模型(MDConvnet)。该模型是一个可以自适应提取数据特征的轻量级的模型,先用三层分组的多维动态卷积提取特征,然后将提取的特征输进全连接层进行分类。其中多维动态卷积是一种卷积核级别的注意力,它是在动态卷积 [15] 的基础上发展的,相比训练后参数固定的静态卷积,动态卷积 [15] 可以依据输入的数据自适应生成权重来分配给多个平行的卷积核,这让其动态适应数据来提取更好的特征。Li等人 [16] 认为一个卷积核有四个维度,分别是:卷积核尺寸,卷积核输入通道,卷积核输出通道,以及卷积核数,而动态卷积只是对卷积核数这一维度采用了注意力机制,忽略了其他卷积维度的特征,于是Li等人将注意力机制推广应用到了卷积核的其他维度,提出了多维动态卷积。其中多维动态卷积可以依据输入的数据,自适应生成卷积多维度的注意力权重,并用该权重来动态地调节卷积核的参数以更好地提取数据自身特征。此外本文使用的多维动态卷积参数少,且采用并行计算的方式来得到多维注意力的权重,大大减少了模型训练的时间。
2. 方法
2.1. 实验数据介绍
本文使用2023年运动想象数据集RankA和数据集RankB来进行验证。RankA据集包含三种运动想象任务,分别是左手想象任务、右手想象任务和双脚想象任务。总共有9名被试者参与实验,每名被试者进行了90次试验,每种任务各有30次试验,且在试验中随机出现。每个试验包括以下阶段:2秒的任务提示阶段,4秒的运动想象任务执行阶段和2秒的休息阶段。RankA数据集中包含59个脑电通道、1个心电通道和3个眼电通道,并且采样率为1000 Hz。RankB数据集的实验任务、被试参与人数和每名被试者实验的次数和实验流程以及数据采集的格式都和RankA一致,只是实验人员不同。本文对RankA和RankB的数据进行了降采样(250 Hz)并保留前59个脑电通道,之后截取从任务开始后0.5秒到3.5秒的时间段(即750个时间点)作为一个单独的样本
,因此每个人一共有90个样本数据。
2.2. 模型结构
MDConvnet模型包含一个预处理操作和三个多维动态卷积(线性多维动态卷积层、空间多维动态卷积层、时间多维动态卷积层),以及一个全连接分类层,模型整体结构如图1所示。
首先对原始脑电信号需要进行预处理操作,该操作包含两个步骤,第一步使用频带范围4~30 HZ的四阶巴特沃斯滤波器对脑电进行带通滤波,第二步对滤波后的每个脑电通道的数据进行Z-score归一化处理,归一化方法如公式(1)所示。

Figure 1. The structure of MDConvnet model
图1. MDConvet模型结构
(1)
其中
是第i个通道的数据。经预处理后,再将数据输入到线性态卷积层得到线性特征,该层仅有一个滤波器个数为8、卷积核尺寸为1 × 32的多维动态卷积。之后将线性特征输入到空间多维动态卷积得到空间特征,该层使用滤波器个数为16,卷积核尺寸为59 × 1的多维动态卷积提取特征,并使用核尺寸和步长均1 × 5的池化层来压缩特征,同时该层还使用PReLU激活函数其公式如下。
(2)
该激活函数给每个输入特征
的通道都添加了一个可学习的参数
,这个可学习的参数可以赋予小于零的特征一个权重,从而保留下小于零的特征可以输入到模型后续的卷积网络中,这样一来模型可以学习到加丰富的特征信息。接着再将特征输入时间卷多维动态积得到时间特征,该层的多维动态卷积核的尺寸为1 × 64,滤波器数量为16,池化层的核尺寸和步长均设置为1 × 5,激活函数为PReLU。最后将时间特征展平输入到一个全连接层输出运动想象分类的结果。
2.3. 多维动态卷积
多维动态卷积会分配多个平行的卷积,然后依据输入的特征生成卷积核数量维度的注意力权重、卷积输入通道注意力权重、卷积输出通道注意力权重和卷积核尺寸维度上的注意力权重。之后将这些权重和多个平行的卷积相乘来动态调节卷积核参数。最后将所有平行卷积核参数聚合与输入特征进行卷积操作得到最后结果。多维动态卷积模型可由公式(3)~(4)来描述:
,(3)
(4)
其中
是输入的特征,
是经过卷积操作后的结果,
是平行卷积核参数共有n个,
是n个聚合后的卷积参数,代表点乘,
代表卷积操作.
是卷积核尺寸维度的注意力,其结构如图2(a)所示,它会给第i个卷积核的尺寸维度上分配注意力权重。
是卷积核输入维度的注意力,其结构如图2(b)所示它会给第i个卷积核输入的通道分配权重。
是卷积核输出通道维度的注意力,其结构如图2(c)所示,它会给第i个卷积核输出的通道分配权重。
是卷积核数维度的注意力,其结构如图2(d)所示,它会给每个平行的卷积核分配权重。
四个维度注意力的计算流程如图3所示。注意力权重的计算首先需将输入特征
进行全局池化,池化后再输入到一个全连接层进行特征压缩,之后将得到的特征输入到ReLU函数进行非线性化,接着再将其输入全连接层提取公共的注意力特征feature,其步骤如公式(5)~(6)所示:
,(5)
(6)
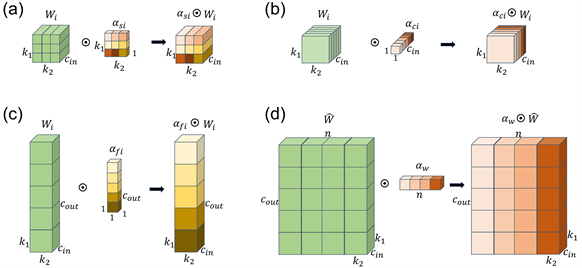
Figure 2. Multidimensional dynamic convolution with dimension-wise attention structure
图2. 多维动态卷积各维度注意力结构
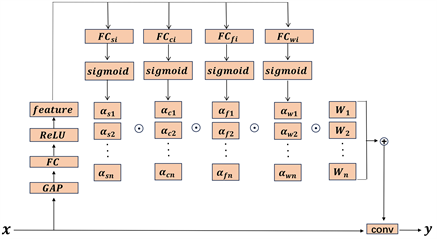
Figure 3. Calculation process of multidimensional dynamic convolution
图3. 多维动态卷积计算流程
然后再将公共特征feature输入四个并行计算不同维度注意力的全连接层,紧接着将全连接层的结果输入sigmoid层将其归一化到[0, 1]的区间得到四个维度的注意力(核尺寸注意力,卷积核输入通道注意力,卷积核输出通道注意力,卷积核数量注意力),上述流程可以用公式(7)~(11)表示:
(7)
,(8)
, (9)
, (10)
(11)
其中,全连接层
会生成第i个平行卷积的卷积核尺寸维度的注意力
,
是卷积核尺寸大小;全连接层
会生成第i个平行卷积的输入通道维度的注意力
,而
是卷积核输入通道数;全连接层
会生成第i个平行卷积的输出通道维度的注意力
,
是输出通道数;全连接层
会生成第i个平行卷积的权值
。最后将生成的多维注意力和多个平行的卷积参数相乘并聚合成一个卷积参数
,与输入特征
进行卷积操作得到结果
。
2.4. 模型训练
RankA数据集和RankB数据集都有9名受试者,每名受试者都有90个样本,本文采用五折交叉验证的方法进行训练测试算法在被试内对左手、右手和双脚想象任务的检测精度。首先将每个受试者的所有样本随机打乱,之后把它们随机分为五个相等的部分,选择其中四份作为训练集,剩下的一份作为测试集对模型进行测试,得到分类准确率,最后将得到的五个准确率取平均值作为模型的分类结果。为了公平比较每个深度学习算法的性能,本文将所有模型的训练轮数、批大小和学习率分别设置为200、32和0.001,同时采用Adam优化器来更新参数,最后使用交叉熵损失来训练函数,交叉熵公式如下所示:
(12)
其中,M代表样本个数,N代表标签的种类,
代表第m个样本的真实标签,而
代表模型对第m个样本的第n类的预测概率。这些实验在配置了Geforce 3060的GPU和AMD Ryzen 7 5800 H的电脑上进行实验,且代码均用3.10版本的Python实现。
3. 实验结果
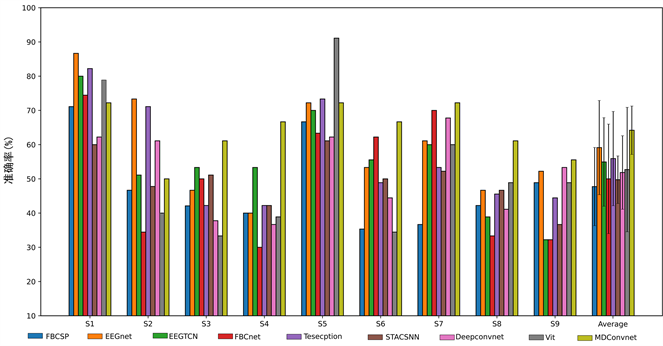
Figure 4. Recognition results of each model on the RankA dataset
图4. 各模型在RankA数据集上的识别结果
本文选取了在MI识别上几个经典的运动想象识别模型和本文的模型进行比较,并用平均准确率作为衡量模型性能的指标。
图4展现的是各模型在RankA数据集上的识别准确率结果,其中MDConvnet模型在RankA的所有被试上取得了最高的平均准确率(64.20%),超过了其他对比算法.平均准确率排名第二的EEGnet [13] 模型仅在被试S1和S2上取得最高的识别准确率。图5展现了各模型在RankB数据集的平均准确率结果,其中MDConvnet模型在RankB的所有被试上也取得了最高的平均准确率(67.02%)。在单个被试上VIT [14] 模型和FBCSP [7] 模型分别在被试S1和S5上取得了最好的识别精度,而MDConvnet模型在被试S3和S4以及S9都上取得了最高的准确率。
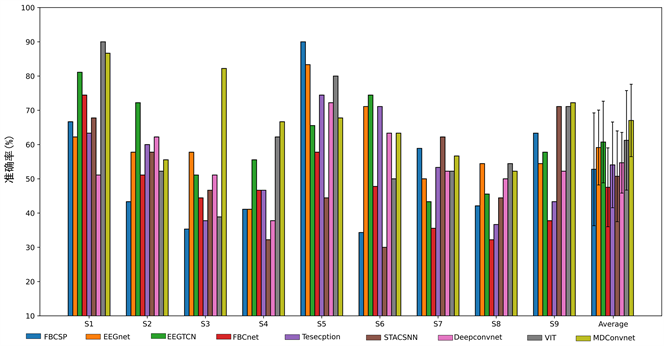
Figure 5. Recognition results of each model on the RankB dataset
图5. 各模型在RankB数据集上的识别结果

Table 1. The parameter count for each model along with the mean and variance of their recognition accuracy
表1. 各模型参数量和各自识别准确率的均值与标准差
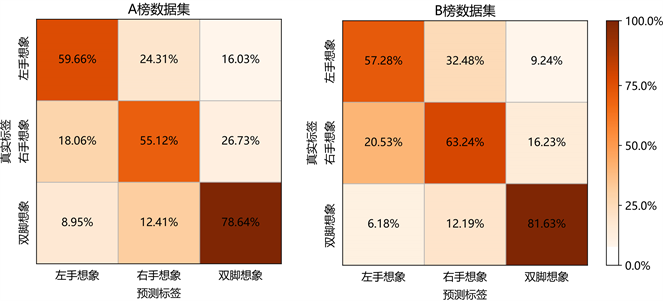
Figure 6. Confusion matrices of classification accuracy for the MDconvnet model on RankA and RankB datasets
图6. MDconvnet模型在RankA数据集和RankB数据集上的分类精度混淆矩阵
表1显示的是各个模型在RankA数据集和RankB数据集上的分类准确率以及这些模型的参数量。在RankA数据集上,MDConvnet模型的分类准确率标准差最小,仅为7.07%。在RankB数据集中,MDConvnet模型的分类准确率标准差仅比Deepconvnet [12] 模型高1.17%,排名第二。值得注意的是,在模型的参数量方面,MDConvnet模型参数量仅为3.93 K,虽然EEGnet [13] 模型和STASCNN [17] 模型的参数量都比MDConvnet模型更少,但MDConvnet模型分类精度却优于它们。从上述实验结果来看,本文提出的MDConvnet模型具有较高的分类精度、较低的方差和较少的参数,是一个高效且稳定的模型。
为了探究MDconvnet模型在RankA和RankB数据集上对不同类别运动想象的分类情况,本文计算了MDconvnet在RankA数据集和RankB数据集上的分类精度混淆矩阵,结果如图6所示。在图6中可以观察到,MDconvnet模型在RankA数据集上对双脚想象的识别准确率为78.65%,明显高于对左手想象(59.66%)和右手想象(55.12%)的识别准确率;MDconvnet模型在RankB数据集上对双脚想象的识别准确率为81.63%,同样高于对左手想象(57.28%)和右手想象(63.24%)的准确率。这说明MDconvnet模型在RankA和RankB数据集上均表现出更高的双脚运动想象识别准确度。
4. 结论
本文提出了一个基于多维动态卷积的模型(MDConvnet),该模型采用三层分组的多维动态卷积来提取特征。其中多维动态卷积会依据输入特征,生成卷积多个维度注意力权重,然后用多维注意力权重来调节卷积参数,来自适应提取不同被试的脑电特征。本文在2023运动想象RankA数据集和RankB数据集上对MDConvnet模型进行了测试。结果显示,MDConvnet模型识别的平均准确率超过了其他对比算法。本文提出的MDConvnet模型是一种具有很大潜力的运动想象解码模型,在未来可应用于运动想象脑机接口系统的解码任务之中,以提高系统的可靠性。
参考文献
NOTES
*通讯作者。