1. 引言
人体的动作捕捉在游戏(人物模型的动作、体感游戏)、体育(运动姿势的矫正)、医学(病人的复建、不良姿势的矫正)、VR/AR和电影制作等各种应用中发挥着重要作用。目前比较流行的是基于视觉人体姿态估计方法。其中一种是通过多个摄像机与深度学习来进行人体姿态估计,如使用了RGB相机 [1] [2] 和深度相机 [3] 进行了人体姿态估计,这种方法可以达到较高的精确度,但无法解决遮挡的问题,不适合在有较多遮挡物的室内使用。另一种是通过在人体上安装光学标记并通过摄像头记录光学信号以实时捕捉人体的动作的方法,比如Vicon就使用这种方法进行人体姿态估计并达到较高的精确度。但是基于光学标记的方法需要庞大且昂贵的基础设施,测试者只能在室内进行运动,同时也无法解决遮挡的问题。目前来说基于视觉的方法都需要昂贵的设备以及合适的场所,并不适合消费者级使用。
与基于视觉的姿态估计方法相比,IMU安装于人体且独立于环境,因此不会受到环境遮挡的影响,可以在各种各样的环境中使用。同时由于IMU的价格较低,比较适合消费者级的用户进行使用。基于IMU的人体姿态估计方法的缺点是当所使用的IMU数量较少时,进行姿态估计时会产生较大的误差。但是随着神经网络的发展,目前的基于单纯基于IMU的高精度人体姿态估计已经有了一定的发展。有的研究者使用了双向递归神经网络 [4] 并使用6个IMU对人体姿态进行了估计,也有的通过将姿态估计分为三个部分提高了姿态估计的精确度 [5] ,有的通过使用简单递归单元(SRU, Simple Recurrent Unit) [6] 进行快速的人体姿态估计 [7] 。以上方法能够通过仅使用6个IMU进行较为准确的人体姿态估计,但所使用的网络都是基于RNN及其变体,没有充分利用IMU信息。因此,针对仅使用IMU进行人体姿态估计任务提出了一种新的网络结构。
主要的改进点是:
1) 提出了一种新的具有双重信息保留注意力模块的网络结构,更好地建模了长距离依赖,提高了姿态估计的准确度。
2) 使用均匀滤波过滤和白噪声模拟的方法对合成加速度进行了数据增强以更好地拟合真实数据。
3) 使用近似变化速度作为额外参数输入并降低了姿态估计的误差。
之后将在第2节介绍了各类人体姿态估计的相关工作。第3节介绍了运动学模型和数据集。第4节介绍了所使用的网络结构。第5节给出了网络在DIP-IMU数据集上的定量和定性评估结果,并进行了消融实验,以证明该方法的有效性。第6节总结了目前方法的局限性并说明未来可能的发展方向。
2. 相关工作
人体的姿态估计目前有三种主要的方法。
2.1. 基于视觉的方法
基于视觉的方法
基于视觉的人体姿态估计是目前最流行的方法,通过相机捕捉人体运动并通过深度学习进行人体姿态估计。例如,利用视频帧之间丰富的时间特征来辅助关键点识别,编码关键点时空上下文以提供足够的搜索空间,然后通过姿态校正网络进行处理,以有效地细化姿态估计 [8] 。通过设计了一种简单有效的半监督训练策略以利用未标记的视频数据,使用基于2D关键点上的扩展时间卷积的全卷积模型快速预测电影中的3D姿态 [9] 。通过提出了一种具有双分支解码器的独特编码器–解码器结构,解决2D关节位置的可变不确定性,并提供了新的大规模真实感合成数据集 [10] 。也有研究者提出了一种用于估计3D人体姿态的快速、统一的端到端模型,该模型将各阶段最佳做法进行结合,之后有人将其应用于艺术体操、训练和舞蹈的评估和评分 [11] 。
2.2. 基于视觉与惯性传感器融合的方法
通过将摄像机与惯性传感器进行融合使用,可以使姿态估计达到较高的精度。例如,将每个图像中的2D姿势检测与每个人配备的相应的IMU相关联,然后使用连续优化框架来优化统计身体模型姿势 [12] 。通过提出了使用多视图图像和连接到人体肢体的一些IMU来估计3D人体姿势 [13] 。此方法首先从两个信号中检测二维姿态,然后将其提升到三维空间。通过使用多通道3D卷积神经网络从视觉占用中学习姿势嵌入,并从离散体积概率视觉外壳中的MVV中学习语义2D姿势估计 [14] 。
2.3. 基于纯惯性传感器的方法
目前基于纯惯性传感器的人体姿态估计主要通过姿态估计优化方法和网络模型来进行优化。
姿态估计优化方法是从姿态估计的流程中进行优化,目前国内外对基于IMU的人体姿态估计研究已经有了一定的进展。在早期就有人使用了17个惯性传感器测量人体运动时各关节的旋转数据 [15] ,以此对人体的姿态进行较为准确的估计,但过多的传感器会限制人体的动作,设置的过程也不方便,同时过多的IMU会增加成本。有研究者为人体研究提供了一个可靠的运动学模型 [16] ,之后在姿态估计方面,有人做出了一项开创性的工作,通过一种基于迭代优化的方法使用6个IMU估计人体姿态 [17] ,但它必须以离线方式操作,这使得实时应用变得不可行。而另外的研究者通过利用双向递归神经网络(也使用6个IMU)来直接学习IMU测量到人体关节旋转之间的映射,相较于之前的工作提高了精度但仍然有可优化的地方。最近也有同样使用双向递归神经网络的方法,同时通过将姿态估计分为多个阶段,即从IMU测量信息分步估计叶关节位置、全关节位置、全关节旋转,通过这种逐步估计的方法实现了更高精度的姿态估计并估计了穿戴者的整体平移。
网络模型的优化是从使用的神经网络上进行优化,改进神经网络的性能,使其更适合人体姿态估计任务。目前人体姿态估计都使用递归神经网络(RNN, Recurrent Neural Network)和双向递归神经网络作为网络模型,保留时间信息以提高精确度。RNN通过传递当前时间步的隐藏状态,来对序列数据进行建模。作为一种数据处理模型,RNN的隐藏状态是通过逐步迭代计算得到的,每个时间步只能看到当前位置之前的信息,对于人体的运动这种有长距离依赖的数据并不能很好地捕捉其依赖关系,同时比较容易产生梯度消失和梯度爆炸地问题。Transformer通过对输入乘以三个矩阵得到三个新的矩阵,并使用这三个矩阵计算自注意力,该方法可以通过全局信息提高了序列建模的能力,并通过堆叠多个这样的多头注意力模块和前馈神经网络模块提升了性能 [18] 。保留网络(RetNet, Retentive Network)与Transformer同样堆叠了多个相同的模块,但其注意力模块在保留了Transformer中的注意力矩阵的同时加入了类似RNN的状态信息参数,提高了推理时的性能 [19] 。因此相较于RNN结构,可以关注全局信息并进行序列建模的Transformer结构更加适合应用于人体姿态估计任务中。因此在RetNet网络和Transformer网络的基础上提出了双重信息保留Transformer网络,能够更进一步提高姿态估计的精确度。
3. IMU校准和数据集预处理
本节将介绍进行姿态估计前所需的IMU校准和数据集预处理工作。在2.1节介绍所使用的运动学模型,在2.2节介绍了IMU的校准方法,在2.3节介绍所使用的数据集以及数据集预处理方法。
3.1. 运动学模型
人体姿态估计的运动学模型SMPL骨架模型。SMPL是一种蒙皮多人线性模型,在有着较高的准确度的同时与现有的图像管道相兼容。SMPL骨骼将身体姿态、动态身体软组织和其他的模板结合,然后通过混合蒙皮进行转换。其定义为:
(1)
其中T是静止姿势中的模板网格,J是24个身体关节,θ是根据关节角度的姿势参数,
是线性混合蒙皮函数。由于IMU数据不包含人类形态特征,所以数据集中的所有肢体长度都相等,即姿态估计都在同一体型下进行。
3.2. 传感器校准
使用的6个IMU分别固定在人体的腰部、左小腿、右小腿、左前臂、右前臂、头部这六个位置。由于每个传感器收集的数据都在其局部坐标系中,而人体姿态估计需要使用运动学模型SMPL坐标系下的数据,因此需要对传感器的数据进行校准。
每个IMU数据测量的加速度与传感器坐标系FS有关,其基矩阵为BS。IMU测量的方向数据与惯性坐标系FI相关,其基矩阵为BI。令姿态估计所使用的人体运动学模型SMPL模型的坐标系为FM,其基矩阵为BM。使得腰部的IMU坐标系与SMPL坐标系一致,IMU的方向O从FI变为了FM,可得:
(2)
让穿戴IMU的测试人员保持T姿势静止几秒,在T姿势中可以方便得知与FM坐标系相关的SMPL骨骼方向的数据
,之后读取与坐标系FS有关的平均加速度读数
以及与坐标系FI有关的方向数据
。并且由于穿戴的IMU与人体骨骼之间的方向必定存在误差,将误差设为
,由此可得在FI坐标系中的人体骨骼方向:
(3)
由于人体的骨骼方向在两个坐标系下是等效的,由此可得:
(4)
将(2) (3) (4)三个式子相结合可以得到在FM坐标系中的方向数据:
(5)
对于加速度数据的转换,首先假设IMU在安装后的位置是固定的,不会产生相对移动,所以可以得到在FI坐标系下的骨向量和
IMU中的加速度是一致的,即:
(6)
同时可以将IMU局部坐标系FS中的加速度转化为全局惯性坐标系FI下的加速度:
(7)
由于传感器的误差以及方向的不确定性,全局坐标系FM中的加速度会存在一个偏移,加上偏移之后再由加速度在两个坐标系下的等效关系可得:
(8)
由于测试人员在测试中保持了T姿势的静止状态,因此
为0,将(2) (5) (6) (7)这4个式子结合可得:
(9)
由于
变为了一个已知量,因此可以计算在全局坐标系FM下骨向量的加速度为:
(10)
由此就得到了全局坐标系FM下的方向
和加速度数据
。
3.3. 训练数据
用IMU进行人体姿态估计的网络需要的输入包含加速度和方向,以及人体运动时各关节的旋转的数据来进行训练。目前达到要求的数据集有DIP (该数据集包括10名佩戴17个IMU的受试者进行约90分钟运动的IMU测量和姿势参数)和TotalCapture [20] (包括5名佩戴13个IMU的受试者进行约50分钟运动的IMU测量、姿势参数和全局平移)。目前所拥有的数据集无法训练出具有足够泛化能力的模型,因此需要通过使用合成IMU数据的方法来获取足够的数据。
合成IMU数据的原始数据集为AMASS运动数据集 [21] ,该数据集是现有动作捕捉数据集的集合,包括在300多个实验个体上收集和执行的40多小时不同类型运动的姿势数据参数。AMASS数据集中的每个子数据集包含SMPL模型的每个关节的旋转和全身位移参数,但其中并没有IMU数据,因此需要通过放置虚拟IMU的方法来获得IMU数据。SMPL是一个具有6890个网格顶点的模型,选取其中与人体配置IMU位置相近的顶点设置虚拟IMU直接获得相应的速度和旋转数据并通过计算获得加速度,加速度的计算公式为:
,
(11)
其中表示第t帧中第i个传感器的加速度测量值,Δt为指定两个连续帧之间的间隔。模型以60帧/秒的速度对所有数据进行采样,因此Δt的值为约为0.0167。在计算的过程中,n = 3或4时接近与真实的加速度值,最终选择n = 4以获取更平滑的加速度数据。
通过将合成的加速度和真实的加速度进行对比,可以发现合成的加速度数据与真实的加速度数据在噪声分布上存在差异,原因是用IMU测量得出的加速度存在着漂移与白噪声。如图1两类的加速度由于漂移和噪声的问题难以拟合,最终会导致在训练出的模型在进行测试时产生额外误差。对真实的加速度数据和合成的加速度数据进行了滤波,并添加正负值为0.2的均匀噪声来模拟加速度测量中的白噪声,对合成的数据进行了数据增强。图2为滤波后的加速度图像,经过滤波后的合成加速度与真实加速度具有更好的拟合度,能够在训练出更好的模型。

Figure 1. No filtered synthetic acceleration and true acceleration
图1. 无滤波合成加速度和真实加速度
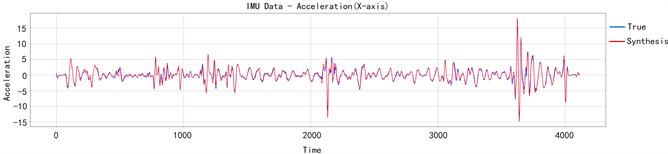
Figure 2. Filtered synthetic acceleration and true acceleration
图2. 滤波后合成加速度与真实加速度
4. 方法
在此节介绍所使用的姿态估计方法,在4.1介绍系统输入与数据标准化的方法,在4.2介绍变化速度Δv的获取,在4.3介绍网络结构,在4.4介绍训练细节。
4.1. 系统输入与数据标准化
网络的目标是通过六个IMU还原人体姿态,即对全身其他15个关节的旋转进行估计。将设置在腰部的IMU称为根节点,将其他节点称为叶节点。系统的输入为6个IMU数据中与人体运动相关的加速度数据为
并进行标准化得到:
(12)
(13)
标准化的目的是将加速度数据变为与根节点相关,比例因子30为经验所得,是为了使加速度适应网络输入并调整加速度数据大小。
IMU的方向数据为
并进行标准化得到:
(14)
对方向数据进行标准化同样是为了将方向数据变为与根节点相关。
4.2. 对加速度积分获得变化速度Δv
仅凭IMU的加速度和旋转数据对人体全身15个关节的映射是相对具有挑战性的。因为当加速度和旋转数据相同时,稀疏的IMU数据会具有不确定性,对关节旋转的估计会产生偏差。例如当人在站着和坐着时,imu的数据几乎是相同的。因此,需要利用全局信息来判断当时的姿态,以及输入更多的信息提高估计的精度。
过IMU还原人体姿态,预测15个关节的旋转时,除了加速度和旋转信息,速度信息也可以提高姿态估计的精度。虽然IMU无法直接获得速度,但可以通过累计在很小时间内的加速度,相当于将其积分到Δv,以此来获得更丰富的信息:
(15)
令Δt的值为0.5,由于使用60帧/秒的速度采集数据,因此相当于累加30个加速度值,最后和之前加速度的标准化一样除以一个缩放因子15来适应网络输入并调整Δv的大小以获得更好的输出,比例因子15同样为经验所得。
4.3. 网络结构
姿态估计网络结构的总体框架如图3所示,将设置在身体各部位的6个IMU所收集到的加速度数据
和旋转数据
进行标准化并合并。之后将通过累计0.5秒内的加速度数据得到近似的
并将其也合并到IMU数据中,最终输入到线性层的IMU数据为
。将进行处理后的IMU数据输入到一个线性层中,第一个线性层的作用是从输入的IMU数据中提取当前动作的特征,其隐藏单元的维度设置为256。
经过特征提取后的数据被输入到网络中,网络的整体结构如图3中所示为堆叠了多个相同模块的网络。其中双重信息保留注意力模块的结构如图4所示。

Figure 4. Bidirectional information preservation attention module
图4. 双向信息保留注意力模块
其中
、
、
为当前时间步的自注意力计算向量,由当前时间步的输入
与三个矩阵相乘获得。
为上一个时间步的状态信息,
与其相乘得到一个状态参数
。根据公式(17)可以计算得到当前时间步的状态参数
,并将当前时间步的状态信息传递给下一个时间步。通过这种改进后的双重信息保留注意力模块,可以在更好地保留时间信息的同时考虑全局信息,从而提高姿态估计的准确度。
最后将提取过时间信息的数据输入到线性层中得到15个关节的6d旋转表示
。最后还原的关节数为15,是因为部分关节的数据可以直接从IMU中获得,而15个关节中的其中8个关节可以直接驱动剩下的8个关节旋转,因此得到15个关节的旋转就可以完整表示人体的姿态。
在实验过程中,可以发现提出的网络模型虽然减小了姿态估计的角度误差,但会导致较大的抖动误差,因此选择在姿态估计时添加了一个实时低通滤波以减少抖动误差:
(16)
根据经验将参数选为0.8和0.2,该参数可以在减少对角度误差的影响并减少抖动误差。
4.4. 训练细节
模型训练分为预训练与微调两个部分,将经过处理的AMASS数据作为预训练的训练集以此来获得人体运动的先验知识。之后在微调使用DIP中S01-S08的数据作为训练集进行微调。
所有的训练都是在12 vCPU Intel(R) Xeon(R) Platinum 8255C CPU和RTX 3080显卡上进行的,软件使用pytorch 1.10.0和cuda 11.3进行训练。模型使用Adam [22] 作为优化器,训练时的学习率为起始学习率为0.001的余弦退火学习率,训练时的批次被设置为256,每个实验训练200轮。
5. 实验比较
在本章进行实验结果的对比,在4.1节介绍模型的评价指标并进行实验结果比对,在4.2节进行消融实验并展示结果对比,在4.3节进行了实验结果的可视化对比。在4.4节描述了该模型的局限性与未来展望。
5.1. 在线与离线的结果对比
本节对在线和离线的实验结果进行对比,实验的评价指标为:1) SIP误差(SIP Err):测量上臂和大腿的在全局坐标系下的平均旋转误差,单位为度;2) 角度误差(Ang Err):全身关节点的全局平均旋转误差。3) 位置误差(Pos Err):根关节(脊柱)对齐的所有估计关节的平均欧几里得距离误差。4) 网格误差(Mesh Err):测量与根关节(脊椎)对齐的估计身体网格的所有顶点的平均欧几里德距离误差。5) 抖动误差(Jitter Err):测量预测运动中所有身体关节的平均抖动。

Table 1. Offline estimation experimental results
表1. 离线估计实验结果
Table 2. Online estimation experimental results
表2. 在线估计实验结果
表1和表2分别为模型对人体的姿态进行离线估计和在线估计的定量比较,可以得出模型在SIP误差,位置误差和网格误差方面得到了更小的误差结果。由此可以得出该网络在上臂与大腿方面的姿态估计方面有较好的准确率提升,而造成这种准确率提升的原因是改进的双重信息保留注意力模块同时使用了自注意力与双重状态信息传递,同时考虑了全局信息并有效利用了历史信息。而所使用的近似Δv拟合以及合成数据集的数据增强,使得模型有了更多的输入信息与更贴近真实数据的合成数据集,这两种方法也进一步提升了模型的性能。
5.2. 消融实验
本节进行消融实验以验证该网络模型的有效性。
Table 3. Ablation experimental results
表3. 消融实验结果
表3为进行消融实验后的实验结果,可以看出模型所使用的Δv与合成数据增强方法都能够有效提高姿态估计的准确度。通过数据集的滤波,使得真实产生的IMU加速度数据与合成所获得的IMU加速度数据具有更好的拟合性,通过合成Δv,并将其加入IMU数据中为姿态估计提供了更丰富的信息,可以看到各项误差都在一定程度上减少了。同时对于模型会产生较高的抖动误差的问题,通过使用低通滤波略微增加了其他方面的误差,但大幅降低了预测过程中产生的抖动误差。
5.3. 可视化定性比较
图5为在线和离线的定性可视化比较,通过从测试的数据集中选取了一些帧并进行可视化来进行定性的可视化比较。
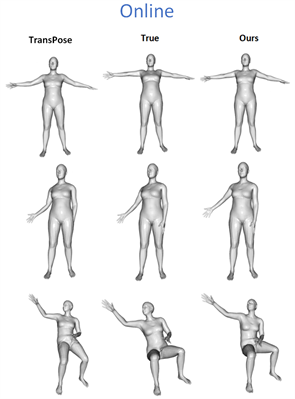
Figure 5. Offline and online visualization comparison
图5. 离线与在线可视化比较
从图中可以看出,改进后的人体姿态估计模型对于手臂部分和腿部的部分的估计更加接近真实的动作。TransPose在手轴和膝盖部分的弯曲以及对于手臂的位置估计有着一定的误差,而改进后的人体姿态估计模型对于这些部分的估计更加精确,在姿态估计时消除了这些误差从而更加接近真实的动作。
5.4. 局限性与展望
对于人体姿态估计的任务,改进后的方法取得了一些进步但也受到了一些限制,限制有IMU硬件和估计任务本身两个方面。
在IMU的测量方面。由于IMU在长时间测量时会积累漂移同时由于加速度中噪声的存在,最终会导致姿态的估计产生较大的误差。方向的测量是由IMU中的磁力计所进行的,因此方向的测量很容易受到周围磁场的影响而产生不确定性。
在姿态的估计方面。在进行在线姿态估计时改进后的方法会产生较大的抖动误差,且虽然模型所使用的∆v对姿态的估计由一定的帮助,但是如果可以确定姿态的初始状态就可以获得人体运动时的速度,对姿态的估计可以产生更大的帮助。
针对以上的问题,可以在未来额外训练一个模型来确定人体姿态的初始状态,之后使用速度数据来进一步提高姿态估计的精确度,同时可以利用人体结构对姿态估计任务产生一定的约束从而提高姿态估计的精确度。
6. 结论
对于人体姿态估计任务提出了一种新型的双重信息保留网络,可以在考虑全局信息的同时利用好历史信息,相比于RNN适合人体姿态估计的任务。此外,通过对合成数据的数据增强和平均滤波使其更加拟合真实数据,以及通过对加速度进行积分获得了近似变化速度∆v,以上的方法进一步提高了姿态估计的精确度,最终完成了仅通过6个IMU完成较高精度的人体姿态估计的任务。之后将尝试训练一个确定人体初始状态的模型来获得运动速度以进一步提高姿态估计的精确度,同时尝试完成仅通过6个IMU达到较高准确率的人体动作识别任务。
NOTES
*通讯作者。