1. 引言
时间序列分析是数据分析的一个重要分支。通过分析时间序列,可以深入了解各种现象的发展趋势,并将其应用于如资源规划、环境控制等领域。多数现有研究专注于模型选优以提高预测精度。例如,李文武等人(2022) [1] 为提高综合能源系统负荷的预测精度,提出了一种结合聚合混合模态分解和时序卷积神经网络(TCN)的预测框架。杨芸珍等人(2020) [2] 为了提高Klobuchar模型的电离层延迟修正精度,提出了基于ARIMA误差修正预测的精化方法。但面临持续增长的数据量,如何有效地利用新数据进行修正预测以提高准确性,这是一个值得关注的问题。
利用新数据进行修正预测主要有两种策略。一种策略是将新数据纳入到原始数据集中,然后基于这个更新后的数据集重新拟合模型,再利用重新拟合后的模型进行预测,这种方法称为重新拟合模型下的修正预测(简称“改变模型修正预测”)方法。另一种策略是在新数据产生后,并不需要重新拟合模型,而是利用平稳时间序列的特性对已有的预测结果进行修正 [3] ,这种方法称为拟合模型不变下的修正预测(简称“不变模型修正预测”)方法。例如,郭祥琳等(2018) [4] 通过介绍时间序列修正预测方法,验证其在建筑物沉降监测中的适用性。刘军等(2011) [5] 考虑到电离层变化的周期性,为了进一步减小极值点处预测误差,提出了改进的修正预测法,用上一周期的预测误差对修正预测法结果进行改正。
本文主要在ARMA模型的修正预测基础上,研究具有多项式趋势的残差ARMA模型的修正预测方法。
2. 模型构建方法
考虑含有多项式趋势项的残差自回归移动平均模型
(1)
其中
代表时间序列在t时刻的值,
代表多项式回归模型的系数,n代表多项式的最高次数,
代表在时间t处的误差项,
代表自回归部分的模型参数,
代表移动平均部分的模型参数,
是残差ARMA模型中的误差项。
2.1. 多项式拟合次数的确定
通过K折交叉验证确定多项式拟合的最佳次数m,通常选取K等于10 [6] 。依次对一次多项式、二次多项式……执行一次K折交叉验证。在交叉验证的每一轮中,数据首先被分割为K份,每次选取一份作为测试集,其余部分作为训练集 [7] 。接着,根据给定的多项式次数对训练集进行模型拟合,并记录该次数下模型在测试集上的均方根误差(RMSE)。这样,每一个多项式次数将得到K个RMSE值,将平均RMSE值作为该多项式次数下的平均误差。最后,找出具有最小平均误差的多项式次数,将其确定为最佳次数。
基于得到的最佳次数m,进行回归分析,得到最小二乘估计的回归系数,获得回归方程,然后,对回归方程进行F检验和t检验,经过检验之后,对残差做进一步的分析。
2.2. 残差ARMA模型参数的确定
基于拟合的趋势模型,得到残差序列。首先对其进行平稳性检验,若不平稳,考虑使用差分、对数转换等方法进行平稳化处理;对于平稳的残差序列,基于自相关函数(ACF)和偏自相关函数(PACF)图形以及AIC和BIC准则,对模型进行识别和阶数的确定。最后,利用最小二乘法或极大似然估计法来确定模型的参数。
2.3. ut的修正预测
对于一个平稳可逆的
模型,它的传递形式为 [3]
(2)
式中
为Green函数。
通过待定系数法,可以得到
模型场合下Green函数的递推公式为
(3)
式中
为
(4)
已知在旧数据
的基础上,
的预测值为
(5)
如果获得1个新观察值
,则
的修正预测值为
(6)
式中
是
的一步预测误差。
如果获得s个新观察值
,则
的修正预测值为
(7)
式中,
是
的一步预测误差。
3. Monte Carlo模拟算例
不妨设模型(1)中
,
,
,
,
,
。此时,模型为
(8)
在Monte Carlo模拟中,进行1000次模拟实验,每次实验生成105个数据,其中前100个用于构建模型,剩余的5个用于验证。基于模型(8)拟合的平均MAE (平均绝对误差)为0.767,平均MSE (均方误差)为0.924;预测的平均MAE为1.213,平均MSE为2.461。表1和表2分别给出了不变模型修正预测结果和改变模型修正预测结果。

Table 1. Mean MAE and mean MSE for modified predictions of the invariant model
表1. 不变模型修正预测的平均MAE和平均MSE
Table 2. Mean MAE and mean MSE of modified predictions by changing models
表2. 改变模型修正预测的平均MAE和平均MSE
由表1和表2可以看出,两种修正预测法的平均MAE和平均MSE均小于未修正预测的平均MAE和平均MSE,并且随着新数据的产生和修正期数的增加,平均MAE和平均MSE逐渐减小,显示了修正预测的优势。进一步地,在初期修正时,不变模型修正预测法的平均MAE和平均MSE较低,而在后期修正时,改变模型修正预测法的平均MAE和平均MSE较低,说明了这两种方法各有优劣。然而,考虑到改变模型修正预测法需要不断地重新拟合模型,将导致计算成本的大量增加,在这个意义下,不变模型修正预测法不失为一种简单易行的方法。
4. 实证分析
选取2023年1月到6月的118期上证指数收盘价做为原始数据,记为
,如图1所示。为确定多项式
的最佳次数及其系数,采用了10折交叉验证方法。通过计算不同次数多项式的平均RMSE,以平均RMSE最小的次数确定多项式的最佳次数,结果如表3所示。当多项式为2阶时,其平均RMSE达到最小值43.381,再使用最小二乘法对二次多项式进行拟合,得到的趋势项模型为
(9)
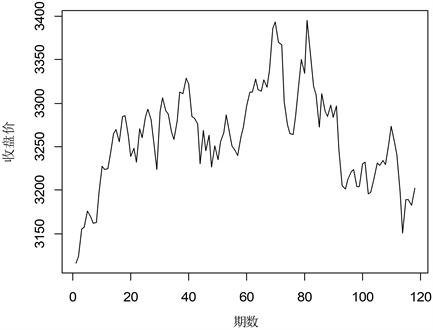
Figure 1. Shanghai Composite Index closing prices from January to June 2023
图1. 2023年1月至6月每期上证指数收盘价
Table 3. Average RMSE for polynomial fitting
表3. 多项式拟合的平均RMSE
对模型(9)进行F检验,统计量值为68.68,对应的P值为0.00,说明该模型显著成立。表4的多项式参数估计和检验结果显示,常数项、一次项和二次项的P值均为0.00,均通过了t检验,即参数估计值显著。
Table 4. Parameter estimates and statistics
表4. 参数估计及统计量
通过去掉多项式趋势项,得到残差序列
,如图2所示。容易看出,残差序列
展现出平稳特性。经ADF单位根检验,其P值为0.00,表明残差序列是平稳序列。经Ljung-Box检验得到P值为0.00,确定该序列是非白噪声序列。
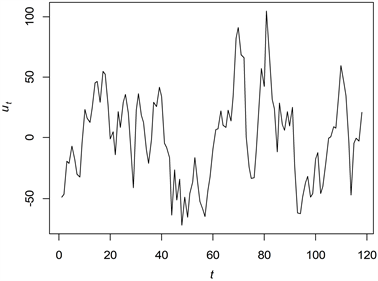
Figure 2.
Timing diagram of residual sequence
图2. 残差序列
时序图
图3给出了残差序列
的自相关图和偏自相关图。由图3可知,偏自相关图在一阶后截尾,选择p = 1。自相关图显示了拖尾特性,为确定适当的q值,参考AIC和BIC的评价准则,根据表5的数据,当p = 1且q = 0时,AIC和BIC均达到最小值,因此,对残差序列建立AR(1)模型。采用最小二乘法对数据进行拟合,最终得到的模型为
(10)
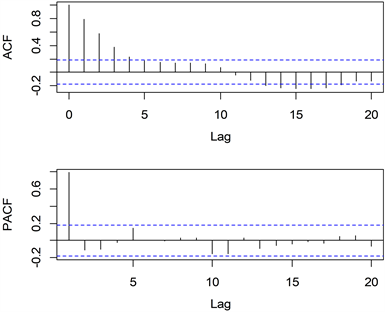
Figure 3. Autocorrelation and partial autocorrelation of residual sequence
图3. 残差序列
的自相关图和偏自相关图
Table 5. AIC and BIC values for residual sequence { u t } modeling
表5. 残差序列
建模的AIC和BIC的值
对序列
进行白噪声检验,P值为0.356,接受原假设,即该序列为白噪声。图4为序列
的QQ图和PP图,这两个图中,数据点紧密地沿着参考线排列,表明
近似服从正态分布。
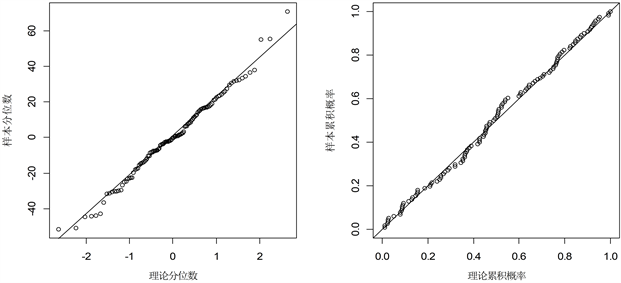
Figure 4. QQ chart (left) and PP chart (right) of residual sequence
图4. 残差序列
的QQ图(左图)和PP图(右图)
基于模型(10),预测了2023年7月上证指数的前5期收盘价,如表6所示。5期预测的相对误差均未超过2%。特别是在第123期,预测的相对误差甚至未达1%。
Table 6. Unrevised predictions based on model (10)
表6. 基于模型(10)的未做修正的预测结果
经将7月份前4期收盘价逐步纳入为新数据进行修正预测后,不变模型修正预测结果见表7,改变模型修正预测结果见表8。由表7和表8可知,两种修正预测的误差均得到了降低。特别地,在不变模型的2期修正预测中,第121期和123期,以及3期修正预测的第122期,预测的相对误差均不足0.1%。同样,在改变模型的2期修正预测中,第121期和122期,以及3期修正预测的第122期,预测的相对误差也均不超过0.1%。
Table 7. Revised predictions for the unchanged model
表7. 不变模型的修正预测结果
Table 8. Revised predictions for changing the model
表8. 改变模型的修正预测结果
进一步地,模型(10)拟合的MAE为17.392,MSE为503.222;预测的MAE为384,MSE为2077.921。表9给出了不变模型修正预测的MAE和MSE,表10给出了改变模型修正预测的MAE和MSE。由表9和表10可知,两种修正预测的MAE和MSE比不修正预测的MAE和MSE小得多,表明了修正预测的优势。此外,两种修正预测方法相比较,在一个新数据引入并进行1期修正下,改变模型修正预测的MAE和MSE较低,但随着后续新数据的逐步引入,改变模型修正预测的MAE和MSE却较高,显示了改变模型修正预测法的不足。
Table 9. MAE and MSE predicted by modified invariant models
表9. 不变模型修正预测的MAE和MSE
Table 10. MAE and MSE for modified predictions by changing models
表10. 改变模型修正预测的MAE和MSE
5. 结束语
本文主要探究了含有多项式趋势的残差自回归移动平均模型的修正预测方法,模拟结果显示,与需要重新拟合的改变模型修正预测法相比,不变模型修正预测法计算成本小,优于未修正预测法,可以看作是一种简单易行的修正预测方法。实证分析结果也表明了不变模型修正预测法的优越性和可行性。
基金项目
国家自然科学基金资助项目(11601126);河南省科技重点攻关项(182102210286)。
NOTES
*通讯作者。