1. 引言
语义分割是计算机视觉中的一项重要任务,它旨在将输入图像的每个像素划分到特定的类别中。随着深度学习的发展,语义分割已经成为众多领域的关键技术,包括自动驾驶 [1] 、医学影像诊断 [2] 以及遥感成像 [3] 等。自从全卷积网络(Fully Convolutional Network, FCN) [4] 被提出解决图像分割问题以来,深度学习技术在准确率和效率方面开始超越传统的基于手工特征 [5] 方法。一些创新模型如Deeplab [6] 、PSPnet [7] 有效地学习像素间的上下文关系,显著提高了分割的准确性。为了进一步提升性能,研究人员开发了多种策略,使这些模型能够捕获丰富的上下文信息,同时保留关键细节。然而,这些模型往往伴随着高昂的计算成本,这一点在需要实时处理的应用场景中如自动驾驶 [8] 和机器人辅助手术 [9] 中不能满足需求。因此,尽管这些模型取得了卓越的分割性能,但在实际应用中的普及仍面临挑战。
为了满足实时分割的需求,研究者们已经提出了许多高速语义分割的模型。ENet [10] 在早期采用了轻量级解码器,对特征图进行了下采样。ICNet [11] 对小尺寸输入进行复杂的深度编码,以解析高级语义。MobileNets [12] 用深度可分离卷积取代了传统的卷积。这些早期的工作减少了分割模型的延迟和内存使用,但低准确率显著限制了它们在实际应用的普及。近年来,许多基于双分支和多分支的模型被提出,随着移动设备部署需求的不断增长实现了较好的分割速度和精度之间的平衡。
在本文中,我们提出了一个具有深度高分辨率表示的三分支网络用于道路驾驶图像的实时语义分割。我们的网络从一个主干开始,然后分成三个具有不同分辨率的平行分支。第一个分支生成相对高分辨率的特征图提取空间信息,第二个分支通过使用多次残差U块提取多尺度语义信息,第三个分支生成边界信息,在三个分支之间架起多个双边连接,实现信息融合。此外,我们引入了上下文变换器模块(Contextual Transformer, CoT),该模块融合卷积神经网络(CNN)的局部感知能力和Transformer的全局依赖建模能力,可以提高模型对图像中不同部分之间关系的理解和表示能力。
本文主要贡献如下:
(1) 使用U2-Net [26] 中提出的RSU模块来构建网络的上下文信息分支,大大提高了网络的多尺度特征提取能力。
(2) 在下采样阶段使用CoT模块 [25] ,生成临近间上下文信息和全局上下文信息,从而增强模型的视觉表达能力。
(3) 构建了一个实时的三分支语义分割网络,没有使用预训练的情况下在Cityscapes数据集上以76.5 FPS的速度取得了78.6%的IMoU。
2. 相关工作
实时语义分割网络由于其在实际应用中的需求日益增长而备受关注。为了在推理速度和准确率之间取得平衡,许多研究都做出了贡献。下面按照三个方面来介绍以前的工作。
2.1. 基于编码器–解码器结构的语义分割
一些方法选择了经典的编码器–解码器架构作为其主要框架。这些方法通过逐层下采样和特征融合操作来提取语义特征,有效地结合了低级细节和高级语义信息。例如,SGCPNet [1] 提出了空间细节引导的上下文传播策略,在解码器阶段利用空间细节来引导低分辨率全局上下文的传播,有效地重建丢失的空间信息。ESPNet [19] 采用了不同扩张率的并行卷积,以此来扩大感受野,提升解码器的效率。EDANet [20] 提出的EDA模块通过在较大的区块内更紧密地连接输入图像和输出特征,实现了在更广泛的接收范围内共享信息。DFANet [21] 通过深度多尺度特征聚合和使用轻量级的深度可分离卷积,有效地细化了高级和低级特征。虽然这些方法在实现了较好的分割精度,但它们在处理高分辨率输入图像时,大多数仍面临着较慢的推理速度的挑战。
2.2. 基于多分支结构的语义分割
与编码器–解码器结构方法不同,多分支结构通过独立提取不同尺度的特征来保留网络早期提取的高分辨率细节以及网络后期提取的上下文信息。BiSeNet [13] 提出了一种由上下文分支和空间信息分支组成的双分支架构。上下文分支基于一个预训练主干提取上下文信息,空间信息分支利用几个卷积层来关注空间细节。此后,BiSeNetV2 [17] 进一步简化了网络结构。提出双边引导聚合取代BiSeNet [13] 中的特征融合模块,设计了完全手工化的语义分支。所有这些努力都提高了网络的效率。然而,分支之间缺乏有效的特征交互,部分导致了准确率的下降,所有的特征都在网络的末端融合,形成了新的瓶颈。因此,Fast-SCNN [14] 和DDRNet [16] 采用了共享骨干网架构。它们从一个分支开始构建网络,然后分成两个具有不同分辨率的平行深分支。这种设计在网络早期共享部分网络参数,允许他们在网络中间添加许多交互。PIDNet [15] 建立与PID控制器的联系提出了三分支结构,三个分支来分别解析细节、上下文和边界信息,并利用边界关注来指导细节和上下文分支的融合。实现了推理速度和精度之间的最佳权衡。
2.3. 基于注意力机制的语义分割
注意机制用于解决神经网络的局部问题,它可以将局部信息与全局信息联系起来,选择需要更多注意的信息。SENet [28] 使用了通道注意力显式建模通道之间的相互依赖性来自适应地重新校准通道方面的特征响应,提高了网络的特征表示能力。DANet [22] 使用了双重注意力,使用位置注意模块来聚焦空间信息,使用通道注意模块来关联通道信息。Jin等人 [24] 提出注意力引导多模态交叉融合模块(ACFM),在多阶段利用融合的增强特征表示。此外,受自注意力在各种自然语言处理任务中不断取得成绩的启发,研究界开始更多地关注视觉场景中的自我关注。FANet [23] 提出了快速空间注意力,这是对自注意力机制的一种简单而有效的修改,通过改变操作顺序,以很小的计算成本捕获相同的丰富空间上下文。CoTNet [25] 使用了上下文变换器,充分利用输入键之间的语义信息来引导动态注意矩阵的学习,促进了远程依赖关系的建模,从而增强了视觉表征能力。
3. 方法
在本节中,将详细说明我们工作的细节。图1解释了我们网络的构造。每个组件的详细描述如下。
3.1. 语义分割模型整体架构
图1是我们提出的网络模型框架总体结构,首先,通过一个共用的快速下采样阶段将输入图像下采样8倍,然后分别引出三个分支,空间信息分支、上下文信息分支、边界信息分支。空间信息分支通过残差基本块和残差瓶颈块提取图像的空间特征,强调物体的形状和大小等细节信息。上下文信息分支使用了残差U块来获取多尺度特征,以及利用上下文变换器模块(CoT)来增强全局依赖建模的能力,这对于理解图像中的整体结构和关系至关重要。边界信息分支则侧重于提取精确的边界信息,这对于在复杂场景中区分相邻的物体非常有用。在网络结构中,不同分辨率的特征图通过级联(Concat)操作进行合并,并在合并前后都使用CoT模块处理以增强特征表达。此外,网络还引入了多尺度损失计算,通过在不同的分支上附加辅助分类器,并计算与真实标签的损失值,分别对应不同类型的信息和分割任务的需求。这种多尺度监督的方法有助于在训练过程中提供额外的梯度信息,从而促进网络在各个层次上的学习。最后,三个分支在网络的末端进行整合,输出精细的分割结果。通过这种多分支结构设计,旨在有效地结合多种类型的信息,以提高在复杂城市道路场景中的分割任务的性能,确保高精度和高效率的模型运行。接下来,我们将详细描述残差U块、上下文变换器模块、损失函数。
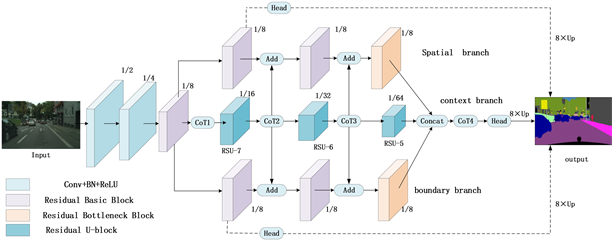
Figure 1. Network architecture overall structure diagram
图1. 网络架构总体结构图
3.2. RSU模块
残差U块结合了ResNet的残差连接思想和U-Net的对称扩张路径结构。它由编码器(收缩路径)和解码器(扩张路径)两部分组成,编码器用于捕捉图像的上下文信息,而解码器则用于精确地定位和恢复图像的详细信息。每个残差U块内部都包含残差连接,这些连接允许梯度直接流向前面的层,从而缓解了深度网络中梯度消失的问题。
在网络中的上下文信息分支中,我们引入了U2-Net [26] 的剩余U块。RSU模块是高度为L的类似U-Net [27] 的对称编码器–解码器结构,RSU-L (L = 7) 的结构如图2所示,其中L为编码器的层数,Cin为输入通道,Cout输出通道,M为RSU内部各层的通道数。RSU主要由3个部分组成。
的结构如图2所示,其中L为编码器的层数,Cin为输入通道,Cout输出通道,M为RSU内部各层的通道数。RSU主要由3个部分组成。
(1) 输入卷积层,它将输入特征
转换为具有Cout通道的中间映射f(x),这是一个用于局部特征提取的普通卷积
(2) 高度为L的类似U-Net的对称编码器-解码器结构,以中间特征映射f(x)为输入,学习提取和编码多尺度上下文信息
。U表示U-Net型结构,L越大,剩余U块越深,池化操作越多,接受域范围越大,局部和全局特征越丰富。
(3) 残差连接,通过求和
融合局部特征和多尺度特征。对于任意RSU尺度,输入特征映射和输出特征映射具有相同的分辨率。在上下文信息分支中,我们线性堆叠了3个不同大小的RSU模块。因此,我们的上下文信息分支由3个阶段组成,每个下采样阶段由一个配置良好的RSU块填充,L的尺度为
。每个RSU块后连接一个步幅为2的最大池化层进行下采样。
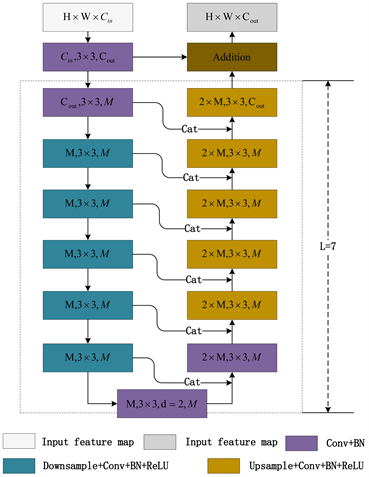
Figure 2. Residual U-block structure diagram
图2. 残差U块结构图
3.3. 上下文变换器模块
CoT模块是对Transformer的改进,传统的Transformer结构通过直接在特征图上使用自注意力来获得基于每个空间位置的独立查询键对的注意力矩阵,但未充分利用相邻键之间的丰富的上下文信息,这限制了在二维特征图上的自注意学习能力。并且只使用卷积的话全局建模能力又受到限制。因此引入了CoT模块,该模块既结合自注意力机制的优点,又利用了相邻键之间的丰富上下文信息。CoT模块的结构如图3所示,首先通过k × k的卷积操作对输入键的局部信息进行提取,这样就可以得到Key邻近键的静态上下文信息K1。具体操作如公式(1)所示:
(1)
其中ReLU表示ReLU激活函数,BN表示批量标准化,
表示卷积核为k的卷积操作。X为输入特征。
随后键Key经过编码后生成的静态上下文特征信息K1与输入查询Query连接,并通过两个连续的1 × 1卷积获取动态注意力矩阵A,具体操作如公式(2)所示:
(2)
然后将学到的注意力矩阵A乘以输入值value以实现输入特征图的动态上下文表示K2。具体操作如公式(3)和(4)所示:
(3)
(4)
最后将静态上下文信息K1与动态上下文信息K2融合作为最终输出。这种设计结构充分利用了Key的上下文信息,增强了模型的视觉表达能力。最后通过邻近键上下文信息与全局上下文信息的融合得到输出结果。具体如公式(5)所示:
(1)
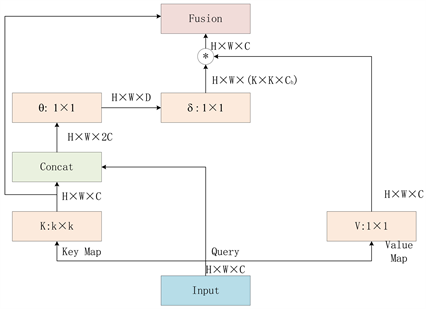
Figure 3. Contextual transformer structure diagram
图3. 上下文变换器结构
3.4. 损失函数
本模型中采用了一种复合损失函数,空间分支的第一个特征融合后的输出处放置了一个语义分割头,采用交叉熵损失函数l0对空间信息分支的输出进行优化,从而更好地加强整个网络的空间信息特征。对上下文信息分支的输出采用交叉熵损失l1进行优化,来获取更精确的上下文信息。在边界信息分支采用加权二元交叉熵损失l2来处理边界不平衡问题,因为对于小物体,粗糙的边界更容易突出边界区域。最后利用l3的边界感知交叉熵损失和边界头的输出来协调语义分割和边界检测任务。损失函数计算可以写成如(6)所示:
(6)
其中N是样本数量,C为总类别数,yi,c是一个指示变量,表示样本i是否属于类别c (如果像素i属于类别c,则yi,c = 1,否则,yi,c = 1,
表示模型预测i像素属于c类的概率。
(7)
其中N是样本数量,yi是第i个像素的真实标签,
表示模型预测i像素为正类的概率。
(8)
其中t为一个预定义阈值,本文中设置成0.8,bi表示像素i为c类的边界头输出,yi,c表示第i个像素为c类的分割标签,
为上下文信息分支分割第i个像素为c类的预测结果。
(9)
公式(11)表示模型总体的损失函数,其中
。
4. 实验
我们在Cityscapes和CamVid数据集上进行了实验。首先介绍数据集和实现细节。接下来,在Cityscapes验证集以及CamVid测试集上,将本文提出的方法与其他方法进行了比较。
4.1. 数据集和验证指标
Cityscapes是侧重于从驾驶角度对城市街道场景的语义理解。将该数据集的精细标注图像分为训练集、验证集和测试集,分别为2975张、500张和525张。所有的图像都是1024 × 2048的分辨率。在我们的实验中,我们按照19个语义类别标准,而不是原来的34个类别。我们只使用精细标注的图像来训练和验证我们的网络。
CamVid (Cambridge-drivingLabeled Video Database)也是一个用于实时语义分割的街景数据集,它包含701个密集标注的图像,每个图像的分辨率为720 × 960。这些图像分为367个训练图像,101个验证图像和233个测试图像。CamVid有32个类别,其中有11个类别的子集用于分割任务。
对于实验中涉及的所有方法,以及本文提出的方法,我们都采用了均交并比(MIoU)和每秒帧数(FPS)作为评价指标。
4.2. 实验设置
由于我们的模型没有使用预训练,我们需要在Cityscapes训练集上从头开始训练我们的模型。我们选择的优化器是SGD算法,动量设置为0.9。在Cityscapes数据集上,我们随机裁剪输入图像到0.5到2倍分辨率大小,批处理大小设置为12,对于学习率,我们使用0.01作为初始设置,5e−4作为优化器中的权重衰减。训练轮数的设置为600,以使模型能够充分学习。在CamVid数据集上,批量大小设置为12。由于缺乏足够的训练图像,我们设置0.005为初始学习率,5e−4为权值衰减。此外,使用在Cityscapes预训练的模型,训练轮数设置为300,以避免训练集上的过拟合。
4.3. 对比实验
在上面描述的实验配置中,我们将我们的网络与以前的实时方法进行比较。所有在Cityscapes上评估的方法都使用1024 × 2048的分辨率。表1显示了每种方法的模型信息,包括mIoU、GPU设备和FPS。其中一些方法我们遵循其原始训练设置并评估其在我们设备上的性能,用符号*标记它们。其他数据均摘自上述方法的原始论文。实验结果表明,我们的网络具有较好的效果。

Table 1. Cityscapes data set results
表1. Cityscapes数据集结果
在CamVid数据集上对我们的方法进行了测试(见表2)。所有在CamVid上评估的方法都使用了960 × 720的原始分辨率,与表1相同,符号*表示我们在设备和环境设置上复现的结果。在CamVid数据集上的实验结果表明,我们的方法也取得了很好的性能。
Table 2. CamVid data set results
表2. CamVid数据集结果
4.4. 可视化结果
本文提出的模型在Cityscapes上的分割效果如图4所示。三列图像是分别是初始图,标签图和模型的分割效果图。在本文模型输出的分割图上对不参与分割的类进行了屏蔽。
5. 结束语
本文提出了一种基于残差U块和上下文变换器的三分支实时语义分割网络,在保证分割准确度的同时兼顾了实时性,上下文路径的RSU模块和CoT模块可以获取丰富的上下文信息以及建立全局依赖。实验表明我们的方法在两个流行的基准测试中取得了具有竞争力的结果。