1. 引言
随着互联网和大数据等技术持续发展,这些技术也逐步渗透到人们的生活中,带给人们良好的使用体验,其中推荐模型无时无刻不发挥着作用。新闻推荐可以帮助用户从海量新闻中推送其感兴趣的新闻,提高了时间利用的效率。目前,新闻推荐已在改善用户阅读体验方面取得显著的效果,引起学术界的广泛关注 [1] [2] 。
之前的新闻推荐算法可分为基于协同过滤的推荐算法、基于内容的推荐算法、混合推荐算法 [3] [4] 。然而,这些方法存在冷启动问题,当用户–新闻矩阵稀疏时,推荐结果往往不够准确。近年来,基于深度学习的方法在建模用户–新闻交互方面表现出更好的能力 [5] [6] [7] ,并广泛应用于新闻推荐领域。其中,通过引入图神经网络来建模用户和新闻之间的交互,GNewsRec [8] 成为了目前较先进的新闻推荐方法。然而,该方法仍存在两个主要缺点。首先,它们通常只考虑新闻标题和新闻概要作为新闻推荐的特征,忽略了用户在页面上停留的活跃时间,而这个时间能更好地反映用户的兴趣。其次,GNewsRec模型通过图神经网络聚合获取用户长期偏好和候选新闻表达时只采用了平均的聚合方法,忽略了用户与用户之间的交互。最后,获取用户偏好时只是简单的将短期兴趣和长期兴趣串联在了一起,忽视了长短期兴趣对用户有不同的影响力。
本文的研究工作受到以下观察结果的启发。首先,用户对新闻文章的兴趣可以通过他们在新闻页面上停留的时间来直接反映。如图2所示,用户“cx:i8i85z793m9j”在新闻页面“阿根廷爆冷输沙特”停留了116秒(525个字),而在新闻页面“日本球迷走后的观众席”停留了15秒(534个字)。我们认为用户更偏好前一条新闻。因此,我们在新闻编码器中引入了时间权重。其次,图神经网络中的用户节点之间可能存在相似的兴趣,而取平均值的聚合方法往往忽略了这一信息。为了更好地表示用户的长期兴趣,我们在聚合过程中计算了节点之间的相似度。此外,将用户短期兴趣和长期兴趣分开与候选新闻进行相关性计算,旨在自适应地调整用户建模中短期兴趣和长期兴趣的重要性。
针对上面的想法本文提出了一种时间敏感的异构图相似神经网络(TSHGSN),旨在通过新闻点击行为和新闻阅读行为来建模用户的兴趣。首先在采用CNN [6] 对新闻进行编码提取新闻特征表示,并引入阅读时间权重。接着使用基于注意力的LSTM模型 [9] 获取用户短期兴趣。然后构建一个用户完整点击新闻历史的用户–新闻–主题异质图,其中主题信息可以缓解用户–新闻交互的稀疏性问题 [10] 。异质图构建完毕后,使用节点相似的采样方法获取用户长期偏好和候选新闻表示。最后,分别采用不同的评分规则计算候选新闻与用户长期兴趣和短期兴趣之间的匹配程度。
2. 方法
2.1. 新闻推荐问题的定义
针对TSHGSN模型,本文给出相关定义如下:给定用户集
,新闻集
,k和m分别表示用户和新闻的数量。根据用户点击历史,用户浏览新闻的记录
,其中
表示用户u所点击的第j条新闻。令
表示用户U和新闻集I之间的用户-新闻交互矩阵,其中
表示用户u点击了新闻d,否则
。
本文与GNewsRec一致,都从新闻的标题和内容(包括新闻实体和实体类型)中提取新闻特征。每个新闻标题T都由一系列单词组成的
,其中wi表示新闻标题T中的第i个单词。新闻内容包括新闻实体
以及实体类型
,其中cj是第j个实体ej的类型,n表示实体的个数。
2.2. 方法总体框架
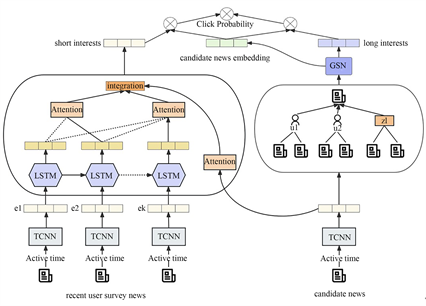
Figure 1. The overall framework of the proposed model
图1. 所提出方法总体框架
本文基于GNewsRec模型,提出TSHGSN模型,模型框架如图1所示。在图1中,TSHGSN包括新闻编码器,用户短期兴趣建模,用户长期兴趣建模和感知预测四个模块。新闻编码模块使用卷积神经网络从新闻标题、新闻实体、实体类型和用户阅读新闻时间提取新闻特征。用户短期兴趣模块使用基于注意力机制的LSTM根据最近点击新闻历史获取用户短期兴趣。用户长期兴趣模块在构建用户–新闻–主题异质图后,利用GNN网络采用节点相似的聚合方法以获取用户长期兴趣和候选新闻表示。感知预测模块将用户短期兴趣和长期兴趣分开与候选新闻进行相关性计算,旨在自适应地调整用户建模中短期兴趣和长期兴趣的重要性。
2.3. 新闻编码器
在新闻特征提取部分,在GNewsRec新闻编码器的基础上加入了用户阅读新闻时间权重。
将新闻标题的单词放入词矩阵中来获取新闻标题的嵌入表示
(1)
其中,wi表示新闻标题T中第i个单词的嵌入向量,k1是词矩阵的维度。新闻实体的嵌入表示
(2)
新闻实体类型的嵌入表示
(3)
其中,ej表示第j实体的嵌入向量,cj表示与其对应实体类型的嵌入向量,k2,k3分别表示新闻实体及实体类型的词矩阵嵌入维度。因为新闻实体及类型的对应关系,将两者拼接起来,得到的新闻内容特征表示
(4)
其中,f(c) = Wcc表示转换函数,,
表示可以训练的矩阵。
此外,新闻页面上的用户的活动时间
,隐含地反映了用户对新闻的兴趣。因此,我们将用户在新闻上的活动时间作为输入的额外权重,标题嵌入可以表示为
(5)
其中,*表示元素间乘积。新闻内容的特征表示
(6)
分别将加入阅读时间的新闻标题词矩阵
和新闻内容词矩阵
送入两个具有独立权重参数的CNN中,并行卷积后得到它们的深层特征表示
和
并连接作为最终的新闻文本特征表示
(7)
其中,
,D表示新闻特征表示向量d的维度,fc表示一个紧密连接层。
2.4. 用户短期兴趣建模
用户在阅读新闻的时,可能会被某些新闻暂时吸引。图2是某用户在一段连续时间内的点击新闻序列,用户在时刻
阅读一篇关于“卡塔尔世界杯开幕”的新闻,后续就会持续关注世界杯的赛事,显然该用户暂时被世界杯事件吸引,即用户的短期兴趣。

Figure 2. Title sequence of news read by user
图2. 用户阅读新闻标题序列
用户对于不同新闻的兴趣是不同的(如图2所示点击了阿根廷相关的新闻就有三次),给定一个用户u,在l最近时间点击新闻
,使用一个注意机制来赋予不同用户最近点击的新闻对候选新闻d的权重:
(8)
(9)
(10)
(11)
其中uc是用户整体兴趣嵌入,αi为点击新闻
对候选新闻d的影响权重。
是新闻的嵌入维度。
应用注意机制对用户当前整体偏好进行建模后,仍关注用户点击新闻的顺序对用户偏好的影响,基于此通过基于注意的LSTM [11] 来捕获用户点击新闻的顺序特征来捕获顺序特征。
在图1中,整个左侧模块是用户的短期兴趣,本文将用户最近所点击的新闻表示按顺序输入到LSTM中,以获取用户点击新闻的顺序特征。由于每个用户的当前点击行为,可能会受到先前点击新闻的影响,将上面提到的新闻内容注意力机制应用于每个隐藏状态hi及其以前的隐藏状态
的LSTM,获得在不同点击时间更丰富的顺序特性表示
。这些内容
由CNN集成所获得的,由此得到用户点击新闻的顺序特征表示
。将用户整体兴趣嵌入和顺序级嵌入的串联,得到最终用户的短期兴趣嵌入:
(12)
2.5. 用户长期兴趣建模
在GNewsRec的基础上,本文亦利用异质图捕捉用户和新闻之间的高阶关系 [10] 。同样采用LDA [12] 算法将新闻进行主题分类,根据用户完整点击新闻历史完成用户–新闻–主题异质图的构建,最后利用图相似神经网络(GSN)学习用户和新闻节点的高阶嵌入表示。
通过GSN计算以用户为中心节点的一般步骤如下。在聚合前,新闻已加入阅读时长权重,由于用户和新闻节点之间都是有一定的相似性的,因此如图3所示,此处采用了节点相似的邻居采样方法:
(13)
(14)
其中用户u是通过公式(11)初始化的,N(u)表示与用户直接相连的新闻,αj表示邻居节点和中心节点的余弦相似度。
然后通过邻居节点嵌入对用户长期兴趣嵌入进行更新:
(15)
其中
和
分别表示GSN第一层的转换权重和偏置。
为了表示新闻d,首先计算邻居采样的相似度权重:
(16)
(17)
其中
新闻相邻用户的向量表示,包括用户u和主题z,其中用户u是通过公式(11)初始化的,新闻的主题z是随机初始化的,而d是用新闻编码器生成的,
表示邻居节点和中心节点的余弦相似度。为了保持每批的计算模式固定和更有效,对每个新闻d统一采样一组大小固定的邻居S(d)。
然后用dN更新候选新闻表示:
(18)
其中
和
分别表示GSN第一层的转换权重和偏置。
如图4所示,绿色部分是单层GSN的聚合过程,候选新闻仅聚合最近节点。为了捕捉用户和新闻之间的高阶关系,GSN可以从一层扩展到二层,更加丰富节点信息。如图4所示,结合灰色部分就可以得到二层GSN后的新闻表示。首先,通过聚合相邻的新闻嵌入来得到与它直接连接的用户嵌入ul和主题嵌入z,然后将聚合得到的嵌入ul和z聚合以获得两层GSN的新闻表示。一般来说,第一层GSN的新闻表示是初始化用户节点和主题节点的混合产物,直到第二层GSN才更为准确。
2.6. 感知预测
GNewsRec模型中是将长期和短期兴趣串联起来和候选新闻进行相关性计算的,但是用户长期和短期兴趣对候选新闻的影响可能并不相同。因此,本文提出了将用户的长期和短期兴趣分开和候选新闻进行相关性的计算,如此可以更准确地预测用户对新闻的点击。首先计算候选新闻嵌入
和用户的长期兴趣嵌入ul之间的相关性:
(19)
再计算候选新闻
和用户短期兴趣us之间的相关性:
(20)
统一的点击分数
为两个分数的线性组合
(21)
其中α为一个可学习的参数。
为了训练模型TSHGSN,正样本为用户点击过的新闻,负样本在用户未点击的新闻中随机选择。一个训练样本被表示为X = (x,u,y),其中x是预测是否点击的候选新闻。对于每个正输入样本,则为y = 1,否则为y = 0。在训练模型时,每个负样本的阅读时间权重为−1。在测试模型时,正负样本的阅读时间权重均为训练的模型的阅读时间的平均数。训练模型时每个输入样本都有一个各自的估计概率
Î[0,1],表示用户是否会点击候选新闻x,使用交叉熵损失作为的损失函数:
 (22)
(22)
其中,||W||2是对所有可训练参数的L2正则化,l为惩罚权重,D+是正样本集,D−是负样本集。此外,我们还采用了退出和早期停止,以避免过拟合。
3. 实验及分析
3.1. 数据集
本文在一个真实的在线新闻数据集Adressa [13] 上进行实验,这是一个点击日志数据集,大约有2000万次页面访问,以及一个270万次点击的子样本。
数据集的情况如表1所示,Adressa分为2个数据子集:Adressa-1week和Adressa-10weeks。分别包含Adressa一周和十周的数据。Adressa是一个基于事件的数据集,然而并不是所有事件包含新闻阅读时间,本文使用如下7个属性:会话开始、会话结束、用户ID、新闻ID、阅读时间、标题和概要文件,用于生成数据集。
将新闻按发布时间进行排序,训练Adressa-1week数据集时,将前5天的历史数据用于构建异质图,训练集第6天的历史数据,验证集为第7天的20%,测试集为剩余的80%的数据。训练Adressa-10周的数据集时,将前50天的数据构建异质图,训练集为的51~60天的数据,验证集为61~62的数据,测试集为最后8天。

Table 1. Description of experiment datasets
表1. 实验数据详细信息
为了减少文本数据噪声,在放入词矩阵前:通过挪威语停顿词文档从新闻标题中删除无用的停顿词,并去除新闻概要文件中的无意义实体和实体类型。
3.2. 实验环境和结果对比
与GNewsRec模型一致,本文亦采用AUC和F1作为评价指标。模型中新闻标题、实体及实体类型的词矩阵维度k1、k2和k3均设置为50,新闻、用户和主题的词向量嵌入维度均设为128,用户短期兴趣模块里点击的新闻数m设为10。在异质图中LDA中主题数与GNewsRec一致设为20,聚合用户节点时Lu设置为10,聚合新闻节点时Ld设置为30。本文高斯分布进行随机初始化参数,其中高斯分布均值设为0、标准差设0.1,并采用学习率为0.0003,失活率为0.5的Adam [14] 对参数进行优化。模型在训练过程中,采用验证集进行验证。上述参数是根据模型在验证集上性能最优时确定的,保留在验证集上最优的模型,并在测试集上进行测试。
为了验证模型的性能,选择如下经典的推荐算法与近期效果突出的新闻推荐算法进行对比实验。
(1) Wide & Deep (Wide & Deep Learning for Recommend Systems) [15] 经典推荐模型,同时兼顾记忆和泛化能力,既可以利用广义线性模型来记忆历史数据的模式,又可以利用深度神经网络来学习数据的抽象特征表示,从而提高推荐系统的预测准确性和推荐效果。
(2) DeepFM (Factorization-Machine Based Neural Network) [16] 经典推荐模型,由线性模型和深度学习两个模块组成,结合广度和深度将FM和神经网络相结合用于推荐模型。
(3) DKN (Deep Knowledge-Aware Network for News Recommendation) [5] 经典新闻推荐模型,提出用并行CNN提取新闻特征和实体,并使用AM提取用户的整体偏好。
(4) DAN (Deep Attention Neural Network for News Recommendation) [6] 基于深度注意力神经网络,将新闻标题和新闻实体及类型通过CNN并行提取,并根据用户点击历史使用注意力机制获取用户整体偏好,同时使用基于注意的LSTM获取用户时序偏好。
(5) GNewsRec (Graph News Recommendation with Long-term and Short-term Interesting Model) [8] 结合用户长期短期兴趣,基于图神经网络构建用户长期兴趣,采用LSTM结合注意力机制建模用户短期兴趣,串联用户长期兴趣和短期兴趣形成用户的最终表示。
(6) GNUD (Graph Neural News Recommendation with Unsupervised Preference Disentangle) [17] 在新闻–用户图结构的基础上,加入偏好解缠正则化以动态识别用户点击新闻的偏好因素,进一步提高模型性。
各模型在两个数据集上的指标值对比结果如表2所示,可得出如下结论:(1) 经典推荐模型在小数据集上的表现普遍不如新闻推荐模型,可是新闻推荐模型都加入了注意力机制的缘故,可以更加准确的表达用户的偏好。表中,新闻推荐模型在大数据集上的性能均低于小数据的性能,可能是大数据记录的用户10周阅读的新闻,由于新闻的时效性,时间较久的新闻可能会对用户兴趣建模造成干扰。(2) 相比于其他模型TSHGSH各项指标值均最高。这主要是由于本文同时考虑了用户点击行为和用户阅读行为来提取深度新闻表示,利用GNN在聚合时采用邻居相似的聚合方法的结果。
Table 2. Performance comparison of different models
表2. 个模型对比
3.3. 参数影响分析
本节进行多次实验,以验证参数对实验结果的影响,在Adressa-1week、Adressa-10weeks数据集上分析模型中训练集负样本阅读时长参数对实验结果的影响和GSN层数对实验结果的影响。
Table 3. Experimental results of different negative sample reading time values
表3. 不同负样本阅读时间取值
Table 4. Experiment results of different GSN layers
表4. 不同GSN层数实验结果
训练集负样本的不同阅读时长对实验结果的影响如表3所示,由表3可看出,本文测试了三个常用参数分别是0.00001,0,−1。当参数0.00001和0时,卷积后由于常量参数b的影响,对最后模型训练结果还是有一定的干扰。当参数为−1时,卷积后加上常量b时,负样本的结果接近于0,干扰最小并且AUC和F1表现最优。不同GSN层数对实验结果的影响如表4所示,由表4可看出,本文将GSN层数分别设置为1、2、3,当GSN层数为2时,两个评价指标效果最优。这是因为一层GSN只是初始化节点聚合的混合物,而三层GSN可能会给模型带来更多的噪声影响模型的性能。

Figure 5. Variation curve of learnable parameter α
图5. 可学习参数α变化曲线
学习参数α的变化曲线如图5所示。由图可知,当α = 0.85在验证集上效果最优。这说明用户长期兴趣在用户兴趣建模中占主导作用,用户短期兴趣在用户兴趣中起到补充作用。
3.4. 消融实验分析
本节为了验证各模块的有效性进行消融实验,定义如下三个子模型。
1) TSHGSN−time表示从TSHGSN模型里去掉新闻阅读时间
2) TSHGSN−short表示从TSHGSN模型里去掉短期偏好
3) TSHGSN−GSN表示用普通的平均邻居采样方法
各模型在Adressa-1week和Adressa-1week实验的指标值如表5所示,表中黑色字体为最优值。由表5可看出,当TSHGSN删除阅读时长的权重后,AUC和F1出现大幅下降,这说明阅读新闻时长可以有效表达用户的阅读满意度,能够提高推荐的准确性。当TSHGSN删除用户短期兴趣建模模块后,AUC和F1下降约2%,这表明用户短期兴趣建模模块的有效性,应同时考虑用户的长期兴趣和短期兴趣。当TSHGSN删除GSN后,使用平均的聚合方法时,AUC和F1下降了1%,这验证GSN对TSHGSN的提升效果。综上可见,本文提出的各模块均是有效的。
Table 5. Result of ablation experiment
表5. 消融实验结果
4. 总结
本文提出基于时间敏感的异质图相似神经网络的新闻推荐模型。TSHGSN算法使用卷积神经网络(CNN)学习新闻特征,并结合用户阅读新闻的时间权重,利用长短期记忆网络(LSTM)学习用户点击新闻的序列特征,以捕捉用户的短期兴趣。同时,构建了一个异构图,并使用节点相似性的方法来聚合节点,获取候选新闻特征表示和用户长期兴趣。最后,用户短期兴趣和长期兴趣与候选新闻分开比较,旨在自适应地调整用户建模中短期兴趣和长期兴趣的重要性。经过对比试验,证明了其在推荐任务上的优异表现。此外,还进行了多个消融实验以检验模型中某些组件的有效性,并分析了不同参数值的设置对算法效果的影响。今后将考虑引入图注意网络,提高新闻推荐的准确性。
基金项目
国家自然科学青年基金项目(61602323)。
NOTES
*通讯作者。