1. 引言
随着京津冀协同战略等国家战略的实施,物流市场也迎来发展机遇。随着人们对食品安全健康的进一步关注,互联网 + 物流的不断融合,现有的物流产业机构和供应链已经逐渐暴露出诸多问题。京津冀农产品的发展已经不能满足消费者个性化和多样化的需求,也不符合国家降本增效的要求。因此,寻求更高效的京津冀农产品物流成为研究的必然方向。农产品物流在流通的过程中涉及的环节多,流量大,影响需求的因素多,数据繁杂,洪玉兰(2010) [1] 等人针对我国农产品冷链物流流通率差,损耗大等特点,探讨了我国农产品冷链物流未来的发展方向。如何有效的提高数据的价值也成为重中之重,因此,如何在这种环境下分析影响农产品物流需求的关键因素,对其农产品物流需求进行合理的预测,对助力加快京津冀农产品物流的全面发展、保障食品安全有着重要的价值。大数据的快速发展提供了有利的研究环境。
本文研究基于大数据的京津冀农产品物流需求问题的解决方案,含三个子模块,即通过构建大数据画像,建立农产品物流指标体系、设计基于大数据和多种方法融合的模型、利用模型对农产品物流需求进行预测和结果分析并提供可行性建议。
2. 研究方法和数据选择
2.1. 研究方法
2.1.1. 大数据
农产品物流需求是个复杂的系统,包含多种影响因素,包括确定性的和不确定性的,因此想要对农产品物流的需求进行合理较准确的预测,需要找到各种影响因素。大数据有其天然的优势可以利用,大数据技术是从大量的、不完全的、有噪声的、模糊的、随机的数据中利用人工智能、机器学习、统计学等技术提取隐含在其中人们未知但又是潜在有用的信息和知识的工具,建立在大数据的分析结果上,可以进行目标的预测,发挥大数据在物流需求领域的价值。大数据画像是根据这些不规则的海量的数据来完成对对象的详尽标签化描述,可视化地展示出最主要的特征,通过关键信息的抓取,可以获取进行需求预测的指标。京津冀可以看作是一个整体,通过对京津冀的大数据画像,了解京津冀地区最主要的特征,从而获取农产品物流的指标,通过对大量数据进行分析,不仅仅可以对影响农产品的关键因素进行分析,还可以预测农产品物流需求的具体数量,增加预测的全面性和准确性。
2.1.2. 因子分析方法
因子分析是主成分回归的扩展,是一种相关分析技术。因子分析是希望能够降低变量的数目,并在一群具有相关性的数据中,转换为新的、彼此独立、不相关的新因子 [2] 。因子分析的实质是用几个潜在的但是不能观察的互不相关的随机变量,研究很多变量之间的内部依存关系,找到数据的基本结构去描述许多变量之间的相关关系 [3] 。因此,从反映某些对象的多个变量中,提取几个公因子,利用这些公因子解释影响研究对象的主要因素,同时又简化了数据结构。
2.1.3. 多元回归分析
多元线性回归模型可以分析众多因素对因变量的影响程度,通过检验判定方程的显著性等,并可以利用逐步回归思想进行模型的修正,保证模型的科学性和实用性。刘宇等(2014) [4] 文中对茶陵县2001年至2012年的GDP、区域消费品零售总额等指标进行分析,构建多元线性回归模型对茶陵县全部客货周转量进行预测,说明了线性回归模型的准确性、有效性。
综合对比分析,确定本文选用多元线性回归方法构建模型,通过因子分析调取主成分之后,从9个指标中选取合适的因子个数作为自变量构建京津冀农产品物流需求的多元线性回归模型,将对应的统计数据输入SPSS统计工具进行分析,并根据分析结果对多元线性回归方程进行修正改进。
2.2. 数据选择
农产品物流需求量的衡量需要一个明确的指标来刻画,对于指标选取,由于没有统一的物流需求的衡量标准,所以通常情况下文献对这一指标的衡量借助间接因素来度量,研究集中在货运量、产品产量和物流总额上。邱慧等(2016) [5] 指出选取货运周转量为特征因素,人均生产总值为其相关因素,利用灰色预测模型GM(1, 2)模型,对山西省未来3年的物流需求进行预测。李夏培(2017) [6] 以北京市农产品物流需求为研究对象,用农产品物流总额表示北京市农产品物流需求,进行单因素分析,预测了“十三五”时期北京市的农产品物流总额。
通过查询国家数据和相关行业大数据报告 [7] [8] [9] ,总结出京津冀地区的大数据画像,如图1所示。可以看出,京津冀地区的政策和经济水平发展有利于发展高水平物流的条件;京津冀地区人口特征以及收入消费水平促进消费升级,支撑网购的繁荣,农产品物流的消费也会大幅提升;物流水平的发展虽居于全国平均水平,但还需要满足进一步的优化。
本文借鉴前人研究的成果,根据相关学者的研究和文献资料的参考,结合京津冀大数据画像所展示的物流发展现状和农产品物流需求影响因素的分析,初步确定的物流需求影响因素如表1。
3. 模型的建立和农产品物流需求预测
3.1. 模型的建立
因子分析是主成分分析的推广和发展,把多个因子转化为少数几个综合因子的一种因子分析方法,用观测变量来描述因子,第P个因子在i个个案上的值可表示为:
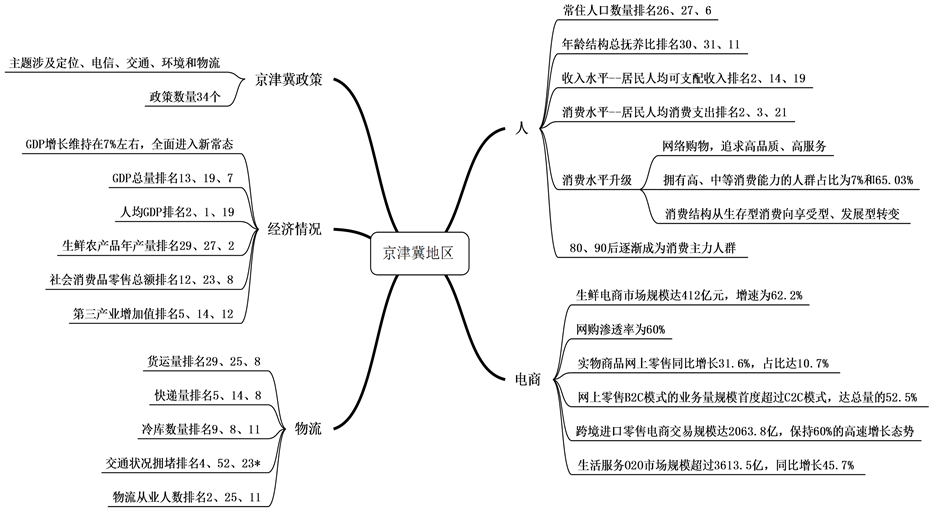 注:*表示河北省进入排名的有4个城市,此处选择最靠前的资料来源:国家统计局和相关行业报告
注:*表示河北省进入排名的有4个城市,此处选择最靠前的资料来源:国家统计局和相关行业报告
Figure 1. Big data portraits of the Beijing-Tianjin-Hebei region
图1. 京津冀地区的大数据画像

Table 1. Agricultural products logistics demand influencing factor index system
表1. 农产品物流需求影响因素指标体系
基于因子分析提取方法运行步骤如下:
1) 设观察到的随机向量为
,不可观察向量为
,则有:
其中
表示因子荷载,
表示误差因子,代表公因子之外的影响因素。
2) 如果因子荷载矩阵不能对主因子进行解释时,需要进一步做因子旋转,使影响因子具有高负载,使因子更加具有合理的解释。
3) 计算因子得分数学模型:
得到
,可以很好的代表原始因子的信息,将这些因子作为多元线性回归的自变量进行输入。
4) 利用SPSS19.0进行多元线性回归分析,建立冷链物流需求预测的多元线性回归模型,并对模型进行各种相关检验,即:
其中Y为因变量,其中
为自变量。
是p + 1个未知参数,
称为回归常数,
为回归系数,
是随机误差(残差)。
3.1.1. KMO和Bartlett的检验判断是否适合因子分析
由表2可知,球形度检验为0.654,接近0.7,非常适合做因子分析,也进一步说明需要去除共线性。
3.1.2. 提取因子
表3为因子分析中的变量共同度。提取的2个特征值的情况下,所有变量的信息丢失较少,因子提取的效果比较好。
通过表4因子解释原有变量总方差的情况。可以看到,第一个因子的特征值是7.6,解释原有9个变量总方差的84.447%,两个因子累计解释总变量的96.104%。在此,提取2个因子,计算因子荷载矩阵。
Table 2. KMO and Bartlett tests
表2. KMO和Bartlett 的检验
提取方法:主成份分析。
Table 4. Total variance of explained (part)
表4. 解释的总方差(部分)
提取方法:主成份分析。
表5显示了因子荷载矩阵,可见,各个变量中除了货运量,八个变量在第一因子的荷载很高,意味着它们与第一个因子的相关程度高,第一因子很重要,第二个因子与货运量相关性较强。因子荷载比较倾斜,考虑旋转后这两个因子的实际含义是否比较均衡。
3.1.3. 命名性解释
表6旋转成份矩阵为旋转后的因子荷载矩阵。采用极大方差法对因子荷载矩阵实行正交旋转以使得因子具有命名性解释。指定按第1个因子荷载降序的顺序输出旋转后的因子荷载,并绘制旋转后的因子荷载图,可见,第一个因子解释了除了货运量的其余变量,第二个因子解释了货运量,因子的含义比较清晰。表7成份得分协方差矩阵显示了两个因子的协方差矩阵。可以看到,两因子没有线性相关性,实现了因子分析的设计目标。
3.1.4. 计算因子得分
表8为因子得分系数矩阵。采用回归法估计因子得分系数,并输出因子得分系数,如表8,根据表8用两个成分解释了原来9个变量,可得因子得分函数:
3.1.5. 建立回归方程
根据因子得分表达式,计算F1、F2的因子得分,作为自变量,北京地区农产品物流需求量作为因变量,进行回归分析(如表9)。
回归后的方程式
,R方 = 0.902,F = 83.741,说明模型拟合很好,并得到了2006~2015年的预测值,预测值如表10。
3.2. 农产品物流需求预测
为了预测2016~2020年北京地区物流需求量,需要对相关经济变量的未来变化趋势进行分析,运用SPSS指数平滑法对变量进行预测,预测结果如表11。
把自变量的预测值带入因子回归模型,北京市的因子回归模型如下:
预测2016~2020年北京市农产品的物流需求量,预测结果如表12。
同理可得,京津冀地区的因子回归模型如下:
提取方法:主成份。a. 已提取了2个成份。
提取方法:主成份。旋转法:具有Kaiser标准化的正交旋转法。a. 旋转在3次迭代后收敛。
Table 7. Component score covariance matrix
表7. 成份得分协方差矩阵
提取方法:主成份。旋转法:具有Kaiser标准化的正交旋转法。
天津市:
河北省:
因此,京津冀地区农产品物流需求量预测值如表13。
Table 8. Component score coefficient matrix
表8. 成份得分系数矩阵
提取方法:主成份。旋转法:具有Kaiser标准化的正交旋转法。
Table 9. Regression equation variable of Beijing
表9. 北京地区回归方程变量
Table 10. Forecast of agricultural products logistics demand in Beijing from 2006 to 2015
表10. 北京地区2006~2015年农产品物流需求预测值单位:万吨
对于每个模型,预测都在请求的预测时间段范围内的最后一个非缺失值之后开始,在所有预测值的非缺失值都可用的最后一个时间段或请求预测时间段的结束日期(以较早者为准)结束。
Table 12. Forecast of agricultural products logistics demand in Beijing from 2016 to 2020
表12. 北京地区2016~2020年农产品物流需求预测值单位:万吨
Table 13. Forecast of agricultural products logistics demand in Beijing-Tianjin-Hebei region from 2016 to 2020
表13. 京津冀地区2016~2020年农产品物流需求量预测值单位:万吨
4. 预测结果与建议
4.1. 结果分析
研究京津冀农产品物流需求,首先以北京市的数据为例,选取了影响北京农产品物流发展的9个因素,利用因子分析方法选取了两个主成分,对北京农产品物流需求进行了因子回归模型分析,第一因子主要反映出社会经济发展水平影响,第二因子反映出物流水平影响。
分析结果显示,影响京津冀物流需求的关键因素是宏观经济和货运量,随着京津冀地区经济快速发展、人民生活水平的提高和消费的不断升级,京津冀农产品物流需求总体呈增长趋势。具体来说,到2020年,北京农产品的产量将会减少到429万吨,而河北和天津的产量将会有所增加,2020年河北的产量相对于2015年增长约为14%,天津增长幅度相对较大约为24%,这与北京定位为政治和文化中心,而河北为辅助地区的发展定位是一致的,这将为制定京津冀农产品物流发展战略、优化物流供给系统提供重要的决策依据。
4.2. 京津冀农产品物流发展建议
4.2.1. 遵循地区定位发展经济
京津冀整体定位是“以首都为核心的世界级城市群、区域整体协同发展改革引领区、全国创新驱动经济增长新引擎、生态修复环境改善示范区”。其中三省市定位分别为,北京市“全国政治中心、文化中心、国际交往中心、科技创新中心”;天津市“全国先进制造研发基地、北方国际航运核心区、金融创新运营示范区、改革开放先行区”;河北省“全国现代商贸物流重要基地、产业转型升级试验区、新型城镇化与城乡统筹示范区、京津冀生态环境支撑区” [10] 。北京、天津的发展离不开河北的支持,同样北京、天津巨大的消费群体给河北的农产品提供需求市场。北京应深入挖掘消费者的需求特点,河北应提供高质量的农产品满足高企的需求,做好自销与供给。
4.2.2. 大力发展物流和通信基础设施
十九大报告中将物流与水利、交通、电力等并列,要求加强基础设施网络建设,结合分析结果显示,经济因子比重较大,但同时物流发展水平不高,可见,要想提高农产品物流发展水平,要从硬件入手,完善物流通道,购置新型高科技物流设备,建立达标冷库等,更好的促进农产品物流的发展。
4.2.3. 提供高质量的物流服务
消费升级的情况下,消费者的个性化和多样化需求要求物流服务及时、安全、有效的送达,提高物流服务质量才能有利于扩大农产品的销售市场。在产品质量方面,精挑农产品品类并做到以全程冷链思维保障农产品新鲜度;在物流质量方面,开展送货上门,当面验收,货到付款等服务,更多体现差异化和人性化。