1. 引言
推荐系统 [1] [2] 可以从互联网上收集有关用户的偏好等信息,旨在为客户提供个性化推荐。推荐系统需要在较短时间内处理海量不同且稀疏的数据,矩阵分解 [3] [4] [5] [6] 技术已被证明对于实现推荐系统是有用且可靠的。随着网络的发展使得用户和条目激增,导致评分矩阵中数据极度稀疏,使得大多数现有的推荐模型准确性较差。在现实世界中,我们总会向信任的朋友寻求推荐,所以信任关系可以作为推荐的辅助信息来缓解评分信息的稀疏 [6] [7] [8] 。然而,很少有研究从信任与被信任信息这一角度去探讨用户间的关联。因此,本文基于矩阵分解方法,利用用户间潜在的信任与被信任信息,来提高推荐准确率。
在如今这个快节奏时代中,效率一词成为大家共同追求的目标,模型的时间效率已逐渐成为判断其性能是否优秀的标准之一。目前绝大多数的模型都通过随机梯度下降算法 [9] [10] [11] 等迭代学习算法 [12] 进行求解。尽管这种算法被广泛采纳,但是它需要通过多次迭代才会收敛,在大规模的数据集中,它的时间效率不尽如人意,用非迭代算法替换迭代算法是至关重要的。基于神经网络的训练过程是非迭代的,会大大提高模型的时间效率。
综上,本文提出的NN-MF-TR模型的主要贡献如下:
1) 利用用户间的信任与被信任关系提高推荐系统的性能。在提取用户的潜在信任与被信任关系时,利用图拉普拉斯正则化,不仅保留了用户间的结构信息,还提高了模型的泛化能力。
2) 利用神经网络对模型进行训练,用非迭代算法替换迭代算法,大大提高模型的时间效率。
3) 四个真实世界的数据集上的实验结果可以表明,本文提出的模型在提高推荐准确率的同时大大提高了时间效率。
2. 相关工作
2.1. 矩阵分解
基于推荐系统的矩阵分解 [3] [4] 定义如下:假设
为评分矩阵,
代表用户i对条目j给出的评分,M为用户的数量,N为条目的数量。
可分解成两个低秩矩阵的近似乘积,即用户特征矩阵
和条目特征矩阵
的乘积,损失函数为:
(1)
其中,
表示已知评分,
是可以防止模型过拟合的正则化系数。
2.2. 自编码神经网络
自编码神经网络 [5] [13] [14] 相比于矩阵分解较为新颖,它通过捕获非线性特征为推荐系统提供了有竞争力的结果。基于自编码的模型由一个三层神经网络构成,即输入层、隐藏层和输出层 [5] [13] [14] ,图1是它的结构模型。自编码神经网络由编码和解码两阶段建立,通过重构输入的数据,使输出数据y与输入数据x相近。其损失函数可由欧式距离构建,具体如下:
(2)
其中,m为输入层数据的个数。
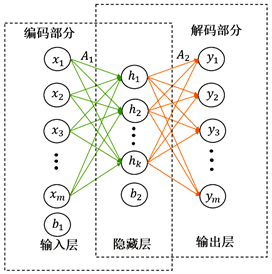
Figure 1. Autoencoder neural network model
图1. 自编码神经网络模型
3. NN-MF-TR模型
3.1. 提取用户潜在的信任与被信任关系
基于分解评分矩阵的方法 [3] [4] 同样可以分解信任矩阵,
为用户的信任矩阵,已知
为
对称0,1矩阵,1代表用户间存在信任关系,0代表用户间不存在信任关系,则可以将
分解成潜在的信任特征矩阵
和潜在的被信任特征矩阵
的乘积。为了提高信任特征与被信任特征的准确性,利用图拉普拉斯正则化 [15] [16] 可将用户间的结构关系保留到潜在的信任与被信任特征之中,同时防止模型过拟合并提高了模型的泛化能力。具体提取用户潜在信任与被信任特征公式如下:
(3)
其中,
、
分别为信任特征矩阵和被信任特征矩阵的正则化参数,
、
分别为信任特征矩阵和被信任特征矩阵的拉普拉斯矩阵。
3.2. NN-MF-TR算法
本文的模型基于矩阵分解 [3] [4] ,利用用户的潜在信任与被信任特征作为辅助信息来缓解目前评分信息的大规模缺失所导致的预测效果较不理想等问题,根据式(3)可以得到用户的潜在信任特征和潜在被信任特征,具体公式如下:
(4)
其中,
表示潜在因子矩阵
中的第i行元素,
表示潜在因子矩阵
中的第j行元素,
表示用户i信任的用户集合,
表示信任用户i的用户集合,
表示用户i潜在信任特征矩阵的第s行,
表示用户i潜在被信任特征矩阵的第s行,
、
为正则化参数。
3.3. 基于神经网络进行参数训练
为了使模型实现更高的计算效率,本文利用神经网络对模型的参数进行训练。假设模型中神经网络的层数为n,则过程如下:
1) 当
时,即神经网络的层数为单层。训练评分矩阵
,将矩阵
的每一行作为输入,然后训练潜在因子矩阵
,通过
可得到
。
2) 当
时,即神经网络的层数为多层。第一层的训练过程和单层神经网络模型相同;从第二层开始,每次训练都是将上一层训练出的潜在因子矩阵
的每一行作为下一层的输入,从而训练出当前层潜在因子矩阵
,通过
可得到
。
接下来,将基于梯度法对潜在因子矩阵
,
进行求解。
1) 当
时,研发的求解步骤如下:
首先,将评分矩阵
中的已知评分作为输入,通过随机学习算法 [17] [18] [19] 生成权重矩阵
和偏置向量
,然后可得到初始化后的潜在因子矩阵
:
(5)
其中,
分别为权重矩阵
的第
行元素,
分别为偏置向量
中的第
个元素。本文设置激活函数为
[20] ,该方法与其他激活函数兼容。
接下来,利用初始化后的潜在因子矩阵
求解潜在因子矩阵
,具体算法如下:
(6)
其中,
矩阵每行中已知元素集合。
令
,可得到:
(7)
其中,
是一个
维的单位矩阵。
整理可得到更新公式如下:
(8)
最后,再一次对潜在因子矩阵
进行更新。因为最初的
具有随机性,为了使结果更近似于评分矩阵
,则对
再次更新。
的更新方法与
相同,具体算法如下:
(9)
令
,可得到:
(10)
2) 当
时,需要注意的是,每层的输入数据为上一层的潜在因子矩阵
中的元素,具体算法如下:
(11)
其中,
分别为权重矩阵
的第
行元素,
分别为偏置向量
中的第
个元素。
接下来,利用梯度法更新潜在因子矩阵
,得到公式如下:
(12)
最后,再一次对潜在因子矩阵
进行更新,可得到:
(13)
3.4. 算法设计和复杂度分析
基于以上公式,本文设计模型的算法流程如下:
输入:信任矩阵
,评分矩阵
中的已知评分数据集合
,k,n,正则化参数
,
,
,
输出:潜在信任特征矩阵
,潜在被信任特征矩阵
,潜在因子矩阵
和
Step 1:根据式(3)求解潜在信任特征矩阵
,潜在被信任特征矩阵
Step 2:根据式(11)求解潜在因子矩阵
Step 3:根据式(12)求解潜在因子矩阵
Step 4:根据式(13)更新潜在因子矩阵
显然,本文所提算法的时间开销主要来源于计算公式(12)和(13)中的逆矩阵。通过计算得到公式(12)和(13)的时间复杂度均为
,其中k表示潜在因子维数。由此可以看出,潜在因子维数越小,则时间花销越少。此外,神经网络层数n的取值也对时间花销有着重要的影响,层数越多,则训练模型的时间成本也越大。
4. 实验及结果分析
4.1. 实验数据集及评估指标
为了验证本文所提模型的高效性,本文选取四个公开数据集作为实验数据,具体如表1:
为了客观公正的对模型进行评估,本文使用5折交叉验证用于训练和测试数据集,其中80%的数据用来做训练集,20%的数据用来做测试集,最终结果取20次实验后的平均值。
本文使用平均绝对误差(Mean Absolute Error, MAE)和均方根误差(Root Mean Squared Error, RMSE)这两个指标来衡量模型的质量。具体公式如下:
(14)
(15)
其中,
是测试数据集中的评分个数,
是测试数据集中的评分,
是预测的评分。
4.2. 模型的参数实验
为了综合评估本文所提模型的性能,需对相关参数进行灵敏度实验,为简便后续操作,预设
,
。其中正则化系数
、
,潜在因子维数k和神经网络层数
这四个参数对实验结果的影响较大。本文利用控制变量法对这三个参数分别进行实验,具体训练过程如图2~5所示。
图2是针对正则化系数
的灵敏度实验,其中潜在因子维数k预设为30,图2(a)~(d)分别展示了在数据集D1~D4上的实验结果。可以看出,当潜在因子维数k固定时,正则化系数
在不同的数据集上最优取值不同,且变化的神经网络层数n对正则化系数
值有一定的影响。通过实验,本文选取的最优正则化系数
值在数据集D1~D4上分别为0.001,0.001,0.0006和0.0002。正则化系数
的实验与
类似,在数据集D1~D4上的最终取值为0.047,0.062,0.013和0.02。
图3是针对潜在因子维数k的灵敏度实验,其中正则化系数
和
分别预设为0.001,0.04,图3(a)~(d)分别展示了在数据集D1~D4上的实验结果。同样可以看出,当正则化系数固定时,潜在因子维数k的取值随着网络层数n的变化而变化。本文进一步考虑时间花销,图4展示了不同潜在因子维数k的时间花销,不难看出k越大导致时间花销越多,综合考虑后选取潜在因子维数k在数据集D1~D4上分别为30,20,50,40。
图5同样是考虑时间花销的实验,它展示了不同神经网络层数n的时间花销,从图中可以看出,时间花销随着n的变大而增加。同时考虑预测精度与时间花销后,本文的选取的最佳神经网络层数n在D1~D4数据上分别为5,3,5,5。
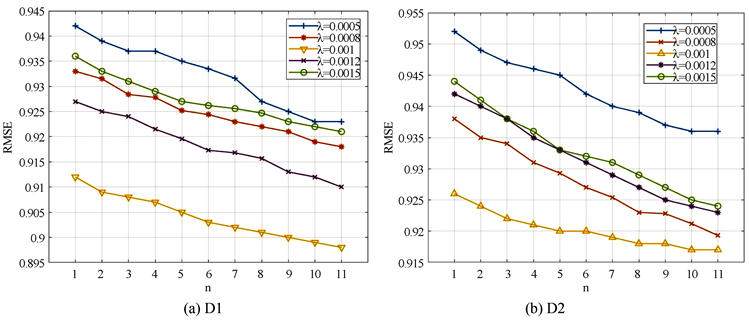
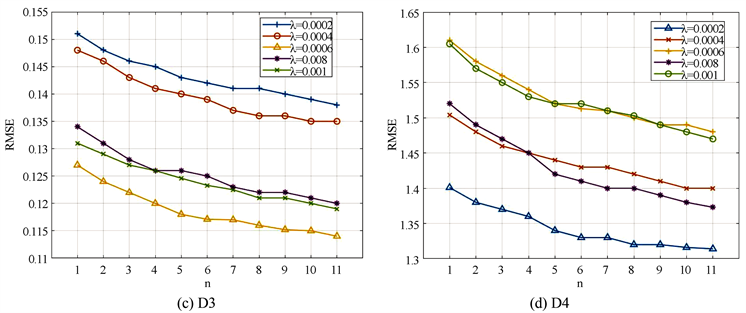
Figure 2. Different values of λ on datasets affect the RMSE
图2. 数据集上不同λ值对RMSE的影响
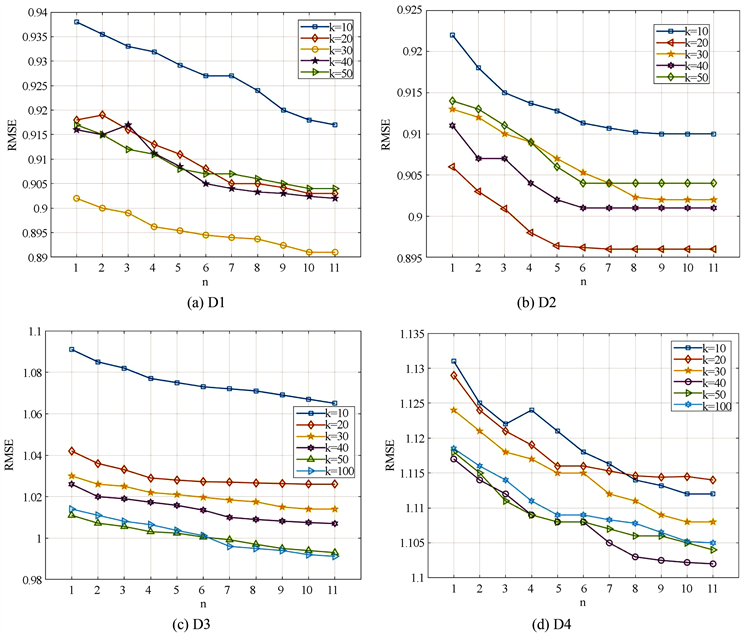
Figure 3. Different values of k on datasets affect the RMSE
图3. 数据集上不同k值对RMSE的影响
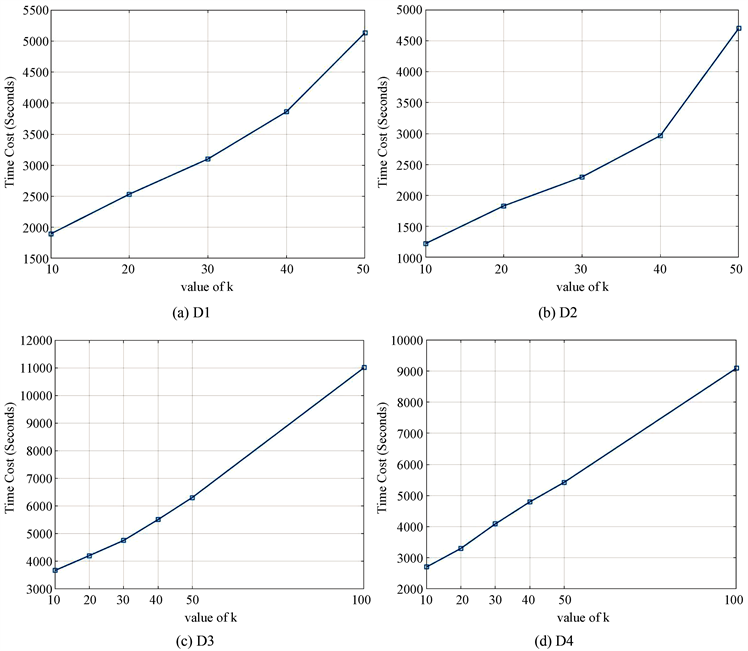
Figure 4. Different values of k on datasets affect the time cost (Seconds)
图4. 数据集上不同k值的时间花销(秒)
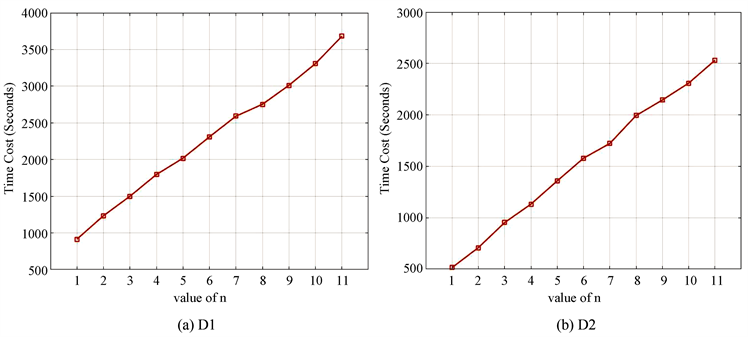
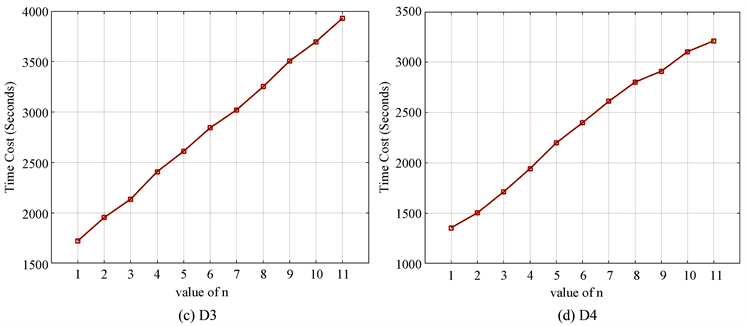
Figure 5. Different values of n on datasets affect the time cost (Seconds)
图5. 数据集上不同n值的时间花销(秒)
4.3. 对比模型实验
为了判断NN-MF-TR模型的有效性,本文选取了两个经典社交推荐模型和两个较新颖的推荐模型,本文涉及的实验模型共有5个,具体信息如下表2:
基于上文参数的确定,将本文模型与所选四个对比模型在四个数据集上进行实验,实验结果如下表所示。其中图6是模型M1~M5在数据集D1~D4上关于MAE和RMSE这两个指标的表现,图7是模型M1~M5在数据集D1~D4上的关于最小RMSE值的时间花销。
从图6可以看出,模型M5与M1、M3、M4相比RMSE和MAE有明显的优势。基于MAE值来说,模型M5至少提升了3.51%。基于RMSE值来说,模型M5至少提升了0.93%。这说明考虑用户的信任与被信任关系挖掘了用户的潜在偏好,缓解了矩阵稀疏的问题,可以获得较好的推荐结果。
从图7可以看出,模型M5的时间花销远少于模型M1~M3,尤其在大型数据集上,如模型M3在数据集D3上取得的最小RMSE的时间花销是29,537 s,而模型M5在数据集D3上取得的最小RMSE的时间花销是3485 s,这说明在训练模型时引入神经网络实现了更高的计算效率。
模型M5与模型M2相比较MAE和RMSE值比较相近,但是模型M5的时间花销少于模型M2。模型M4的时间花销小于模型M5,但是模型M5预测评分的精度却高于模型M4。在综合考察衡量推荐准确率和时间效率后,模型M5被证明可以在保证预测评分精度的同时减少时间花销,所以模型M5的整体表现优于其余四个对比模型。
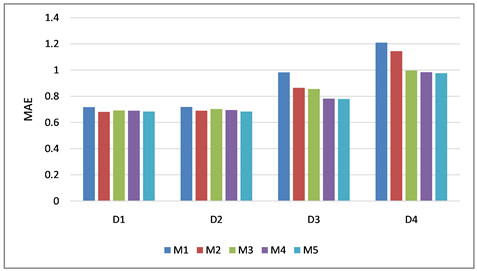

Figure 6. Lowest MAE and RMSE of models M1~M5 on datasets D1~D4
图6. 模型M1~M5在数据集D1~D4上的最小MAE和RMSE
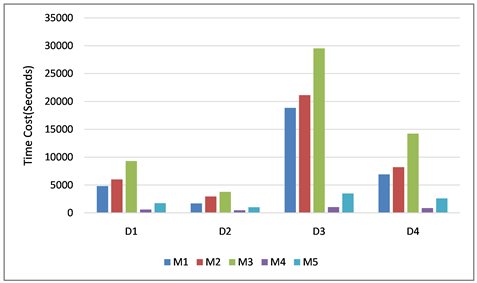
Figure 7. Time cost by the models M1~M5 on the datasets D1~D4 regarding the lowest RMSE (Seconds)
图7. 模型M1~M5在数据集D1~D4上关于最小RMSE的时间花销(秒)
5. 结论
如何提高推荐准确率和时间效率已经逐渐成为推荐系统中的研究热点。本文综合考察衡量准确率和效率这两个方面。一方面,利用用户潜在的信任与被信任信息来挖掘出用户的潜在偏好,在一定程度上缓解了评分矩阵稀疏所导致的推荐准确率低等问题。另一方面,在训练模型时引入神经网络,其训练过程大大提高了其在稀疏数据上的表示学习能力,能够在保证推荐准确率的前提下减少训练模型的时间花销。最后,本文在四个真实世界数据集进行实验,NN-MF-TR模型与对比模型相比较综合性能最优。通过实验结果可证明引入神经网络对模型进行训练且利用用户间潜在的信任与被信任关系作为推荐模型的辅助信息可提高推荐系统的性能,在提高模型准确率的同时也提升了训练速度。
基金项目
本研究获得国家自然科学基金面上项目资助,项目编号为61973219。
NOTES
*通讯作者。