1. 引言
神经网络是人工智能研究领域 [1] 的核心之一,其本质是模拟人脑的学习系统,通过增加网络的层数让机器从数据中学习高层特征 [2] 。近年来,由于神经网络优异的算法性能,已经广泛应用于图像分析、目标检测等领域 [3] [4] 。
视觉图像提供了丰富的特征信息 [5] ,可以提供某个时刻对于研究问题所需要的环境的有效状态信息。正因为其具有的丰富的特征信息量,视觉图像被广泛应用于如机器人导航、机械臂控制等许多应用上。纯粹基于视觉图像的抓取控制,其质量极大地依赖于图像的特征提取的准确性和机械臂抓取控制的动力学模型的准确性。但是,传统的视觉特征提取算法受环境动态变化的影响,手工提取的特征往往费时费力,很难满足机械臂抓取控制的需求。同时,机械臂运动轨迹的求解与规划,正逆动力学模型的建立往往也十分困难。
目前国内外许多文章提出了不同的机械臂控制方法,近年来由于图像识别技术的发展以及人工智能得到广泛的运用 [6] ,出现了将两者结合起来用于机械臂的控制,并且取得了良好的效果。文献 [7] 将机械臂避障路径规划问题置于强化学习的框架当中,采用深度Q学习的方法训练策略以规划路径,使得机械臂能够在空间中存在障碍物的情况下实现避障抓捕。文献 [8] 对图像进行了预处理并提取了目标边缘,结合目标特点对提取的边缘进行了椭圆拟合,并对椭圆拟合偏差进行了分析。针对常规方法设计视觉控制器的不足,基于BP神经网络对视觉控制器进行了设计,考虑了不同网络参数和训练算法对网络训练效果的影响。文献 [9] 深入分析了机械臂特性和目标特性,在建立机械臂、相机和目标的运动关系的基础上,基于立体视觉实现了对空间目标的位姿测量,控制机械臂进行抓取预定位。考虑立体相机的测量误差和机械臂的控制精度因素,在抓取末阶段采用单目相机,基于图像的视觉伺服策略控制机械臂进行精确位姿调整对目标进行抓取。文献 [10] 以二自由度机械臂为基础,用摄像机获取机械臂运动区域的图像,通过图像分析,求解机械臂末端执行器在直角坐标空间的坐标值,将该值作为系统的实际位置,并通过反馈与期望坐标值相减,将所获得的误差作为机械臂控制系统的补偿量,实现整个系统的全闭环控制,进一步解决了原半闭环控制带来的控制精度不高的问题。文献 [11] 针对多自由度机械臂的神经网络控制问题,将控制系统根据自由度分为两个子系统,提出全局神经网络与局部神经网络组合对机械臂系统进行控制。
文献 [12] 指出机械臂视觉抓取系统中基于深度学习的视觉识别可通过对深度卷积神经网络的训练实现多目标快速识别而不必更改识别算法。这需要搜集被检测目标的大量图像制作标准的训练集,利用前述基于深度神经网络的目标识别算法对数据集进行离线训练,将得到的模型用于在线识别。R-CNN系列算法 [13] [14] 是目前主流的用于机械臂抓取的深度学习目标检测算法,但是速度上并不能满足实时的要求。
机械臂视觉抓取在常规的机器人学、控制理论的基础上,融合了计算机视觉理论、深度学习和人工智能等学科,具有重要的科研和应用价值。
如何提高视觉图像特征与优化控制之间的契合度是现有技术需要解决的问题。针对现有技术的缺点,本文提出了一种结合深度强化学习 [15] 的机械臂视觉抓取控制优化方法。在建立在人工智能算法深度强化学习的基础上,能自主地学习视觉图像的特征提取,并有效地规划机械臂的抓取控制轨迹。同时,根据不同的应用环境和抓取目标,自主地学习相应的机械臂抓取控制策略,提高了算法的泛化能力。深度强化学习的应用,避免了人为的特征提取和运动轨迹计算,提高了准确度,简化了复杂度,从而提升实际机械臂抓取控制的效率。
2. 深度学习神经网络模块设计
设计一种深度学习的神经网络模块,前端采用卷积神经网络 [16] ,不断学习提取高维的视觉图像信息,并将其处理成低维的状态信息。然后经过一个长短时记忆网络,有效地处理时序信息,提取机械臂每个状态前后的隐含信息。后端采用强化学习的执行器–评价器 [17] 结构,获取低维的状态信息,从中学习提取有效信息,输出策略动作,从而控制机械臂的抓取。
由于整体框架采用神经网络,并通过反向梯度传播算法进行迭代学习,可以大大减少手工处理图像信息的难度。并且可以根据不同的机械臂工作环境,进行相应的抓取控制策略的学习,大大提升了该方法的实用性和泛化能力。此外,所提出的方法是端到端地进行机械臂抓取控制策略的学习,可以自主的学习有效的、必要的信息,提供更准确的抓取控制,达到基于视觉图像的机械臂抓取控制目的。
2.1. 执行器–评价器结构
执行器–评价器结构是指ACTOR-CRITIC METHOD,一种结合了Policy Gradient (Actor)和Function Approximation (Critic)的方法。执行器(Actor)基于概率选行为,评价器(Critic)基于执行器(Actor)的行为评判行为的得分,执行器(Actor)根据评价器(Critic)的评分修改选行为的概率。该结构既有基于值的方法(Q-learning等)可以进行单步更新的优点,提升了学习效率,又有基于策略的方法(Policy Gradient等),能在连续动作空间进行决策的优势,扩大了应用范围。
2.2. 卷积神经网络
将机械臂视觉传感器获取的图像进行预处理,处理后的图像为一系列的160 × 120的红绿蓝图像
,输入到设计的神经网络,就可以获得通过卷积神经后的一组特征图
,其中n为一次机械臂抓取过程的阶段长度,c为卷积神经网络的输出特征图通道数,w,h分别代表为特征图的长和高,如公式所示:
将卷积神经网络输出后的二维特征图,转变为一维特征
,其中,
,如公式所示:
将一维特征向量
输入卷积层后的递归层长短时记忆网络LSTM。在每个训练阶段开始,长短时记忆网络的隐含状态都为0,如公式所示:
将递归神经网络输出
,通过柔性最大值传输函数变化映射成为机械臂的每个动作选择概率
和通过线性变化映射成为机械臂的状态值
值,如公式所示:
本文所述的深度学习神经网络模块的优点是,可以自主地在大量数据中学习机械臂抓取控制的同时,应对不同场景不必重新设计算法,可以自主学习以提供不同的抓取策略,并且单纯的基于视觉图像。
3. 控制优化方法及实例
3.1. 学习流程
在图1所示学习流程中,智能体观察机械臂抓取的环境视觉图像,经过图2所示的神经网络的处理,应用深度强化学习,直接输出机械臂抓取控制策略。控制机械臂关节的移动,从而获得相应的来自于环境的奖励。智能体通过奖励的学习,不断优化机械臂的抓取控制策略,在下一次抓取时,提供更加优秀的抓取策略。通过不断地与环境交互的自主学习,机械臂渐渐的学会靠近抓取目标,最终抓取物体。
3.2. 控制策略
神经网络架构获取机械臂环境的红绿蓝视觉图像。首先通过卷积神经网络,处理高维的视觉图像信息。然后经过全连接神经网络,提取有效环境状态特征信息。最后采用强化学习的执行器–评价器结构,直接输出机械臂的抓取控制策略。根据与环境交互产生的奖励,利用强化学习算法的贝尔曼方程,进行方向梯度传播进行梯度更新,优化神经网络参数,从而优化最终控制策略。
3.2.1. 贝尔曼方程
贝尔曼方程是对强化学习中值函数的一种迭代求解方法。首先定义累积回报
(带衰减系数γ),如公式所示:
从而可以定义值函数为回报的期望:
将上式展开:
从而得到:
。
上式即为贝尔曼方程,它表明当前状态的价值和下一步的价值以及当前的反馈回报有关,说明值函数是可以通过迭代来进行计算的。
3.2.2. 神经网络参数选取
图2所示的神经网络结构里,神经网络的输入为同一系列中的4张160 × 120的红绿蓝三通道图像,输出为机械臂7个关节的角速度和夹具的动作(打开或关闭)。感知网络由四层卷积神经网络和一层长短期记忆单元组成。第一个卷积层使用了16个10 × 10的卷积核,步长为4,填充为1,卷积后得到16个39 × 29的特征图。第二层使用2个5 × 5的卷积核,步长为2,填充为1,卷积后得到32个19 × 14的特征图。第三层使用2个5 × 6的卷积核,步长为2,填充为1,卷积后得到64个9 × 6的特征图。第四层使用2个5 × 6的卷积核,步长为2,填充为1,卷积后得到128个4 × 2的特征图。将这些特征图送入长短期记忆单元,输出一个8维向量,前7维表征机械臂关节角速度,最后一维表征夹具动作。卷积网络使用kaiming高斯初始化方法。强化学习部分使用基于随机排列的经验次序回放。探索策略使用ϵ贪婪策略,初始化为0.5,然后在训练中退火到0.1。衰减系数γ为0.5。
3.3. 抓取控制实例
机械臂在仿真环境中机械臂学习抓取控制,抓取其中一个物块,将其叠放在另外一个物块纸上,比如红色物块叠放在绿色物块之上,如图3所示。
机械臂在真实环境中的抓取控制实例。上半图所示为机械臂学习抓取控制,抓取物块移动到黄色目标位置。下半图所示为机械臂学习抓取,成功检测到桌上物块的位置,准确定位并实施抓取,如图4所示。
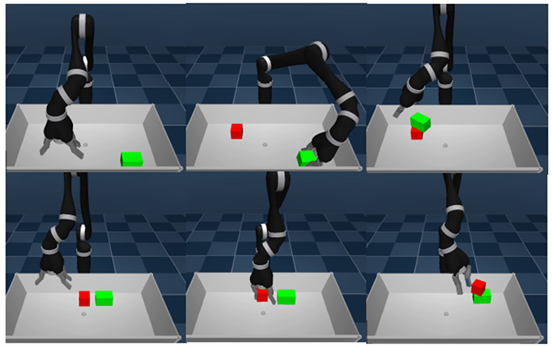
Figure 3. Example of grab control of the robot arm in the simulation environment
图3. 机械臂在仿真环境中的抓取控制实例

Figure 4. Example of grab control of a robot arm in a real environment
图4. 机械臂在真实环境中的抓取控制实例
4. 结束语
本文提出了一种结合深度强化学习的机械臂视觉抓取控制优化方法。在建立在人工智能算法深度强化学习的基础上,能自主地学习视觉图像的特征提取,并有效地规划机械臂的抓取控制轨迹。同时,根据不同的应用环境和抓取目标,自主地学习相应的机械臂抓取控制策略,提高了算法的泛化能力。深度强化学习的应用,避免了人为的特征提取和运动轨迹计算,提高了准确度,简化了复杂度,从而提升实际机械臂抓取控制的效率。