1. 引言
在电商、互联网广告、移动互联网中,推荐系统发挥着越来越大的价值。过去几年来,一个明显的趋势是搜索、计算广告,以及个性化推荐这三者在底层模型和技术工具上越来越趋于融合。相比于PC互联网,用户使用场景和习惯的改变使得用户行为模型在推荐领域的重要性获得了空前提升。推荐不再单单局限于兴趣领域,兴趣、关系、场景、行为模式,这四者都会起到至关重要的作用。目前几乎所有的解决范式都是将用户理解为行为结构体,这个结构体包含了兴趣、关系、场景、行为模式中的一种或者多种,这些信息向量化之后成为大量Feature。而推荐的目标就是预测用户的未来行为,如点击行为(CTR预估)、购买行为(CVR预估)等等。但是大多数基于特征集合的方法更注重一般偏好,更容易忽略短期动态变化的兴趣。一般偏好代表用户的长期和静态的行为,更容易基于整体的特征矩阵运算得到。而用户的短期和动态行为,则来自于在很近的时间物品之间的某种关系。例如在某电商平台的手机app平台,在不断下拉的feed流环境下,用户的兴趣动态变化频繁,有些用户可能在购买小米手机后不久就购买手机配件,尽管大多数用户一般不会购买手机配件。在这种情况下,只考虑一般偏好的系统,将错过在销售iPhone后推荐手机配件的机会,因为购买手机配件不是一种长期的用户行为。
本文目标是通过结合用户的一般喜好和序列模式,来推荐他\她未来最有可能需要的一系列物品。和以往各种深度学习机器学习的Top-N推荐算法不同的是,Top-N序列推荐将用户行为建模为物品的序列,而不是集合。
2. 相关研究
2.1. 基于特征集合
FM (Factorization Machine)是近年来在推荐、CTR预估中常用的一种算法,该算法在LR的基础上考虑交叉项,FM在后半部分的交叉项中为每个特征都分配一个特征向量V,这其实可以看作是一种Embeding的方法。Dr. Zhang [1] 在文献中提出一种利用FM得到特征的embeding向量并将其组合成dense real层作为DNN的输入的模型——FNN [1],将每个特征用其所属的field来表示,导致原始输入大大减少,但是FM参数需要预训练,无法拟合低阶特征,每个field只有一个非零值的强假设。Dr. Zhang在FNN模型的基础上又提出了新模型PNN [2]。但模型对于低阶特征的表达比较有限。
因此,Google在2016年提出了大名鼎鼎的Wide & Deep [3] 结构来解决了这样的问题。网络结构如图1所示,Wide部分是LR模型,Deep部分是DNN模型。Wide and Deep模型的核心思想是结合线性模型的记忆能力(memorization)和DNN模型的泛化能力(generalization),在训练过程中同时优化2个模型的参数,从而达到整体模型的预测能力最优。记忆(memorization)即从历史数据中发现item或者特征之间的相关性。泛化(generalization)即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合。

Figure 1. Wide & deep model structure
图1. Wide & deep模型结构
华为诺亚方舟团队将Wide & Deep部分的LR部分替换成FM来避免人工特征工程,于是有了DeepFM [4]。DeepFM包含两部分:神经网络部分DNN与因子分解机FM部分,分别负责低阶特征的提取和高阶特征的提取。这两部分共享同样的输入。Google在2017年提出了Deep & Cross Network,简称DCN [5] 的模型,可以任意组合特征,而且不增加网络参数。图2为DCN的结构。与此对照,阿里在2017年提出的Deep Interest Network,简称DIN [6] 模型。与上面的FNN,PNN等引入低阶代数范式不同,DIN的核心是基于数据的内在特点,引入了更高阶的学习范式。用户的兴趣是多种多样的,从数学的角度来看,用户的兴趣在兴趣空间是一个多峰分布。在预测CTR时,用户embedding表示的兴趣维度,很多是和当前item是否点击无关的,只和用户兴趣中的局部信息有关。因此,受attention机制启发,DIN在embedding层后做了一个action unit的操作,对用户的兴趣分布进行学习后再输入到DNN中去,网络结构如图3所示。

Figure 2. The Deep & Cross network
图2. The Deep & Cross网络
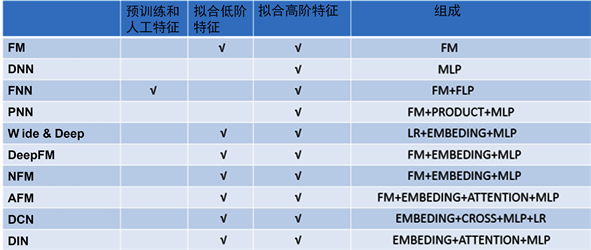
Figure 3. Summary comparison of various deep learning models on CTR
图3. 在CTR上的各种深度学习模型汇总比较
以上介绍了深度学习在CTR场景下最新的网络结构,总结起来如图3所示。各种CTR深度模型看似结构各异,其实大多数可以用用下图3表示,从图中可以CTR领域的深度学习过程可以用一个通用范式来表达。input->embedding:把大规模的稀疏特征ID用embedding操作映射为低维稠密的embedding向量。embedding层向量:concat,sum,average pooling等操作,大部分CTR模型在该层做改造。embedding->output:通用的DNN全连接框架,输入规模从n维降为k × f维度甚至更低。其中,embedding vector这层的融合是深度学习模型改造最多的地方,该层是进入深度学习模型的输入层,embedding融合的质量将影响DNN模型学习的好坏。
2.2. 基于特征序列
基于马尔可夫链 [7] [8] 的模型是Top-N序列推荐早期的一种方法,L阶马尔可夫链基于前L个行为来做推荐。一阶马尔可夫链是利用极大似然估计学习的一种物品到物品的转移矩阵。
Rendle等人提出的分解个性化马尔可夫链(FPMC [9])及其变体通过将转移矩阵分解为两个潜在的和低秩的子矩阵来改进这种方法。基于物品相似模型的分解序列预测(Fossil [10])将该方法推广到高阶马尔可夫链,利用加权和聚合方法对已有物品的潜在表示进行加权和聚合。然而,现有的方法主要有两方面局限性:1) 未能对联合级序列模式进行建模。2) 不允许跳过某些行为,过去行为的影响不允许跳过几步对未来发生影响。例如,游客在机场、酒店、餐厅、酒吧和景点中依次签到,虽然机场和酒店的签到并不是在景点之前,但它们与后者依然有很强的关联。在餐厅或酒吧签到对景点签到几乎没有影响,因为去景点之前到餐厅或者酒吧不是需要的。为解决上述两种工作的局限性,并结合已有方法的优点,作者提出一种卷积序列嵌入推荐模型R-TCN,作为Top-N序列推荐的解决方案。
3. R-TCN
3.1. 模型结构
本文所提出的网络结构主要受TCN [11] 网络模型的启发。TCN是将卷积网络设计中的最佳实践提炼而成的一个简单架构。其在不同任务和数据集上的性能优于典型的RNN网络。R-TCN的主要特征是:1) 架构中使用的卷积是因果关系,保证没有从未来到过去的信息泄露,这是适用于序列建模的前提;2) 该架构直接对稀疏数据嵌入之后的矩阵进行卷积操作;3) 通过使用非常深的网络(残差层搭建)和空洞卷积来构建非常长的有效历史规模,即可以利用非常遥远的历史值做出预测。
R-TCN由三个部分组成:embedding [12] 层、卷积层和全连接层。
1) embedding层:为了训练CNN,本文从用户序列中为每个用户u提取L个连续物品作为输入,并提取它们接下来的T个物品作为目标,如图4所示,这是通过在用户序列上滑动一个大小为L + T的窗口来完成的,每个窗口都为u生成一个训练样本,由一个三元组表示(用户u,前L个物品,后T个物品)。
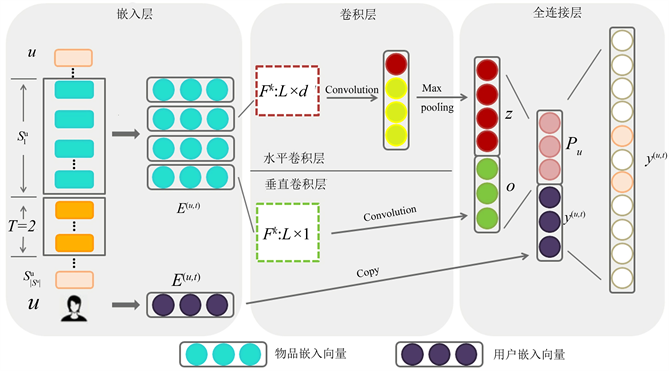
Figure 4. R-TCN model module diagram
图4. R-TCN模型模块图
2) 卷积层:R-TCN使用因果空洞卷积作为卷积层,而每两个这样的卷积层与恒等映射可以封装为一个残差模块。这样由残差模块堆叠起一个深度网络。网络结构如图4所示,R-TCN由很多个残差块串联而成,残差块的个数由具体任务的输入和输出的尺寸大小决定。
3) 全连接层:将这两个卷积层的输出串联起来,并将它们输入到一个全连接的神经网络中。
3.2. embedding层
对于简单的公式,可以直接以文本方式输入;对于复杂的公式,可以考虑使用公式编辑器,或者将公式制作成图片后插入文中。编辑公式的过程中要特别注意减号与连字符的区别,前者较长,后者较短。NN之所以在CV领域 [13] 大放异彩是由于其具有如下特性:1) 参数共享通常一个特征检测子(如边缘检测)在图像某一部位有用也在其他部位生效。2) 稀疏连接每一层的输出只依赖于前一层一小部分的输入。在NLP任务中由于语句天然存在前后依赖关系,所以使用CNN能获得一定的特征表达 [14]。
在推荐任务中输入是空间无序的,特征是高维稀疏的,没有NLP和CV任务上空间上的强相关性和密集性,造成了CNN在推荐领域使用甚少。
如图4部分,将前L个物品在隐空间的表示连接起来,作为用户u在当前时刻t的序列矩阵表示(d是隐藏层的维数):
除了物品的表示之外,本文还为用户u提供了一个用户表示:
它表示潜在空间中的用户特性。这些表示在图4的左侧第一模块中,用蓝色和紫色的实心圆表示。
3.3. 卷积层
3.3.1. 总体介绍
如图4将前L个物品在隐空间的表示Latent Space (L × d的矩阵E(u, t))看作一张“图像”,卷积层就是是利用卷积核对其进行序列模式的搜索和学习。两个水平卷积核(用h × d的矩阵表示,图中所示h = 2)通过在矩阵E上滑动来提取两种不同的联合级序列模式。其中第一个卷积核通过与“高铁”和“网红店”的embedding表示的交互,跳过“旅行箱”和“房卡”,提取出“(高铁,网红店)→景点”的模式。同理,第二个卷积核提取了“(旅行箱,房卡)→酒店”的序列模式。矩阵方块中颜色越深代表值越大。因此,水平卷积核可以被训练来提取具有多种模式。图5中间卷积部分的下半部分显示了垂直卷积层,在该层中,垂直卷积核(用L × d的矩阵表示)在矩阵E上从左到右滑动,通过对前几项物品的潜在表示的加权和来捕获点级序列模式。
3.3.2. 残差
序列建模任务通常需要很长的感受野,而感受野依赖于网络深度以及卷积核大小等,为了使更大更深的人R-TCN网络更加稳定,采用通用残差模块。
残差网络(Residual Network, ResNet [15])通过加入shortcut connections,变得更加容易被优化。包含一个shortcut connection的几层网络被称为一个残差块(residual block),这已多次被证明有利于非常深的网络。一个深度网络中如果期望用一个非线性单元
去逼近目标函数
,可以将目标函数拆分成恒等函数
和残差函数
。
根据通用近似定理,一个由神经网络构成的非线性单元有足够的能力来近似逼近原始目标函或残的学习会比前者简单。因此,原来的优化问题便转换为:让非线性单元
去近似残差函数
,并用
去逼近
。
R-TCN的残差块结构如图6中所示。在R-TCN的残差模块内,有两层因果空洞卷积,根据非线性,使用了校正线性单元(recfied linear unit, ReLU)。对于归一化,我们将权值归一化应用于卷积滤波器。此外,R-TCN在残差模块内的每个因果空洞深度可分离卷积后都添加了Dropout [16] 以实现正则化,防止过拟合。最终,由多个这样的残差模块堆叠起一个深度网络。图6给出了残差连接的示例。残差块里面有两层因果空洞卷积。实线代表滤波器,虚线代表恒等映射,在R-TCN中,输入与输出有不同的维度,因此需要使用额外的1 × 1卷积来确保对应元素相加有相同的维度。k代表卷积核大小,这里卷积核尺寸为3,d表示空洞系数,这里为1,也就是相当于普通卷积操作。
3.3.3. 因果空洞卷积层
序列问题强调的是先后顺序,RNN的特性使其有助于解决时间序列预测问题,但它串行处理序列数据,训练速度慢。CNN可以并行处理序列数据,速度比RNN快,但普通卷积网络会把序列中未来的数据和过去的数据同等地位对待,可能会导致未来数据到过去数据的泄露。因此普通卷积不能直接用于处理序列数据,要用因果卷积替代传统卷积。如图7所示,因果卷积 [17] 提供了处理时间流的适当工具,当
对输入数据的顺序很注重的时候,因果卷积便可以发挥作用。一个简单的因果卷积只能用网络深度的线性大小来回顾历史,而普通因果卷积网络的感受野很小,多层卷积感受野增长太慢,不能覆盖较长的序列。这使得将上述因果卷积应用于序列任务非常困难,尤其是那些需要较长历史的任务。
根据van den [18] 等人的工作,解决方案是使用空洞卷积,不增加参数数量,同时增加输出单元感受野,使一个指数级大的感受野成为可能。如图8所示,左图对应3 × 3的空洞卷积,空洞为0,和普通的卷积操作一样,中间图对应3 × 3的空洞卷积,实际的卷积核还是3 × 3,空洞为1,但是该卷积核的感受野已经增大到了7 × 7;右侧图对应空洞卷积实际的卷积核还是3 × 3,空洞为3,该卷积核的感受野已经增大到15 × 15。可以看出,增加空洞后,参数量不增加但是大大增加感受野范围。
3.4. 全连接层
在全连接层中,如图4右部分所示,作者将这两个卷积层的输出concat起来成为向量Z,并将它们输入到一个全连接的神经网络中,以获得更高层次和更抽象的特征。值得注意的是我们对Z和Pu进行了concat操作。如图4向量Z来自卷积操作,向量Pu来自输入端的用户向量直连。向量Z表示用户的短期兴趣,而向量Pu则代表了用户的长期兴趣。Concat(Z, Pu)将同时拥有长期和短期兴趣信息。同样的,Pu的生成方法是很多的,我们采用DeepFM预训练之后形成的Pu,因为对于一般兴趣的捕捉存在着包括机器学习(FM LR)和深度学习(DeepFM Wide & Deep)在内的众多方法。所以本文的模型具有结合CNN、RNN机器学习等多种模型共同发挥作用的潜力,采集他们的优点,同时序列预测又规避了他们的动态短期兴趣捕捉不足的弱点。
4. 实验准备
4.1. 数据集
Movielens [19] 数据包含138,493个用户,27,278部电影,21个类别和20,000,263个样本。基于userid分割训练和测试集。在138,493名用户中,随机抽取10万人形成训练集(大约14,470,000个样本),其余38,493人形成测试集中(约5,530,000个样本)。特征包括movie_id,movie_cate_id and userrated movie_id_list,movie_cate_id_list.
Amazon Dataset Amazon [20] 数据集包含商品评论和来自Amazon的各种元数据,将用作本课题的基准数据集。我们抽取Electronics这个类别的子集数据进行实验,包含192,403个用户,63,001个商品,801个类别和1,689,188个样品。此数据集中的用户行为非常丰富,每个用户和商品的评论超过5条。假设用户行为是(b1, b2, ..., bk, ..., bn),那么任务就是根据前k个浏览的商品预测第k + 1个要浏览的商品。特征包括goods_id,cate_id,user reviewed goods_id_list cate_id_list。统计两个数据集的数据细节,如表1所示。

Table 1. Dataset statistics used in this article
表1. 本文使用的数据集统计
4.2. 对比模型
1) LR
Logistic regression (LR)是一种应用广泛的浅层回归方法。
2) FM
FM (Factorization Machine)是近年来在推荐、CTR预估中常用的一种算法。
3) CF
协同过滤算法分为UserCF (基于用户的算法)、ItemCF (基于物品的算法)两大种。
4) Wide & Deep
在实际工业应用中,Wide & Deep模型已被广泛接受。根据上节所述,包含Wide (手工LR)和Deep (DNN)两部分。
5) DeepFM
根据上节所述,利用FM替代Wide & Deep的Wide部分,实现End2End训练。
4.3. 评价指标
我们在每个用户序列的70%作为训练集,并使用之后的10%动作序列来搜索各种模型额最佳超参数。使用余下的20%的作为模型表现的测试集。正如之前论文 [21],我们按Precision@n、Recall@n和Mean Average Precision (MAP)评估一个模型。给定用户的Top-N预测项的列表,表示为
,则

为了计算所有用户的Prec Recall的平均值,
AP计算值如下:
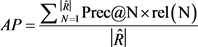
Precision (MAP)是所有用户的AP的平均值。
5. 实验结果
实验软件环境为Windows 10操作系统,深度学习框架是tensorflow1.12。实验硬件环境是Intel Corei3-8100HQ四核处理器,4 GB内存,GPU为NVIDIA(R) GeForce GTX 1060。
5.1. 推荐效果
表2显示了Amazon数据集和MovieLens数据集的结果。所有实验重复多次,并汇报平均结果。显然,所有的深度学习网络(Wide & Deep DeepFM)都显著地击败了机器学习模型(LR FM),这确实证明了深度学习的力量。
Table 2. Comparison of statistical recommendation indicators
表2. 统计推荐效果指标比较
如图9图10所示,在相对简单的MovieLens数据集上,Top1推荐的任务与CTR任务很类似,DeepFM表现是最好的,但是Top5 Top10的推荐任务,R-TCN的指标都是第一,好于其他任务。分析原因,一是Top-N推荐任务中R-TCN模型通过TCN的宽阔视野和两个方向上的卷积捕捉到了更多更细腻的信息,这一点其他模型无法做到,二是结合其他的模型已有优点,同时利用了长期静态的用户嵌入向量和短期动态向量的信息。
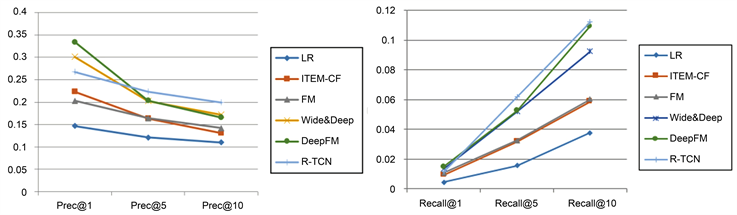
Figure 9. MoviesLens data set PREC/Recall (y-axis) vs. N (x-axis)
图9. MoviesLens数据集PREC/Recall (y-axis) vs. N (x-axis)
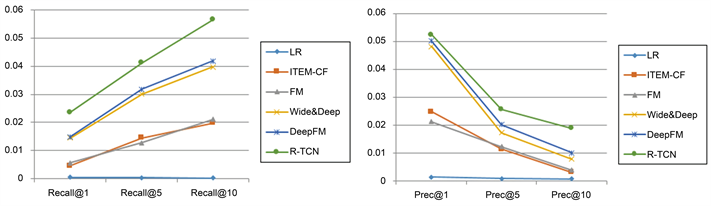
Figure 10. Amazon dataset PREC/Recall (y-axis) vs. N (x-axis)
图10. Amazon数据集PREC/Recall (y-axis) vs. N (x-axis)
在具有更丰富用户行为的Amazon数据集上,大多数模型做Top-N推荐的准确率都大幅的下降了,说明工业环境中个性化推荐确实是一个比较复杂的问题。在此数据集上,R-TCN指标全部位列第一,好于其他模型,说明在更复杂的环境中,能同时捕获长期和短期信息的模型,扬长避短的模型更有优势。
5.2. 时间效率
以LR的时间为单位时间,times of LR分别是各个模型训练时间对单位时间的比值。统计时间效率如表3 (CPU)和表4 (GPU)所示,并将结果可视化对比,如图11所示。
Table 3. CPU time efficiency comparison
表3. CPU时间效率对比
Table 4. GPU time efficiency comparison
表4. GPU时间效率对比
LR由于工业上最广泛的机器学习方法,得益于其时间效率极高。以LR训练时间为基准,从时间效率指标上看,R-TCN训练时间均是最短。在CPU环境上,R-TCN领先优势更加明显。分析其原因,得益于卷积操作的并行化处理效率。在生产环境,借助于配套的大数据系统,基于各方面的并行优化,还有巨大的时间优化的潜力。缩短训练时间对于实现更加灵敏和快速的实时推荐有着重要的意义。
5.3. 结论
本文提出了一种新型的网络结构R-TCN,基于推荐效果和时间效率两方面的综合比较,展现出一定的优势。在推荐效果方面,高于LR FM DeepFM等工业上广泛使用的方法。在训练时间方面,也领先上述相比较的模型,并还有继续大幅优化的潜力。综合来看,R-TCN未来具有一定的优化和使用潜力。
6. 结束语
针对用户推荐场景的序列预测问题,本文提出了一种新的方法,R-TCN,通过理论和实验证明了该方法在达优秀的推荐效果的同时,还能大幅缩短训练时间,并且理论上还有继续大幅优化时间效率的潜力。模型更加注重利用短时变化的兴趣信息,更贴合各种沉浸式APP的算法推荐。训练时间缩短,有助于提高并发瓶颈和实时计算。