1. 引言
随着大数据的不断发展,数字化的思想逐步渗透到工业制造业中。工业4.0趋势 [1] 就是将更多的物联网设备部署到工厂中,用算法取代人脑,用自动化设备取代人力,逐步实现工业智能化。然而,不可忽视的是随着联网设备的不断扩充,多用户多任务并行处理需求。传统集中式云计算已无法满足当下工业生产的实时性需求。边缘计算将部分计算卸载到边缘,在边缘端实现对数据流的简单计算或筛选 [2] [3],减轻云端计算及存储压力。同时由于计算位置上的变化,边缘设备更靠近用户端,可实现短时间内的有效交互,大大降低传输时延。边缘计算的出现为时间敏感型工业生产带来福音。
据IDC数据统计,到2020年将会有超过500亿的终端联网设备,超过50%的数据需要在网络边缘侧分析、处理与储存。边缘服务器往往是由较近的路由器,基站等设备构成,虽然能为云端解压,但受其有限的计算及存储能力限制,无法满足大型任务需求。针对目前多用户多任务并行处理的现况,必须有一套合理的计算卸载方案来保证边缘服务器计算的可靠性。
现有方案中,Yaozhong Song [4] 等人基于QoS面向物联网任务提出了一种在边缘计算网络中定期分配传入任务的方法,增加了可以在边缘计算网络中处理的任务数量,然而其并没有考虑到任务之间的关联性,及任务之间的优先级关系。Feng Wei [5] 等人面向移动边缘计算物联网设备之间分配资源提出了一种选择最低能耗优先的算法,充分考虑服务器资源及无线信道分配,使用户端到边缘端的任务分配更加科学。然而其并没有讨论带宽对分配方案的影响,也没有讨论任务间的相关性。Zhang D [6] 等针对异构边缘计算设计了一种基于社交传感的任务分配方法,考虑了任务的动态性,然而其也没有考虑任务的关联性并且仅能用于某一单独的任务,无法满足多任务并存场景。Boutheina Dab [7] 等面向边缘计算的多任务联合分配及资源分配提出基于多用户WiFi的MEC架构,满足任务延迟约束下移动边缘端的能量消耗最小,他们默认服务器接收所有数据,但由于边缘服务器计算能力存储能力有限,这一想法虽然能短期内使时延及能耗最小化,但在大数据任务中将很难实现。
现有关于边缘计算的计算卸载问题大多考虑任务截止时间,容量,计算能力等限制,根据指定优先级进行任务分配。工厂往往部署多个传感器收集不同的特征数据,利用机器学习决策树思想发现,任务中常存在很多决策无关的特征数据流,放弃无关数据的处理不仅可避免决策无关数据的传输开销,而且能减轻边缘端计算及存储压力,同时由于先到的处理优先级低的特征数据必须进行缓存等待优先级高的特征数据流到达,所以按特征数据流的优先级进行传输,可避免边缘服务器缓存过多导致容量不足的问题。
本文将基于边缘计算框架,联系机器学习算法和多数据流思想,对问题进行深入研究。
2. 系统模型
智能边缘计算的架构如图1所示,考虑多个任务集合,每个任务都含有若干个特征数据流。多传感器作为用户端,各自接收数据组成一个特征数据流。云端根据多任务需求生成决策树,并将训练好的模型放置边缘服务器上 [8] [9]。各个边缘服务器依照自身计算能力和存储能力选择是否接收用户端的计算卸载请求。
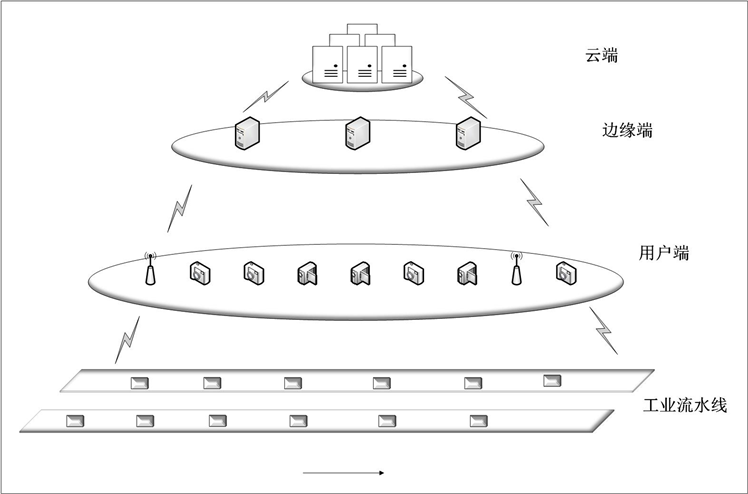
Figure 1. Industrial intelligent edge computing framework
图1. 工业智能边缘计算框架
3. 问题描述
为满足当下工业生产实时性需要,考虑任务相关性,在MEC (Multi-Access Edge Computing)多接入边缘服务器计算能力存储能力限制下,设计满足多个任务并存场景的计算卸载方案。应用场景图如图2。
本文以多任务平均决策时间为优化目标 [10] [11],首先对基于数据流相关性面向工业智能边缘计算的任务卸载方法进行建模。考虑
为一个数量为n的任务集合,每个任务
都含有
个特征数据流,由
表示,每个
。
表示特征
调度到边缘服务器e上所需带宽,
表示特征数据流
的数据量,
常用
表示。在不同计算调度方案中,
的卸载顺序不同,因此引入次序的概念,用字母m表示。
为第m个特征数据流传输开始时间,
为第m个特征数据流传输结束时间。由下式表示:
(1)
用
表示n个任务的对应决策时间,边缘服务器某一时刻j接收计算卸载请求的任务集合由
表示。故由(1)可得多任务决策时间为:
(2)
因此,优化目标多个任务各自完成时间的平均值为:
(3)
为保证调度方案可靠性,我们引入带宽约束,
表示并行计算的数据流集合:
(4)
因此,多任务计算卸载方法可以表示为:
4. 一种工业智能边缘计算中基于数据流相关性的任务卸载方法
一种工业智能边缘计算中基于数据流相关性的任务卸载方法,包括步骤:S1:MEC服务器依据不同任务的决策需求,生成相应的决策树,用户端收集特征数据,将同一任务对应的特征数据流归为一个特征数据流组;S2:用户端选择重复率最高的任务向服务器发送计算卸载请求;S3:服务器按重复率选择调度算法,接收任务所包含的特征数据组;S4:服务器计算任务的累积完成时间,以及计算此时多任务平均完成时间。
具体流程如图3:
1) 某一周期内用户端收集生产线数据并全部上传至MEC服务器上;
2) 服务器依据多任务的决策数据及结果,制定相应的决策树;
3) 将任务涉及到的特征编为一组;
重复上述步骤,生成所有任务的决策树并整理。
4) 计算任意K个任务的特征数据流重复率。用u表示。
5) 用户端选择重复率最高的任务向服务器发送计算卸载请求;
计算卸载请求为:
6) 计算K个特征数据流组中各个特征数据流的预期最小传输时间
;
7) 如果重复率高于阈值选择调度算法为重复优先算法,则将选定的K个特征数据流组中重复特征数据流按预期最小传输时间由小到大进行排序,依次排入调度表中(满足带宽限制的情况下可并行传输);
8) 当并行计算的某个特征数据流完成传输,则选择剩余特征数据流中预期最小传输时间最小的特征数据流排入调度表中(满足带宽限制)。若不满足带宽限制则安排预期最小传输时间第二小的特征数据流排入调度表中,以此类推,直到该服务器要接收的多特征数据流组中各个特征数据全部传输完成;
9) 如果重复率低于阈值选择调度算法为TMF算法(Topological Sort and Expected Minimum Completion Time First 拓扑排序及预期最小完成时间优先联合算法),则把服务器即将接收K个特征数据流组中的特征,依据决策树模型进行拓扑排序,依次排入调度表中(满足带宽限制的情况下可并行传输);
10) 当并行传输的某个特征完成传输,则选择剩余特征中拓扑排序靠前的特征排入调度表中。注意当遇到同一位次有多个特征可供选择时,将这些特征中预期最小传输时间的特征数据流排入调度表中(满足带宽限制)。若不满足带宽限制则将该位次下预期最小传输时间第二小的特征数据流排入调度表中,以此类推,直到该服务器把将要接收的多特征数据流组中全部特征数据流传输完成。
5. 结果评估
用python对两种算法进行验证,随机模拟了10,000组数据,将重复优先算法和TMF算法和传统贪婪算法(预期最小完成时间优先)以及普通卸载进行对比(如图4)。实验表明(如表1)面向工业智能边缘计算多任务并存场景下,在服务器计算能力允许的范围内,考虑避免重复数据多次卸载的重复优先算法和TMF算法以及预期最小完成时间优先算法因为处理数据量的减少,都比普通卸载时间优化13.71%以上。
其中,在多任务重复率低于32.6%时,重复优先算法与预期最小完成时间最优效果相仿,都比随机卸载时间节省15%~17%。而TMF算法比随机卸载时间节省21.93%。故在多应用重复率较低时,我们可采用TMF算法进行计算卸载。在多任务重复率在67.1%~92.7%时TMF算法与预期最小完成时间最优效果相仿,都比随机卸载时间节省15%~16%。而重复优先算法效果较优,相比随机卸载时间节省22.32%。因此,灵活根据重复率选择重复优先算法和TMF算法在解决此类问题上具有更高的优化性,满足了工业生产的实时性及可靠性需要。
6. 结语
本文运用边缘计算和机器学习技术,结合多数据流相关性思想。基于传统贪婪算法(预期最小传输时间优先算法),提出了一种工业智能边缘计算中基于数据流相关性的计算卸载方法,避免无关数据卸载、多任务场景下重复数据多次卸载及无序卸载导致的缓存过多,存储器容量不足等问题。仿真结果表明该方法相比传统算法具有更高的卸载效率,满足工业场景的实时性需求和可靠性需要。
参考文献