1. 引言
网络新闻在传播方式上具有流量化、去中心化、题文分离的特点,新闻标题既承担文章内容的概括作用,同时还作为文章链接负责将用户引导到新闻正文部分 [1] 。网络新闻内容多、数量大、更新速度快的特点,使用户逐渐养成快速阅读新闻标题并根据标题内容决定是否点击链接的“读题”式浏览习惯,也在素材趋于同质化的新闻行业中催生了“标题党”的产生 [2] [3] 。“标题党”新闻常使用过度夸张、歪曲事实、制造虚假新闻等手段,加工出引人眼球、耸人听闻的标题,以迎合、吸引用户。“标题党”新闻的泛滥,不仅影响用户获取所需的新闻内容,而且对网络新闻行业的健康发展以及网络和谐环境的构建造成恶劣影响。“标题党”现象已受到国家相关部门和社会各界的关注,相关部门积极采取各种措施对“标题党”新闻进行打击和消除,并加强在“标题党”新闻识别方面的研究。
2. “标题党”新闻识别方法的介绍及分析
2.1. “标题党”新闻识别方法研究现状
目前,针对“标题党”新闻识别的研究主要以“标题党”写作中使用的语言特征为主要研究对象,常用的“标题党”新闻识别方法可分为基于文本相似度的识别方法和基于机器学习模型的识别方法两大类。
基于文本相似度的识别方法主要针对“标题党”新闻中“题文不符”的现象,利用文本相似度计算对“标题党”新闻进行判断。2011年,王志超提出基于主题句相似度的“标题党”新闻鉴别技术,利用正文主题句集合与标题的文本相似度对“标题党”新闻进行识别 [4] 。2015年,罗佳提出基于潜在语义的“标题党”新闻识别技术,利用正文中的词频构建向量空间模型,奇异值分解后得到正文的塌陷矩阵,生成标题的文档坐标,通过计算文档坐标和与各段落对应向量间的余弦相似度进行判断 [5] 。2018年,赵帅提出基于改进型VSM-How Net融合相似度算法的“标题党”新闻识别方法,使用同义词词组的向量替代词向量对正文进行表达,利用改进型VSM结合余弦相似度来度量文本相似度 [6] 。2019年,陈彤从语言学角度,提取主题词后计算标题和正文相似度对“标题党”新闻进行识别 [7] 。
随着机器学习的兴起和运用,相关学者提基于机器学习的“标题党”识别方法,利用提取到的新闻标题及正文特征进行分类模型的训练,使模型不断学习“标题党”新闻的各种特征,并利用模型对“标题党”新闻进行判断。2016年,Potthast等人针对twitter中“Clickbait”现象,提取了三大类共215个特征进行模型训练,构建出“Clickbait”检测模型 [8] 。同年,Chakraborty等人利用多种机器学习分类模型,设计了一个浏览器扩展,以达到检测“Clickbait”的目的 [9] 。
2.2. 现有“标题党”新闻识别方法分析及本文方法介绍
“标题党”新闻识别方法的不断成熟,对“标题党”新闻起到了一定的控制作用。但随着网络技术与新闻行业的发展,新闻图片作为提高视觉吸引力和视觉感受的媒介,逐渐成为网络新闻中不可获取的一部分,目前网络新闻的内容往往也是由新闻文本与新闻图片组合而成的,新闻图片更是成为“标题党”新闻用于吸引用户的新手段 [10] 。因此,仅仅利用新闻文本的语言特征对“标题党”新闻进行识别的方法可靠性逐渐降低,不能够完全满足保障网络新闻健康传播的需求。因此,研究结合新闻图片信息和文本信息的“标题党”新闻识别方法具有十分重要的意义。
本文提出一种综合考虑新闻图片与新闻文本特征的“标题党”新闻识别方法,以提高对当前流行的“标题党”新闻的识别准确率。本文基于深度学习思想,利用图像描述等技术,充分提取新闻中的图片语义信息,并对新闻图片中的人脸图片及文本图片进行模型构建。对于提取到的多类型图片信息,本文提出一种图片和文本相关度评价指标,并将该指标融入“标题党”新闻识别模型进行“标题党”新闻的识别与判断。
3. 新闻图片特征提取
对图片信息的信息提取是本文的主要研究内容,通过对大量新闻的定量统计发现,新闻中的配图主要可以分为两类:一是人物、场景及物体信息等非文本图片,二是评论截图、通知截图等文本图片。二者在信息提取过程中需要侧重点略有不同,因此,为了提高对新闻图片信息的有效提取,针对不同类型的图片采用不同的提取方法。本文使用相关深度学习技术进行图片信息提取,主要由四个模块组成,分别是:文本图片信息提取、非文本图片信息提取,人物信息提取,和文本图片相关度计算,整体模型结构如图1。
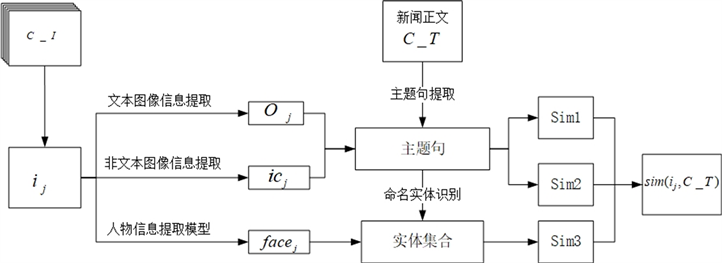
Figure 1. Image feature extraction flowchart
图1. 图像特征提取流程图
3.1. 图像语义描述与信息提取
本文使用融合场景信息的图像描述模型 [11] 获取新闻图片中的语义描述信息,获取新闻图像的图像描述,模型主要结构如图2所示。
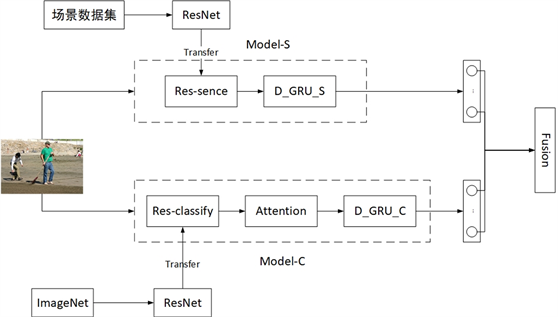
Figure 2. Scene image description structure diagram
图2. 场景图像描述结构图
Res-sence是用于提取图片场景信息的模型,Res-classify是用于提取图片中物体信息的模型,两者在结构上使用的都是ResNet 101网络结构。区别在于Res-sence是在场景数据集places-365和AI challenge的场景分类模型数据集上预训练的,而Res-classify是在ImageNet物体分类数据集上训练的。两个模型分别连接双层GRU解码器,得到侧重场景信息和侧重物体信息的图像语义表达,最后对概率进行加权平均计算,得到最终的输出。Attention代表软注意力机制,考虑到本文研究方法中,新闻图像信息的提取需在最大程度上与新闻内容相匹配,因此,本文在使用Res-classify模型对非文本图像进行物体信息提取时,融入软注意力机制的思想 [12] 。Fusion代表加权融合操作,在t时刻Model-S和Model-C的输出概率值为
和
,
和
表示权重,得到
表达式:
最终模型在AIC-ICC数据集(AI challenger图像描述竞赛数据集)上训练得到本文的场景图像信息提取模型,AIC-ICC数据集中数据分布表1所示。

Table 1. AIC-ICC data set distribution table
表1. AIC-ICC数据集分布表
图像描述常用的客观评价指标有BLEU,CIDEr等,但是考虑到客观评价指标主要是评价模型生成语句与参考语句的相似程度或者是评价生成语句与人类表达的差异性,这与本文的应用场景并不完全符合,本文选择人工评价的方式,具体的是设立四个评价等级,分别是非常好、好、一般、差,具体等级及对应等级描述如表2所示。
Table 2. Manual evaluation standard grade
表2. 人工评价标准等级
模型训练参数设置:
因为对于循环神经网络来说时间步的大小决定了网络的记忆能力,直接决定了在推断阶段网络能够生成的单词数,因此在解码阶段,将双层GRU模型的时间步设为30。在模型编码、解码结构联合训练过程中,考虑到GPU显存大小,设置Batchsize为8,本文使用Adam算法训练网络的参数,初始学习率为0.001,Adam的参数包括动量和衰减系数,分别设为0.9和0.99。
实验结果:
本文在AIC-ICC训练集中随机选取了500幅图片,对模型生成的语句进行了人工评价,具体实验数据如表3所示。
对于图片中的人脸信息提取和文本图像信息提取,本文使用开源的模型实现这两个模块的功能,文本图像信息提取使用的是文献 [13] 提出的CTPN文本框检测模型和文献 [14] 提出的CRNN文本识别模型。在人脸信息提取上,本文使用了文献 [15] 提出的MTCNN模型和百度的公众人物识别的API。
3.2. 图片与文本相关度计算
因为新闻中的图片作为新闻的一部分,图片的语义表达往往是和新闻的内容息息相关的。类似于文本新闻的“标题党”识别方法中使用正文文本与标题文本的相似度计算,本文考虑使用新闻图片和正文文本的相关度作为模型识别的一个特征,本文使用表4所使用的符号分别代表新闻中每个组成部分。
Table 4. The symbol of the main content in the news
表4. 新闻中主要内容符号示意
其中
,即
。故本文在研究新闻中的图片与新闻主体的相关度的时候主要考虑的对象是正文图片和正文文本。
针对
中一副图片
,因为
可能同时包含图像描述、文本信息以及人脸信息。将
经过图像语义描述与信息提取模型进行处理,得到一个三元组
,其中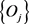 表示这幅图片经过OCR模型转换得到的文本信息;
表示这幅图片进过图像描述模型处理得到的图像描述;
表示这幅图片经过人物信息提取模型处理得到的人物信息。因为考虑到
和
是直接与新闻正文相关的文本信息,且本身具有一定的语义信息,我们可以将得到的
和
分别与新闻的正文的主题句进行直接的文本相似度计算,可以得到这两个部分与新闻正文的相关度的度量值sim1,sim2。
表示这幅图片经过OCR模型转换得到的文本信息;
表示这幅图片进过图像描述模型处理得到的图像描述;
表示这幅图片经过人物信息提取模型处理得到的人物信息。因为考虑到
和
是直接与新闻正文相关的文本信息,且本身具有一定的语义信息,我们可以将得到的
和
分别与新闻的正文的主题句进行直接的文本相似度计算,可以得到这两个部分与新闻正文的相关度的度量值sim1,sim2。
对于人物图像信息的使用,本文在对大量“标题党”新闻分析后发现,一些“标题党”新闻往往使用名人、政要的人脸图像吸引用户点击,让用户产生一种这篇新闻是与这个人物有关系的错觉,但是往往新闻的正文文本信息和使用的人物图像相关度很低。针对这个特点,本文考虑对新闻正文进行主题句提取后,对主题句进行命名实体识别操作,识别句子中的人名得到一个包含人名的集合
,对
和
进行比较,具体如下:
判断
是否是
的子集,如果
是
的子集,则认为这张图片和文章有关联,令sim3的值为1;如果
中并未包含
则sim3的值为0;如果两个集合中有交集,则利用Jaccard相似度计算方法,得到
,由此可以得到关于一张图片中的人物信息的相关度的
度量sim3,且sim3的取值范围为[0, 1]。
考虑到一副图片中并不一定全部包含这三类图像信息,故这三个值可能为空值,所以单独将这三个相似度值分别作为图片和文本的相似度度量是不合适的,会导致一幅图片因为某个方面的信息的缺失而被模型认为这张图片与文本的相关度为0。因为sim1和sim2本身是通过文本相似度计算得到,故本身的取 值范围是[0, 1],而我们从sim3的计算过程也可以发现,sim3本身的取值范围也为[0, 1],我们考虑使用计算三个值的均值,将得到的均值作为一幅图片和文本的相关度的度量值。计算方法如下:
其中,N为一幅图片中存在的sim值的个数,又因为
,所以

最终提取的新闻图片特征如表5所示。
4. 实验过程及结果分析
4.1. 实验设计与评价标准
4.1.1. 实验方案设计
本文设计了对比实验,验证本文提出的融合图像信息的“标题党”新闻识别方法的有效性。本文使用文献 [13] 的模型作为baseline,与本文的融合图像信息的“标题党”新闻识别模型进行对比实验。与原文不同,但是由于本文考实验必须使用、包含图像和文本两种模态的数据集,所以本文通过爬虫制作了包含文本数据和图像数据两种模态的新闻分类数据集,在这个数据集上对比baseline和在baseline中加入图片与文本相关度的模型效果,具体的实验模型设计如表6所示。
4.1.2. 评价标准
通过表7中的混淆矩阵,可以得到精确度、召回率、F1-值的计算公式:
4.2. 实验数据获取及预处理
本文使用Scrapy框架从一些新闻分发平台通过爬虫的方式构建本文的实验数据集,每条数据闻的正文、标题,文章类别,文章的作者,文章的发表时间,文章的评论数,文章的浏览量等数据。对爬取的新闻进行人工筛选和人工标注,最后获得实验数据3356条,其中非“标题党”新闻1700条,“标题党”新闻1656条。
数据预处理主要包括对图像信息的转换过程以及特征提取过程,具体如下:
1) 使用本文提出的图像信息提取模型对每篇新闻的图片进行信息提取;
2) 对文本进行分词处理,本文同样采用Jieba分词工具,Jieba分词目前被广泛使用,在多个自然语言处理相关任务中均取得较好的表现;
3) 本文在文本信息的表示上使用Word2Vec工具对数据集中的原始文本信息和图片转换出来的文本信息进行词嵌入模型训练,使用Skip-gram模型的训练方式,词向量的维度设置为128;
4) 使用余弦相似度计算每篇新闻的标题文本和正文文本的相似度,利用本文提出的文本图片相关度计算方法,计算获得每篇新闻的图片集合和正文的图片文本相关度。编写脚本,依据文献 [16] 的研究提取新闻的文本特征,并对全部特征进行特征筛选,最终得到模型的训练特征及每个特征的重要度评分如表8所示。
Table 8. Model training features and importance ranking
表8. 模型训练特征及重要度排序
4.3. 模型训练
在模型选择和训练方式上,为了保持单一变量,我们在baseline上采用与文献中相同的采样方式和分类模型,即采用有放回随机抽取的采样方式,分类算法使用随机森林分类算法。本文的分类算法模型实现主要使用的是Scikit-learn机器学习库,Scikit-learn是一个开源的机器学习Python库,其中集成了包含分类、聚类、回归等众多机器学习算法。为了避免模型训练过拟合同时可以使模型学习到更多的有效信息,本文使用K折交叉验证法训练模型避免过拟合,K值取10。
4.4. 实验结果
Table 9. Experimental data of “Clickbait” news classification
表9. “标题党”新闻分类实验数据
从表9中我们可以直观的看出,baseline在同时含有文本信息和图像信息的多模态新闻数据集上精确度是0.862,召回率是0.842,F1-score是0.852,这个结果与文献 [16] 中使用随机森林的最好成绩0.87相比,精确度有所下降,导致这个现象的原因应该是数据集差异,本文使用数据集一共是3356条,而baseline使用的数据集为808条,这对最后结果有所影响。而在baseline融合入图片特征信息后精确度是0.896,召回率是0.878,F1-score是0.887,相对于baseline,模型识别效果在精确度上有所提高,但是提高的幅度并不是很大,经过分析,本文认为可能有两个方面的原因,第一是因为数据集中部分图片“标题党”新闻中也具有“标题党”的文本特征,这一部分的信息,在忽略图片信息以后,依然可以使用新闻的文本特征去识别,而在加入图像信息之后,模型的检测效果有所提升,被提升出来的这一部分新闻,是仅仅包含图片“标题党”特征的新闻,这一类新闻在数据集中较少,因此导致了模型在评价指标上的提升效果有限。第二个导致模型在评价指标上提升较小的原因应该是本文使用的图像语义描述与信息提取模型在部分新闻图片与文字转换的结果上有所偏差,因为图像描述模型尽管已经在大部分图片文字转换任务中取得了较好的效果,但是依然有部分图片转换出来的效果较差,导致无法准确提取图片中的语义信息,直接影响到图片和文本相关度计算的准确性,使得图像信息并没有被充分利用。 “标题党”新闻的识别效果有所提升,可以检测出一些原本只依靠文本信息无法检测出来的新闻,在一定程度上验证了本文提出的图片和文本相关度这一特征的有效性。
5. 结论
本文给出了对于网络新闻“标题党”现象检测的一种全新的思路,对于网络新闻由文本和图像两种模态数据组成的情况,本文提出使用图像语义描述与信息提取模型提取图片中的信息,并设计了一种融合场景先验信息和注意力机制的图像描述模型,提出了一种使用图像语义描述与信息提取模型提取的文本信息计算新闻图像和文本相关度的方法,并对方法的有效性进行了实验验证,实验结果表明,融合了图像信息的“标题党”新闻检测模型,综合考虑了新闻的图片特征和文本特征信息,可以更加准确、全面的检测“标题党”新闻。