1. 引言
随着国内股票市场的逐步完善,越来越多的研究机构和公司投入股票的分析和预测研究。对股票指数进行分析预测,能够快速掌握股票市场的发展动态,也能一定程度上反映国家的经济状况。由于影响股票数据的因素复杂多变,且股票序列本身具有随机游走等特性 [1],使得股票预测成为经济领域的一大难题。
股票预测已有较长的历史。统计学方法是最先用于现代股票市场预测的方法之一,其通过对股票数据的整理和分析,预测股票价格的短期走势。其中较为成功的有自回归移动平均(ARMA)模型 [2],该模型由于对股票数据优异表现沿用至今。SVM [3]、集成学习 [4] 等机器学习的方法也常用于股票预测,王禹等人boosting的方法,在添加股票的纵向变化指标后预测股票走势 [5],在股票预测的精度上取得了一定的提升。深度神经网络也是现在主流的股票预测模型之一,在股票预测上优异的表现得益于其强大的非线性拟合能力。邓凤欣利用LSTM网络对股票价格的走势做了预测,其结果表明使用LSTM的预测精度水平较高 [6]。
在股票特征处理上,现有的研究大都使用特征归一化处理。同时在预测方式上,以拟合股票收盘价走势和预测股票涨跌为主。本文在已有研究的基础上,通过对股票交易的特征进行量化和编码,对股票价格的涨跌幅度进行预测。在网络结构上,选择LSTM作为量化股票预测的基本网络,使用量化后的数据对其进行训练,以预测股票价格的涨跌幅范围,并将结果和未将股票特征量化训练的模型做了比较分析。
2. 特征量化和模型结构
2.1. 股票数据集描述
股票价格的变动通常和多种因素有关,其中能直接影响到其变化的则是股票的基本交易指标 [7]。开盘价、最高价、最低价、收盘价以及成交量等5维数据是最为常用的股票交易指标,使用神经网络预测股票时,常将这5维数据作为模型的输入,预测股票的价格走势或涨跌变化。本文也使用这5维特征作为股票数据的输入特征。
在股票数据的选择上,使用中证100指数的成分股作为基础数据来源。沪深300是为了反映沪深股市超大市值公司的股票价格表现而挑选出的300只股票 [8]。由于该股票集的选取标准严格,其成份股市值高,影响大,所以研究该数据集的股票发展规律也有助于分析国内股票市场。
在数据集时间跨度上,本文使用2013年~2017年的沪深300指数的成分股票,并将筛选后的股票数据集划分为训练集和测试集。其数据集详细信息见表1。

Table 1. Overview of stock data sets
表1. 股票数据集概况
2.2. 股票的特征量化
在训练时选择包含多只股票的数据集时,由于各只股票受上市时间、公司规模等因素的影响,其股票价格差别较大,这导致模型难以学习整体股票数据的变化规律;除此之外,股票市场易受各种外部因素的影响,从而造成涨跌停等特殊情况,导致该时间段内的股票特征数值过高或过低。这样的数据对模型来说等同于噪声数据,会对模型的学习造成误导。因此本文在构建整体股票数据集时,将先对每只股票数据按其价格范围进行均匀量化,然后再将其合并到整体的数据集中。
在量化之前,本文先对因部分股票停盘而造成的缺失数据进行填充。填充方式为将缺失数据上一交易日的股票数据填充为缺失数据。这样在每只股票的时间维度上可以保持统一。
具体量化时,将单只股票的5维特征在最大值和最小值之间划分为4个区间,从低到高依次编码为1~4。然后按照每个特征值所属的区间,将其编码为对应的数值。
表2是原始的部分股票特征数据,表3则是按照上述方法进行量化编码后的特征数据。对比可以看出,在经过量化处理后,在同一时间段上,由于股票体量等因素造成的价格差异被消除了。同时,对同一只股票,其涨跌停的数据经过量化平滑后,数值变化波动较小,有利于过滤噪声数据。
除此之外,股票特征中成交量其量纲和其他4维数据不同,造成在数量级有较大的差异,而量化编码过程是在每一维股票特征上单独进行的,因此经过量化,原来量纲带来的影响也被消除,这样数据不用再经过归一化的处理。
Table 2. Partial stock characteristic data
表2. 部分股票特征数据
Table 3. Some stock characteristic data after quantification
表3. 量化后的部分股票特征数据
2.3. 神经网络结构基础
神经网络通过强大的非线性拟合能力,成为最为流行的人工智能模型之一,在分类和预测任务中都有优异的表现。它通过模拟神经单元的构造和功能来设计相关的网络模型,再通过不同的连接方式搭建不同的神经网络 [9]。
1986年Rumelhart等人提出的反向传播(BP)的前馈神经网络是最早提出的神经网络,其通过引入隐藏层来实现非线性计算 [10];循环神经网络(RNN)则在序列相关的数据上做了改进,通过在神经网络层之间引入有向循环连接,使其具备时序数据的记忆功能 [11]。但RNN在长期依赖的问题上,随着需要提取的依赖项的长度增加时,梯度将不会再更新,甚至出现梯度消失等现象,因此需要对RNN进行改进,以解决信息的长期依赖 [12]。
长短期记忆网络(LSTM)是RNN的一种改进网络结构 [13],相较普通的神经网络,LSTM加入了可控门单元。LSTM结构如图1所示,其包括输入门it、输出门ot、遗忘门ft等门结构,这些特殊的设计能够实现细胞状态Ct的更新,式(1)、(2)、(3)是3个门的更新公式。其中,σ表示激活函数,W和b分别表示权重矩阵和偏置,下标f、i、o代表遗忘门、输入门和输出门。ht − 1表示t − 1时LSTM细胞的输出,xt代表t时刻的输入。
(1)
(2)
(3)
在计算时,首先从当前时刻的输入和上一时刻隐藏层状态的信息中选择出要遗弃的部分,该部分是由遗忘门来实现的。然后由输入门决定神经单元要更新的值,通过Tanh函数更新神经单元状态。最终神经单元输出的状态由输出门决定,其先用Sigmoid层决定要输出的神经单元状态,然后将这些状态用Tanh函数压缩在−1到1之间。
2.4. 股票预测模型
本文使用LSTM网络作为基本网络结构,将量化编码后的股票特征数据作为输入变量。在模型输出上,使用涨、跌和小幅度涨跌等3类的分类方式做涨跌幅预测。
为了确定3个类别的划分界限,本文对股票数据集的涨跌幅做了统计。图2是股票数据集股票价格涨跌幅分布的直方图,可以看出,沪深300股票集的股票涨跌幅主要集中在±5%以内,也有部分样本出现了涨跌停的情况。

Figure 2. The rise and fall range distribution of the data set
图2. 数据集的涨跌幅分布
图3是以涨跌幅1%为界限的3分类直方图,从图可以看出,在涨(涨幅超过1%)、跌(跌幅超过1%)和小幅度涨跌(涨跌幅在±1%之间)的样本数量接近。分类预测中,多个分类的样本数均衡分布,能提高模型的精度。
因此,本文将股票的涨跌幅以上述分类方式做3分类,即在涨区间的即为0;小幅度涨跌区间编码为1;跌区间编码为2,并将这3个分类用Onehot表示为:[0,0,1]、[0,1,0]、[1,0,0]。将编码后的涨跌分类作为标签,用以监督模型的训练。

Figure 3. Sample distribution of three categories
图3. 3个分类的样本分布
在框架选择上,使用Tensorflow作为深度学习的框架,并使用GPU加速计算。在网络结构上,输入数据先进入一个全连接层,然后连接1层LSTM网络层。最后在输出端外接一个Softmax层,可将输出转换为各个类别的概率,从而输出预测的类别。神经网络内部节点数为64,初始的学习率为0.006。
图4是股票预测模型。由于使用3分类的预测方式,本文选择交叉熵函数作为模型的损失函数,用于评估模型预测的各类别的概率分布和实际分布之间的差异。预测值和标签值越为接近,损失函数的值就越小。在模型输出最终输出值后,需要将误差反向传播回去,不断更新模型的权重值,直至训练迭代结束。
3. 实验与结果
为了验证股票特征量化处理的预测效果,本文在训练数据集上分别使用经过量化编码处理后的股票特征数据和经过归一化处理的原始数据,其他的参数保持一致,训练后对应的模型分别为模型1和模型2。本文将处理后的数据集划分为训练集、验证集和测试集。对每只股票,将其数据的前80%作为训练集,剩余20%作为测试集。训练集中,又以8比2的比例将其划分为训练集和验证集。训练集用于训练调节LSTM网络参数,测试集用于评测效果。验证集数据用于判断模型收敛时的迭代次数,避免过拟合。
在模型评估上,本文除使用分类准确率作为判断模型优劣的标准外,还使用了精确率、召回率和F1值等指标,以较为全面的比对两个模型在预测性能上的差异。
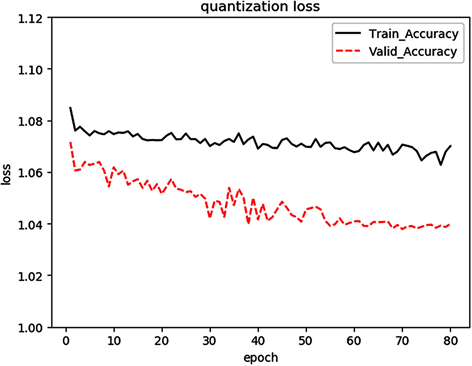
Figure 5. Model 1 loss function variation
图5. 模型1损失函数变化
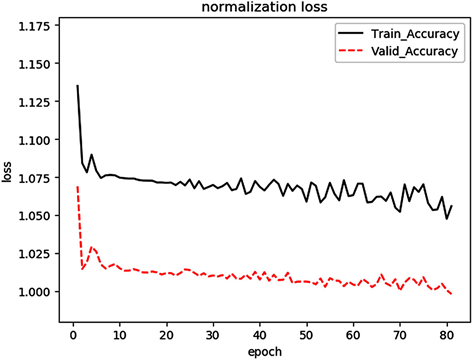
Figure 6. Model 2 loss function change
图6. 模型2损失函数变化
图5和图6分别是模型1和模型2训练过程中损失函数的变化图象。由图可以看出,使用量化的股票交易数据训练模型时,在迭代了60次左右收敛。相比使用非量化数据,模型收敛速度较快,在迭代20次时就已经收敛。在模型保存上,保存验证集损失函数最小时的模型,作为测试集的预测模型。
表4是模型1和模型2在测试集上的表现,由表可以看出,模型1在准确率和F1上的表现都优于模型2,这说明对股票交易数据进行量化处理可以有效的过滤噪声数据,使特征数据更加平滑,利于模型对股票价格变动规律的学习。
Table 4. Performance of different models in test set
表4. 不同模型在测试集的表现
为了测试模型单只股票预测效果,本文从数据集中随机抽选了3只个股,分别在两个模型上测试预测精度。
Table 5. Performance of single stock on Model 1
表5. 单只股票在模型1上的表现
Table 6. Performance of single stock on model 2
表6. 单只股票在模型2上的表现
从表5和表6可以看出,在单只股票预测上,由于个股的发展规律各不相同,预测精度也各有差别。在准确率上,单只股票在两个模型的表现较为接近,但在F1上,模型1要优于模型2。因此,在实际对单只股票进行预测时,可以使用对股票特征进行量化的方式训练模型。
4. 总结
在股票涨跌预测上,本文使用对股票特征量化的方式,对股票特征数据进行过滤和平滑,使用量化编码后的数据和原始数据分别训练股票预测模型。结果表明,在沪深300数据集上,经过量化处理的股票特征更容易让模型学习到股票价格发展的规律,其测试集的各项指标都优于使用原始数据训练的模型。在单只股票预测上,使用量化数据训练的模型表现也优于使用原始数据训练的模型。
但是,金融时间序列预测的数据来源于市场的真实数据,而市场运行于博弈过程中。如果某种预测方法明显优于其他方法,且在相应的市场操作过程中该预测方法起到一定作用时,则会随着时间的推移,其性能会下降,因此,也就不会有预测准确性能特别优异的算法存在。而本文提出的基于股票数据特征量化编码的数据处理方法,并结合LSTM网络构建的预测模型,其主要目的是在没有特别突发事件的影响下,在仅仅基于主要的交易数据本身(不考虑其他事件),尽可能获得一种适应能力更强的、预测准确度较高、性能稳定的预测方法。