1. 引言
显著性目标检测是根据人类视觉注意机制,从图像中检测并分割出最吸引人的区域 [1] [2]。近年来在计算机视觉领域有着广泛的应用,通常作为图像分割 [3] [4]、视觉跟踪 [5] [6] [7]、视频压缩 [8] [9] [10] 等的预处理阶段。
在显著性检测的研究过程中,研究者提出了许多显著性检测的方法,通常可以分为两类 [11] [12] [13]:自下而上和自上而下。自下而上的方法利用先验知识和深度学习方式来完成检测,这类方法一般效果较好,能很好的突出显著性区域,但是要执行大量的训练,软硬件要求高,特别是数据收集。与自上而下的方法相比,自上而下的方法不需要数据收集和训练过程,要求低。这些优点使得自上而下方法更有效、更容易在广泛的实际计算机视觉应用中实现。本文主要对后者展开研究。
近年来,大部分自上而下的显著性检测方法中,几乎是根据颜色对比、纹理、形状等特征来实现检测,检测效果较好,能够突出显著性区域。
Achanta和Hemami等 [14] 提出了一种基于频率调整的显著区域检测方法,该方法通过从原始图像中保留更多的空间频率内容,输出具有明确显著对象边界的全分辨率显著图。Wei and Wen等 [15] 从不同的角度提取背景信息,利用自然图像中两种常见的背景先验,即边界先验和连通性先验,为显著目标检测提供更多的线索。Lang和Liu等 [16] 提出了一种多任务稀疏追踪算法,该算法结合多种不同的特征用于图像显著性检测。根据一幅多视图特征描述的图像,通过对多视图特征矩阵进行联合低秩和稀疏分解,寻找一致稀疏的元素来推断该图像的显著性映射。Shen和Wu等 [17] 提出了一种统一的显著性目标检测模型,将传统的低级别特征与更高级别的引导相结合,在一定的特征空间内将图像表示为低秩矩阵加稀疏噪声。Xie等人 [18] 结合拉普拉斯稀疏子空间聚类和统一低秩表示提出一种基于超像素聚类和统一低秩表示的显著性目标检测,该方法能较好的凸显连续的显著性区域。Huang等人 [19] 充分利用背景信息,结合先验知识提出一种特征聚类的检测方法。
这些方法虽然效果较好,但是当检测到分布较广的显著性区域时,产生的区域连续性较不理想。针对此问题,本文利用背景的结构特征和统计信息,生成一个以背景信息为依据的初始显著图,该显著图能较好把整个显著性区域凸显出来。为了消除初始显著性区域中的背景信息,利用保边滤波器对初始显著图进行初步优化,减弱背景信息,增强显著性区域。最后为了减弱被显著性区域包围的背景区域,利用显著性目标区域中相邻元素的相关性,对显著性图进一步的优化,得到最终的显著图。通过以上三个过程,可以有效的抑制背景信息的显示,突出显示显著性目标区域,图1为本文实验效果图。
2. 本文算法
本文首先对输入的图像进行预处理,然后通过聚类和区域分布规则来生成初始显著图,最后对初始显著图优化,得到最终的显著图,算法流程如图2所示。
2.1. 初始显著图的构造
为了增加区域的连续性,减小算法的复杂度,本文采用SLIC (Simple Linear Iterative Clustering)超像素分割算法对图像进行预处理。SLIC算法是Achanta等人提出的一种性能较优的超像素分割算法,可以有效的把图像分割成轮廓清楚,区域均匀的像素块。根据人类视觉注意力特征和显著性研究发现,一般情况下,图像边界区域为显著性区域的可能性较低。也就是说,图像边界区域包含更多的背景信息。因此,本文基于此结论,提取图像的边界区域信息。将图片灰度化,选取图像边界的超像素(超像素标签),去除边界之外的超像素,生成一副只剩下边缘的图像。但是直接把提取到的边界区域作为背景信息来生成显著图是不合理的,因为,显著性区域也有可能接触图像边界。为了得到有效的背景信息,减少显著性目标信息,利用K-means聚类算法对提取的边界信息进行处理,这样充分利用了背景的统计信息和结构信息。通过实验发现当聚类的数目为3时,检测的效果较理想。通过以上过程,可以得到3个特征聚类N(k),
。利用生成的三个聚类构造初始显著图。在构造显著图时,分别考虑每个超像素与3个特征聚类在颜色特征和空间分布的关系。
显著性目标区域一般更能引起人的视觉注意,与背景区域的特征分布相差较大。因此,本文利用每个像素与背景分布的差异性构造分布显著图。如果像素与N(k)分布距离较远,则该像素为显著性像素。采用欧氏距离度量像素的分布差异性。每个超像素的分布显著性图值DFk的计算如下:
(1)
其中di表示i个超像素的空间位置,参数α = 8,qij表示i个超像素的向量特征,该特征是在CIELab颜色空间中由颜色和结构特征组成。qkj表示N(k)的质心,
。
通过上述计算可得3个基于背景信息分布的初始显著图。最后需要将三个显著性图融合成一个初始的显著图,融合方法如下:
(2)
其中βk表示第k个分布图的权重,βk的计算方法如下:
(3)
每个特征聚类N(k)所包含的超像素数量是不同的,一般情况下,图像边界的超像素大部分属于背景,所以,包含超像素数量较大的N(k)更能表示背景。
2.2. 保边滤波器对初始显著图进行初步优化
图像中显著性区域和背景区域之间有着比较明显的边缘分割,同时,如果一个区域被显著性区域包围,则这个区域为显著性区域的可能性较大。在初始的显著图中,显著性区域被加强凸显,与背景区域有着明显的区别。初始显著图中掺杂了大部分背景信息,为了抑制这些背景信息的显示,利用上述的先验知识,结合保边滤波器对初始显著图进行初步优化。在优化过程中,计算每个超像素的显著性值Spo。
(4)
其中,n是第j个超像素的相邻超像素的个数。
是一个判定第超像素是否与背景接触的因子,若与背景区域接触,值为1,否则为0。如果一个超像素与周围像素的差异性较大,则认为该超像素是显著性区域的边缘像素,否则不是。超像素与周围像素的差异性由方差来度量,方差可以显示该像素与周围像素的特征差异性,相同区域像素的特征差别小,方差小,不同区域差别较大,方差就大。
2.3. 利用相邻像素的关系进一步优化Spo
虽然通过保边滤波器优化了显著性图,但是对于复杂性较高的图像来说,显著性图中还包含了较多的背景信息,为了进一步抑制背景信息的显示,本文提出了一种通过建立相邻元素之间关系进行优化的方法。一个区域一般与其周围的像素有很大的关联,可以根据一个超像素与其相邻超像素的差异性来确定其为显著性的概率,经过多次迭代计算相邻像素的关系来增强显著性区域。本文迭代次数设置为6,优化方法如下:
(5)
其中,S1 = Spo,C是超像素之间的关系矩阵,D是基于最短路径的权值矩阵,F是影响因子矩阵,
是迭代次数。
超像素之间的关系矩阵C计算方式如下:
(6)
其中,
,
,M是超像素的个数。
影响因子矩阵F计算方式如下:
(7)
其中,
是超像素i与j的位置关系,
是超像素的特征关系,
。
最短路径的权值矩阵D的计算如下:
(8)
其中,
,G是超像素i相邻超像素的个数,
是相邻超像素的特征欧氏距离,
。
3. 实验结果与分析
选用ECSSD和MSRA-1K数据集作为验证算法有效性的数据集,ECSSD和MSRA-1K数据集分别由1000张复杂的自然图像构成的数据集。实验平台为:Window 10 系统,i7-9750H CPU,Matlab 2018。实验参数设置:超像素分割数目为600。对比实验分别为wCtr_opt [20],SF [21],GS [15],MR [22]。wCtr_opt是Zhu等人利用背景连通性和空间布局的特征提出地一种鲁棒性检测方法。SF是Perazzi等人基于对比度滤波提出的一种显著性区域检测方法。GS是Wei等人从背景先验出发,根据背景优先级提出的一种检测方法。MR是Yang等人利用流形排序思想,基于背景和前景的空间分布和连通性提出的一种检测方法。
3.1. 定性分析
图3是几种算法的实验效果图,其中Image是原图,GT是真值图,OUR是本文算法效果图。

Figure 3. Experimental results of different algorithms
图3. 不同算法的实验效果
第一幅图中的显著目标为树叶,背景区域中右上角和左下角区域颜色与树叶的颜色相近,容易被误检为显著性区域,可以从wCtr_opt、SF、GS算法的效果图看出,本文算法和MR算法很好地过滤了这些影响区域,但是本文算法检测出的目标轮廓比MR算法更清楚,更接近GT图。第二幅图中的显著区域为白马,第三幅显著目标为中间的大图标,从效果图可以看出,本文算法更加接近GT图。第四幅图的显著目标是两个黄色的路标,几个对比实验中,MR算法把目标区域包围的区域误检为背景区域,wCtr_opt、SF、GS算法的显著区域不清楚,或者包含背景区域,本文算法效果相比更好。第六幅图中的显著性区域包含与背景区域颜色相近的区域,四种对比算法的检测结果与GT相比,都不完整,本文算法很清楚的检测出整个目标区域,结果更加接近GT图。从实验效果图和分析得出,本文算法对细节的处理效果更好,更能完整的检测出显著性目标区域。
3.2. 定量分析
定量分析评估指标选用精确度Precision、召回率Recall和综合评价指标F-measure。精确度是指正确分配的显著性像素的百分比,召回率是指分配的显著性像素相对于显著性像素的真实数量的比例。使用范围在[0, 255]内的不同阈值,将检测结果图与GT图二值化,并进行比较,得到精确度Precision和召回率Recall的值,绘制Precision-Recall (PR)曲线。综合评价指标F-measure由精确度Precision和召回率Recall计算得到,计算公式如下:
(9)
(10)
(11)
其中,
是检测结果的二值图,
。
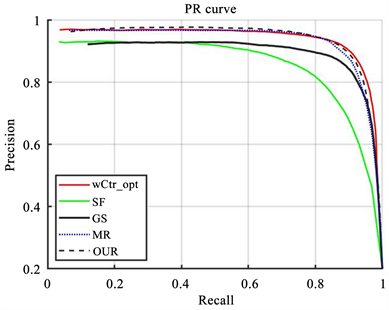
图4、图5分别给出了五种算法在各数据集的PR曲线图和F-measure值条形图。从图4中可以看出,本文算法在两个数据集上的值均高于其他四种算法。图5中,本文算法的Precision、Recall和F-measure均高于其它算法,算法性能优异。
 (a) MSRA-1K
(a) MSRA-1K  (b) ECSSD
(b) ECSSD
Figure 4. Comparison of PR curves of five algorithms on two datasets
图4. 五种算法在2个数据集上的PR 曲线对比图
 (a) MSRA-1K
(a) MSRA-1K 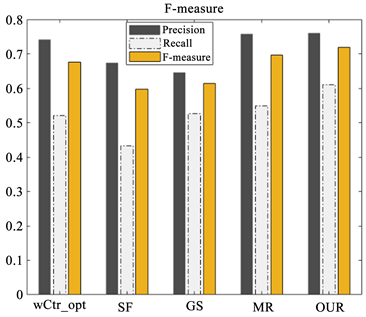 (b) ECSSD
(b) ECSSD
Figure 5. Comparison of F-measure values of five algorithms on two datasets
图5. 五种算法在2个数据集上的F-measure值对比图
3.3. 算法时间复杂度对比
表1中给出了五种算法平均处理每幅图片需要的时间对比。由于本文算法在每次更新优化时,要不断搜索相邻元素来建立关系,更新的次数越多,花费的代价较高。

Table 1. Algorithm running time comparison (unit: s)
表1. 算法运行时间对比 (单位:s)
4. 结束语
本文提出一种基于背景相邻关系优化的显著性检测方法,利用背景区域的统计特征信息和空间结构分布信息,建立相邻像素之间的关系,通过不断更新优化显著性区域来提高检测的准确性。在两种不同的数据集上进行测试,并与其他性能较好的算法对比,结果显示本文算法的效果更好,准确性较高。由于本文算法的时间较高,下一阶段将如何降低算法的时间,提高算法的效率作为研究。
基金项目
国家自然科学基金项目(61801005),安康学院校级项目(2019AYQJ03),陕西省教育厅项目。