1. 引言
抑郁、焦虑等心理疾病是常见的心理疾病,并伴有思想和行为异常。根据世界卫生组织数据 [1],全世界大约有20%的儿童和青少年患有精神疾病,而由于精神健康引起的自杀是15~29岁人群的第二大死因。精神疾病不仅是心血管疾病和慢性疾病的危险因素,也是基础疾病患者疗效和预后的重要因素。
然而,心理健康的诊断和治疗仍处于效率低下的局面。心理量表已被国内外综合性医院广泛应用于焦虑、抑郁症的诊断。其中,PHQ-9/GAD-7量表对消极情绪的特异性和阴性预测值在90%以上 [2]。然而,这些量表缺乏客观的评价依据,难以探索人为掩饰下的真实情感。在治疗上,低收入国家里每个人每年花在精神健康上的费用不到0.25美元,超过75%的精神病患者根本得不到任何治疗 [3]。如何提高精神疾病的诊治水平,对于预防各种亚健康疾病,提高生活质量具有重要意义。
随着心理学的发展,心理学界对情绪识别的研究主要集中在情绪分类模型等影响情绪识别的因素上。此外,如何判断情绪也是一个重要领域。众所周知,日常中可以通过面部表情,声音和手势,甚至行为来判断情绪。面部表情是基于视觉的情感分析的重要模式。1971年,Friesen和Ekman设计了面部动作编码系统分析实验来分析自发性情感表达 [4]。从语音、文本和多模态融合中提取信息也是一种重要的方法 [5]。Luengo发现了6个能够区分不同情绪的声音韵律特征,分别是声音信号的平均值和方差,韵律的能量对数和基本对数的动态范围,基本频率的平均值和对数斜交 [6]。然而,这些变化可以被人们的主观意识所控制。当一个人经历情绪失衡时,其心率、血压和其他生理信号也会发生变化,不易受到意识的影响 [7]。因此,如果能够识别出生理信号的属性,即可以推断出人的情绪。考虑到测量时的便携性需求,本文选择光电容积脉搏波(photoplethysmography, PPG)信号进行分析。PPG信号是由人体的自主神经系统和内分泌系统直接调节的 [8],其变化反映了血流量、总外周阻力、血管弹性和其他参数的变化。PPG 信号直接反映心血管状态,间接反映了神经系统对循环系统的影响。此外,PPG信号还具有无创检测和快速响应等优点,对可穿戴设备的应用以及提高测量和识别的便携性具有重要价值。
目前,许多学者从分类方法上进行了探索。为了找到最好的特征,研究者们提出了各种各样的生理特征,包括时间/频率、熵、几何分析、子带光谱、多尺度熵 [9] [10] [11]。这些手动特征提取方法可以直接解释情绪状态的变化,但也存在精度低、泛化能力差等缺点。随着深度学习的发展,许多研究也开始使用深度学习框架,在基于生理信号的情绪识别领域进行探索。Lee等学者分割并连接信号,以PPG和肌电图(electromyogram, EMG)同时作为输入,利用卷积神经网络提取特征,分别从效价和唤醒的四个等级进行分类。各组平均正确率达到了83% [12]。Hassan等将无监督的深度信念网络应用于融合观测的PPG和另外两个生理信号的深度特征提取中,得到一个特征融合向量,用对五种基本情绪进行分类 [13]。Singh等将递归神经网络应用到实时监控系统中,以识别驾驶员的情感状态,并基于皮肤电反应和PPG,累计计算出驾驶员压力水平 [14]。Kim提出了一种基于卷积长短时记忆网络和基于时间裕度的损失函数的稳健生理学模型——深层生理情绪网络,用于从PPG和双极性脑电信号中分类情绪 [15]。
在以往的研究中,识别的准确率得到了一定的提高,但是只有少数方案进入实际应用,即计算资源消耗、准确率和设备实用性之间未能处于平衡状态。从这一角度出发,本文提出了只使用PPG信号作为外围输入的方法进行情绪识别。通过对脉搏波的特征点进行自动检测,提取出信号特征,分析比较了不同机器学习算法的性能。结果显示,只使用PPG信号在保证了准确率的同时,也能实现设备快速地响应。
2. 实验数据与预处理
2.1. 实验数据
根据数据采集实验设计的合理性和采集的原始数据的有效性,本文使用了开源数据库MIT情感识别数据库 [16] 进行情感四分类实验,以验证实验方案在不同数据库下的稳定性。
MIT情感识别数据库包括几个独特的情绪模式,如平静,愤怒,悲伤,喜悦等。数据库收集了一个受试者在32天内的受情绪激发试验下的生理信号数据。每次试验都要求受试者坐在椅子上,同时佩戴PPG传感器和耳机。耳机中的提示音提示单个情绪激发开始,受试者将观察到各类激发情绪的图像,每类按照固定的顺序出现:平静,愤怒,悲伤和快乐,出现周期持续3~5分钟。在每次试验阶段,大约30分钟的数据被记录下来,采样频率为20 Hz。由于硬件故障,最终收集了20个完整的数据集。
2.2. 预处理
从数据库获取的时域信号会经过以下步骤完成预处理过程。
首先,考虑到人体心率一般不会超过180 bpm,PPG信号的基频信号应在3 Hz以内,而信号中高频噪声的频率集中在50 Hz及以上,因此,使用截止频率为20 Hz的巴特沃斯低通滤波器对原始信号进行滤波;
其次,为了消除信号的量纲数据差异,便于后续的分析,将信号进行min-max标准化如式(1),将数据归一化到[0, 1]范围内;
(1)
信号处理效果如图1所示。
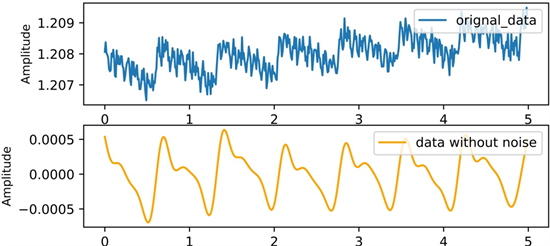

Figure 1. Signal processing—filtering and normalization
图1. 信号预处理过程——滤波和归一化
最后识别每个周期内波形的波峰和波谷,获取对应的索引值,如图2所示。
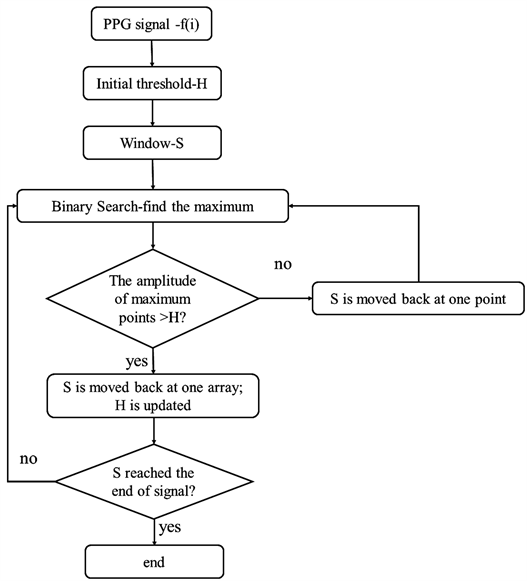
Figure 2. The process of finding the peaks and troughs
图2. 波峰波谷的识别过程
本文采用阈值法和移动窗口法 [17] 提取波峰波谷。PPG信号的采样频率为fs,一个脉搏周期长度约为0.75 s。首先,设置了一个包含了
个点的窗口,即包含了L个点的时域序列S,
。然后,使用二分法,搜索该序列中的最大值点。以
为算法起始点,如果该点满足以下条件,即被视为S的一个波峰。
(2)
(3)
(4)
其中,H是初值为0.9的阈值,
。
以一个脉搏周期为间隔,将窗口从信号的开始移动到末尾,并在每个窗口中搜索最大值。通过自适应方法更新H:
(5)
其中,
是当前窗口波峰点的幅值,
。
若不满足式2~4,则以1个点为间隔,将窗口向右移动形成新的窗口
,以
为新的起始点,重复上述步骤,直至找出整个PPG信号的所有波峰点。
根据PPG波的属性,峰值左侧的第一个最小值是波谷点。波谷和波峰之间的时间间隔约为周期的1/10。通过同样的方法,可以通过一个包含
个点的新窗口找到每一个周期内的波谷。脉搏周期T可通过相邻波峰点的间隔来确定。波峰波谷点的识别结果如图3所示。脉搏波的波峰波谷点都可以准确地提取出来,并计算出相邻峰值点的时间间隔和当前心率,以便后续分析。
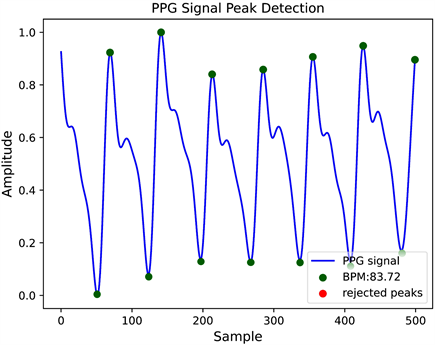
Figure 3. Detection result of peaks and troughs
图3. 波峰波谷点检测结果图
以第一个波谷点为基准,本文在MIT数据库中分割了20个来自不同情绪的信号片段(4种情绪,每一种情绪有5个序列),并将其放在同一个时间轴上进行比较。如图4所示。在图4(a)中,坐标轴内放置5个平静下序列(蓝色表示)和5个喜悦下序列(粉色表示)。图4显示了相同/不同情绪信号的显著趋势。相同情绪的多个序列处于相似的状态,而不同情绪下,超过5 s后的序列片段,在频率或振幅上有直观差异。
因此,本文选择切割信号段来创建网络的输入。以第一个波谷点为起始点,截断7 s的信号段作为输入。

Figure 4. Comparison of PPG sequences in different emotions
图4. 不同情绪下,PPG序列对比
3. 实验方案
为了分析该模型的效果,本文使用了MIT情感识别数据库中的4个类780个序列(每个序列有140个点)。其中,有异常信号的序列被剔除。

Figure 5. The whole classification scheme process
图5. 整体识别方案流程图
整个实验方案分为两个部分,如图5所示。第一部分是使用传统机器学习方法对手动提取的特征进行分类。第二部分首先是将一维卷积神经网络(One Dimensional Convolutional Neural Network, 1D-CNN)作为分类器,得到一类分类结果;然后使用中间层的输出,作为机器学习分类器的输入,再进行分类,得到另一类分类结果。所有的程序都是在Core i5,3.2 GHz的计算环境下,使用python 3.6并搭载scikit-learn0.24.0、TensorFlow2.1.0和Keras2.3.0实现。
3.1. 机器学习分类
脉搏信号会因情绪状态的改变而发生一定程度的变化,通过计算出脉搏信号在时域下的形态变化,如周期、面积、幅度等变化,使用机器学习分类器学习这种变化规律。基于已有的数据生成识别模型,在未知情绪状态下,计算有关参数,提供相应的判断。
特征提取包含三个方面——时域、频域和非线性。时域特征包括信号的峰值点、最小值点、周期、其特有的特征量及短时的心率变异性分析(Heart Rate Variability, HRV)等,它们能够直观地体现该信号的时域特点,解释其在医学上的生理意义。频域特征主要通过快速傅里叶变换和谱分析的方法求得信号的幅值谱、功率谱,根据维纳–辛钦定理计算功率谱密度。非线性动力学分析按一定采样周期去测量得到的时间序列数据蕴涵着原系统的动力学运动信息。根据相空间重构理论,利用测量数据构筑一个抽象的高维空间,计算出高维空间特征参数:关联维数、最大Lyapunov指数和样本熵等 [18]。从序列中提取出心率、波峰波谷、心率变异性、血管收缩时间和血管舒张时间等24个特征,并利用这些特征构成特征向量。表1列出了所有的24种特征参数名称。

Table 1. 24 features manually extracted from the PPG sequences
表1. 由PPG序列手动提取得到的24个特征参数
随着对分类问题研究的深入,越来越多泛化性高、稳健性强的算法涌现而出。本文选择比较了来自三个方向的机器学习分类器,一是具有聚类思想的K近邻算法(K -Nearest Neighbor, KNN),二是具有最大边距决策思想的支持向量机(Support Vector Machines, SVM),三是具有集成学习思想的分类器,其中根据集成和拟合角度的不同,选取了随机森林(Random Forest, RF),AdaBoost (ADA)以及梯度提升决策树(Gradient Boosting Decision Tree, GBDT)进行分析比较。所有算法经随机参数搜索法,在有限的一定范围内的超参数空间进行参数的随机组合,用以参数调优并获取当前模型的最优结果。表2展示了各类算法的具体参数。
Table 2. Parameters of machine learning methods
表2. 机器学习方法的参数
3.2. 1D-CNN
该部分首先将1D-CNN作为整个分类器得到一种分类结果,然后将该网络中间层的结果作为特征,使用3.1节中分类效果较好的三个分类器进行分类得到另一种分类结果。
图6展示了1D-CNN的具体结构。输入的CNN是一个经切割后的PPG 信号片段。整个结构包括两对具有激活功能的卷积层和池化层C1、C2、S1和S2。C1包含16个步长为1,大小为3 × 1的卷积滤波器,因此C1层将输出16个特征图。C1输出在池化层S1中进行降采样,以将特征减少到只有有意义的特征。最大池化层S1用于返回10 × 1过滤器中的最大值。C2包含64个大小为5 × 1卷积滤波器,最大池化层S2的大小为5 × 1。为了避免过拟合,在C1后引入一个批量归一化层,将神经元输入的分布改变为均值为0,方差为1的标准正态分布,解决了梯度消失问题,提高了学习收敛速度。采用整流线性单元作为激活函数,增强了层间的非线性,提高了运行速度。
为了验证1D-CNN是否具有良好的特征提取效果,采用t分布随机邻域嵌入(t-Distributed Stochastic Neighbour Embedding, t-SNE)算法进行降维处理,并对多类样本提取的特征向量进行可视化。随机邻域嵌入(Stochastic Neighbour Embedding, SNE) [19] 的思想是,如果数据在高维空间是相似的,映射到低维空间的距离也是相似的。它将不同类数据之间的距离视为条件概率正态分布(高维和低维样本分布均视为正态分布)。利用Kullback-Leibler发散距离来保证映射后的分布尽可能相同。t-SNE [20] 简化了SNE的梯度公式,在低维空间中用t分布代替正态分布,扩大了距离较大的簇之间的距离,解决了低维空间的数据拥塞问题。图7展示了从MIT数据库中三类情绪样本信号段内,提取的32维特征向量经过t-SNE算法降至3维后的可视化结果,其中,每个颜色代表同一类数据。由图可知,同一类间的点聚合得很紧密,不同类之间的点存在较明显的疏远。说明1D-CNN具有良好的特征提取效果。

Figure 7. Visualization of multiple feature vectors after dimensionality reduction
图7. 多维特征向量降维后的可视化
4. 结果与分析
本文按照7:3的比例对MIT情感识别数据库中四类情绪对应的PPG信号进行了训练集和测试集的划分(训练集546组,测试集234组),保存了训练模型,计算出了识别单组样本识别消耗的时间,对不同识别手段的结果进行了比较,如表3所示。
Table 3. Comparison of different classifiers
表3. 不同分类方法比较
表中前5行为3.1节的结果。四分类任务中,GBDT的准确率最高,达到了49.7%;由于分类算法简单,单个样本识别周期短,每种算法均不超过0.2 s。但从总体上看,手动提取特征并结合传统的机器学习分类器,该方案的性能并不佳,分类的准确率使该方案没有良好的实用性。由于手动提取特征存在有几个局限性,一是不能表示信号的细节,在提取特征时不可避免地会出现信息的丢失;二是时域特征和频域特征在短时间内没有意义(例如心率变异性相关的时域参数,在长时计算中会更为准确)。因此,不适合用手动计算特征的方法来进行短序列信号的情绪识别。
于是,在第二部分开展了深度学习的研究。与手工提取特征不同,深度学习可以自动且全面地提取特征,3.2节的计算结果优于3.1。结果显示,1D-CNN直接进行特征提取和分类的准确率达到了51.3%,与前一部分的计算结果相差不大,而且计算机的资源消耗也在增加。在提取出1D-CNN的中间层输出作为分类器的输入之后,分类准确率最优可以达到96.2%,而非最优的其他模型平均分类准确率也可以达到76% ,并且消耗的时间相较于单使用网络来说下降了一些。这表明使用PPG信号和1D-CNN结合分类器的思想进行情绪识别,可以在保证正确率的前提下,减少运算时间,在实际运用中体现出明显的优势。
5. 总结与展望
本文提出了一种只使用光电容积脉搏波作为外围输入进行情感识别的方案。首先,对收集的信号进行了低通滤波和归一化。其次,使用阈值法和滑动窗口法相结合的手段,对PPG信号的波峰波谷点实现自动检测。然后,将信号分成若干个序列,分析了不同情绪序列的差异。最后,实现了包括GBDT在内的五种机器学习分类器,以及1D-CNN和以1D-CNN中间层输出为分类器输入的9种分类手段,并存储了训练模型,测试了这9种模型在实际分类中的性能。
本文对MIT情感识别数据库进行处理,得到4类情绪样本,并用上述方案进行了测试,准确率最高达到了96.2%,并且在此情况下单个样本的测试时间为0.42 s,验证了PPG信号在情绪分类方面的良好性能,以及在识别应用中的可行性。整个方案对便携式测量和可穿戴设备具有很大的潜在价值。未来的工作将集中在联合心率变异性来分析病人的抗压状态。通过计算心率变异性,可以得到交感神经和副交感神经神经张力及其平衡状态,进而得到心血管系统的功能状态,从而可以评价抗压程度。从临床实践中扩展数据集以获得更准确的结果,并利用哈希学习实现大量样本的快速检索和个性化检测,节省训练时间。
NOTES
*通讯作者。