1. 引言
随着互联网便捷化的发展,以及新闻信息传播媒介的逐步转变,新闻资讯信息的传递速度达到了前所未有的水平。在金融证券领域的服务类别中,用户阅读金融类资讯的使用频率远超于其他金融服务,相对应,上市公司重大事件新闻的传播影响力也在快速增大。例如18年7月发生的长生生物疫苗事件,国家药品监管局早在同年7月18日便发布公告称长生生物疫苗研究中违反了相关规范,直到7月22日,一篇《疫苗之王》的公众号文章将长生生物推至风口浪尖,其股票价格一路下跌同时带动同概念生物疫苗相关股票价格一路狂跌。从类似事件的发生我们可以发现虽Fama [1] 于1965年提出了“有效市场假说”,但该假说的前提假定为:于证券市场参与者来说,人们均处于极其理性的情况下,同时掌握了金融证券市场完整的信息。但在真实的金融领域,由于中国的证券交易市场仍处于初期阶段且影响因素繁多,投资者往往难以自主对海量数据即时准确做出判断从而成为证券市场中的被动者。因此在计算机技术、深度学习逐渐兴起的背景之下,针对证券市场企业实体的情绪分类对于投资者以及投资机构来说尤为重要。近年来,在针对证券领域新闻文本的情感分类理论研究中,研究学者往往仅从文本化非结构性数据中获取相关影响因子或有效信息,而这一过程往往忽视了金融证券市场是一个综合整体的实体存在,对当前证券领域缺乏准确普遍的建模方法。故在本文中我们通过搭建面向情感分类的证券领域知识图谱,使证券领域实体之间的关系图像化,即为通过构建图边关系进一步对市场企业实体的情绪进行有效的分析打下基础。
在对金融证券领域的文本信息转换为知识图谱搭建中,首先需要考虑的问题是如何获得证券领域内的新闻文本和基本面数据,以及如何实现将其文本表述转换为计算机能够识别的表示方法。在传统的机器学习方法中,常需要充足的数据量来支撑参数调整优化,然而在特定专业领域,模型学习的效率往往由于上述假设过于严格而难以达到很好的效果。事实上,这些领域可用数据量缺失,使得训练样本往往不足以供复杂的机器学习模型进行训练从而得到一个可靠的生成预测模型。因此在本章,我们首先构建实时的定向爬虫框架来获取所需的证券领域新闻文本以及半结构化企业基本面数据。
其次本文针对非结构化数据证券领域新闻文本,提出基于命名实体识别的方法对证券领域知识图谱进一步情感分类标注的扩充。虽然命名实体识别模型搭建在现有的解决方案中已较为普遍,但由于证券领域新闻文本相关数据常存在一系列专有名词,大多数仅通过人为设立规则和模板方法为主,统计学习方法多作为辅助决策来完成。针对证券领域有标签数据常存在人工标注慢等此类问题,在本文中我们提出了一套针对新闻文本的基于迁移学习的命名实体识别模型的搭建框架,通过同领域不同任务的参数迁移方法有效解决了该类问题。
最后,针对现有的证券领域中缺乏一种较为准确普遍的建模方法去体现企业实体之间的情绪表现关联,我们基于已爬取的半结构企业市场基本面数据,提出了一套证券领域知识图谱的构建框架。另外考虑到金融证券领域的特殊性,股市参与者对实体企业的信心往往能迅速表现于相应股价表现行为上。故在文中,我们将证券领域知识图谱与新闻中基于实体识别所得实体的市场涨跌表现进行融合,生成了面向情感分类的证券领域知识图谱。
2. 金融财经新闻文本数据的收集
在本章中,我们主要提出了一种针对证券领域的定向实体爬虫框架,为后续研究做出数据支持。之后对数据的分布与基本类型进行分析,设定规则为后续模型制作样本提供数据基础。
2.1. 基于上市企业数据的获取
随着网络信息的快速膨胀,如何准确快速的提取互联网信息已经成为一大新型挑战,爬虫技术即人为构造一套框架可以自动的从互联网中定向获取所需信息。在定向获取信息的过程中,人们往往会定义一套规则选择性下载目标信息,即常讲的定向爬虫。
如图1所示即为我们本节的金融领域非结构化新闻文本爬虫框架。首先,我们需要确定数据信息来源,并分析所需数据结构。本文中我们不仅仅要获得新闻文本等非结构化数据并存储至本地,同时需要获得其实体在股票中的基本面信息,例如地点、概念、板块等作为后续知识图谱构建关系实体的基础。根据爬虫的难易程度、新闻发布方的权威性等方面,我们在新闻资讯类非结构化数据方选取了以新闻权威性为主要竞争力的东方财富发布的Choice [2] 金融终端,作为本文的信息来源方。至于基本面数据半结构化数据,存储模块中我们设置了接入Tushare [3] 的API端口函数存储至本地。

Figure 1. A crawler framework for unstructured news text in financial domain
图1. 金融领域非结构化新闻文本爬虫框架
其次,在我们从互联网直接获取非结构化数据的过程中,我们通过Fiddle记录下客户端与服务器交互过程中所有的HTTP请求,并对网络请求(request)和回复(reply)进行进一步的分析,查找得到了我们所需网页的请求包,我们相应进行伪装处理模拟器header进一步的访问,并依据预定义的爬虫规则从互联网上下载指定的数据。此外在制定获取网页的函数时,我们同时要考虑并行、执行频率等相关因素。由于本文涉及数据的并行化抓取,采用Python多线程模块处理所需定向URL。在解析网页源代码中,网页文件一般以代码段的形式呈现,在经过Service处理后通过设计URL循环函数对定向更改参数的每一条链接进行数据抓取。利用DOM解析器,依据预定义的规则如取< p >标签下的可用文本将信息自动化地抽取出来。由于网页的结构复杂多样,基于规则的自动化抽取往往会产生一些错误,因此还需要清洗模块修正解析的结果。如图2所示,其网站的HTML中并没有明显区分标题与正文的不同,但文中有“【xxx】”的标记如“【中标项目】”来区分不同的文本板块。
最后需要对我们所获得的数据进行持久化的存储并清洗。在本节中我们主要存储与mysql数据库中,运用python中pandas.tosql进行批量存储。主要保存为字典类别的方式方便后续数据处理中转换为dataframe进行进一步操作。当我们存储到数据后,进一步清洗数据于python中的scrapy模块ItemLoader中进行,定义一个默认的全局输出处理器,再通过TakeFirst函数取出相应文本段,若为空,便丢弃整篇新闻文章。

Figure 2. Correspondence diagram of HTML page structure and key text
图2. HTML网页结构与关键文本对应图
2.2. 数据的分类与分析
在对本文的数据进行分类分析时,需要分别对半结构化数据以及非结构化数据两个场景进行考虑。
2.2.1. 半结构化数据的处理
首先我们对企业实体在股票领域的基本面半结构化数据进行预处理。通常的证券类数据包含日间交易数据、所在地域、所属行业、主营业务等基本面数据。在考虑相关方面数据时,主要目的为进一步发现证券领域企业实体间的隐藏信息。例如,当某日的白酒行业爆出“黑马”时,相应白酒类股票实体均表现优良。故在本文第三章构建令全领域知识图谱时,我们将行业、主营业务等概念同样以“实体”加入至知识图谱中。具体数据存储格式如表1所示:

Table 1. Example of crawler data storage format
表1. 爬虫数据存储形式示例
具体为知识图谱建模所作的数据映射转换见第3.1节。
2.2.2. 非结构化数据的处理
证券类新闻是了解该时刻或当日重要事件的主要通道,在证券领域又称为另类宏观数据,它包含了企业、上市公司实体或相关概念的当日事件等信息,其中含有大量的金融证券领域的实体词语。在本节中我们主要对该类数据进行进一步的分类标签化预处理,为后续的FinBERT-CRF命名实体识别模型框架提供数据基础。具体映射前后区别如表2所示。
Table 2. Example of data format after mapping operation
表2. 映射后数据样式示例1
在本章模型的输入中,为了进一步强调输出类别标签之间的依赖性,我们将输入文本样本做出了以下几点约束:
· 实体标记的起始字符需为“B_”;
· 实体标记的中间字符需为“M_”;
· 实体标记的结束字记需为“E_”;
· 同一实体标记中间不能出现不同的类别标记,如“B_LOC, M_ORG”的标记连续出现是不被允许的;
· 其余情况均被标记为“O_”。
具体新闻文本数据的预处理(news preprocessing)的伪代码算法如下所示(算法1)。
Algorithm 1. News text preprocessing algorithm
算法1. 新闻文本预处理算法
3. 基于FinBERT-CRF框架的证券领域新闻实体识别模型
为了进一步扩充证券领域知识图谱的情感分类属性,本章针对非结构化证券领域新闻文本,构建了一种基于FinBERT-CRF的证券领域新闻文本命名实体识别模型,用于识别新闻中的专有企业实体,以结合市场当时情绪扩充知识图谱中实体的情感表现。由于所爬取的证券领域新闻文本未自身带有企业实体标注,故我们采用了DataFountain金融领域实体新闻任务数据集进一步训练本节所提出的模型,并通过已训练模型对证券领域新闻文本进行实体识别,而DataFountain数据集中带有企业实体标注的规模较小,故在模型BERT部分的初始参数设置时,通过复用了FinBert [4] 中在金融领域情感分析任务中已训练参数,有效减少数据规模小所带来训练不佳等影响,同时在参数优化阶段我们通过CRF损失函数对模型进行训练。本节将首先就本章模型FinBERT-CRF模型框架展开介绍,之后通过对比实验训练该命名实体识别模型,最后对其算法进行进一步分析并讨论结果证明模型算法的有效性。
3.1. 模型结构
在基于FinBERT-CRF的金融领域中文命名实体识别模型,我们首先设计BERT框架作为编码器并生成词向量,之后通过Linear层进行非线性映射生成概率矩阵,最后通过CRF (Conditional Random Field)损失函数 [5] 对输入标签进行学习反馈得到最终结果。模型框架如图3所示。

Figure 3. Model structure of FinBERT-CRF
图3. FinBERT-CRF模型框架
从图3可以看出,模型共分为三个模块,分别为输入层、编码层以及输出层。在输入层中我们将输入的中文文本样本,转换为模型可识别的文本格式输入文本序列
。在编码层中我们主要将输入文本序列转换为已处理的特征向量格式。输入层中的文本
以单个汉字与相应标签如“司O-ORG”的格式作为一个单位的 个单位输入序列。在本节的编码层中我们主要使用了BERT模型思想,且在BERT模块的参数设置中,我们复用了FinBERT训练所得参数。FinBERT [4] 模型为一种基于BERT的金融领域文本模型,在金融情绪分类的任务中的Financial Phrasebank数据集达到了86%的准确率。BERT在文本特征向量生成中相较于仅考虑单向训练的语言模型,其同时训练了每个单词上下文。其中编码层主要包含了两个部分,分别为嵌入层与Transformers [6] 所组成的编码器层。
在嵌入层中除了输入层文本之外,存在段嵌入层(Segment embedding)、符号嵌入层(Token embedding)以及位置嵌入层(Position embedding)。段嵌入层的目的是使模型对文本中不同的句子关系进行区分,在生成过程中嵌入A、B符号表示区分多个句子在整篇文章中的奇偶性。符号嵌入层的目的是在针对每个句子的处理中,从词典中查询对应单词的词语向量,并该嵌入层在每个样本前端插入[CLS]标识,同时在每句话的最后加入[SEP]标识来表明每个句子的结束边界,这样句子的语义特征均可通过CLS训练表达。位置嵌入层的目的为识别文本中单词的前后依赖关系,我们在最后一层嵌入了位置向量层去传递模型相应单词的位置信息。在三层嵌入层之后我们将输入向量进入标准编码层,本文中我们通过使用12个Transformer层叠加聚合并同时输出生成了了一组特征向量
。
在输出层中我们主要将已生成的特征向量将其转换为对应标注的概率矩阵并经过损失函数进一步调整训练相关参数。在特征向量生成后进入Linear层,将编码器部分输出的特征向量做映射变换生成不同的logits向量,随即进入softmax层转换为概率值,最后便得到文本输出的各个标签对应的概率矩阵即为我们的输出结果。在输出层得到概率矩阵后在本节我们通过设计了CRFs算法作为损失计算函数,根据CRFs计算出的条件概率得到了最大化对数似然函数并使用梯度下降法,根据损失函数反向学习模型参数输入至我们的编码器中,优化相应调整有关参数。在训练结束后在不同的文本位置处输出结果选择其中概率最高的标签类别作为当前的预测结果并进行解码输出即为我们的标签结果。
3.2. CRF损失函数
在本文中我们通过CRF来构建模型的损失函数,CRF损失函数共由两个部分组成,真实标签所得的概率分数以及所有标签的总分数。假设我们的数据集中有以下的类别标如表3所示。
若存在一个包含六个单词的句子,可能的类别序列为存在46656(66)种可能性,假设每种路径的可能概率为
,则路径总分如式(1)所示。
(1)
若其中第m个标签路径为真实标签路径,则
应为所有概率序列中最高的概率值,定义的损失函数如式(2)所示。
(2)
其中由于
,则在计算真实概率值中,e为固定常量参数则需计算
。
主要是由两个部分所构成,分别为发射分数与转移分数,该分数即有CRF层中的状态转移矩阵得以计算。
3.3. 实验结果
在本章中我们主要介绍了本章的实验环境,同时对对比实验研究中涉及的训练数据集进行了进一步的介绍,最后展示了我们的对比实验结果,并表明本文所提出的模型框架以及实验思想在小规模证券领域命名实体识别的任务中得到了优异的表现。
3.4. 实验数据
本章中主要涉及到两个训练数据集,分别为通用细粒度命名实体识别数据集Cner、数据科学竞赛平台DataFountain金融类文本新实体识别数据集。具体说明如下:
1) 通用细粒度命名实体识别数据集CNER [7]
Cner数据集为已处理的中文通用数据集,共包含十种不同的类别,包括:人名(name)、组织(organization)、地址(address)、公司(company)、政府(government)等,每组样本以输入的原始单个文本和标记为键值对的组成序列。其中训练集包含3820个样本,验证集包含462个样本。具体如下表4所示:
2) 数据科学竞赛平台DataFountain金融类文本新实体识别数据集 [8]
该数据集原始格式以csv文件的格式提供,为金融类网络文本包括金融类新闻,每条数据包括标识号码(id)、新闻标题(title)、新闻内容(text)、未知实体列表(unknownEntities)即实体列表五种文本,且提供的比赛数据中训练集与测试集分别均含有10,000条中文新闻文本。由于该类数据集已标记了文本相关实体,故我们对该原始数据集做统一的数据分类与分析处理同3.1节框架方法作半结构化数据预处理,得到我们的样本总集并将其按照7:2:1的方式分为训练集、验证集与测试集。
3.5. 评测指标
本章实验的评价系统采用命名实体识别任务中常用的三类指标:精确率(P, Precision)、召回率(R, Recall)和F1-Measure (F1),具体公式分别如下式(3)、式(4)、式(5)所示。输出的预测标注的结果为
,人工标记的结果为
。在匹配的过程中,需要同时评价实体类别以及标记边界范围预测的效果,故本文中若该两个部分均预测准确,才作为正确预测计入评测系统中。
(3)
(4)
(5)
其中的
即表示我们人工标记的结果T。
3.6. 实验结果分析
在构建本章基于FinBERT-CRF的证券领域命名实体识别模型框架中,部分原始模型参数选择如表5所示。
Table 5. Part of the model parameters
表5. 部分模型参数
在本章所提出的FinBERT-CRF证券领域实体识别模型框架中的BERT模型进行训练主要分为两个步骤,分别为预训练和微调(Fin-tune)。
在预训练的过程中,本文模型主要通过三种不同的方式:第一种,直接调取Google提出的BERT模型参数迁用至本章BERT模型中;第二种,我们通过在通用实体识别数据集即Cner数据集输入至BERT模型进行预训练,第三种,我们使用了FinBERT模型已训练参数加入至BERT模型之中即本文所提出模型。
在微调的过程中,使用上述四种情况得到的参数初始化BERT模型,后通过下游任务的目标基于DataFountain金融类文本新实体识别数据集对其进行小步幅的调整,并通过CRFs损失函数调优最终得到各类标签的概率矩阵。得到对比实验结果如下图4所示。
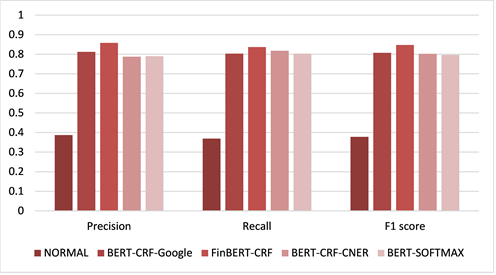
Figure 4. Comparison of experiments results
图4. 实验结果对比图
其中如下表6所示,NORMAL表示我们对BERT [9] 的语调参数作随机初始化,BERT-CRF-Google表示我们直接应用Google提出的BERT模型参数预训练基础下使用小规模数据集Kaggle比赛中的文本在BERT-CRF模型架构上进行训练得到的结果;FinBERT-CRF表示我们应用FinBERT模型参数并再DataFountain数据集训练学习得到的结果;BERT-CRF-CNER为上述所提在通用数据集预训练CNER基础得到的结果;BERT-SOFTMAX为不通过CRF作为损失函数的BERT-Linear模型。
Table 6. Experimental results on different methods
表6. 实验对比结果
从上述实验可以看出,FinBERT-CRF相较BERT-SOFTMAX模型可以提升6.81%的准确率,故本节中提出的以CRF为损失函数可以有效的提升模型的训练效果。在对比NORMAL与本文所提基于金融领域新闻预训练的FinBERT-CRF的过程中,我们可以发现同领域不同应用任务模型的参数可以有效解决特定领域数据不足的问题。在对比BERT-CRF-Google、BERT-CRF-CNER与FinBERT-CRF的过程中可以发现同领域迁移学习模型较跨领域迁移学习表现更为优异。
从上述实验中我们可以发现,本章所提出的基于FinBERT-CRF框架的证券领域命名实体识别模型可以在迁移学习的思想下可以有效并优异的完成小规模样本下证券领域命名实体识别任务。
4. 基于FinBERT-CRF命名实体识别的证券领域知识图谱的构建
在前两节的数据准备以及FinBERT-CRF命名实体识别模型的基础上,本节主要介绍本章基于金融证券领域的知识图谱的设计以及基于FinBERT-CRF对证券领域知识图谱情感分类的扩充算法。
4.1. 初始证券领域知识图谱的设计
本小节主要通过已爬取的企业于股票市场中的基本面数据构建初始的证券领域知识图谱。三元组作为知识图谱的基本结构,在进行本文领域知识图谱的设计的过程中是不可忽视的一部份。根据本文已爬取数据的实际情况,主要设计了两种相应的存储结构。第一种为“实体–属性–具体属性”,该类三元组具体表现为“一对一”的形式即每一个实体的特定属性仅有唯一对应的值存在。例如实体姓名(name)、是否退市(list_state)、总资产(reg_capital)、省份(province)、城市(city)、主营业务(main_business)为唯一属性映射形式。第二种为“实体–关系–实体”,该类三元组表现为“一对多”的形式即通过关系映射,某一实体的某一特定关系存在多个实体。如下表所示,表7列举了某一企业实体的实体属性“一对一”映射关系。
本文在构建证券领域知识图谱中创建了code (股票代码)、name (企业姓名)、list_state (上市情况)、经营规模(reg_capital)、管理者(chairman)、province (省份)、city (城市)七个节点属性标签,位于(located)、属于(belong)、主营(main_business主营业务)三个关系属性标签。如表7中list_state中的L表示该企业实体正常上市中,D表示该企业实体已经退市。三个实体属性和省份、城市、行业、概念、主营业务五个实体之间的关系。
Table 7. Examples of “one-to-one” mapping
表7. 属性“一对一”映射关系举例
4.2. 证券领域知识图谱的构建
本节为进一步实现“实体–属性–属性值”和“实体–关系–实体”的结构特性,需对抓取到的数据进行预处理,为构建初始证券领域知识图谱提供数据基础。首先将industry表中的一对多的映射信息转换为“一对一”映射的数据表中。例如industry表之间的转换,我们需要将表8通过Pandas与math包等处理为表9中“一对一”映射方式。
Table 8. Example of “one-to-many” mapping table for industry
表8. Industry表“一对多”映射表举例
Table 9. Example of “one-to-one” mapping table for industry
表9. Industry表转换为“一对一”举例
通过该种方式,本节共创建了股票(code)、城市(city)、省份(province)、主营业务(main_business)、概念(notion)五种节点,股票姓名–城市(name-city)、城市–省份(city-province)、股票姓名–主营业务(name-main_business)、股票姓名–所属概念(name-notion)、股票姓名–省份(name-province)五种实体关系映射表。最后将预处理后的表格数据导入neo4j [10] 图数据库中。Neo4j数据库提供了Cypher语句进行逐条导入,该种方式可以实时插入数据且修改数据较为灵活,同时也可以通过LOAD CSV语句进行基础的csv文件多批次插入。本文中我们在Centos7系统下将处理过的节点、关系文件通过neo4j-import的方法进行批次插入,得到的部分可视化呈现如图5所示。
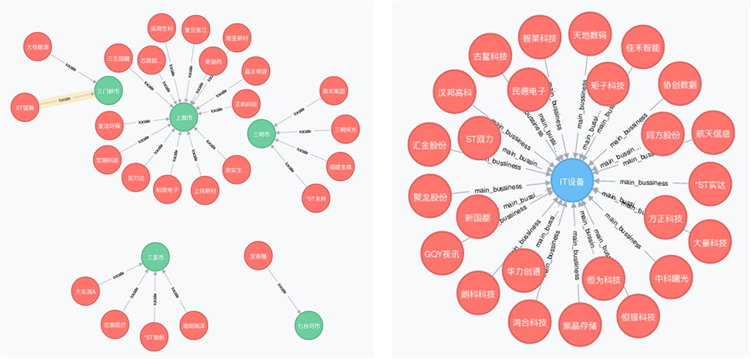
Figure 5. Visulization of knowledge graph in the securities field
图5. 证券领域知识图谱可视化部分呈现
在本节所构建的初始证券领域知识图谱中,共包含了4673个实体节点、18,986个属性描述以及13,340条边关系。
5. 基于FinBERT-CRF的证券领域知识图谱的构建
为了进一步实现对于企业实体节点的情感分类任务,本节主要介绍了在已构建的初始证券领域知识图谱基础之上,基于FinBERT-CRF构建面向情感分类的证券领域知识图谱的构建原理以及算法实现。
在构建了初始证券领域的知识图谱之后,本节将主要就面向情感分类的证券领域知识图谱的构建的流程展开介绍。对于非结构化新闻文本数据,我们基于FinBERT-CRF命名实体识别模型,将爬取的相关新闻文本作为训练样本送入体模型中,即可训练得到对应文本相关企业实体,之后通过如图3所示流程为模型所输出的实体打上情感标签,生成面向情感分类的新闻实体数据集,最终与知识图谱融合生成最终的面向情感分类的证券领域知识图谱,具体流程如图3所示。
如图6所示,我们首先将爬取的新闻文本数据送入基于已训练的FinBERT-CRF命名实体识别模型,分别将其中相关企业实体进行识别并标注,得到新闻样本中的相关实体集
。
其次我们基于新闻发布时间点以及相关企业实体,通过实际的股票市场中新闻发生第二日后具体涨跌表现,将其标注为相应新闻实体的情感表现。在本节中我们考虑到新闻事件的时效性,选择了一日后股票的表现作为其情感表现的评估标准。
例如在2020年4月16日晚间公布的一条新闻中“省广集团:暂未开展RCS相关业务”,则其中得到的企业实体为“省广集团”,在证券市场中“省广集团”的于2020年4月17日的涨跌幅为−8.16%,故该条发生于4月16日的新闻我们将其打为负情绪。以此类推,在本数据集中我们假定下述三种情况为我们制作标签的规则:
· 若第二日的涨跌幅大于1.5%,则为正类情感标签;
· 若第二日的涨跌幅小于−1.5%,则为负类情感标签;
· 若第二日的涨跌幅位于−1.5%至1.5%之间,则为中性情感标签。

Figure 6. Construction process of Knowledge graph FinKG-EMO in Securities field
图6. 面向情感分类的证券领域知识图谱FinKG-EMO构建过程图
之后按照该类情感分类的标签方法对其进行迭代即可得到对应新闻文本中实体的当日市场相关情绪值,同时我们将证券领域知识图谱中的相关概念以及板块如“新能源”“白酒”等节点在第二日的市场表现仍遵从以上规则进行情感分类标签处理。
最后结合已构建的知识图谱三元组生成在时间区间内每一日的证券领域知识图谱相即生成一系列的相关样本结构图数据集,同时考虑到新闻样本的数据集规模较小,我们通过将一组十张连续日的知识图谱将节点情绪进行了如式所示的拼接。
(6)
如式(6)所示,其中
代表第i日企业节点 在市场中的情感分类,
代表第i日企业节点E对第N日节点 的情绪权重,我们在本节中我们设置
且
中i越小相应的权重越小,最终生成了基于FinBERT-CRF模型的面向情感分类的证券领域知识图谱数据集FinKG-EMO,具体实现算法如算法2,且相应生成的具体实体节点情感三元组样本示例如表10所示。
Algorithm 2. FinBERT-CRF-based knowledge graph construction algorithm
算法2. 基于FinBERT-CRF的证券领域知识图谱构建算法
Table 10. An example of storage representation of entity nodes of knowledge graph in the securities field
表10. 面向情感分类的证券领域知识图谱实体节点存储表示举例
除此之外,为了进一步充实面向情感分类的证券领域知识图谱中节点的特征信息,我们将已搭建的知识图谱FinKG-EMO中的企业节点基于上述FinBERT模型编码嵌入层部分生成了一系列的情感特征向量附于知识图谱并进行初步拼接,为之后的模型训练提供了有效的数据信息。
6. 小结
本文针对当前证券领域缺乏准确普遍面向关系的可视化建模方法在一定假设下提供了可能解决方案。针对获取数据方面,本章提出了一套完整的金融财经新闻文本数据的爬虫框架,可基于该框架及时准确地从互联网中获取大量的上市企业新闻文本数据以及非结构化企业基本面数据,为进一步的命名实体与知识图谱的搭建提供数据支持。对于非结构化新闻文本,本节在特定领域样本规模小的假设前提下提出了基于FinBERT-CRF框架的证券领域新闻命名实体识别的模型,通过复用同领域情感分析FinBERT模型中的参数,实现从小规模证券领域文本中提取新闻相关实体并通过对比实验证明该模型框架的有效性。最后,基于上述爬虫所得半结构化数据所构建的初始证券领域知识图谱以及基于FinBERT-CRF命名实体模型所得相关实体的市场情感表现搭建了面向情感分类的证券领域知识图谱,为本文下述基于图的情感分类模型研究提供了支持。
综上所述,本文主要解决了如何能够及时准确地从互联网中获得所需的证券领域新闻文本的问题、如何能在小规模新闻文本数据集上准确高效地识别证券新闻涉及的相关企业实体的问题以及如何结合实际应用场景根据已有的半结构化数据和相关实体的市场表现搭建有效的领域知识图谱的问题,分别提出了一套基于上市企业的定向爬虫框架、基于FinBERT-CRF的证券领域命名实体识别模型以及基于命名实体识别模型的一套构建面向情感的证券领域知识图谱框架,为后续基于图结构的情感分类研究展开提供了基础,并为类似特定领域的情感或文本类研究提供了实践参考。