1. 引言
乒乓球被誉为我国的国球,其易于开展,参与性强,普及度高,得到了国内各年龄段人员的普遍喜爱。随着科技的高速发展,计算机技术已成为提升运动竞技水平的重要工具,带有智能功能的比赛记录和分析装置已在训练和比赛中得到了初步应用。王恺凡等人基于卷积神经网络开发了一款乒乓球训练平台,将人脸识别、人体骨骼识别和心率检测功能进行了整合,提升了训练效果 [1]。丁朔等人融合语音交互与自然语言处理技术,设计了一款乒乓球智能训练系统,辅助教练员制定训练计划,并对错误的动作给予视频纠正指导 [2]。杨波等人将VR (Virtual Reality,虚拟现实)技术引入高等院校的乒乓球课堂教学,将其整合融入既有课程,提升了教学效果 [3]。任云青等人采用ROS (Robot Operating System,机器人操作系统)、OpenCV (Open Source Computer Vision Library,开源计算机视觉库)等软件,设计并实现了一款智能乒乓球自动捡球机器人,实现了乒乓球智能识别、分拣与运输等功能 [4]。
在以乒乓球运动为代表的对抗性球类项目的球员技术动作识别与分析方面,基于机器视觉的人体动作识别技术近来得到了普遍关注。孙于成等使用时空图卷积在其自建的乒乓球骨骼数据集上实现了击球动作的研究 [5]。Martin等提出的双时空卷积神经网络(TSTCNN)在MediaEval 2020“运动视频分类:乒乓球的动作分类”比赛中取得了优异的成绩 [6]。杨静等基于支持向量机(SVM)和光流分析,提出了一种识别体育视频中羽毛球运动员运动的方法 [7]。Nur Azmina Rahmad等在其自建的羽毛球比赛数据集中对AlexNet,GoogleNet,VggNet-16和VggNet-19四种卷积神经网络的模型分类性能进行了比较 [8]。Piergiovanni等构建了MLB-YouTube棒球比赛运动数据集,并用3D卷积网络的方法对数据集细粒度活动进行识别 [9]。
然而上述动作识别算法研究均基于公开或非公开球员间比赛的视频数据集,在疫情常态化的新形势下,发球机已成为训练的重要组成部分,发球机发球速度、力量和旋转方式和球员回球有较大差异,而关于球员在乒乓球发球机上的回球动作识别相关研究目前比较罕见。为提升乒乓球发球机的训练质量,课题组邀请专业乒乓球队员进行标注技术动作采集,通过60 fps深度摄像机采集专业运动员接发球动作,建立了发球机接发球标准动作数据集,随后通过密集姿态(Dense Pose)技术去除环境、衣服、肤色等影响因素,最后对C3D网络 [10] 改进并训练数据,完成对乒乓球击球动作的识别,整个项目的实验过程如图1所示。
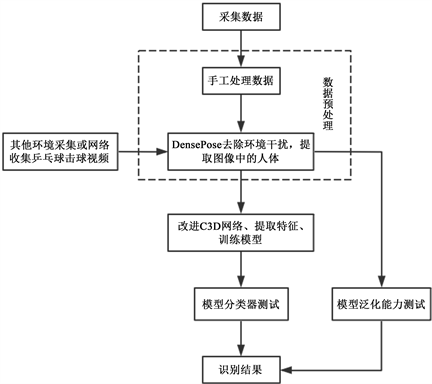
Figure 1. Flow chart of the recognition algorithm of table tennis striking action
图1. 乒乓球击球动作识别算法流程图
2. 视频数据集构建
2.1. 数据采集环境搭建
选取市场上主流的乒乓球发球机(双鱼1040)进行接发球训练。该设备在出球口设置了胶皮擦球装置,能够通过胶皮摩擦发出上旋、下旋转和侧旋球;同能够调整发球速度、角度、频率,可以满足接发球技术动作训练要求。
视频采集设备为ZED双目深度像机,参数调整为:分辨率720像素、帧率60 fps。为了保证采集到的运动视频不会出现丢帧和跳帧等问题,在数据采集时对连接摄像机的电脑硬件设备进行了调整。整体采集设备硬件如图2所示。

Figure 2. Equipment for data acquisition
图2. 数据采集设备
2.2. 数据集搭建
目前乒乓球接发球主流的技术动作可分为正反手拉球、正反手攻球、正反手搓球、正反手削球等几类,目前这些技术动作尚无准确的动作集标准,然而统计分析表明,多数高水平运动员在乒乓球发球机上的接发球动作有较大相似性,因此选择邀请高水乒乓球球员动员录制接发球视频,将他们的击球动作作为标准数据集。
香港中文大学研究者于2020年构建了一个大规模体操运动人体动作数据集:FineGym [11],数据集通过层级化标注对动作的细粒度进行了区分,最细划分到一个具体的体操动作,例如平衡木体操下马动作中的团身前空翻动作。文章根据此数据所划分的细粒度动作,构建了乒乓球击球动作数据集。
乒乓球击球动握拍方式大致可以分为横拍和直拍两种,通过分析视频中的连续帧发现,直拍中有些击球动作轨迹相似,例如正手攻球和正手拉球在即将击球的瞬间的连续2~3帧动作相似,反手攻球和反手拉球在准备接球和击球的瞬间都有1~3帧的动作相似,这也是击球动作中区分的难点,击球动作相似和动作差异如图3所示。因此,在采集数据和做动作区分时,选择了对正手攻球、正手拉球、反手攻球、反手拉球的动作进行采集。采集的数据集中,击球动作之外的动作将其称为其他动作,对4类击球动作和1类其他动作进行识别,以便于模型更好区分击球动作。


Figure 3. The similar action in the stroke action: (a1) and (b1) are the frames of the similar action in the forehand stroke and forehand pull; (a2) and (b2) are frames of the difference between the forehand stroke and the forehand pull. (c1) and (d1) are frames of similar movements in the backhand stroke and backhand pull
图3. 击球动作中的相似动作:(a1)和(b1)为正手击球和正手拉球过程中相似动作的某一帧;(a2)和(b2)为正手击球和正手拉球过程中动作区别的某一帧;(c1)和(d1)为反手击球和反手拉球过程中的相似动作的某一帧
3. 数据集处理
3.1. 数据预处理
对所采集的乒乓球击球视频进行处理。由于在乒乓球运动中,击球是一个快速动作,直接给视频数据设置标签不仅比较困难,而且标签所在的时间段也存在其他动作的干扰。
通过将乒乓球击球视频的每一帧提出来,经过研究对比发现,每种击球动基本在16~24帧内完成击球,因此将完全包含一个击球动作的16~24帧的连续帧进行提取,形成一个击球动作的时空特征数据;非击球动作一般在48个连续帧左右之内,将提取非击球动作的48个连续帧,形成一个非击球动作的时空特征数据。经过手工提取数据后,数据集包括了824个动作,将近20,000帧图片,5类动作每类包含150左右个动作连续帧的时空特征数据。表1完整的显示了动作类别和动作数量。为了便于训练、Dense Pose处理数据和设置动作标签,设置了五个文件夹,其名字作为应五个动作类的标签,既Facade Attack (正手攻球)、Facade Pull (正手拉球)、Back Attack (反手攻球)、Facade Attack (反手拉球)和Other Action (非击球动作)五类运动标签。每个标签文件夹中的每一个子文件夹都代表一个动作,每个动作由连续帧组成。

Table 1. Data set of action category and number of actions
表1. 数据集动作类别和动作数量
3.2. Dense Pose处理数据集
2018年Facebook [12] 和Inria France [13] 的研究者分别在ECCV会议和CVPR会议发表了篇有关于Dense Pose的文章,介绍了他们提出的Dense Pose系统 [14]。在Dense Pose系统中的密集姿态估计(Dense Pose Estimation)功能 [11] 可以将2D人体映射到3D的人体表面,在图4中展示了2D到3D的转换。这种2D映射到3D转换的过程并不会改变图像的大小,所映射的3D人体表面在图像中分成了24份,每一份的中的颜色值存在偏差,并且此功能可去除图像中的背景干扰,如图4所示。
 (a) 处理前
(a) 处理前  (b)处理后
(b)处理后
Figure 4. Pose estimation of image processing using Dense Pose system
图4. Dense Pose系统密集姿态估计处理图像
通过Dense Pose系统中的密集姿态估计功能,对手工处理后的数据集中动作帧图像进行处理,把2D人体映射到3D模型,经过此处理图片中的人体只有形态和动作,模型的泛化效果不会被人体的肤色和着装所影响。经过Dense Pose处理过的图像,动作识别中环境干扰因素都会被去除,模型泛化效果就不会受环境等因素所影响。图5介绍了未处理的数据对比经过处理后的击球部分连续动作帧。
 (a) 连续帧处理前
(a) 连续帧处理前 (b) 连续帧处理后
(b) 连续帧处理后
Figure 5. Comparison of unprocessed data with continuous action frame of striking of table tennis processed by Dense Pose
图5. 未处理的数据对比Dense Pose处理后的击球部分连续动作帧
4. 网络模型搭建
4.1. 3D卷积网络
3D卷积也是从2D卷积的基础上发展而来的,基于2D卷积核的卷积网络 [15] 可用于学习单通道或者三通道的图像的空间特征,图6中的图6(a)是2D卷积应用在三通道的图像卷积的结果,输入为w × h × c三个维度,表示图片的宽、高和通道数。2D卷积应用在学习单通道图像的特征时,除了输入维度少一个通道维度外,整个卷积过程与图6(a)三通道卷积过程相同。
相比于2D卷积核来说3D卷积核 [10] 是多了一个维度去学习数据中的时间特征,如图6(b)输入为t × w × h × c四个维度,其中t代表连续帧数目,t这一维度的特征就是数据时间维度上的特征。对于连续的单通道图像来说,输入的维度是t × w × h三个维度,整个卷积过程和图6(b)三通道图像卷积过程相同。
 (a) 2D卷积过程
(a) 2D卷积过程 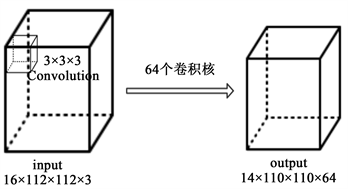 (b) 3D卷积过程
(b) 3D卷积过程
Figure 6. Difference between 2D convolution process and 3D convolution process
图6. 2D卷积过程与3D卷积过程的区别
4.2. C3D网络结构改进
C3D网络是Du Tan (杜兰特)等人 [10] 于2015年提出的一个用于学习和识别视频中信息的通用网络,其通过3D卷积网络去学习视频中的时空特征,学习所得到的模型可用于场景分类、动作识别等领域。C3D网络的训练所使用的数据集为UCF101数据集 [16],数据集由101个人类动作类别的13,320个视频组成,视频图像未经过处理,由于数据集种类多,视频图像中的特征复杂,因此C3D网络整体网络层次设计比较深,包含为8个卷积层、5个池化层、2个全连接层,整个网络的参数为6000万左右。在项目组自建的数据集中,数据经过处理后没有了环境、衣服、肤色等特征的影响,图像中只有人体形态,图像中的特征相对简单,为了防止出现过拟合现象,因此将C3D网络的整体结构缩减为5个卷积层、5个池化层、2个全连接层,并对特征图个数和神经元个数进行了缩减,最终网络参数降为500万左右。整个网络结构如图7。

Figure 7. Structure diagram of improved C3D network
图7. 改进后的C3D网络结构图
输入层(Input):输入的数据为16个连续的视频帧,每一帧的宽高为112 × 112,通道数为3,即输入维度为16 × 112 × 112 × 3;
卷积层(Convolution):5个卷积核的每一个卷积核维度为3 × 3 × 3,步长为1,并在卷积过程让其自动填充padding,保证卷积过程中输入和输出尺寸相同,在每个卷积过程结束后,使用ReLU激活函数。卷积计算公式如式(1),其中W为帧的宽度,H为帧的高度,T为连续帧的时间维度,p为边界填充值,s为步长,为卷积核维度。
(1)
池化层(Polling):池化层使用的事最大值池化,为了在初始卷积池化阶段保留时间上的特征,保留了原网络的池化结构,在第一次池化时维度为1 × 2 × 2,步长为1 × 2 × 2,其他池化层的维度都为2 × 2 × 2,步长为2 [6];
全连接层(FC):全连接层的神经元个数根据最后一次池化后特征图的大小设置为512个。经过前面卷积提取特征后,全连接层最终会将这些特征映射到标签空间,起到一个分类器的作用。
输出层(output):根据数据集中5个类别的动作,网络最后的输出是判断的这五个类别的概率值。
5. 正文实验结果与分析
基于自建数据集训练乒乓球击球动作识别模型实验硬件环境为:处理器Intel(R) Core(TM) i7-7800X CPU @ 3.50 GHz 3.50 GHz和NVIDIA GeForce RTX 2080Ti GPU;模型泛化性能测试实验环境:硬件环境Intel(R) Xeon(R) E-2224 CPU @ 3.40 GHz 3.41 GHz和NVIDIA GeForce GTX 1650 GPU,DensePose系统不能再Windows系统上安装,所以系统环境为Ubuntu操作系统。
5.1. 模型训练实验结果分析
用于训练模型的训练集和验证集均来自于自建数据集,训练集和测试接的划分别为数据集的80%和20%。通过30次迭代训练,通过图8(a)可以看出在第18次迭代后训练集精准度稳定在99.5%,验证集精准度稳定在99.3%。通过图8(b)可以看出在第18次迭代后训练集损失函数值趋近于0,验证集损失函数值稳定在0.09以内。
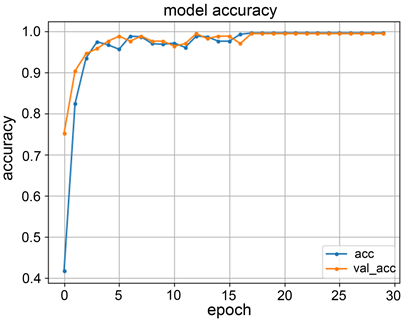 (a) 训练集和验证集训练结果准确率曲线
(a) 训练集和验证集训练结果准确率曲线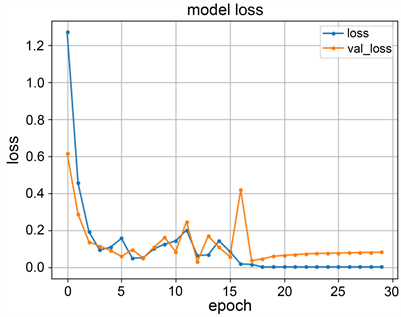 (b) 训练集和验证集训练结果损失函数值曲线
(b) 训练集和验证集训练结果损失函数值曲线
Figure 8. Accuracy and loss function value curves of the training results of the training set and the validation set
图8. 训练集和验证集训练结果的准确率和损失函数值曲线
5.2. 模型泛化效果预测
乒乓球击球动作识别模型泛化效果的好坏决定着这个模型是否具有实际应用价值,通过从网络上找到拍摄角度与课题组自建数据集中拍摄角度相似的乒乓球击球视频,整个视频经过Dense Pose系统处理后放入到模型中测试泛化效果。图9中的视频来源于视频网站与训练集中的数据不存在交集,并且图中为连续动作帧中提取出来图像。图9中,图9(a)预测结果为正手攻球,图9(b)预测结果为正手拉球,图9(c)预测为反手攻球,图9(d)预测为反手拉球,预测结果均与球员实际击球动作类型一致。通过泛化性能测试可以看出本文所提出的方法训练出来的动作识别模型泛化能力较强,有一定的实际应用价值。
 (a) 预测为正手攻球
(a) 预测为正手攻球  (b) 预测为正手拉球
(b) 预测为正手拉球  (c) 预测为反手攻球
(c) 预测为反手攻球  (d) 预测为反手拉球
(d) 预测为反手拉球
Figure 9. Generalization performance test of recognition model for table tennis striking action
图9. 乒乓球击球动作识别模型泛化性能测试
6. 结语
基于专业运动员在乒乓球发球机上的接发球视频,自建了包含五分类的乒乓球击球动作识别视频数据集,通过动作划分手工提取了连续击球动作视频帧,采用Dense Pose系统中的密集姿态估计功能对手工提取的视频帧进行了处理,最终通过改进C3D网络训练出了乒乓球击球动作识别模型。实验表明:模型训练时在第17次迭代之后训练精准度稳定在99.5%,验证集精准度稳定在99.3%,并且模型通过了泛化性能测试,证明文章提出的方法可以去除环境、衣服等因素的干扰,训练的乒乓球击球动作识别模型具有实际应用的价值。
基金项目
大连市科技创新基金项目“面向足球青训的技战术分析算法及配套可穿戴设备研发”(项目编号:2020JJ26GX038);大连民族大学学科团队项目“基于机器学习的乒乓球接发球动作识别与水平评估算法研究”。