1. 引言
短期负荷预测是编排发电计划、调度计划、确保系统安全稳定运行的基础 [1],但易受气象条件、节假日等因素的影响,对其精确的预测显得尤为重要。
近年来,短期负荷已由传统的时间序列法 [2]、灰色预测 [3]、趋势外推法 [4] 等发展到今天的随机森林法 [5]、模糊理论 [6]、人工神经网络 [7]、支持向量机 [8] 等方法。例如文献 [9] 采用自适应柯西变异粒子群对LSTM模型参数进行寻优,提高短期电力负荷预测的精度和稳定性;文献 [10] 提出多阶段优化的变分模态分解和粒子群算法优化支持向量回归的短期电力负荷预测模型,精度得到了提高;文献 [11] 利用花朵授粉全局搜索能力强的特点对BP神经网络的权值阈值进行优化,提高了短期负荷预测的精度。
针对BP神经网络收敛速度较慢且易陷入局部极值缺点,采用混沌反向策略初始化种群;引入黄金正弦改进发现者的位置,并在跟随者位置更新中采用t分布策略的方法改进麻雀算法,利用改进后的麻雀算法优化BP神经网络,应用于短期电力负荷预测中,仿真结果表明,改进后的方法预测精度提高。
2. 麻雀算法
SSA算法 [12] 与其他算法相比,具有收敛速度快,稳定性好等优点,但易陷入局部最优解。麻雀算法由发现者、跟随者和预警者组成的。设n只麻雀组成的群体及对应适应度函数分别可表示为:
和
。发现者位置更新如下:
(1)
式中,i为迭代次数;
。
为最大迭代次数;
为第i只麻雀在第j维中的位置;
为随机数;
和
分别为预警值和安全值;Q是服从正态分布的随机数;L为
的全1矩阵。
跟随者的位置更新为:
(2)
式中,
分别为当前全局最优和最差的位置。A为
的全1或−1矩阵,且
。
预警麻雀占种群的10%~20%,位置更新为:
(3)
其中,
为当前全局最优位置。
为服从(0,1)正态分布的随机数。
的随机数,
、
和
分别为当前麻雀个体、全局最佳和最差的适应度值。
为最小的常数。
3. 改进麻雀算法
3.1. 混沌策略反向学习初始化种群
随机生成初始种群虽能保证初始位置均匀分布,但不能保证解的质量,影响算法的收敛速度及精度。本文采用反向学习初始化的方法引入Logistic映射策略 [13]。首先利用Logistic映射生成N个向量,再使用反向学习生成相对应的N个反向初始解,然后从初始解和反向解中选择前N个适应度较好的个体作为初始化种群。
3.2. 黄金正弦因子
2017年,Tanyildizi等人提出黄金正弦算法(Golden-SA) [14],具有寻优能力强、设置参数少、原理简单等特点。利用上述方式生成的N个个体,在发现者的位置更新上采用黄金正弦因子,改进后的更新方式如下:
(4)
式中,
为随机数,黄金分割系数
缩小搜索空间,平衡搜索和开发,使个体趋向最优值,
,黄金分割数
。
3.3. 自适应t分布
在SSA跟随者位置中引入自适应t分布 [15] 变异策略,可以增加种群的多样性,避免陷入局部最优。更新后的位置更新方式如下:
(5)
式中,
为当前发现者的最佳位置。
3.4. 改进算法性能测试
3.4.1. 测试函数及参数设置
为验证改进麻雀算法的性能,与粒子群算法(PSO) [16]、灰狼算法(GWO) [17] 进行比较,参数设置如表1所示。选取6个标准测试函数进行测试,详见表2。本文测试实验环境为:Inter(R) Core(TM) i7-4700HQ CPU @ 2.40GHz,8GB内存,Window7系统和matlab R2019b。种群规模为30,最大迭代次数为1000,维数为30。
3.4.2. 测试结果
针对同一函数,每种算法独立运行20次,并统计4种算法在6个基准函数上的平均值、标准差,结果如表3所示;寻优曲线趋势如图1所示。
由表3可知,对
,GSASSA的寻优结果优于其他3种优化算法,GSASSA能寻到最优值0,而PSO、GWO、SSA中,GWO在
、
上的均值和标准差优于其他2种智能算法,SSA在
上的寻优效果强。对于函数
,SSA和GSASSA都能寻到最优解0,GWO的寻优效果相对于PSO较优。
由图1(a)~(f)可知,GSASSA算法的寻优速度及精度都优于其他几种算法。

Table 3. Comparison with the optimization results of standard optimization function
表3. 与标准优化函数寻优结果对比
图1. 不同算法的寻优测试结果
4. GSASSA-BP模型
4.1. BP神经网络
BP神经网络是采用梯度下降法,调整相应的权值和阈值,使网络的实际输出值和期望输出值的误差均方差最小。BP神经网络一般由输入层、隐含层、输出层组成 [18]。
、
和
分别为输入层、隐含层和输出层,各层之间通过全连接进行连接。
4.2. GSASSA-BP模型
GSASSA-BP采用改进后的麻雀算法对神经网络的初始权值和阈值进行优化,使得优化后的BP神经网络收敛速度更快,全局搜索能力更强。GSASSA-BP流程图 [19] 如图2所示。
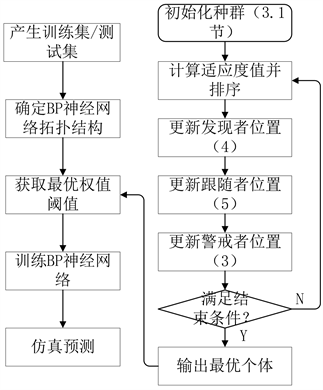
Figure 2. GSASSA-BP network model process
图2. GSASSA-BP网络模型流程
5. 算例分析
5.1. 数据选取及预处理
本文实验数据选取2016年电工数学建模竞赛负荷预测数据集,包括2012.01到2015.01的最高温度、最低温度、平均温度、相对湿度(平均)、降雨量及日需求量负荷(kWh)数据。其中,前1099天的日需求量负荷及气象条件作为训练数据,后7天的数据作为测试数据。
5.1.1. 数据预处理
在数据收集时,由于各种原因会出现数据缺失的现象,对其处理方法如下:
(6)
其中,
分别为第d天缺失点的数据,第d − 1天缺失的数据和第d + 1天缺失的数据。
5.1.2.数据归一化处理
电力负荷数据中存在差异较大,为增加预测的准确性,需要对数据做归一化处理,使各种影响因素在同一数值范围内。
(7)
其中,x为即将归一化处理的数据,
分别为处理后的数据、处理数据中的最大和最小值。
针对降雨量进行分段处理再进行量化取值,具体如下表4。
5.1.3. 相关性分析
使用Pearson相关系数法对电力负荷数据和各气象条件进行相关性分析,Pearson相关系数是用来描述两个变量X和Y之间的线性关系,计算公式如下:
(8)
式中,X为电力负荷数据,Y为各气象条件,N为数据总量个数,
,结果越接近−1或1表示两个变量之间的线性关系越强。经计算得,日需求负荷分别与最高温度、最低温度、平均温度、相对湿度、降雨量的相关系数为0.5947、0.6380、0.6391、0.1171、−0.1143,存在相关性,故把这些变量作为输入,以提高电力负荷预测精度。
5.2. 实例预测及结果分析
本文采用数据对BP、PSO-BP、SSA-BP及GSASSA-BP神经网络的预测模型进行验证,得到预测结果如下图3所示。

Figure 3. Simulation and prediction results of each prediction model
图3. 各预测模型仿真预测结果图
由图可知,GSASSA-BP的预测结果相较于SSA-BP、PSO-BP、BP更接近于实际负荷曲线。
为准确评估四种模型的预测精度,采用平均绝对百分误差(MAPE)进行估计,公式如下:
(9)
各神经网络预测对比结果见下表5:
Table 5. Comparison of prediction error results
表5. 预测误差结果比较
由表5可得,GSASSA-BP的MAPE比BP低4.9%,比SSA-BP低2.97%,说明优化后的麻雀算法预测效果能力更强。
6. 结束语
麻雀算法是一种新的智能算法。针对麻雀算法的局部搜索能力差的缺点,使用Logistic反向学习初始化种群,提高种群初始解的质量;在发现者位置更新中引入黄金正弦因子协调搜索和开发的能力;并在跟随者位置更新中加入t分布策略,提高全局搜索能力。选用BP神经网络对短期电力负荷进行预测,针对BP神经网络收敛速度慢、收敛精度不高的问题,结合改进的麻雀算法提出GSASSA-BP模型,使用该进麻雀算法对BP神经网络的权值和阈值进行寻优,实验结果表明,GSASSA-BP模型提高了BP神经网络的收敛精度,预测效果更好。
基金项目
天津市科技特派员项目(19JCTPJC41500)。
NOTES
*通讯作者。