1. 引言
中文地址匹配是指分析和判断两个或多个来自不同数据源中的中文地址,是否指向现实世界中的同一个中文地址。中文地址因其存在复杂性、非规范性、非结构化等问题,给企业内业务系统之间的融合提供了很大阻碍。目前,针对非规范的中文地址匹配研究主要集中在中文地址的文本特征,例如文献 [1] 提出了一种基于元数据关联特征的交互式数据预处理方法。文献 [2] 提出了一种新的文本相似度量方法,应用自然语言处理技术对文本进行预处理。文献 [3] 提出了一种基于条件随机场的中文地址解析方法。文献 [4] 提出了一种基于动态规划的中文地址匹配方法。文献 [5] 提出了一种基于熵的文本相似度求解方法,在对文本间字符信息的提取基础上,建立共同子文本串度量维度,然后采用熵的方法进行相似度度量。文献 [6] 针对当前在电力中文地址匹配中存在部分地址歧义的问题,结合自然语言处理的基本原理,提出了一种基于贝叶斯算法的中文地址精确匹配方法。
综上,如图1所示现有的中文地址匹配研究方法集中于中文地址文本特征的研究,而忽略了中文地址所包含的建筑特征、地理位置特征、统计特征和行业特征的数据,此类特征数据可以有效地辅助中文地址的匹配研究。本文以燃气行业居民用户数据为例进行实验,通过分析两个数据源中用户信息的多个特征数据,提出以结合标注的中文地址匹配规则链模型,实验结果表明该模型可以一定程度提高中文地址匹配的成功率。
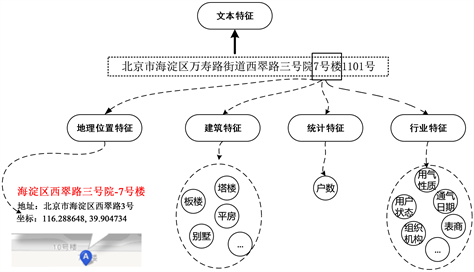
Figure 1. Feature analysis of Chinese address data
图1. 中文地址数据特征分析
2. 结合标注的中文地址匹配规则链模型设计
本文设计一种结合标注的中文地址匹配规则链模型如图2所示。
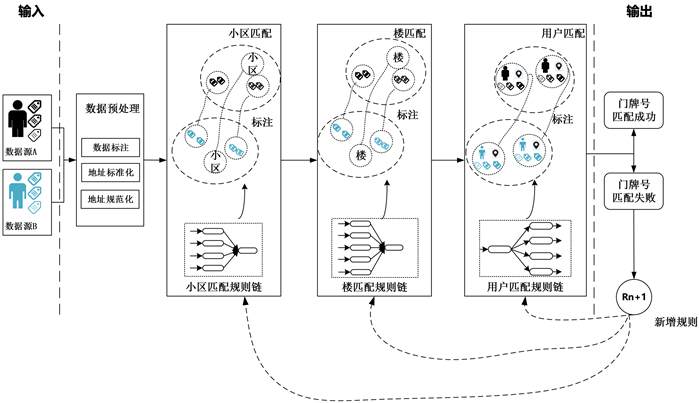
Figure 2. Chinese address matching rule chain model combined with annotation
图2. 结合标注的中文地址匹配规则链模型
数据预处理阶段,实现两个数据源中的中文地址标注、规范化和标准化的过程。根据数据预处理的结果,首先按小区匹配,小区匹配规则链实现两个数据源中小区地址要素与北京市标准地址库的匹配。其次是按楼匹配,结合楼名称、建筑特征、地理特征、统计特征等标注信息构建规则链,实现中文地址中楼信息的匹配。最后是按用户匹配,用户匹配主要依据楼匹配的结果(二元组、三元组)进行详细地址匹配。匹配失败的可以通过增加规则,补充规则链内容,继续迭代匹配过程。规则链的优点是链内的规则可以动态配置,支持代码复用,通过人工 + 计算机的方式多次迭代,新增和优化规则,逐步提升中文地址的匹配成功率。
3. 结合标注的中文地址匹配规则链模型实现
3.1. 结合地理、行业标注的小区匹配
小区匹配是判断两个不同的数据源中的小区名称是否为同一个小区。小区匹配的难点在于小区名称存在歧义、别名、简称等多种描述方式,例如“朝阳北苑路86号”、“嘉铭桐城”、“桐城国际”、“朝阳嘉铭园”、“嘉铭苑”都指向同一个小区,但是因为小区的历史变革、早期的不规范录入、系统缺少统一标准等因素导致同一个小区在不同的数据源中存在多个描述的问题。本文结合了地理、行业标注数据实现小区匹配,小区匹配流程如图3所示。
小区匹配结合地理特征、行业特征等标注,基于小区匹配规则链实现小区信息与北京市标准地址去的匹配,如果匹配失败,通过分析匹配失败原因,增加新的规则补充至小区匹配规则链,通过多次迭代,逐步提升小区匹配的成功率。小区匹配规则链包括小区名称匹配、地址匹配和行业特征匹配三个规则集合,规则集合内的规则可以动态增加,规则链的包含的规则内容如表1所示。

Figure 3. Community matching flow chart
图3. 小区匹配流程图

Table 1. Community matching rule chain
表1. 小区匹配规则链
如表1所示小区匹配规则链包括以下内容:
1) 小区名称匹配
主要采用待匹配的两个数据源中的小区名称与统计局标准社区名称,如图4中的小区信息标准库,进行匹配,匹配成功的小区信息,可以通过关联上级的街道和行政区,同时实现小区、街道和行政区地址要素的标准化。首先通过爬虫技术获取国家统计局《2020年度全国统计用区划代码和城乡划分代码》,逐级获取北京市→市辖区→行政区→街道→社区类别的统计用区划代码和名称。
标准库中小区信息都是以“社区居委会”结尾,需要去除“社区居委会”后,通过小区名称与两个数据源中的小区名称进行相似度匹配。
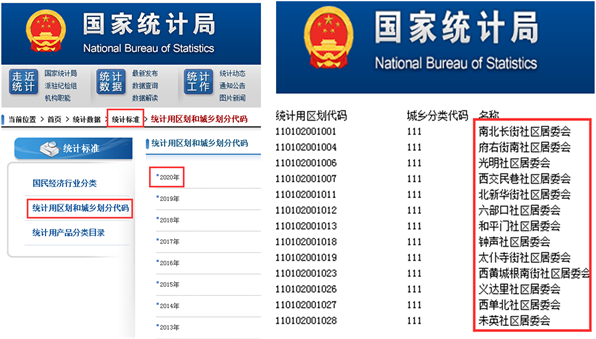
Figure 4. Community information standard library
图4. 小区信息标准库
2) 地理特征匹配
高德开放平台提供的地理/逆地理编码服务,可以将结构化的中文地址(包含行政区、街道、小区等)解析为对应的经纬度。
根据小区名称通过接口调用方式。
a) 地理编码API服务地址,如表2所示:
b) 请求实例:
https://restapi.amap.com/v3/geocode/geo?address=丰台区太平桥街道华源三里&output=XML&key=< 用户的key >
c) 请求参数,如表3所示:
d) 返回结果
如下所示小区信息“丰台区太平桥街道华源三里”通过地理编码API服务地址获取到经纬度数据“116.320237, 39.879165”,分别根据两个数据源中的小区名称调用地理编码API服务地址可以获取小区信息的经纬度数据。
3) 行业特征匹配
组织机构特征匹配是根据数据预处理阶段标注的组织机构特征数据进行匹配,每个小区所属的组织机构是不变的,可以通过组织机构匹辅助实现中文地址匹配。
如图5所示,不同的两个数据源中两个组织机构“西直门网点”和“和平里网点”所包含的小区名称存在不一致的情况,数据源中A的“百万庄”小区和数据源B中的“百万庄中”和“百万庄大街”小区对应,因为都属于同一个组织机构“西直门网点”,因此通过组织机构特征的匹配,可以缩小中文地址中地址要素小区的范围,降低中文地址匹配的难度。
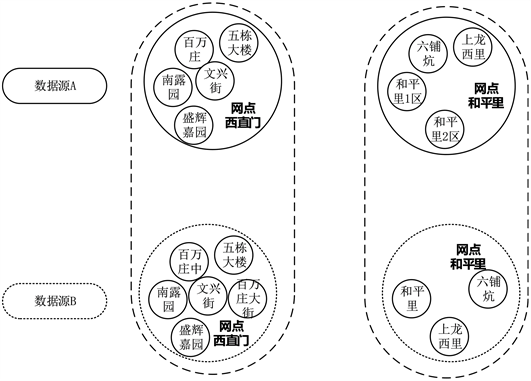
Figure 5. Organization feature matching
图5. 组织机构特征匹配
3.2. 结合建筑、统计、行业标注的楼匹配
本节基于规则链方式实现两个或多个数据源之间的楼信息的匹配。结合了建筑、统计、行业标注数据实现楼匹配,楼匹配流程如图6所示。
楼匹配规则链包括名称匹配、建筑特征匹配、统计特征匹配和行业特征匹配三个规则链,规则链内的规则可以动态增加,规则链的包含的规则内容如下:
Table 4. Building matching rule chain
表4. 楼匹配规则链
如表4所示楼匹配规则链包括以下内容:
1) 楼名称匹配
根据小区匹配成功的结果,验证两个数据源同一个小区内通过楼名称或别名相同的楼匹配。
如图7所示使用楼名称别名匹配规则B1-2,数据源B数据库中的“331号楼”与数据源A数据库中“1号楼”匹配,类似“332号楼”与“2号楼”匹配,“333号楼”与“3号楼”匹配。使用楼名称直接匹配规则B1-1,数据源B数据库和数据源A数据库的楼名称“A3号楼”和“A4号楼”如果相同,表示为楼匹配成功。
2) 建筑特征匹配
根据数据预处理的结果和小区匹配成功的结果,验证两个数据源同一个小区内通过楼的建筑特征(塔楼、板楼、别墅、平房)是否匹配。建筑特征匹配不是唯一性匹配条件,但是可以按分类缩小楼匹配的范围。
3) 统计特征匹配
统计每个楼所包含的用户数,用户数可以作为参考值进行匹配。
如图8所示,在楼号相同的情况下,统计特征每个楼包括的用户数可以辅助匹配,如果楼号不相同的情况下,无法直接通过统计特征进行匹配。
4) 行业特征匹配
如图9所示,行业特征主要包括用气性质匹配、通气日期匹配、表商匹配、用户状态匹配四个规则。用气性质匹配按照普通用户、壁挂炉用户和大用气量用户进行分别匹配,通气日期可以直接进行匹配,表商需要分类匹配,用户状态按照正常、停用和未开户分别匹配。行业特征无法提供唯一性匹配,重要程度不高,但是通过行业特征分类匹配后,可以缩小楼匹配的范围,降低楼匹配的难度。
3.3. 结合建筑、行业标注的详细地址匹配
相同的中文地址信息在两个系统中的详细信息不同,如数据源A的中文地址描述为“北京市朝阳区建外街道永安里国际公寓7号楼1单元1104”,而在数据源B中描述为“朝阳区建外街道永安里国际公寓(通用时代国际中心)7()11104”另外,在数据源A中的客户编码和数据源B中编码没有统一规范,也没有映射关系,因此无法直接通过技术手段进行关联。本文结合了建筑、行业标注数据实现详细地址匹配,匹配流程如图10所示。
详细地址匹配规则链包括塔楼用户匹配、板楼用户匹配、别墅用户匹配和平房用户匹配四个规则链,规则链内的规则可以动态增加,规则链的包含的规则内容如表5所示。
Table 5. Detailed address matching rule chain
表5. 详细地址匹配规则链
如表5所示详细地址匹配规则链包括以下内容:
1) 塔楼用户匹配
塔楼用户中文地址特征是“楼–门牌号”,匹配规则为“二元组匹配”。例如“车公庄北里36楼1901号”,直接通过数据库关联“楼”和“门牌号”二元组是否一致。
塔楼单元地址要素中录入了层的信息,需要通过层和门牌号结合形成唯一性的地址信息,例如:“东城区东直门街道东方银座B号楼10层H”,塔楼,但是操作员习惯性将楼层信息录入单元字段,门牌号中不含楼层信息。这种情况匹配规则为“三元组匹配”,层的信息不能缺失。
塔楼单元地址要素中信息为空,例如:“电子城小区20楼单元0807号”,只录入中文地址要素单元,但是单元前没有具体化。这类中文地址单元无实际意义,匹配规则为“二元组匹配”。
2) 板楼用户匹配
塔楼用户中文地址特征是“楼–单元–门牌号”,匹配规则为“三元组匹配”。例如:“圣都大厦20#楼1单元305号”。
塔楼用户中文地址特征是“楼–门–门牌号”,匹配规则为“三元组匹配”,例如:“鼓楼西大街113号3门201”。
塔楼用户中文地址特征是“分隔符”,匹配规则为“三元组匹配”,例如:“开阳里一区-1#-5-301”。
3) 别墅用户匹配
别墅用户中文地址的特点是“小区–楼”,匹配规则为“二元组匹配”。例如“紫玉山庄K3071号别墅”。
别墅用户中文地址的特点是“小区–楼单元号”,匹配规则为“二元组匹配”,例如“中海瓦尔登湖别墅247楼单元号”,“单元号”无实际意义。
4) 平房用户匹配
平房用户中文地址特征是“小区–门牌号”,匹配规则为“二元组匹配”。例如“二外东平房15号”。
平房用户中文地址特征是“小区–楼单元–门牌号”,匹配规则为“二元组匹配”。例如“太平庄10号院平房楼单元8号”,“楼单元”无实际意义。
4. 实验结果及分析
为了验证模型有效性,以某燃气公司两个不同数据源中的居民用户中文地址为实验数据进行小区匹配、楼匹配和详细地址匹配验证。
4.1. 匹配率测试
分别从两个不同数据源中以组织机构为单位抽取3种不同容量的数据样本。
样本A1,随机抽取数据源A中的1个服务网点的用户数据,总共包括76个小区,245个楼信息,33,081条用户数据,抽取数据源B中相同服务网点的用户数据,总共包括82个小区,231个楼信息,32,063条用户数据。
样本A2,随机抽取数据源A中的2个服务网点的用户数据,总共包括117个小区,716个楼信息,65,319条用户数据,抽取数据源B中相同服务网点的用户数据,总共包括126个小区,705个楼信息,64,972条用户数据。
样本A3,随机抽取数据源A中的3个服务网点的用户数据,总共包括181个小区,907个楼信息,117,882条用户数据,抽取数据源B中相同服务网点的用户数据,总共包括190个小区,924个楼信息,120,491条用户数据。
通过表6小区匹配结果分析,小区匹配因为数据量较少,虽然两个系统中小区的定义不同而存在别名情况,导致两边的小区数量不一致,但是通过规则链的方式,不断迭代增加别名替换规则,最终是可以实现小区地址要素90%以上的匹配,小区的匹配结果为后续楼和详细地址匹配提供高质量的基础数据。
Table 6. Community address matching results
表6. 小区匹配结果
通过表7楼匹配结果分析,匹配失败的楼主要原因是原始数据缺失严重,数据源A的楼信息在数据源B无法找到,后续需要继续通过人工方式补充缺失的数据。
Table 7. Building address matching results
表7. 楼匹配结果
通过表8详细地址匹配结果分析,详细地址匹配结果作为中文地址匹配的最终结果,随着样本数量逐渐增加,匹配成功率没有显著降低,通过分析匹配失败的详细地址分析,主要原因是数据预处理阶段,无法预知所有的异常处理、缺失数据,需要后续通过不断迭代方式增加和优化规则链,提升数据预处理阶段的数据质量。
Table 8. Detailed address matching results
表8. 详细地址匹配结果
4.2. 匹配质量测试
对于4.1节中已匹配成功的中文地址进行匹配质量测试,从三组样本集中数据中,分别随机抽取1000条,2000条,3000条中文地址进行准确率统计,如表9所示。
如表9中所示,三组样本集的中文地址匹配的准确率均保持在97%以上。通过分析异常匹配数据,主要原因是原始数据预处理阶段,中文地址标准化过程中,地址要素拆分中存在异常,需要后续优化规则链中的规则内容。
4.3. 实验小结
以某燃气公司两个不同的业务系统中的居民用户中文地址为实验数据,随机抽取三组样本数据进行中文地址匹配。通过实验结果分析中文地址匹配成功率90%左右,准确率97%左右。通过分析未匹配成功的中文地址主要有三个原因:一是中文地址存在缺失数据、重复数据、不规范数据的问题,需要不断增加和优化规则链,通过多次迭代方式逐步提升匹配成功率;二是中文地址标准化过程中地址要素拆分错误,导致后期的匹配失败;三是两个不同业务数据源的中用户数量不对等,存在数据源A中有的中文地址,数据源B中无法找到,这是因为企业缺失用户主数据的统一管理,没有形成统一的管理入口,业务人员分别从多个数据源录入,造成这种用户数据不对等的情况,因此无法实现100%的匹配。综合以上情况,实验结果表明该模型可以一定程度提高中文地址匹配的成功率,保证较高的准确性。
5. 结束语
本文面向非规范的中文地址,设计了一种结合标注的中文匹配规则链模型。该模型针对不同地址要素设计多种规则链。其中包括结合北京市地址标准库设计的小区匹配规则链,融合中文地址中的建筑特征、地理特征、统计特征构建的楼匹配规则链,以及基于二元组和三元组匹配规则设计的详细地址匹配规则链。采用分级匹配、逐级缩小、循环迭代的方式,实现了中文地址匹配。以某燃气公司两个不同的业务系统居民用户中文地址为实验数据进行匹配,实验结果验证了模型的有效性。模型的优点是针对不同特征的中文地址,可以选择不同的规则链,规则链节点内的规则可以通过迭代方式动态增减。不足之处是匹配失败的中文地址,需要人工方式更新或增加规则,继续迭代匹配。
NOTES
*通讯作者。