1. 引言
近年来,金融业务数据化趋势显著,对金融市场秩序维护造成了极大的挑战。上市公司风险的分类与预测,可以推进市场分类监管、精准监管、科技监管,推动公司有效控制风险,保护投资者合法权益,实现上市公司的高质量发展。
现有关于我国上市公司风险分类与评级主要集中在上市公司的信用风险 [1]。当前应用于信用风险研究的模型主要集中在机器学习的分类算法,除了常规机器学习的方法之外,还有机器学习算法的改进、算法与算法之间的结合等。Guo Y.等学者 [2] 使用BP神经网络对信用风险评估模型进行了研究,结果显示与Logistic算法相比,BP神经网络效果更佳。Zhou等学者 [3] 使用最近子空间算法、SVM和最近邻方法对美国信用卡数据集进行分类,显示最近子空间算法在信用风险评估上更有效。Luo J.等学者 [4] 提出一种无监督二次曲面支持向量机(QSSVM)用于风险评估。Tian Z.等学者 [5] 使用梯度提升决策树对信用风险进行了评估。陈云等学者 [6] 在SVM的基础上提出一种混合集成策略RSA-SVM,在UCI机器学习数据库中的信用数据集上将RSA-SVM与一些常见的信用风险评估模型进行了对比,显示了RSA-SVM具有更高的预测准确率。孙晓琳等学者 [7] 使用混合logit模型对房地产公司的信用风险进行了较高的识别与预测。申晴等学者 [8] 提出了一种新的银行信用风险识别方法SVM-KNN组合模型。马威 [9] 使用决策树算法对小额贷款公司的信用风险进行研究并提出相应的管理建议。赵静娴等学者 [10] 使用神经网络与决策树相结合的算法对信用风险进行了评估与分类。
目前,我国对于上市公司的风险识别研究较少。经过上述文献的启发,将上市公司的信用风险分类方法应用于上市公司的风险识别。决策树(Decision Tree)作为机器学习中的一种经典算法,主要用于分类和预测 [11]。决策树算法可以处理标称型属性、数值型属性和缺失值,新增的剪枝技术可以解决模型的过拟合问题,并且不局限于二分类,多分类依然适用,适用范围广,原理简单易懂,已广泛应用于诸如故障诊断 [12]、图像识别 [13]、临床研究 [14]、土地利用 [15] 和信息提取 [16] 等方面,并取得了很好的效果。因此,文中引入决策树算法对上市公司风险进行识别。
2. 模型理论
2.1. 决策树
决策树是一类常用的机器学习算法,与其他分类算法不同的是,它是基于树结构来进行决策的。树是一种非线性的数据结构,包括根结点、父结点、子结点和边,有助于对分类问题进行决策。构造决策树的常用算法包括ID3、C4.5和CART等 [17]。ID3是利用信息增益进行决策树的划分特征选择,C4.5是在ID3的基础上将信息增益改进为信息增益率进行划分特征,CART是使用“基尼系数”(Gini index)进行划分特征。决策树生成步骤一般分为特征选择、决策树生成和剪枝。
信息熵是决策树算法用到的重要概念,是一种度量数据集不确定性的常用指标。值越大,数据集的不确定性越大。假设数据集C中有k类,第i类样本所占比例为
,则C的信息熵为:
(1)
条件熵
为在已知特征a条件下数据集C的不确定性,假设数据集C中特征a有V个取值
,使用特征a对数据集C进行划分,产生的V个分支结点,其中第V个分支结点包含了C中特征a上取值为
样本,记为
。
(2)
信息增益为对数据集C用特征a进行划分后,数据集C的条件熵与数据集C的信息熵的差值。
(3)
信息增益率为了避免每个分支结点仅包含一个样本导致决策树不具有泛化能力,定义为:
(4)
其中,
为属性a的固有值。
2.2. 成本敏感决策树
不平衡数据是指一类样本比另一类样本数据量大的多,并且在现实生活中,小样本数据通常更具有价值。普通的分类模型倾向于大样本的分类准确率,会忽略小样本的分类准确率来提高整体的准确率。成本敏感决策树 [18] 就是针对不平衡数据分类提出的算法,成本敏感决策树中使用成本矩阵(见表1)表示分类器的误分类成本。
假设1代表正(小)样本数据,0代表负(大)样本数据。一般情况下,
。
成本敏感决策树是通过最小化错误分类成本来选择分裂属性,成本函数C为式(5)。
表示每个样本的平均成本,用于评估模型的综合性能。
(5)
(6)
(7)
样本X中包含
个属性(
),每个属性有j个不同的值
(
),在
处的误分类成本为:
(8)
其中,
表示分支j的比例,
表示分支j的成本。对于非叶子结点j,它的成本是所有叶子结点成本的加权和。对于叶子结点j的成本
如下式(9)。
(9)
其中,
表示正样本在
处比例,
表示在
处样本总数目;
表示负样本在在
处比例;
是在叶子结点
处正样本的成本;
是在叶子结点
处负样本的成本。如果
,则叶子节点为正,否则为负。
3. 上市公司风险指标体系构建
本研究根据《深圳证券交易所上市公司风险分类管理办法》(简称《分类办法》),从基础性指标和触发性指标两方面构建上市公司风险指标体系。其中,审计意见、退市状况、财务造假、资金占用、违规披露、操纵股价、违规担保、失信执行人、内幕交易、股份质押比10个指标为触发性指标,剩下的12个指标为基础性指标。根据熵权法得到各二级指标的权重,具体指标体系如表2所示。

Table 2. Risk rating index system
表2. 风险评级指标体系
4. 实证分析
4.1. 数据来源
样本是从深圳证券交易所选取了35个违规犯罪的公司,这些都是存在财务造假、违规担保、资金占用、操纵股价等违法犯罪影响恶劣的典型案例,又从不同板块选取30个无记录违规犯罪的公司。本研究所选取的65家企业涵盖了食品、纺织、家具、电子、化学、金属、设备、医药、生物制品等多种行业,具备全面性,也可保证模型的通用性。根据《分类办法》上的原则,将65家上市公司进行设置标签。高风险类(3)、次高风险类(2)、关注类(1)、正常类(0),样本集见附录。
4.2. 上市公司风险分类模型结果分析
上市公司风险分类根据触发性指标建立模型,将数据集分为训练集和测试集,训练集为编号1~55的上市公司,测试集为编号56~65的上市公司,根据测试集的准确率来反映模型的性能。通过决策树算法得出训练集结果如图1所示:
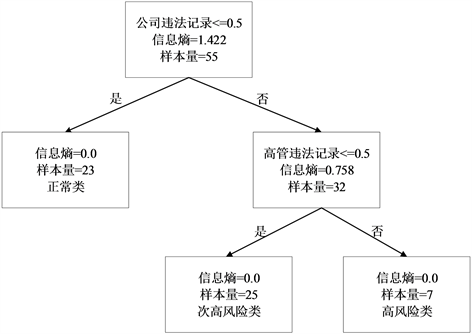
Figure 1. Decision tree of training set
图1. 训练集的决策树
测试集的模型预测结果如表3所示:
由以上结果可知,无论是训练集还是测试集,模型准确率都达到100%。说明决策树算法作为上市公司风险分类模型可以准确的将其上市公司进行风险划分。而在现实生活中,不仅需要对已经违法犯罪的公司进行分类处罚,对于潜在的违法犯罪公司也应予以警告,及时制止,防止对社会经济造成更大的危害。因此,本研究采用基础性指标进行决策树分类风险预测,以期对上市公司的风险预测有一定的参考。
4.3. 上市公司风险预测模型结果分析
对基础性指标使用决策树模型,训练集为编号1~55的上市公司,测试集为编号56~65的上市公司,模型结果如图2所示。

Figure 2. Basic index decision tree model
图2. 基础性指标决策树模型
测试集的模型预测结果如表4所示:
Table 4. Test set model prediction results
表4. 测试集模型预测结果
由以上结果可知,训练集准确率为92.7%,测试集准确率为80%,模型预测效果良好。但是,有风险的上市公司错分代价较大,对经济社会可能产生较大的恶劣影响。因此,需要对预测模型进行优化。
4.4. 上市公司风险预测模型优化
根据预测模型的分类结果,其中有风险公司被预测为正常公司的样本如表5所示。利用分类结果为正常公司的样本用成本敏感决策树进行二次分类。
Table 5. Listed companies at risk that have been wrongly classified
表5. 被误分的有风险上市公司
本文错误预测一个有风险的上市公司比错误预测一个正常公司付出的代价要大;正确预测一个有风险的上市公司比正确预测一个正常公司所产生的收益要多。如表6所示为上市公司的价值矩阵。
表中(2)代表次高风险上市公司,为小样本数据;(0)代表正常上市公司,为大样本数据。假设对于上市公司预测风险正确的价值为正,即
;对于上市公司预测风险错误的价值为负,即
。并且,有风险上市公司预测正确的价值比无风险公司预测正确的价值大的多,即
。根据价值矩阵,可得次高风险的上市公司预测为正常公司的代价为
,正常上市公司预测为次高风险的上市公司代价为
,其中
,可得上市公司成本矩阵如表7所示。
本研究使用软件Weka进行训练本研究提到的成本敏感决策树 [8],具体设置的参数为confidenceFactor为0.25,minNumObj为1,subtreeRaising选Ture,Unpruned选Ture,其他为默认设置。在测试更多选项中添加了成本敏感价值矩阵,通过大量重复的试验,当
,
时,总成本以及平均成本都是最小的。模型运行结果如图3所示和表8所示。
Table 8. Forecast result of cost-sensitive decision tree
表8. 成本敏感决策树预测结果
结果显示,成本敏感决策树的二次分类使有风险的上市公司全部分类正确,整体准确率也由91.7%提高到96.7%。
5. 结论与建议
本文针对上市公司违法犯规行为,根据《分类办法》构建了上市公司风险分类指标体系,将触发性指标利用决策树构建了上市公司风险分类模型,结果表明无论训练集还是测试集分类准确率达到100%。为了预测上市公司的风险等级,本文将基础性指标利用决策树构建了上市公司风险预测模型,得出预测准确度为80%。最后,针对错分有风险上市公司代价更大问题,应用成本敏感决策树对分类正常的上市公司进行了二次分类。结果表明,成本敏感决策树对于代价不平衡问题具有很好的适应性,将决策树与成本敏感决策树结合处理上市公司风险分类,既可以保证准确率,也可以保证错分代价最小。本文的创新之处在于:在上市公司风险分类评级指标体系还不成熟的情况下,创造性地从基础性指标和触发性指标上建立了评价指标体系;建立的模型不仅可以对已有违法犯罪的上市公司进行分类评级,而且将模型应用到普通公司,预测其风险状况,以便及时采取措施。
根据以上结论提出以下政策建议:第一、对于已经通报违法犯罪的上市公司,深圳证券交易所可以直接根据决策树模型将其风险分类,以做出相应的处分;对于潜在违法犯罪的上市公司,深圳证券交易所可以使用成本敏感决策树进行分类,以预测有风险的上市公司。第二、为了减少上市公司违法犯规,应该建立上市公司诚信档案,限制失信公司及高管行为,并加大行政和刑事处罚力度,增加违法犯罪的成本。
基金项目
上海市哲学社科基金“上海社会化养老模式创新研究”(2019BGL020);
中国博士后科学基金面上资助基金“最低工资标准确定及调整机制研究”(2019M651540)。
附录