1. 引言
会话推荐是推荐系统的重要组成部分,其对用户点击交互的商品、新闻、音乐等历史序列进行分析,预测下一步点击的内容。会话推荐由于主要关注序列本身,不借助用户或项目的特征即可对该用户下一次点击的商品实现推荐或预测,有利于解决匿名用户推荐等问题,故在近几年备受关注 [1]。
会话为用户在一段时间内访问电子商务等平台,依次点击商品的序列,本身不含用户或商品特征上下文,传统的协同过滤 [2]、矩阵分解 [3] 等方法不适用处理会话信息。会话推荐的主要研究内容是如何分析用户的点击会话数据,设计合适的推荐算法,预测用户后续点击的内容。根据会话的时序特性,其建模一般使用马尔可夫链 [4] 或RNN (Recurrent Neural Network,循环神经网络) [5] 等方法处理,以获得会话建模。然而,单纯的RNN等结构难以处理用户随机点击问题;其次,各会话相对孤立,会话之间的信息未被充分挖掘。对于使用GNN (Graph Neural Network,图神经网络) [6] 的会话推荐模型,其将所有的一维会话序列整合成一个二维图结构,以刻画信息较为整体的向量表示。虽然GNN从整体的方式克服了会话的孤立性,但未能以个体的角度捕捉每个用户的兴趣变化,未能实现实时推荐,如某学生在考试前关注图书或文具类商品,考试后关注娱乐类商品等,且噪声商品问题仍待解决。
针对会话推荐中的用户行为随机、商品数据稀疏和推荐结果滞后等问题,本文提出一种融合了GNN和AM (Attention Mechanism,注意力机制)的会话推荐模型TGGA-SR,在充分利用会话数据的基础上实现准确推荐,并解决以下问题:
1) 用户行为随机性。为减少上述噪声商品对推荐结果的影响,模型根据用户点击相邻商品的时间间隔生成相对点击时间率,参与商品关系依赖图的生成,对很短时间连续点击的商品之间赋予较小的权重。
2) 商品数据稀疏性。针对会话推荐中用户或商品特征缺失的特点,模型首先通过生成商品关系依赖图建立商品之间的联系,然后使用多层GNN进行向量表示,聚合多阶邻居节点信息。
3) 推荐结果滞后性。用户在不同时期会表现不同的兴趣偏好,点击的商品会发生变化。根据这一特点,用户下一步关注的商品与最后一次点击的商品有很大关联。模型结合GRU和AM,对用户会话时间靠后的商品信息进行强化,形成实时推荐。
2. 研究现状
2.1. 传统会话推荐方法
这类方法采用数据挖掘或机器学习等手段挖掘会话内数据的相关性,进行会话推荐。
Item-KNN [7] [8] 是基于物品的k-近邻算法,通过召回和会话余弦相似度最高的物品进行推荐。Mobasher等人 [9] 提出了关联规则的方法,以条件概率的方式计算置信度返回预测项目。BPR-MF [10] 结合贝叶斯个性化排序与矩阵分解,主要通过随机梯度下降法优化Pairwise排序损失函数。FPMC [4] 则采用了马尔可夫链模型,为每个用户生成单独的转移概率矩阵,生成转移矩阵立方体,用于预测未知物品引起用户兴趣的可能性,并以此排序得出物品推荐列表。
2.2. 基于深度学习的会话推荐方法
这类方法主要结合RNN、GNN等手段,具有表达能力强,挖掘更多数据隐藏模式等特点。
RNN主要用于建模序列信息,其变体LSTM或GRU因能有效记忆较长序列而获得较广泛的应用,在机器翻译 [11]、语音识别 [12]、视频描述 [13] 等领域都有很好的效果,也适合处理会话。GRU4REC [14] 为经典的融合RNN会话推荐模型,该模型还根据物品流行程度进行采样,划分正负样本,使用基于排名的损失函数。NARM [15] 在基于RNN的会话推荐模型基础上加入了AM [16],从隐状态捕获用户在当前会话的目的,并结合用户浏览时的序列行为进行推荐。STAMP [17] 则结合记忆力与注意力,同时考虑用户通用兴趣和当前兴趣,并通过提高短期兴趣的权重来减轻兴趣漂移对推荐结果的影响。
GNN为图表示学习(Graph Representation Learning)的一个分支,采用CNN (Convolutional Neural Networks,卷积神经网络)思想表示图结构,GNN根据节点聚合与更新方式的不同,主要模型有GCN [18]、GraphSAGE [19]、GGNN [20] 等,在推荐系统 [21]、生物医学 [22]、知识图谱 [23] 等领域皆有应用。相较于RNN对会话进行建模缺乏对商品的刻画,GNN可以将所有会话合成一张图,进而学习商品表示。SR-GNN [24] 是其中的经典模型,其结合AM考虑用户当前兴趣。TAGNN [25] 模型也借助AM将用户的短期和长期兴趣结合推荐。SEMGNN [26] 模型则从商品类别和商品本身两个不同粒度分别形成图结构,得出商品和商品类别的表示并用AM进行信息融合,输入到GRU学习会话信息,形成推荐。
3. 算法模型
3.1. 问题描述
如图1,多个用户在一段时间内登录电子商务平台,分别先后点击了若干商品。用户依次点击的商品序列形成会话,而这些会话不包含用户或商品的特征信息。本模型需要通过分析这些会话预测各用户下一次点击的商品,实现推荐。
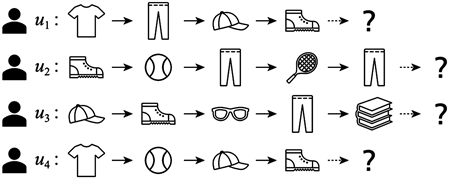
Figure 1. An example of problem description
图1. 问题描述示例
3.2. 总体结构
本文TGGA-SR模型结构如图2所示。该图展示模型根据用户点击商品记录实现商品推荐,大量用户浏览商品行为数据经过处理后,形成用户点击商品会话(①)。这些会话将整合到商品关系依赖图的有向图结构中(②),并由GNN学习商品表示(③)。处理用户表示时,将用户点击商品对应的商品表示按会话顺序排列,作为GRU的输入,并由结合AM形成最终用户表示(④),最后生成推荐结果(⑤)。

Figure 2. The architecture of TGGA-SR model
图2. TGGA-SR模型结构
3.3. 建立商品关系依赖图
TGGA-SR的输入数据为电子商务平台在一段时间内用户与商品的交互日志,包括用户ID、商品ID和交互时刻(用户点击商品的时刻)等关键信息。模型首先把属于同一个用户ID的所有日志按时序整理成会话,即会话包括某用户先后点击的所有商品。一般而言,用户u在一段时间依次点击了n件商品
,则相应形成会话
。会话用于用户向量建模,也参与商品关系依赖图的生成。
商品关系依赖图集合了所有会话的节点和边信息。商品关系依赖图G以会话内商品为节点,相邻商品之间的商品节点建立有向边,由先点击商品指向后点击商品。以图2的会话
为例,G的子图
则存在有向边
,
,
,
,形成的子图
结构如图3所示。所有会话的商品关系依赖图
节点与有向边分别取并集,形成最终的商品关系依赖图G。这种将原本一维的会话整合成二维的图结构方法,可以进一步挖掘商品之间的联系,减少数据稀疏。
根据用户自身偏好,用户在点击浏览不同的商品时会呈现不同的关注程度。由于会话不含用户和商品特征,用户对商品的关注程度仅能依据时间信息间接判断。如果用户对某商品的关注程度较高,则该商品的浏览时间相对较长,且在会话内所有商品浏览总时长占比较高。故TGGA-SR引入会话相对点击时间率(Relative Time Ratio) [27],用来衡量会话内商品的重要程度。

Figure 3. Subgraph of item relationship dependency graph
图3. 商品关系依赖图的子图
一般地,在会话
中,用户u先后在
和
时刻分别点击商品
和
,则两者点击时间间隔
相当于用户u在电子商务平台展示商品
的时长,以s为单位。若
和
商品未依次点击,即有向边
,则
。时间间隔定义见式(1)。
(1)
较短的商品展示时间反映用户对该商品的关注程度较低,或随机性点击商品 [27]。而在适当情况下展示时间越长的商品,反映该商品越能引起用户的关注,越符合用户的期望。但展示时间如果过长,并不一定意味着该商品符合期望,因为用户可能处理其它事务或离开屏幕,暂停浏览商品。故TGGA-SR模型根据真实数据集的统计规律,设置停留时间上限。
会话相对点击时间率用来衡量会话内的商品展示时长在整个会话时长的比例,反映该商品占整个会话的关注程度。如会话
内商品
的会话相对点击时间率如式(2)所示。
(2)
会话相对点击时间率参与商品关系依赖图的有向边权重计算,以设定权重的方式加强或削弱会话中商品之间的联系,如较低的会话相对点击时间率反映两种商品切换时间相对较短,关联度较小,以此减少了因随机性造成的误差。整个商品关系依赖图G的出度矩阵与入度矩阵分别由式(3)和(4)定义。
(3)
(4)
其中,i表示会话序号;
为商品节点
的出度,表示整个平台一段时间内先点击商品
、后点击其它商品的行为次数;
为节点
的入度,表示先点击其它商品、后点击商品
的行为次数。建立的商品关系依赖图为后续商品基于图神经网络的向量表示提供依据。
接续会话
的例子,假设5件商品点击时间间隔依次为10 s、50 s、200 s、140 s,则子图
出度矩阵
和入度矩阵
分别如图4的(a)、(b)所示。
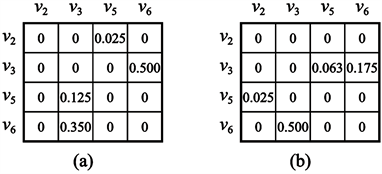
Figure 4. An example of out-degree matrix and in-degree matrix
图4. 出度矩阵和入度矩阵示例
3.4. 商品向量表示
TGGA-SR使用GNN学习商品关系依赖图的节点,形成商品的向量表示。由于图为节点和边表示的结构,相邻节点以边联结,GNN形成节点向量的过程则由其相邻节点向量的信息传播到该节点,并作一定聚合获得。
商品关系依赖图商品节点采用GGNN (Gated Graph Neural Network,门控图神经网络)学习。GGNN结合RNN思想学习节点向量,节点信息随单位时间传播。图5为
按时序展开传播信息的示意图,各节点向量信息在当前时刻以同样的规则传播、聚合形成下一时刻的节点信息,以
为初始单位时刻。传播规则为,对于尾节点指向头节点的有向边,每个头节点接收尾节点的信息,也向尾节点反向发送当前信息。以图5的有向边
为例,在
时刻,节点
对应的信息
向
传播(实线箭头),参与形成
时刻的信息
;同时
反向传播到
(虚线箭头),参与形成
。
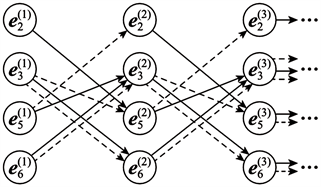
Figure 5. The propagation of GGNN per time unit
图5. GGNN单位时间传播示意
对于整个商品关系依赖图,TGGA-SR设定多层GGNN,聚合更多相邻商品的信息,使商品之间的联系更紧密。学习过程如式(5)至式(10)所示。
(5)
(6)
(7)
(8)
(9)
(10)
上述式中,式(5)的
为商品节点的初始向量表示。式(6)的
是单位时刻
各商品节点向量表示;
是商品关系依赖图G的出度矩阵
和入度矩阵
的拼接,
;
表示从
中选择对应节点
的两列;
为权重;
为偏置。
式(7)至式(10)类似于GRU (Gated Recurrent Unit,门控循环单元)正向传播过程,其中
为sigmoid激活函数,式(7)相当于更新门,用于控制上一时刻的信息的去留;式(8)相当于重置门,用于控制新信息的产生;式(9)为候选新向量表示,其中
表示哈达玛积(Hadamard Product),即对应元素乘积;式(10)通过对新旧向量表示的控制,形成下一时刻商品向量表示。
3.5. 用户向量表示
TGGA-SR用GRU和AM生成用户向量,以表示用户偏好程度。用户向量表示的输入为会话的商品序列,其中的商品为上一步学习的商品表示。图6以会话
为例进行用户向量表示的过程。
3.5.1. 用户会话处理
TGGA-SR使用GRU处理会话,因其可避免传统RNN在长序列训练过程出现的梯度消失问题,也较LSTM (Long Short-Term Memory,长短期记忆)使用更少的参数。GRU模型如图7所示。
GRU的前向传播如式(11)至式(14)所示。
(11)
(12)
(13)
(14)
其中,
为当前时刻商品向量输入,
为上一时刻输出。式(11)和式(12)分别为更新门和重置门的处理过程。式(13)为候选新状态生成,并在式(14)与旧状态结合,形成新时刻状态。
3.5.2. 注意力机制
注意力机制(AM)源于人类对事物的观察,即人的目光聚焦在事物的关键区域,以获取所需信息,而其它无关区域会被忽略。推荐模型应用AM可将相关特征进行强化或抑制,以得到更准确的推荐结果。TGGA-SR利用AM先计算每个特征的权值,再对特征进行加权求和,权值越大,对当前的结果影响就越大。
考虑到用户的兴趣具有阶段性变化,点击的商品与上一项有关联,即会话越靠后的商品对用户兴趣建模的贡献度越大,故应用AM对会话靠后的商品信息进行加强,同时也能对噪声类商品信息进一步抑制,实现实时推荐。设置注意力权重因子
,其中n为会话的末端商品,用于衡量两个GRU输出位置之间的关联程度。权重因子计算如式(15)所示。
(15)
其展开如式(16)所示。
(16)
其中,参数矩阵
,
分别将LSTM隐层状态
,
进一步转化为隐向量表示。通过将隐层状态转换求和,得到的结果再经过sigmoid激活函数,获得新的隐向量表示。将新隐向量表示与参数矩阵
进行矩阵乘法,最终得到权重因子。
将权重因子分别作用于各GRU单元输出,并进行线性变换,最终得到用户表示
,该过程如式(17)所示。
(17)
3.6. 推荐结果预测
在获得用户表示与商品表示后,TGGA-SR先进行用户与商品的余弦相似度计算,再进行softmax归一化形成预测商品的概率分布,进行Top-k推荐。此过程如式(18)和(19)所示。
(18)
(19)
由于用户对商品浏览行为只有浏览和不浏览两种,因此选择二分类交叉熵作为损失函数,如式(20)所示。
(20)
其中,
为预测概率分布,
为真实分布。
4. 实验
4.1. 数据集与处理
本文使用Yoochoose和Diginetica两个数据集进行实验。Yoochoose数据集是由英国在线零售商提供的用户在6个月内,含9,249,729件商品的共计33,003,994条用户点击记录,每条记录分别包含会话ID、时间戳、商品ID、商品类别信息。Diginetica数据集记录了另一个电子商务平台用户在5个月内,含43,097件商品的共计204,771条用户点击记录,每条记录分别包含会话ID、用户ID、商品ID、点击发生的时间帧、点击发生的日期信息。
本文对数据集进行拆分。对于Yoochoose数据集,将最后1天数据作测试集,其余作训练集;对于Diginetica数据集,将最后7天数据作测试集,其余作训练集。实验根据Li等人 [15] 和Liu等人 [17] 的工作进行数据预处理。两个数据集长度为1的会话和出现次数少于5次的商品将被过滤,同时过滤测试集中未曾出现在训练集中的商品。过滤后,Yoochoose数据集有7,981,580个会话及37,483件商品,Diginetica数据集则有202,633个会话及43,097件商品。
本文根据Tan等人 [28] 的工作对实验数据进行扩充。具体扩充一般方法为,原会话
拆分成一系列子会话和标签
,
,……,
,其中
内的子会话为输入的会话,最后一项为结果标签。由于Yoochoose数据集数据量大,根据Li等人 [15] 和Liu等人 [17] 的工作,仅使用该数据集的靠后部分进行训练就可以获得更好的结果,故分别取该数据集最后的1/64和1/4数据进行实验。表1为实验数据集统计信息。
由于Yoochoose和Diginetica原始数据集均记录了商品点击时间帧,故模型可以记录会话内点击相邻商品之间的时间间隔。图8和图9分别展示了Yoochoose和Diginetica数据集相应点击时间间隔的频次分布。

Figure 8. The distribution of click-time interval from Yoochoose datasets
图8. Yoochoose数据集点击时间间隔分布

Figure 9. The distribution of click-time interval from Diginetica datasets
图9. Diginetica数据集点击时间间隔分布
需要说明的是,Yoochoose数据集的最长时间间隔达3600 s,Diginetica数据集则长达1200 s。表2以分段的形式完整给出了不同时间间隔区间的频次占比。

Table 2. Statistics of time interval from datasets
表2. 数据集时间间隔统计信息
虽然两个数据集组成不同,但分别处理和统计后可从统计图表看出,除了0 s附近时间间隔有差异,两个数据集的用户点击行为整体相近,大多数时间间隔集中在180 s以内,此后的频次随时间间隔增加呈现递减趋势。
由于1200 s以上的时间间隔频次少,较长的时间间隔可能由处理其它事务或离开屏幕而暂停浏览商品造成。为保持数据的完整性以及减少其它商品的会话相对点击时间率过小的影响,模型设置时间间隔上限为1200 s。另外,Yoochoose数据集频次最高的点击时间间隔集中在5 s附近,用户在如此短的时间内点击,往往未能有效阅读平台展示的商品信息。这些商品被视为噪声商品,不利于形成用户兴趣,给推荐结果带来不利影响。相对点击时间率的引入试图削弱短时间间隔浏览商品之间的联系。
4.2. 基准方法
为了评估本文所提出TGGA-SR模型的有效性,将该模型与以下模型进行对比。
第一类为传统会话推荐模型,包括POP [14]、S-POP [14]、Item-KNN [7] [8]、BPR-MF [10]、FPMC [4],部分模型已在前文讨论。POP是简单的流行度预测方法,将数据集中出现频率最高的商品进行推荐;S-POP是基于当前会话的流行度预测方法,为用户推荐当前会话下出现频率最高的商品。
第二类为基于深度学习的会话推荐模型,包括GRU4REC [14]、NARM [15]、STAMP [17]、SR-GNN [24]、SEMGNN [26],已在前文讨论。
4.3. 评价指标
本文采用会话推荐场景中最常用的Precision@k和MRR@k (Mean Reciprocal Ranks, MRR)两种评价指标评估模型。
Precision@k用于衡量基于会话的推荐系统的预测准确性,表示推荐结果列表中排在前k个推荐物品中,有正确物品的样本所占的比例。指标定义如式(21)所示。
(21)
其中,
表示前k个推荐物品中有正确物品的样本数量,N表示测试集的总样本数。
MRR@k表示平均倒数排名,是在Precision@k方法的基础上,加入了商品位置的影响。在推荐物品列表中物品的位置越靠前,则其值越大,反之越小,当物品不在前k个推荐物品中时,该值为0。指标定义如式(22)所示。
(22)
其中,N表示测试集的总样本数,
表示第i个测试样本的推荐列表中正确物品所在的排列位置。
实验取
,即前20件候选商品,这些商品在现实中往往出现在电子商务平台的第一页,受到大多数用户关注。
4.4. 参数设置
本文模型参数设定如下。商品向量嵌入维度
,学习率
,学习率衰减
,商品图神经网络嵌入表示层及GRU层的隐层节点个数均设置为100。训练批次设定方面,Batch大小为100,迭代次数为10。所有权重矩阵均采用服从
的正态分布随机初始化,L2惩罚系数为
,算法使用Adam优化方法对模型参数进行求解。
4.5. 实验结果及分析
本文所提出TGGA-SR模型与其它模型的对比见表3。
其中,FPMC在处理Yoochoose 1/4数据集时出现内存不足问题,未给出结果。从表3可以看出,传统会话推荐模型缺乏对会话转移信息的有效捕捉,效果总体较基于深度学习的会话推荐模型差。在基于深度学习的会话推荐模型中,引入RNN、GNN等可以较好地表示会话和商品所隐含的信息,从而带来相对较好的推荐结果。本文的TGGA-SR则通过引入会话相对点击时间率对噪声商品的信息有所抑制,同时使用AM获得相对实时的推荐,提高了推荐性能,在Yoochoose 1/64和Diginetica数据集均取得相对显著的提升。
4.6. 消融实验
消融实验(ablation study)的作用是验证TGGA-SR模型的各个部分对推荐性能的影响,本文设置了四种模型加以对照。相对于完整的TGGA-SR,–T为仅去除相对点击时间率,保留商品关系依赖图,但其出度矩阵和入度矩阵的构造与SR-GNN [24] 相同;–TG为仅去除商品关系依赖图和GNN的商品表示部分,直接学习会话信息;–GA为仅去除GRU和AM的用户表示部分,直接将用户会话涉及商品表示的平均值作为用户表示;–A为仅去除AM,直接使用GRU建模会话形成用户表示。实验结果如图10和图11所示。

Figure 10. Results of ablation study (Precision@20)
图10. 消融实验结果(Precision@20)

Figure 11. Results of ablation study (MRR@20)
图11. 消融实验结果(MRR@20)
从图10和图11可以看出,对于仅去除用户表示部分(–GA)的模型,由于会话潜在信息不能被GRU和AM有效挖掘,造成用户表示不理想,推荐效果显著降低。对于仅去除商品表示部分(–TG)的模型,商品之间的联系由于分散在一维会话结构中而不能有效聚合,形成的推荐结果不一定很好地符合用户需求。对于仅去除AM (–A)的模型,其缺少实时性修正,推荐的结果未必反映用户兴趣阶段性变化特点,效果不如完整模型。而仅去除相对点击时间率(–T)的模型则受到噪声商品影响,尤其是Yoochoose数据集出现较多随机点击行为,推荐性能较完整模型下降相对明显。
消融实验结果表明,本文TGGA-SR模型结合各模块的优势,具有更好的推荐效果。
5. 结束语
在基于会话的推荐算法中,目前大多数方法都只是使用会话中商品的信息,而潜在的用户点击商品时间间隔等信息没有利用,导致算法的学习不够充分。针对此问题,本文提出的TGGA-SR模型可以学到更充分的信息,模型的推荐性能用于其它模型。
但是,用户的长期兴趣和短期兴趣对推荐结果也有很大的影响,至于长期兴趣的表示,以及如何权衡长期兴趣与短期兴趣综合推荐,本文未作研究。后续将进一步研究用户的长短期兴趣对模型泛化能力的影响。
基金项目
广东省重点领域研发计划(2021B0101200002,2019B01018001,2020B0101100001);广东省科技计划项目(2020B1010010010,2019B101001021)。