1. 引言
随着科学技术的快速发展,我们能接收到的信息量不断上升,我们如何才能在这个信息爆炸的时代快速挑选出我们所需的信息成为了一个热点的研究问题。而个性化推荐系统是信息过滤的重要手段,是解决信息超载现状 [1] 的有效方法。现有传统的推荐方法存在着以下三个问题,1) 用户和物品之间的交互非常稀疏。例如,一个购物软件上可能有几百万件商品,但用户购买的商品可能只有几百件。推荐方法需要预测大量未知信息,但能利用的已观测到的数据却相对稀少,这会导致过拟合问题的产生。2) 由于系统中缺乏历史交互信息,无法为新用户或项目进行准确建模和推荐,这种情况也称为冷启动。3) 现在的推荐系统对于推荐商品的解释还比较随意甚至是缺乏可解释性。为了解决上述问题,研究者们将知识图谱(Knowledge Graph, KG)引入推荐系统中,知识图谱是一个多关系异构体,其中包含大量的实体和关系,一般以三元组形式呈现,例如(ipad,品牌,Apple),其中ipad和Apple是三元组中的头实体和尾实体,品牌是三元组中的关系。然而在知识图谱中实体之间会存在相关性不高的问题,导致推荐的准确率不高。针对该问题我们使用注意力机制融入知识图谱中并将其与实体的上下文信息融入实体来重新定义实体的嵌入来构建用户向量。综上所述,本文主要贡献如下:
1) 我们提出了将带有关系的实体间的注意力机制融入基于知识图谱的推荐模型重新定义实体的嵌入,以此来优化用户向量来作出推荐。
2) 我们将该算法与其它基于知识图谱的推荐算法在数据集Cell_phone和Clothing上进行了比较,评价指标准确率、点击率、召回率和NDCG的结果验证了本文所提算法能够提高top-K推荐的性能,同时也为推荐结果提供了可解释性。
2. 相关工作
近年来,对于在推荐系统中加入知识图谱引起了研究者们的兴趣。知识图谱被广泛用于各种应用中比如语义搜索、知识问答等等。总的来说,现有的基于知识图谱的推荐包含三种类型,基于路径、基于嵌入和基于传播的方法。
基于路径的推荐系统应用知识图谱主要是基于该图谱预先定义用户和项目之间的联系,然后将其放入模型中进行预测,基于路径的方法也有一定的效果和可解释性。Zhao等人 [2] 提出FMG算法,通过HIN和meta-graph,提供了一种简单有效的框架,既能够非常灵活地利用边的信息来提升推荐效果。同时,还能利用人工设计的meta-graph来保留必要的语义信息,从而对推荐结果提供一定的可解释性。YI等人 [3] 提出了一种基于元路径的随机游走策略,用于生成有意义的网络嵌入节点序列,以嵌入HINs。学习节点嵌入首先用一组融合函数进行转换,然后将其集成为扩展矩阵分解模型。对扩展后的MF模型 [4] 和融合函数执行联合优化预测任务。基于嵌入的方法通过使用KGE算法将学到的实体嵌入向量用于推荐系统框架中,使用用户和项目表征的点积结果来预测推荐结果 [5] [6]。无论是基于嵌入的方法还是基于路径的方法都只利用了知识图谱中的部分信息。这就使得知识图谱的信息不能得到充分的利用。因此为了让两种方法的优势能够充分发挥来获得更好的推荐,提出了将两种方法相结合的方法,主要思想通过路径中的关系,再使用嵌入的方法优化向量的表示。例如Wang等 [7] 提出了Ripple Net模型,这是基于传播的推荐方法的一个典型模型,该模型通过以用户的交互记录为中心在知识图谱中像水波纹一样沿着关系向外扩展寻找用户的偏好,通过用户偏好为用户建模来进行推荐,通过实验该方法的有效性也得到了验证。与Ripple Net类似,Tang等人 [8] 提出了AKUPM,该模型通过偏向向不同的实体传播用户的偏好。还有研究者利用图卷积网络 [9] [10] 和图网络的注意力机制 [11] [12] [13] 对知识图谱进行建模,并使其优化目标与推荐系统一致,从而提升了推荐结果。
尽管以上方法取得了一定的成果,但基于路径的方法在推荐前需要构建大量的元路径,严重依赖人工设计的元路径的数量和质量,并且当知识图谱发生改变时,就需要重新针对该知识图谱设计出有效的元路径。基于嵌入的方法虽然解决了定义大量元路径的问题但没有充分利用到知识图谱的信息。基于传播的方法通过在知识图谱上传播信息来探索用户的偏好,但在知识图谱中不是所有实体都有着较高的相关性,这不可避免地会引入与特定用户项目连接性无关的噪声,从而误导用户偏好的推断。为解决上述问题,我们提出了基于知识图谱融入注意力机制商品推荐的可解释性方法。
3. 研究思路和方法
本文受到RippleNet框架和关系预测方法 [14] 的启发提出了基于知识图谱融入注意力机制商品推荐的可解释性方法,该推荐方法分为以下四个步骤:第一步使用随机初始化向量表示用户实体、项目实体和他们之间的关系的表示;第二步通过实体间的注意力机制来更新实体的嵌入;第三步通过用户偏好和第二步中获得的实体嵌入来优化用户向量;第四步通过用户嵌入和项目嵌入来预测点击概率。其框架如图1所示:
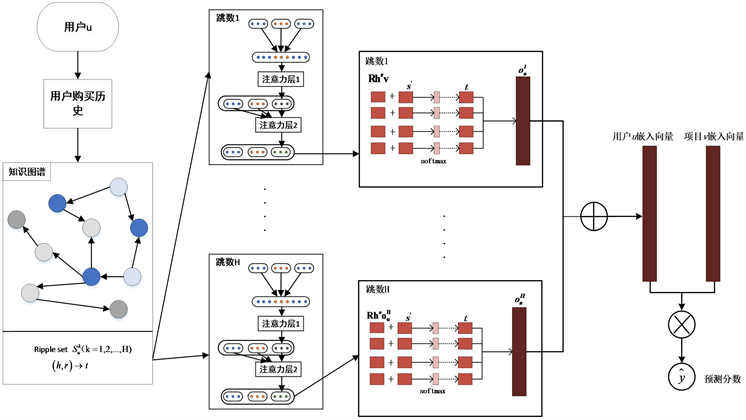
Figure 1. Overall framework of the method
图1. 方法总体框图
3.1. 相关定义
在商品推荐问题中,有用户集U和商品项目集V,用户–商品项目的交互矩阵
是基于用户的隐式反馈而定义的,如下所示:
(1)
知识图谱G,G中包含大量的三元组
,
,
,
是分别为三元组的头实体、关系和尾实体,其中E表示实体集合,R表示实体之间的关系集合。给定交互矩阵Y和知识图谱G,预测用户u与项目v交互的概率
,并生成top-N推荐列表:
(2)
其中
是推荐方法,
是方法中的参数集合。
为了用KG来描述用户层次扩展的偏好,我们递归地定义了用户的偏好。用户u的k-hop相关实体集合如下:
本文使用的符号与原始RippleNet框架一致,其中关键的两个相关定义如下:
定义1 (相关实体)通过交互矩阵Y和知识图谱G,对于用户u的相关k-hop实体的集合定义如下:
(3)
其中
是用户过去点击的实体项目集合,可以看作知识图谱中用户u的种子集,H是用户u在知识图谱中的最大跳数。
定义2 (波纹集)用户u的k-hop波纹集定义为从
开始的三元组的集合:
(4)
3.2. 注意力聚合层
本节将详细说明提出的实体间的注意力机制,该机制的作用是通过实体的近邻实体权重来将这些实体聚集在一起表示新实体的嵌入,使得最终该节点的嵌入信息包含近邻实体的信息,该实体的这些近邻实体也包括该实体本身,并且通过此机制避免了不相关实体的相关信息。
为了获得实体
的新嵌入,我们通过对实体和关系特征向量的连接进行线性变换来学习这些嵌入,该特征向量对应于
中一个相应的三元组
,如公式(5)所示:
(5)
其中
、
和
是关系
、头
和尾
的嵌入,||表示拼接操作,
表示权值矩阵,然后我们学习了第k跳中每个三元组的重要性
。我们通过一个权值矩阵
的线性变换,然后应用LeakyRelu激活函数来得到三元组的绝对关注值,也就是尾实体t在关系r下对头实体h的重要程度,公式如(6)所示:
(6)
在获得尾实体r对于头实体h的绝对关注值后,然后使用softmax函数对
进行归一化处理,公式如(7)所示:
(7)
其中
是在第k跳中连接头实体
和尾实体
的关系集合,
是头实体
的相邻实体集合。新的实体
的嵌入是由每个三元组嵌入和注意力值加权的表征,如方程(8)所示:
(8)
每个实体h嵌入都是由其近邻实体聚合表示的。我们利用多头注意力来稳定学习过程,将实体注意力重复N次,公式为(9)所示:
(9)
其中||代表的是拼接操作,
是一个任意的非线性激活函数,在我们模型的最后一层中,我们采用平均的方法来得到实体的最终嵌入向量,如公式(10)所示。
(10)
对于用户向量中头实体的嵌入我们的模型最终采用将基于注意力嵌入层得到的新
和原实体
进行相加,使得原实体的特征也参与了最终实体的表示,得到最终实体的嵌入,如公式(11)所示。
(11)
3.3. 用户向量构建层
在上节中,通过注意力嵌入层我们获取到了新的实体嵌入
,然后将每个候选项目嵌入表示为一个d维向量
,给定项目嵌入
和用户的1-hop波纹集合
,通过比较项目v和头
和该三元组中的关系
进行比较然后和尾实体的情感分数进行相加,为
中的每个三元组
计算一个相关概率
,如公式(12)、(13)所示:
(12)
(13)
其中
和
是关系
和更新后头实体
的嵌入,
是一个商品评论综合分数,pol是用户评论文本的情感极性,包括积极的情感、消极的情感和中性的情感,
是用户对商品的评论分数,n是同一个商品的评论总个数。得到商品评论综合分数后,我们将
转化为与
同维度的矩阵
,再把
加入到每跳波纹集中。
在上一步得到相关概率后,取对应相关概率加权的
中尾部的总和,得到向量
,如公式(14)所示:
(14)
其中
是尾部
的嵌入。向量
可以理解为用户u的点击历史
相对于项目v的一阶响应。通过公式(4)和(13)中的运算,用户的兴趣沿着
中的连接从其历史集
转移到其一跳相关实体
的集合。
在公式(14)中用向量
替代向量
,可以实现重复该过程以获得用户u的二阶响应向量
,对于更高阶波纹集兴趣
可以通过重复上述操作来得到。而用户u的向量是通过将各阶波纹集上兴趣的累加。
(15)
3.4. 预测层
最后我们将获得的用户嵌入
和项目嵌入
进行结合来输出预测的点击概率
:
(16)
其中
是sigmoid函数。
4. 实验应用分析
4.1. 实验数据集
在两个数据集:Clothing和Cell_Phones上分析我们的模型,两个数据集来自于Amazon 5-core的Clothing Shoes and Jewelry和Cell Phones and Accessories两个产品类别。每个数据集包含评论、产品元数据和链接。评论数据由用户项目评分和相应的评论文本组成。产品元数据包括类别和品牌。链接数据包括一起浏览/一起购买。为了构建知识图谱,我们从Clothing和Cell_phones数据集中抽取了其出现的所有商品及相关属性,将每个数据集的商品和它们的属性值映射链接到相应的实体,每个数据集的项目属性和用户的行为属性视为关系来构建三元组。例如(1182702295, categories, Accessories)其中1182702295是商品ID。总体而言,用户、物品和其他实体的交互非常稀疏,对于数据集,我们随机抽取每个用户交互的60%作为训练集,20%为验证集其余20%作为测试集。数据集的统计数据汇总如表1所示。

Table 1. Statistics of the data set
表1. 数据集的统计
Amazon数据集并不包含我们所需的评论情感极性,针对此问题我们使用现有的BERT [15] 模型来对评论进行训练、测试。我们发现评论集中含有一些只有分数而没有评论问题的数据,所以首先将评论中含有空白评论文本进行处理。再从两个数据集中分别挑选出一万条数据人工标注情感极性作为训练数据,最后将剩余所有数据作为测试数据。将所有数据送入模型训练、测试得到所有评论的情感极性,部分评论如表2所示:
Table 2. Examples of comment data sets
表2. 评论数据集实例
我们将评论情感划分为3类情感等级,分别是Negative、Positive、Neutral。这3类情感词语的情感等级和对应的情感极性如表3所示:
4.2. 实验参数设置
在我们的模型中,Clothing和Cell_phone的跳数H都设为2,根据实验结果,更多的跳数几乎不会提高性能,而且会导致更重的计算开销。完整的超参数设置在表4中给出,其中d表示实体和知识图谱的嵌入维度,表示学习率,表示知识图谱嵌入权重,是l2正则化的权重。超参数是通过在验证集上优化 Precision来确定的。
Table 4. Data set hyperparameter settings
表4. 数据集超参数设置
4.3. 评价指标
为了评估模型的推荐性能,我们采用精确率(Precision),召回率(Recall),归一化折损累计增益(NDCG)和命中率(HR)作为评价指标。这四个指标得分越高,推荐性能越好。在最优推荐集中(Top-K),使用训练好的模型为测试集中的每个用户在测试集商品中,筛选预测概率最高的前10个候选商品作为推荐结果。
精确率是在推荐列表中用户交互的项目占用户推荐列表项目的比例,而召回率是在推荐列表中用户交互的项目占测试集中用户交互的项目的比例,精确率和召回率计算公式如下。
(17)
(18)
其中
是为用户
生成的推荐列表;
是用户在测试集中交互的项目列表。
NDCG是通过项目在列表中的位置来评价排序性能,计算公式为:
(19)
其中
代表项目i这个位置上的概率。IDCG是理想情况下最大的DCG值。
(20)
其中
表示结果按概率从小到大的顺序排列,然后取前N个结果组成的集合。在top-K推荐中,HR是一种常用的衡量召回率的指标,计算公式为:
(21)
其中分母是所有的测试集合,分子表示每个用户推荐列表中属于测试集合个数的总和。
4.4. 对比方法
本文方法和以下方法在Clothing和Cell_Phones两个数据集进行了对比:
BPR [16]:Bayesian Personalized Ranking (BPR)是基于用户的隐式反馈,为用户提供物品的推荐,并且是直接对排序进行优化。贝叶斯个性化排序(Bayesian personalized ranking, BPR)是一种Pairwise方法,并且借鉴了矩阵分解的思路。
RippleNet:本文方法所依据的框架,这是一种类似记忆网络的方法在知识图谱上传播用户的偏好推荐。
DKN [17]:Deep Knowledge-aware Network (DKN)是基于内容的深度推荐框架,用于点击率预测。DKN的关键部分是一个多通道和单词–实体对齐的知识感知卷积神经网络(KCNN),它融合了新闻的语义层面和知识层面的表示。KCNN将单词和实体视为多个通道,并在卷积过程中显式地保持它们之间的对齐关系。此外,为了解决用户不同兴趣的问题,作者还在DKN中设计了一个注意力模块,以便动态地聚合当前候选对象的用户历史记录。
RuleRec [18]:RuleRec提出了一种新的、有效的联合优化框架,用于从包含商品的知识图谱中归纳出规则,并基于归纳出的规则进行推荐。该框架由两个模块组成:规则学习模块和推荐模块。规则学习模块能够在具有不同类型商品关联的知识图谱中导出有用的规则,推荐模块将这些规则引入到推荐模型中以获得更好的性能。
4.5. 实验结果对比与分析
为了验证提出方法的有效性,本节设置进行了三个实验:1) 将我们提出的方法和几种推荐算法进行对比;2) 设置多跳跳数参数实验,分析不同跳数对实验结果的影响;3) 设置波纹集数量参数实验,分析对于模型所提出参数设置不同对模型性能的影响。
1) 推荐性能
Sentiment-RippleNet-Att和基线模型在最优推荐集(Top-K)中的性能表现如表5所示:
Table 5. The recommended performance of the baseline and our model in the top-10, bold is the best performance of the baseline
表5. 基线和我们的模型在top-10的推荐性能,加粗是最佳性能
实验结果分析和讨论如下:从表5中可以观察到我们的模型在两个数据集上关于top-10的指标大部分都优于基线。其中Sentiment-RippleNet是没有融入注意力机制的模型,这表明了我们提出的融入注意力机制的算法能进一步的优化用户向量的表示,为用户提供更加精准的top-K推荐,能够有效的解决在构建用户偏好时三元组头尾实体不相关的问题,这也证明了我们模型的有效性。但从表5中也可以看出在Cell_phone数据集中Recall指标并没有超过最优基线,分析原因可能在于不同模型中对于知识图谱的处理方式不同而导致Cell_phones数据集中Recall指标没有提升,这意味着知识图谱这一辅助信息对于推荐系统的推荐效果十分重要。
2) 跳数实验
我们设置不同跳数进行了实验,实验结果如表6所示。
Table 6. Accuracy results of hop number
表6. 跳数准确率结果
从表6中我们可以观察到该实验结果在跳数取2时获得最高的准确率,而且数据集的准确度会随着跳数的增加先升后降,这是因为一跳路径所包含的语义信息较少,而多跳路径就很难探索长距离的实体间相关性和依赖性,会为探索用户偏好带来更多噪声,因此本文选择多跳路径的长度为2。
3) 波纹集数量实验
我们改变用户每一跳波纹集的数量,以进一步对模型进行实验验证。两个数据集上准确率结果如表7所示。
Table 7. Accuracy results of the number of ripple sets
表7. 波纹集数量准确率结果
从表7中可以看出波纹集数量对于实验结果的影响,两个数据集对于波纹集大小的结果基本是一致的,随着波纹集的增大,数据集的准确率先升后降,Clothing数据集在64准确率达到最高值,Cell_phone则在32达到最大值,这是因为更大的波纹集可以编码更多来自知识图谱的知识,但当波纹集过大时会带来噪声,从而出现先升后降的效果。
4.6. 可解释性
可解释性推荐不仅为用户做出推荐,为用户做出推荐解释同样重要,下面给出一个直观的例子来感受一下此方法的可解释性,如图2所示。
图2中,带有颜色的椭圆框为商品实体,其它是品牌、类别实体。本文随机选取一位用户的三个交互记录,并在测试集中选取一个标签为1的候选商品,此处选择的候选商品为B003X6LPRK。对于每个用户的k-hop相关实体,我们计算该实体与候选商品或其k阶响应之间的关联概率,如图2中连线的分数所示。为了更清楚的表达我们省略了关系的表示,从图2中我们观察到候选商品和用户相关商品通过不同实体链接起来,候选商品的推荐理由是:从用户记录中发现,用户兴趣分布于商品120401325X、B00CJFXXEE和B00A6KELHM,而这些实体与商品B003X6LPRK高度关联。另外,我们的模型从用户到候选商品构建了大量链接,知识图谱中的几个实体也得到了用户的多次关注,这些可以作为用户未来的潜在兴趣。
5. 结论
本文通过研究发现通过知识图谱中的关系来探索用户偏好时会存在与用户交互记录有不相关实体的问题,因此本文提出了一种基于知识图谱融入注意力机制商品推荐的可解释性方法。该算法通过知识图谱在构建出用户潜在偏好时,通过将知识图谱融合注意力机制来嵌入实体更为相关的近邻实体的语义信息,更新后的实体嵌入中能包含更多信息,然后通过用户偏好和获取的实体嵌入构建用户向量,最后通过用户向量、项目向量以及评论情感和评分相结合得到推荐项目并给出推荐项目的解释。最后在Amazon 5-core的Clothing Shoes and Jewelry和Cell Phones and Accessories两个数据集中通过实验证明了实验的有效性。在未来我们将更进一步挖掘出知识图谱之间的高阶关系,进一步改进模型,提高模型的能力。