1. 引言
随着信息技术的快速发展和信息基础设施的大规模建设,信息资源已经成为国家重要的战略储备资源,是经济建设和社会发展不可或缺的基础性条件。网络与信息安全问题日益突出,信息安全保障工作正面临着巨大的困难和挑战 [1]。为了提前发现和预防安全风险,网络安全防护的理念逐渐由被动防御转变为主动防御,漏洞检测的技术逐渐被广泛应用。漏洞检测主要通过模拟入侵者的攻击方法,批量扫描目标资产的脆弱性。越来越多的信息化管理者希望通过主动的安全隐患检测,提前发现和解决问题,实现防患于未然的目的。但是随着信息化资产的快速增长,对于漏洞主动发现的及时性、有效性的要求也越来越严格,漏洞检测技术的瓶颈也逐渐出现。为了提升漏洞检测的时效性和准确率,与当前迫切的安全需求相匹配,本文针对漏洞检测技术展开了深入的研究。
国内外已有很多专家开展了对于漏洞检测的技术研究工作,奥地利的Jovanovic,Kruegel,Kird开创性的提出了静态源代码分析法,通过此方法研究数据流,确认污点数据是否得到完善处理,同时推出服务侧源码静态分析工具PiXy [2] [3];Stefan Kals,EnginKirda等人根据渗透测试推出了自动Web应用安全检测工具SecuBat [4],主要包含网络爬虫、渗透测试、漏洞分析、测试样本库,对于现代漏扫工具的发展起到了深远影响;法国Renaud Derasion在其基础之上进行了优化改进,研发了C/S架构的Nessus [5] 系统,为了满足漏洞库升级的需求,采用了插件技术,维护过程非常简单;付堂欢 [6] 基于动态交互点和网址在页面中的分布规律设计与实现了漏洞扫描器的表单爬虫,利用预设的阈值和窗口,优先爬取在包含新URL较多的页面下发现的URL;黄从韬 [7] 针对漏洞发掘技术和利用的方法不断变换的特点,设计并实现了一种基于规则和插件的可扩展的漏洞检测方法。以上研究为现代漏洞扫描技术的发展提供了参考性和可行性依据。
目前存在的漏洞扫描器依然存在一些不足。例如随着漏洞扫描时间的变长,Nessus系统负载越来越大,用户在进行扫描配置和等待扫描结束需要的时间较长;AWVS、WebInspect、AppScan这些漏洞扫描器均采用单机部署,其扫描效率取决于所部署服务器的性能;部分系统漏洞检测范围较小,漏洞库不能进行有效扩充,当新漏洞产生,不能准确识别。我国针对漏洞检测技术的研究工作不够深入,没有很完善的高性能检测系统,很多安全从业人员依然使用国外的检测引擎。因此,继续深入研究漏洞检测技术,设计一种高效、准确、全面、易用的漏洞检测引擎十分迫切和必要。
本文针对漏洞产生的原理和检测方法进行研究,设计并实现一种综合资产信息探测技术、网络爬虫技术、漏洞检测技术和分布式技术的漏洞检测引擎。通过资产信息探测为漏洞检测提供更全面的信息支持,提高漏洞检测的准确率;通过宽度优先遍历策略和布隆过滤器算法提高爬取目标交互点的精准度;通过分布式引擎架构提高漏洞检测的速率和稳定性。测试结果表明,本文设计与实现的引擎具有更高的漏洞检测准确率和扫描速率。
2. 分布式引擎的设计
2.1. 分布式技术
Celery是一个简单、灵活、可靠的分布式队列,是分布式技术实现的基础,一般借助它进行任务的调度。当任务执行失败或者在任务执行过程中连接超时,它会自动发起连接,并重新执行任务 [8]。
Celery主要包含以下几个组件:
1) Beat (任务调度器):任务调度器会读取配置文件的内容,并向任务队列发送即将到期的任务。
2) Producer (任务生产者):任务生产者主要负责生成具体的任务,并发送到任务队列中。
3) Broker (消息中间件):消息中间件存储任务生产者产生的任务,并下发给任务执行者。
4) Worker (任务执行者):执行任务的消费者,通常在多个服务器上运行多个消费者,以提高执行的效率。
5) Backend (任务结果存储):将状态信息和结果保存,供任务结束后查询。
任务生产者周期性地将任务发往消息中间件,任务执行者负责从消息中间件中获取任务,任务执行者执行完任务后将结果保存在任务结果存储中。Celery架构如图1所示。

Figure 2. Distributed architecture diagram
图2. 分布式架构图
2.2. 分布式引擎架构的设计
本文设计了分布式引擎,由中央节点和多个任务节点构成,采用可以进行全局控制多节点并行的主从式分布架构,中央节点对整个引擎的进行功能统筹与实时控制,进行整体的资源调度和扫描任务下发,并且对任务节点的worker进行数据监管,通过这种方式可以把控各任务节点的工作进展。任务节点主要负责网络爬虫、信息收集和漏洞检测三方面工作。其整体架构如图2所示。
2.3. 分布式引擎中央节点的设计
在主从式分布架构中,整个引擎的监管工作由中央节点执行,用户可以在中央节点配置扫描目标,中央节点向不同的任务节点发布检测任务,监管扫描状况,收集扫描数据。中央节点的各模块主要包括:前端交互模块、任务分配模块、消息监控模块、数据管理模块。中央节点的各功能模块及作用如表1所示。

Table 1. Function modules of the central node
表1. 中央节点各功能模块
2.4. 分布式引擎任务节点的设计
任务节点的功能模块包括:网络爬虫模块、信息探测模块和漏洞检测模块。任务节点的各个模块功能如表2所示。
Table 2. Function modules of the task node
表2. 任务节点各功能模块
2.5. 分布式引擎工作流程
分布式引擎的前后端为B/S结构,首先用户访问浏览器端,向中央节点下达检测任务并进行检测任务与检测规则配置。中央节点服务器在获取到分配好的检测任务后,将检测任务划分为不同的子任务,并将子任务根据规则存入检测任务队列中,激活任务节点中的worker。任务节点worker开启对目标的检测。在所有子任务检测完成后,将检测结果数据反馈到中央节点。中央节点负责收集与处理各任务节点的结果数据。分布式引擎的工作流程如图3所示。
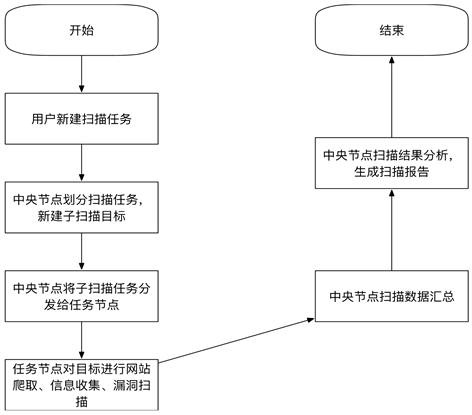
Figure 3. Workflow of a distributed engine
图3. 分布式引擎的工作流程
3. 分布式引擎的实现
3.1. 分布式中央节点的实现
3.1.1. 任务分配模块的实现
在分布式引擎中,中央节点向每个任务节点的worker分配检测任务,到任务节点把检测任务执行完成并将检测数据反馈,整个检测过程包含了四部分:
1) 用户在中央节点进行检测任务下发并将主任务划分为子任务,然后根据子任务的检测级别分配到引擎的消息代理中。
2) 消息代理在接收到检测任务后,将不同的子任务分别压入不同的任务队列中。
3) 任务队列根据任务节点的运行情况,将任务分配给不同的任务节点的worker,避免超出某一节点的性能负荷。
4) worker在收到下发完成的任务后开始检测,在检测完成后将检测数据传输到任务结果存储中。
使用Redis数据库作为消息中间件,任务结果存储使用MySQL数据库,如图4和图5所示。

Figure 4. Configure message-oriented middleware
图4. 配置消息中间件
Figure 5. Configure task result storage
图5. 配置任务结果存储
通过任务下发接口下发检测任务,任务队列根据各个任务节点服务器的性能进行最终的任务分配,如图6所示。

Figure 6. Assignment of tasks to task queues
图6. 任务队列的任务分配
3.1.2. 消息监控模块的实现
当消息监控模块监控任务的执行情况时,分布式引擎通过任务优先级调度的方法将更多的节点资源分配给优先级更高的任务,并提高任务执行的效率。同时为了避免节点中的worker运行负荷过高,通过令牌桶算法 [9] 来进行任务调度。令牌桶算法是速率限制(Rate Limiting)中最常用的算法之一,如果令牌桶中存在令牌,则允许发送流量,任务节点中的worker接收并执行任务;而如果令牌桶中不存在令牌,则不允许发送流量,任务节点中的worker停止接收任务。
当消息监控模块对节点的运行情况进行监控时,不需要对部署任务节点的服务器进行资源监控,仅需要判断任务节点中的worker是否能够继续接收任务即可。如果任务节点中的worker能够正常完成各项检测任务,则说明任务节点负载正常,如果worker在执行任务过程中长时间无正常响应,则说明任务节点资源异常,此时将此worker承担的任务分配给其他正常worker。
3.2. 分布式任务节点的实现
3.2.1. 网络爬虫模块的实现
网络爬虫模块 [10] 主要包括解析模块和提取模块。解析模块负责爬取目标url,并构造http请求,接收与解析目标url反馈的响应包,判断目标url是否存活。提取模块负责从解析url之后的页面中提取交互点。
网络爬虫采用宽度优先遍历策略,在爬取过程中先完成对根结点的遍历,再依次对所有的直接子结点进行遍历,通过这种策略尽可能扩大资产的爬取范围。基于宽度优先遍历的网络爬虫的工作流程如图7所示:
1) 首先是获取初始url,将初始url放入待爬取列表,并且基于此url进行进一步的地址资源搜索;
2) 当在爬取过程中发现新的url时,将其放入待爬取列表;
3) 从待爬取列表中取出url并发送请求,通过响应的状态码判断url是否存活。若存活则继续对爬取的页面进行动态交互点提取;
4) 页面爬取完成后,将此url从待爬取列表中删除,然后取出新的url重复交互点的爬取,直至待爬取列表为空。
爬虫过程中需要对爬取的url进行去重,这里通过布隆过滤器算法 [11] 进行去重,定义了两个方法,一个负责向布隆过滤器添加元素,另一个负责判断元素是否位于布隆过滤器中,在调用布隆过滤器进行去重时,将Hash函数个数预先设定为3,将二进制数组的长度设置为10,000。添加元素和检查元素的核心代码如图8、图9所示。
3.2.2. 资产信息探测模块的实现
资产信息探测模块主要负责对目标进行信息收集,一方面为用户提供信息参考,另一方面当获取到新的动态交互点可以添加到待检测目标中,增加漏洞检测的准确率。该模块包含了多种信息收集子模块,例如可以针对一些可能包含敏感信息的文件进行扫描,针对目标地址开放的端口进行扫描,针对目标服务器响应包中的banner进行扫描以获取系统指纹信息等。其中包含的信息探测模块如图10所示。
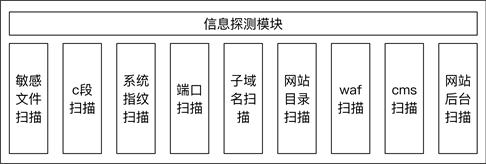
Figure 10. Structure of information detection module
图10. 信息探测模块的结构
1) 敏感文件扫描
敏感文件是指具有网站敏感信息的文件,例如网站源文件、网站备份文件、包含用户数据的文件等。在没有任何外部访问控制的情况下,一旦被攻击者获取,极易被利用,进一步开展对服务器的攻击。针对敏感文件的扫描,首先是构建敏感文件的后缀规则库,将后缀与检测目标的目录进行拼接,然后将构造的http请求发送给目标服务器,根据http响应的状态代码确定是否存在敏感文件。
2) c段扫描
c段扫描主要是为了检测处于同一c段的存活的主机,资产信息探测模块在接收到检测目标后,对c段中的每个目标发起主动连接,并监听是否有响应信息返回。若存在响应,则证明此ip存活,并将存活的ip录入到数据库中,继续对其他ip进行遍历,未返回响应则证明不存在活跃主机。
3) 系统指纹扫描
获取存活主机返回的指纹信息,从指纹信息中可以获取软件开发商,软件名称、版本、服务类型等信息。从这些信息中可以判断目标系统是否存在脆弱性,借助某些工具可以直接调用对应的exp进行攻击。
4) 端口扫描
端口扫描主要是为了发现目标服务器开放了哪些服务,该功能的实现主要是通过socket套接字进行探测,向目标服务器的端口不断发送请求建立连接的数据包。如果对方存在此服务则会应答,全端口的探测可以通过增加线程进行快速探测,资产较多的情况下通过分布式探测增加探测速度。
5) 子域名扫描
通过子域名扫描可以发现目标存在的其他服务,增加发现漏洞的可能性。首先构造子域名字典,对目标主域名进行字典爆破来发现可能存在的子域名。对爆破发现的子域名进行dns解析,如果可以解析为存活的真实ip,则说明目标存在该子域名,将发现的子域名保存到数据库中;如果解析不成功,则说明不存在,进行其他测试,直至字典爆破结束。
6) 网站目录扫描
网站目录扫描主要是为了发现更多有价值的信息,比如网站的管理后台、网站的配置信息、网站的源码备份等。网站目录扫描的工作流程为:首先,获取目标的初始url并将其存储在数据库中,然后在初始页面中寻找新的url,将获取的新url和数据库中的url进行比较,以确定它是否已存储,如果没有存储则将其录入数据库中,并对该url的页面进行爬取。爬取结束后,数据库中的url则为获取的网站目录。
7) waf扫描
目前大多数网站都会被waf防护,导致漏洞检测无法正常工作,进行waf扫描主要是为了判断目标是否被waf防护。如果被防护则根据返回的信息判断waf的类型,进行简单的绕过,保持漏洞检测引擎的正常工作。不同厂商的waf具备不同的特征,这些特征可能会在响应数据包的header头部信息中显示。进行扫描时,首先主动向目标发送请求,在获取的响应数据包中找出相应的字段并与已有的特征进行比对。本系统对网络中常见的waf进行了特征收集,尽可能判定目标的waf类型 [12]。
8) cms扫描
通过对cms的扫描可以发现目标正在使用的cms以及使用的版本,基于以上信息,可以通过检索当前版本cms已暴露出来的漏洞进行攻击利用。目前市面上使用的cms种类非常多,想要识别目标使用的cms版本,需要采集不同cms的特征进行比对。目前已收集了1400多种cms特征,主要通过识别MD5和正则表达式匹配的方式来判单判断目标的cms类型。cms的指纹如下所示:
{
url: /kindeditor/license.txt,
re: ,
name: T-Site建站系统,
md5: b0d181292c99cf9bb2ae9166dd3a0239
}
9) 网站后台扫描
对网站进行后台扫描,主要是为了发现网站开发后台,并进行版本漏洞利用。扫描模块中包含构造好的后台字典,然后将常见的后台访问链接与目标地址逐一拼接,根据能否正常访问来判断是否存在相应的网站后台。
3.2.3. 漏洞检测模块的实现
漏洞检测是引擎的核心功能,从结构上看,漏洞检测模块包括交互点提取、漏洞特征识别、漏洞扫描模块。同时为了更好的与任务节点配合,需要实时与节点通信模块保持通信。为了扩大漏洞检测的范围,增加漏洞检测的准确率,需要接收来自信息探测模块采集的相关信息。以上几个模块共同为引擎的漏洞检测功能服务,结构如图11所示。

Figure 11. Vulnerability detection module structure
图11. 漏洞检测模块结构
当进行漏洞检测时,首先用户下发检测任务,检测目标被漏洞检测模块获取,根据针对目标收集的基础信息,调用对应的漏洞检测插件,检测插件会向目标交互点发送请求,请求中的POC中包含攻击载荷。检测模块会监听目标的响应,它主要通过判断响应的信息来确定目标是否存在对应的漏洞。若存在则将漏洞信息存储到数据库中,不存在则结束当前检测,开始下一项漏洞的检测。漏洞扫描的流程如图12所示。
为了增强漏洞检测模块的扩展性,除了包含针对常见漏洞进行检测的模块,还有一个可以扩展的漏洞检测插件模块。本文对所有的漏洞检测插件进行规范化,所有扫描插件都有相同的编码标准 [13],使得检测引擎能够及时识别出现的新漏洞,编写格式如图13所示。
4. 测试结果及分析
4.1. 测试目标选取
鉴于网络安全法中明确禁止个人从事未经授权的漏洞探测和任何其他危害公共系统安全的行为,此次测试将个人搭建的三个网站作为测试目标。本次测试采用了对比测试的方法,进行测试的漏洞检测引擎包括常用的漏洞扫描工具AWVS、APPSCAN、WDScanner [14] 和本系统。其中AWVS、APPSCAN为目前白帽子使用的主流漏洞扫描器,WDScanner为ted团队开发的具有代表性的分布式扫描器,通过对比以上几款扫描器的检测结果,可以更直观的反映本系统的真实性能。
4.2. 测试环境搭建
检测引擎配置在5台虚拟机上,其中1台部署中央节点,其他4台部署任务节点,保持每台虚拟机的内存、cpu、硬盘等基础配置相同,其他检测引擎根据要求部署在同样配置的虚拟机中,虚拟机中的软件信息如表3所示。
Table 3. Environment configuration for a distributed engine
表3. 分布式引擎的环境配置
4.3. 性能测试
在检测引擎部署完成后,分别使用四种检测引擎对三个目标进行扫描,统计扫描的时间和发现的漏洞数量,对比四款引擎的漏洞检测效率。统计结果如表4所示。
Table 4. Comparison of test results
表4. 检测结果对比
1) 通过对比扫描的平均时间可以发现,本系统的扫描速度最快:
本系统 < WDScanner < APPSCAN < AWVS
2) 在发现的平均漏洞数量上,AWVS发现的漏洞数量最多,本系统第二:
AWVS > 本系统 > WDScanner > APPSCAN
3) 在查看漏洞信息发现,由于本系统的漏洞库不够完善,部分漏洞未检出,所以发现漏洞数量偏低。
为了统计以上几款检测引擎的漏洞检测准确率,对发现的漏洞进行手工验证,验证结果如表5所示:
1) 对比统计的平均误报数量,AWVS误报数量最少,APPSCAN误报数量最多,本系统的误报数量略高于AWVS。
AWVS < 本系统 < WDScanner < APPSCAN
2) 对比计算的平均准确率,AWVS准确率最高,本系统准确率第二位。
AWVS > 本系统 > WDScanner > APPSCAN
漏洞检测引擎不能保证将所有漏洞检出,存在漏报的情况,因此计算漏报率是衡量漏洞检测引擎性能的另一个重要指标。本文采取的方法是,将所有引擎检测的有效漏洞的并集作为漏洞检测的最终结果,经过比对发现本次检测发现的A、B、C三组的有效漏洞数分别为58、31、43个,统计的漏报情况如表6所示:
Table 6. Comparison of false alarm rate
表6. 漏报率对比
1) 对比统计的平均漏报数量,AWVS漏报数量最少,APPSCAN漏报数量最高,本系统漏报数量略高于AWVS。
AWVS < 本系统 < WDScanner < APPSCAN
2) 对比计算的平均漏报率,AWVS漏报率最低,本系统漏报率略高于AWVS。
AWVS < 本系统 < WDScanner < APPSCAN
结合以上数据分析得出如下结果:
1) AWVS检测的准确率最高,本系统次之,APPSCAN检测的准确率最低;
2) 本系统检测的速度最快,AWVS检测的速度最慢;
3) AWVS检测的漏报率最低,本系统次之,APPSCAN检测的漏报率最高。
从准确率、速率、漏报率三个指标综合分析发现:APPSCAN的综合性能最差,AWVS的综合性能比较突出,但是检测的时间太长,本系统的检测准确率和漏报率最接近AWVS,在检测速率上占据上风。
综上所述,与其他检测引擎相比,本系统可以快速准确的对目标进行漏洞检测,满足设计的要求与目的。
5. 结语
针对目前漏洞检测技术中存在的不足,基于前人研究的基础上,本文对漏洞检测相关技术进行了应用和改进,设计与实现了一种分布式资产信息探测与漏洞检测引擎。该分布式引擎通过宽度优先遍历策略提高了漏洞检测的全面性;通过布隆过滤器算法对爬虫获取的url进行去重,提高了漏洞检测的效率;通过资产信息探测辅助漏洞检测,提高了漏洞检测的准确率;通过分布式架构极大提高了漏洞检测的速率。该分布式引擎与其他三款漏洞扫描器相比,提高了漏洞检测的准确率和速率,可以很好地应用到实际生产环境中,为主动发现网络环境的安全隐患提供了有力保障。
致谢
向本文在完成过程中给予指导和帮助的老师以及给本文提出指导意见的评审专家表示感谢。
基金项目
本课题得到山东省自然科学基金项目(ZR2021MF092)资助。