1. 引言
在过去的几十年里,进化算法已经成为一种流行的优化工具。许多已有的进化算法都假设对候选解的评估代价是廉价的,然而,在现实世界中,许多优化问题很难找到合适的评估函数或评估代价十分昂贵。比如,基于大量数据的创伤系统的一次函数评估需要处理40,000条事件记录 [1]。为了降低进化算法中函数评估阶段的昂贵代价,研究者进行了许多探索,数据驱动的进化优化便是研究出的一种非常有效的解决方法。数据驱动的进化优化通过收集现实生活或者仿真实验的数据训练代理模型,然后使用代理模型近似代替全部或部分函数评估,从而大大减少真实昂贵函数评估的代价。在数据驱动的进化算法中已使用的代理模型有多项式回归 [2]、克里金模型 [3]、人工神经网络 [4] 和径向基函数 [5] 等。根据优化过程中是否可以使用新生成的数据,将数据驱动的进化优化分为离线数据驱动的进化优化和在线数据驱动的进化优化。目前,已经有许多研究者提出一些数据驱动的进化算法,比如TT-DDEA [6]、SRK-DDEA [7]、KRVEA [3]、CSEA [8] 等。数据驱动是随着人工智能、机器学习兴起的一门技术,近几年也有其他学者对数据驱动的优化算法作出研究进展,比如F Yu等 [9] 提出了一种针对昂贵优化问题的基于多进化采样策略的数据驱动进化算法,Ashley M. Hou等 [10] 提出了一种机会约束优化的数据驱动调整算法:概率性能保证的两个步骤,Q Gu等 [11] 提出了一种基于双档案的数据驱动混合整数优化改进辅助进化算法。本文基于一种在线数据驱动的进化算法KTA2 [12] 作出改进,提出了一种改进克里金模型辅助的双档案在线数据驱动进化算法KTA2_addModel4。
2. KTA2算法
KTA2算法 [12] 是根据数据驱动进化算法的一般框架,选择克里金模型 [3] 训练代理模型,并结合双档案算法设计的在线数据驱动进化算法。
2.1. 代理模型的训练
在KTA2算法中,为了提升代理模型的质量,重点研究对模型质量影响较大的数据。在 [12] 中,考虑目标值较大或较小的影响点,通过设置参数控制影响点的数量,然后分别训练包含所有影响点和去除目标值较大的影响点以及去除目标值较小的影响点的模型。如图1所示,图1(a)图是由全部数据训练得到敏感模型,图1(b)图是由去除目标值较大的影响点后的数据集训练得到不敏感模型1,图1(c)图是由去除较小影响点后的数据集训练得到不敏感模型2。
2.2. 代理模型的使用
在KTA2算法中,一共训练了三种模型用作代理模型:所有数据集训练得到的敏感模型;按比例去掉部分最大目标值的数据集1训练得到的不敏感模型1;按比例去掉部分最小目标值的数据集2训练得到的不敏感模型2。在使用代理模型近似真实昂贵函数评估,即进行预测时,首先由敏感模型预测得到预测值
,然后比较
与数据集1目标值均值λ的差值
、
与数据集2目标值均值μ的差值
的大小,选择由不敏感模型1或者不敏感模型2得到最终预测值,如图2所示。
2.3. 代理模型的更新
在KTA2算法中,代理模型的更新是根据收敛性、多样性指标完成采样的。通过判断此时是收敛性需要阶段、多样性需要阶段或不确定性需要阶段,分别采用收敛性采样策略选择收敛性好的解提升种群的质量,采用多样性采样策略选择多样性好的解使种群更均匀地分布在Pareto前沿面上,采用不确定性采样策略选择不确定性解提升代理模型的全局精确度,详见 [12]。
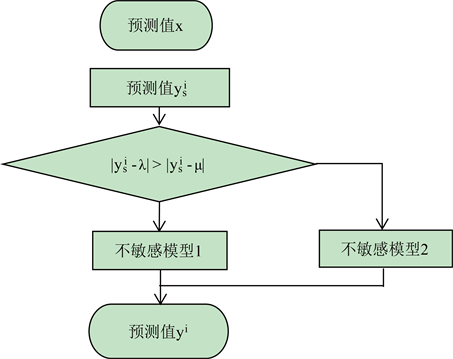
Figure 2. Model usage of KTA2 algorithm
图2. KTA2算法的模型使用
3. 改进的KTA2算法——KTA2_addModel4算法
本文基于Song [12] 等人提出的KTA2算法,对代理模型的训练作出改进,针对每个目标,由原来的三种模型近似真实函数评估改进为四种模型近似真实函数评估,提出了改进的KTA2算法——KTA2_addModel4算法,KTA2算法与KTA2_addModel4算法都是求解评估代价昂贵的多目标优化问题的在线数据驱动进化算法。
图3是KTA2_addModel4算法框架。与KTA2算法相同,KTA2_addModel4算法依然使用双档案保持种群的收敛性和多样性。其中,CA代表收敛性档案,DA代表多样性档案。与KTA2算法针对每个目标训练三种克里金模型 [3] 作为代理模型不同,KTA2_addModel4算法针对每个目标训练了四种克里金模型作为代理模型:由全部个体训练的敏感模型、去掉较大影响点训练的不敏感模型1、去掉较小影响点训练的不敏感模型2、同时去掉较小与较大影响点训练的不敏感模型3。由代理模型近似真实函数评估,得到适应度值。在管理代理模型时,与KTA2算法相同,通过自适应采样策略更新训练集,实现代理模型的更新。
3.1. 改进的代理模型
在原来KTA2算法中,代理模型包括由全部数据训练得到的敏感模型、去掉部分较大目标值的数据集训练得到的不敏感模型1和去掉部分较小目标值的数据集训练得到的不敏感模型2。在本文中,所有去掉的个体都称为影响点。将除去的目标值较大的个体称为较大影响点,将除去的目标值较小的个体称为较小影响点。在KTA2算法中,之所以训练去掉这些影响点后的模型,是考虑到这些影响点对代理模型质量的影响。因为在KTA2算法中,代理模型的作用是近似真实昂贵函数评估,所以在使用代理模型预测适应度值时,通常会有一定的近似误差。而这些影响点的存在,可能会降低代理模型的质量,产生较大的近似误差。
在改进的KTA2算法——KTA2_addModel4算法中,对代理模型作出改进,增加了第四种模型——同时去掉部分较大目标值和部分较小目标值的数据集训练得到的不敏感模型3。即在KTA2_addModel4算法中,增加训练了一种同时考虑较大影响点和较小影响点的模型。考虑影响点对代理模型的影响,可能降低训练得到的代理模型的质量,从而可能产生较大的近似误差。与传统只使用一个代理模型的数据驱动的进化算法对比,使用多个代理模型的数据驱动的进化算法的好处在于:
1) 由多个代理模型共同完成近似真实昂贵函数评估任务,可以综合各个代理模型的作用,提升预测准确率;
2) 等同于将一个代理模型细分、精确化,可以兼顾不同候选解适应度值的预测准确率。
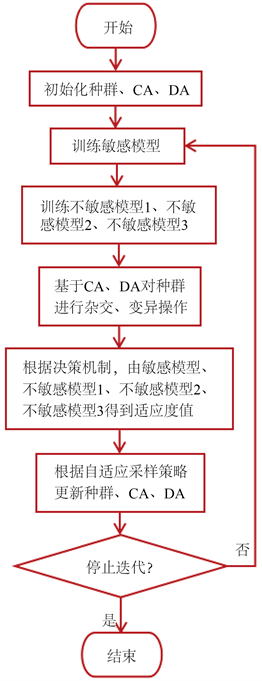
Figure 3. Flowchart of KTA2_addModel4 algorithm
图3. KTA2_addModel4算法流程图
在KTA2_addModel4算法中,种群中的个体具有多个目标,针对每个目标,训练四种克里金模型作为代理模型:包含所有影响点训练的敏感模型、除去较大影响点训练的不敏感模型1、除去较小影响点训练的不敏感模型2、同时除去较大和较小影响点训练的不敏感模型3。如图4,由于代理模型的训练针对每个目标,KTA2_addModel4算法中改进的代理模型描述如下:
设种群规模为N,种群中的个体有m个目标,对每个目标的所有目标值进行升序排序,则根据每个目标,得到种群的升序排列。设置控制影响点数量的参数τ,τ表示取种群中训练数据的比例。针对每个目标,训练敏感模型时,取N个训练数据作为训练集;训练不敏感模型1时,取前τ * N个训练数据作为训练集;训练不敏感模型2时,取后τ * N个训练数据作为训练集;训练不敏感模型3时,取中间(1 − (1 − τ) * 2) * N即去掉前(1 − τ) * N和后(1 − τ) * N个训练数据作为训练集。
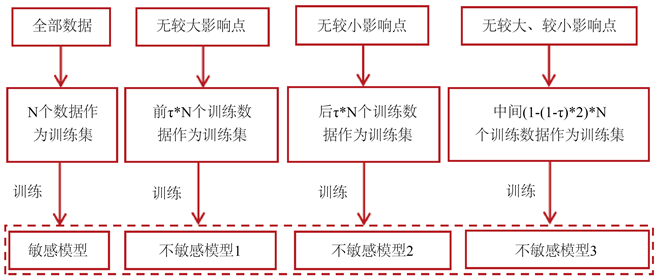
Figure 4. Agent model of KTA2_addModel4 algorithm
图4. KTA2_addModel4算法的代理模型
3.2. 改进代理模型的使用
在KTA2算法中,通过某种决策机制,使用敏感模型、不敏感模型1、不敏感模型2得到候选解的适应度值。在KTA2_addModel4算法中,由于增加了不敏感模型3,因此代理模型的使用也要发生改变。但是,代理模型的使用原理,即决策机制未作出改变。KTA2_addModel4中代理模型的使用如下:
设种群规模为N,目标个数为m。首先由敏感模型预测得到预测值
,然后分别计算训练不敏感模型1、不敏感模型2、不敏感模型3的训练数据集的均值λ、μ、σ,最后比较
与λ、μ、σ差值的绝对值,根据最小值选择对应的模型作为最终选择的预测模型,如图5所示。
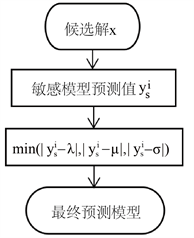
Figure 5. Use of KTA2_addModel4 algorithm agent model
图5. KTA2_addModel4算法代理模型的使用
3.3. 改进代理模型的更新
在KTA2_addModel4算法中,由于增加了不敏感模型3,所以代理模型的更新也要作出相应的调整。但是,代理模型的更新策略与KTA2算法中更新策略相同。如KTA2_addModel4算法流程图图3所示,如果没有满足停止条件,更新后的种群进入新一轮迭代,然后会按照3.1节的图4所示,从新一代种群中,得到全部数据集、无较大影响点的数据集、无较小影响点的数据集和无较大、较小影响点的数据集,依次更新敏感模型、不敏感模型1、不敏感模型2和不敏感模型3。
4. 实验结果及分析
为了验证改进的KTA2算法——KTA2_addModel4算法的性能,本节首先将KTA2_addModel4算法与KTA2算法在11个测试函数CDTLZ2、DTLZ1、IDTLZ1、IDTLZ2、SDTLZ1、SDTLZ2、WFG1、WFG3、WFG5、WFG7、WFG9上作对比,然后再将KTA2_addModel4算法与4个代理模型辅助的昂贵多目标进化算法ABSAEA算法、CSEA算法、KRVEA算法、MOEADEGO算法在这11个测试函数上作对比。本文所有测试函数及对比算法参数均设置为默认值,KTA2_addModel4算法参数设置与KTA2算法默认值一致。CDTLZ2、DTLZ1、IDTLZ1、IDTLZ2、SDTLZ1、SDTLZ2、WFG1、WFG3、WFG5、WFG7、WFG9均为3目标测试函数。种群规模均设置为100,最大函数评估次数maxFE均设置为300。
本文实验选取反转世代距离IGD [13] (Inverted Generational Distance, IGD)作为评价指标,IGD由真实Pareto前沿 [13] 中的个体到实验所求得的Pareto解集的平均距离表示,反映算法求得的Pareto解集逼近真实Pareto前沿的情况。算法求得的Pareto解集越逼近真实Pareto前沿说明算法的性能越好,即IGD值越小算法的性能越好。
4.1. 与KTA2算法对比
本节使用IGD作为算法的性能评价指标,表1是KTA2_addModel4算法与KTA2算法在CDTLZ2、DTLZ1、IDTLZ1、IDTLZ2、SDTLZ1、SDTLZ2、WFG1、WFG3、WFG5、WFG7、WFG9测试函数上的IGD性能对比结果。为了保证算法的真实性和公平性,在每个测试函数上,每个算法独立运行30次。表中每个算法在每个测试函数上的IGD结果数据有两个,第一个是算法独立运行30次后的IGD平均值,第二个是IGD标准差值。每个测试函数上的性能最优算法加粗表示。从表1中可以看出,KTA2_addModel4算法在11个测试函数上与KTA2算法对比,在CDTLZ2、DTLZ1、IDTLZ2、SDTLZ1、WFG1、WFG3、WFG7这7个测试函数上的IGD均值都比较小。在IGD均值更小的这7个测试函数上,IGD标准差值只有在WFG1和WFG3两个测试函数上稍微大于KTA2算法,在其他5个测试函数的IGD标准差值均小于KTA2算法。总体来看,KTA2_addModel4算法在11个测试函数中,在7个测试函数上性能优于KTA2算法。

Table 1. Comparison between KTA2_addModel4 algorithm and KTA2 algorithm
表1. KTA2_addModel4算法与KTA2算法对比
4.2. 与其他算法对比
本节仍使用IGD作为算法的性能评价指标,将KTA2_addModel4算法与ABSAEA、CSEA、KRVEA、MOEADEGO四个代理模型辅助的昂贵多目标进化算法在CDTLZ2、DTLZ1、IDTLZ1、IDTLZ2、SDTLZ1、SDTLZ2、WFG1、WFG3、WFG5、WFG7、WFG9测试函数上作对比。表2是KTA2_addModel4算法与ABSAEA、CSEA、KRVEA、MOEADEGO四个算法的IGD性能对比结果。为了保证实验结果的可靠性,在每个测试函数上,每个算法独立运行30次。表中每个算法在每个测试函数上的IGD结果数据有两个,括号外的是算法独立运行30次后的IGD均值,括号内的是IGD标准差值。性能更好的IGD值加粗表示。如表2所示,KTA2_addModel4算法在9个测试函数CDTLZ2、DTLZ1、IDTLZ1、SDTLZ1、SDTLZ2、WFG3、WFG5、WFG7、WFG9上的IGD均值都最小,虽然有少数几个IGD标准差值大于其他算法,但是相差很小。因此,KTA2_addModel4算法在这9个测试函数上的性能基本优于其他对比算法。
Table 2. Comparison between KTA2_addModel4 algorithm and other algorithms
表2. KTA2_addModel4算法与其他算法对比
5. 总结与展望
数据驱动的进化优化算法是近年来研究者针对昂贵进化优化问题提出的一种有效的解决方法。本文对在线数据驱动的进化优化算法KTA2进行改进,通过研究提升代理模型的质量以提升算法的性能。本文对代理模型作出的改进在一些测试问题上取得较好的效果,但是在其他测试问题上的性能仍有待提升。由于增加了不敏感模型3,降低敏感点对模型质量影响的同时,也增加了模型预测的不准确性,关于如何进一步解决这一问题,使其在更多测试问题上取得优良效果,仍有待研究。