1. 引言
河流、湖泊的水质是一个复杂的过程,其与污染源强、时间、空间、人类活动、产业布局、经济发展等因素之间有很强的依赖性和相关性。水质模型的运用就是要在大数据时代结合爆炸式的信息与严谨的科学规律,做到最精细的决策,从而实现经济与环境的平衡。在当今社会,流域环境管理以及水环境防治对于水质模型的需求越来越强烈,然而现阶段较为常见的水质模型如Mike,SWAT等需要构建复杂的输入系统,这大大限制了水质模型在环境管理中的运用和推广,也增加了模型的不确定性和校验难度。同时,由于模型体量太过于庞大,这些模型往往消耗过久的模拟时间,限制了这些模型在较大流域中的运用。根据Ingrid Keupers等人的研究 [1],在PC端利用MIKE11-ECOLab来模拟不到400 km2的汇流区域时耗时约4天。河网水动力模型是水质模型的基础 [2],河网二叉树的编码方式早已在大尺度流域中有所运用 [3] [4]。付立冬基于WebGIS技术采用一维水质模型实现了蒲河流域基于河流流域的容量总量计算及排污许可分配 [5],卢诚等人基于EFDC模型建立了十堰市神定河的水动力水质模型 [6],两种水质模型的实现方式对于单一河道的水质模拟具有较好的模拟效果,但这两种方法仅适用于单一河道,对于复杂河网并不适用。薛野基于三级解法的分级解法建立了河网一维水动力模型 [7],能够较好地模拟复杂河网的水质,但该模型仅考虑了单一污染源的输入,并未考虑大流域范围内不同污染源的输入过程。为了提高模型模拟的效率,同时减小模型的复杂程度,我们基于水质一维模型构架了更简便快捷的大流域水质模型。
2. 研究方法
河网水质模拟模型的构建以一维水质模型为基础,分为河网拓朴构建、污染源拓扑关系构建、污染源强核算、河网流量初始化以及模拟运算几个步骤,模型构建的原理如图1所示。1) 河网拓扑构建以GIS水文分析为基础,设置一定的阈值后定义并提取河网。李铁键等人提出了一种基于二叉树理论并以二元形式表示的河网编码方法 [8],本文河网拓扑网络的构建与该方法相似,不同之处在于本文所构建拓扑网络除了河网本身还包括与河道关联的污染源的拓扑结构。2) 污染源拓扑关系构建以构建好的河网拓扑以及污染源位置为基础,计算出距离污染源最近计算单元后在该计算单元处设置概念化的“排污口”。面源污染对水质的影响很突出 [9] [10],不同于经济发达地区面源污染通过雨水排口进入水体,云南地形起伏大、管网设施不完善,大部分面源污染无固定排口。为凸显面源污染的影响,除了常规点源污染源,城镇生活源、农村生活源等污染源以所在城镇或乡村为源强概化为点源,农田径流以地块质心概化为点源。3) 污染源强的核算分为点源和面源,点源污染源强数据获取途径较多,面源污染源强与人类活动、降雨情势、下垫面类型之间有着直接的相关性。径流曲线数模型(SCS-CN模型) [11] 和长期水文影响评价模型(L-THIA模型) [12] 是连接降雨、人类活动和下垫面类型的关键。4) 通常在水质模型的运用过程中,支流河道通过概化的形式简化计算流程,河道流量的赋值只能逐段进行或者求解圣维南微分方程 [13] [14],这样的实现方式并不利于在大流域水质模拟中运用。河网流量初始化以GIS汇流分析所得各栅格累计流量以及流域实际出流点流量为基础分配。图遍历是求解拓扑网络常用的手段,通常包括深度优先算法和广度优先算法 [15] [16]。广度优先算法指的是从图的一个未遍历的节点出发逐层遍历相邻节点,遵从先进先出的原则通常采用队列的形式实现;深度优先算法从图的一个未遍历节点出发,沿着某个分支遍历到叶子后再遍历另一分支,深度优先算法遵从先进后出的原则,通常通过栈的形式实现。本文对河网的遍历采用深度优先算法中的中序遍历形式实现。模拟运算过程以河网拓扑构建、污染源拓扑构建、河网流量初始化三个准备工作的结果为输入,以中序遍历的方式实现河网水质的模拟运算。

Figure 1. Schematic diagram of model construction principle
图1. 模型构建原理示意图
2.1. 一维水质模型
在忽略离散作用时,描述河流污染物一维稳态衰减规律的微分方程为:
(2-1)
将
代入,得到
(2-2)
积分解得
(2-3)
式中:u——河流断面平均流速,m/s;
x——沿程距离,m;
K——综合降解系数,1/d;
C——沿程污染物浓度,mg/L;
C0——前一个节点后污染物浓度,mg/L。
2.2. 河网拓扑构建
河网拓扑可以利用数字高程模型(DEM)数据提取,并以一定的编码方式形成计算机可操作的拓扑模型。GIS水文分析工具以在计算区域模拟无限降雨的方式形成汇流,因而所形成的河道并不一定是真实的河道,需要设置一定的汇流面积为阈值定义河道。DEM所提取河网本身已经包含拓扑信息,为了在关联污染源的时候更易操作,需要将拓扑关系以拓扑表的形式存储。存储拓扑关系的最小单元也即计算单元,计算单元可以以任意精度将河网进行切割,然而为了提高计算的效率,并为以DEM计算形成的汇流栅格分配初始流量做准备,需要以DEM的分辨率为最小切割单元进行切割。如图,假设DEM分辨率为90 m,则以90 m为一个单元将河网分为11个计算单元,其中1、7、9号单元为源头单元,11号为出流单元,2号单元为1号单元下游,同时也是3号单元的上游,由于支流的存在,10号单元存在4号和5号两个上游,以此类推可以形成图中所示的河网拓扑关系表。
2.3. 污染源拓扑关系构建
长久以来,在规划或者决策过程中往往仅考虑所管理区域污染物的排放量、入河量,然而对于污染物入河以后对河网水质的影响欠缺系统性的分析。与工业源、集中式污水处理厂等具有实际排放口的点源污染不一样,面源污染没有固定的排放口,为了更加系统性地分析面源污染带来的影响,需要将面源污染概化为点源纳入到模型计算中。如图2所示,若1号、3号污染源代表农村生活源,村落往往傍水而建,则可用该村落产生的生活污水推算出入河量,并将该村落投影到附近河道作为一个“虚拟”排口。
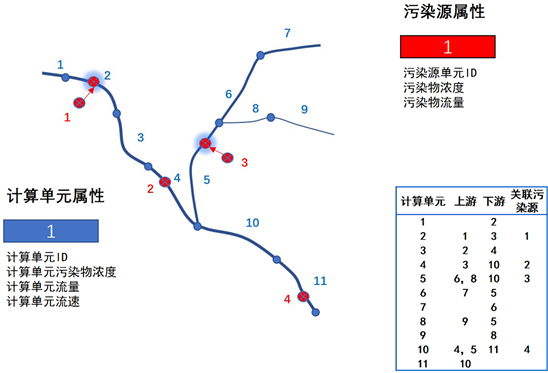
Figure 2. Schematic diagram of topological relationship construction of river network and pollution sources
图2. 河网以及污染源拓扑关系构建示意图
排口设置完成后需要将污染源与计算单元关联,将被关联的污染源编入拓扑关系表,至此拓扑关系表相当于一个索引表,以上游、下游、计算单元以及污染源的ID为键值实现计算单元的关联。计算单元和污染源数据应分别封装到不同的类内,其中计算单元类应包含计算单元ID、计算单元污染物浓度、计算单元流量和计算单元流速四个属性,污染源类应包含污染源ID、污染物浓度和污染物流量三个属性。
2.4. 污染源源强的核算
点源污染源可以通过调查统计的方式获得污染源强的数据,面源污染源的源强与流域范围内人类活动及产汇流的过程相关。面源污染源强的确定分两部分进行,首先通过年平均降雨量在区域内的分布情况以及下垫面的覆盖类型利用SCS-CN模型计算各计算栅格累计流量,再根据各下垫面的平均事件浓度计算在相应降雨事件条件下的污染源强。面源污染仅考虑COD以及TP的污染负荷,NH3-N负荷不计。
径流曲线数模型(SCS-CN, Soil Conservation Service Curve Number Model)是由美国农业部自然资源保护局开发的确定特定区域降雨事件直接径流近似量的有效方法。
(2-4)
式中:Q——累计径流量,mmH2O;
P——降雨量,mmH2O;
Ia——初损,包括:地表蓄水、截留和产流前的下渗,mmH2O;
S——潜在最大保留量,mmH2O。
初损Ia通常按0.2S估算,则径流量为:
(2-5)
(2-6)
式中CN为径流曲线数,是反映降雨前流域特征的一个综合参数,它与流域前期土壤湿润程度、坡度、植被、土壤类型和土壤利用现状等有关。
利用美国土壤保持局长期水文影响评价模型(Long-Term Hydrologic Impacts Assessment of landuse changes, L-THIA)对非点源负荷估算。非点源污染包括城市径流、农村径流、农田径流。
(2-7)
式中:L——污染负荷量,kg;
R——径流量,mm;
C——事件平均浓度(Event Mean Concentration, EMC),mg/L;
A——集水区面积,m2。
2.5. 河网流量初始化
水是污染物降解和扩散的媒介,只有让河网中所有计算单元的计算单元流量属性赋值后河网水质模拟才可以展开。通常以圣维南方程为基础,推导单一河道下一维水动力学数值解,这无疑增加了水质模拟的复杂程度。为了减少模型运行的成本和复杂度,可以利用GIS汇流分析计算计算范围内所有像元点会累计流量与流域出流点累计流量的占比,从而依据出流点实际流量推演河网各计算单元的流量。由于GIS汇流分析时假设降雨无限大,因而累计流量与流域面积成正比,累计流量之比也即汇流面积之比。如图3所示,11号计算单元端点的汇流面积为A11,4号计算单元汇流面积为A4,7号计算单元的汇流面积为A7,则11号、4号、7号计算单元的初始流量分别为Q11,Q11*A4/A11,Q11*A7/A11,以此类推可以将整个河网赋值初始流量。
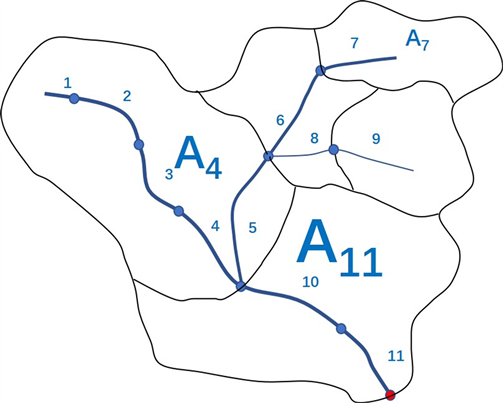
Figure 3. Schematic diagram of flow distribution principle of river network
图3. 河网流量分配原理示意图
2.6. 模拟运算
栈是一种数据结构,遵循先进后出的规则,利用栈可以实现对河网树形结构的遍历。当沿着河网计算计算单元的污染物浓度时,若沿途不存在支流或者计算单元上游已经完成所有计算时,通过检索拓扑关系表查找对应下游计算单元顺序计算即可完成一连串的污染物浓度计算。若出现支流或者上游存在未完成计算的单元时需要将未完成计算的支流或者计算单元推入栈中等待计算,直到推至河流源头时再逐一从栈中取出计算单元进行计算。计算单元的污染物浓度与上游计算单元污染物浓度之间符合一维动力学关系,其中源头污染物的浓度可以是上有控制单元来水的污染物浓度或者水体本地污染物浓度,当计算单元处排口设置,则该计算单元的污染物浓度等于一维水质模型运算结果与排口污染物均匀混合后的浓度。
如图4所示,依据前述计算规则,若计算起点选择3号计算单元,则由于3号计算单元并非所在河道源头,上游存在未完成计算的计算单元,则依次将3号、2号计算单元推入栈中,2号计算单元上游单元为1号,1号已至源头,则依次按照1→2→3的顺序从栈中取出元素并依照一维水质模型计算各计算单元水质,其中2号单元上有1号污染源,故将1号污染源与2号计算单元均匀混合后作为2号计算单元污染物浓度继续参与计算。计算至4号计算单元时,上游计算单元皆以完成计算,且不存在支流,则继续往下游计算,4号计算单元下游10号单元存在支流5号计算单元,故而将10号计算单元及其未完成支流推入栈中等待计算。如此整个过程的计算顺序应该是1→2→3→4→9→8→7→6→5→10→11。
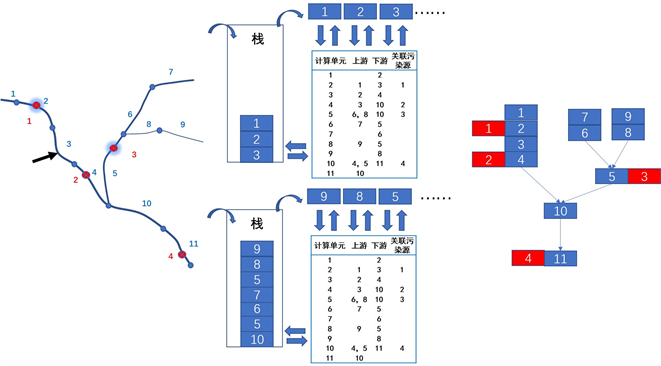
Figure 4. Diagram of traversal principle of river network
图4. 河网遍历原理示意图
3. 研究区域与数据
3.1. 研究区概况
如图5所示,研究区域位于龙川江流域,龙川江地处横断山脉与云贵高原的过渡地带,是流经楚雄州境内中心地带的一条重要河流,河道平均比降4.8‰,流域径流面积9327.4 km2。区域内峰峦叠障,谷地错落,溪河纵横,流域内大部分属中山山原地貌,中上游山高坡陡,河床切割深,地形起伏大,下游地势较缓,为盆地地形。蜻蛉河为龙川江最大的一级支流,发源于姚安县太平乡各苴坪无名山,源地高程2767 m,河长143.6 km,落差1817 m,平均比降9.0‰,集水面积3548 km2。本次模拟以龙川江流域北部片区为研究对象。
3.2. 数据处理
以SRTMDEM 90M分辨率原始高程数据为基础对龙川江流域北部片区进行水文分析,提取流域内各像元累计流量以作备用,并定义0.9 km2的汇流面积所形成的汇流为河道,将提取出的河网矢量化并以90 m为一个计算单元划分计算单元,并逐个单元赋值唯一ID。河网拓扑关系的编码利用Python的Networkx包实现,将编码完成的河网拓扑关系写入拓扑关系表。河网计算单元添加COD、NH3-N、TP等污染物浓度字段,添加河道流量字段。
河网拓扑关系建立后需要对河网各计算单元初始化处理,包括污染物本底浓度以及计算单元初始流量。污染物本底浓度的设置分为上游来水以及源头点两种情况,若存在上游来水则以上游来水污染物浓度作为本底,若计算单元为源头点,则可以取区域内水质较好湖库平均水质,其他计算单元污染物可不用赋值计算单元初始流量的设定以所提取累计流量栅格数据以及2017年龙川江入金沙江平均流量进行确定。各河段流量分配的结果如图6所示。
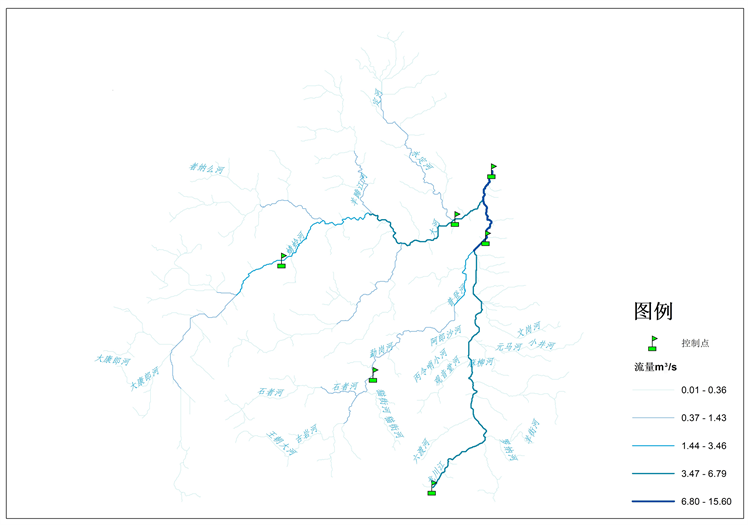
Figure 6. The results of flow distribution initialization in the river network in the basin and the distribution of cross-section of model check
图6. 流域内河网流量初始化分配结果与模型校验断面分布情况
根据第二次污染源普查中该流域片区内的涉水工业企业、畜禽养殖状况、集中式污染源、农村生活污染源、城镇生活污染源等数据构建污染源拓扑网络,污染源的分布如图7和图8所示。由于DEM精度、污染源类型等原因,污染源往往距离河道有一定距离,为了准确构建污染源拓扑网络,需要将所有污染源以点源的形式投影到最近河道,采用Python代码的形式将污染源移动到就近河道上,并将污染源与计算单元进行关联。

Figure 7. Distribution of pollution sources and underlying surface in the basin
图7. 流域内污染源及下垫面类型分布图
4. 结果与讨论
4.1. 模拟结果
水质模拟结果如图9所示,模型模拟了1624.39 km河道的水质,其中满足地表水I类标准的河段占24.7%,满足地表水II类标准的河段占28.4%,满足地表水III类标准的河段占15.9%,水质优良率为69%。IV类、V类以及劣V类水分别占模拟河段长度的13.5%,8%和9.5%,主要分布在距离居民点较近的支流、岔流。

Figure 8. Source intensity distribution of non-point source pollution in the basin
图8. 流域内面源污染源强分布
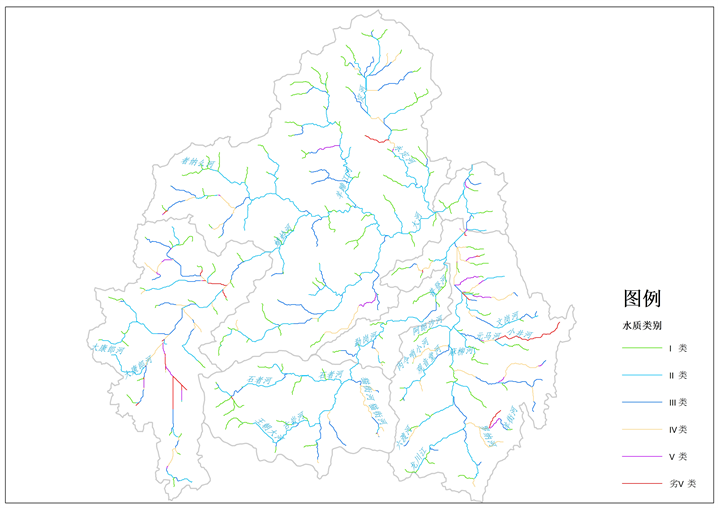
Figure 9. Water quality simulation results of each reach in the basin
图9. 流域内各河段水质模拟结果
4.2. 模型校验
河网水质的模拟同样利用Python代码实现,由于COD数据缺失,此处仅以TP和NH3-N的实测浓度来校验模型,校验结果如图10所示。分别在蜻蛉河、龙川江和勐岗河(又名普登河)选取断面计算2017年TP和NH3-N的年平均浓度,共选取5个断面。TP和NH3-N实测值和模拟结果之间具有较好的相关性,其中TP皮尔逊相关系数为0.91,NH3-N为0.98。NH3-N实测值和模拟值之间的线性拟合结果较好,斜率接近与1,且Nash-Sutcliffe系数为0.95,表明模型对NH3-N具有较好的模拟能力;TP实测值与模拟值之间的线性拟合结果相比较于NH3-N较差一些,拟合曲线斜率约为1.36,略大于1,Nash-Sutcliffe系数为0.82,表明一维水质模型对TP具有一定的模拟能力,但模拟的精度还不够高。
4.3. 模型运行效率
模型运行的时间与河网密度以及河网长度呈正相关。模型运行效率见图11,根据模型运行时间与河网上游河段数之间的关系可以将河段分为5个模式,其中模式1河段数量占比最高,占总河段数量的92.4%,模型运行时间随上游河段数量的增长模式为线性增长,增长速率最大;模式2模型运行时间随上游河段数量的增长无明显相关性,该部分河段数量占总河段数量的0.58%,主要为无支流汇入的干流河段;模式3模型运行时间随上游河段的增长呈指数型增长,该部分河段占总河段数量的1.97%,空间分布形式无明显规律;模式4和模式5增长方式均为线性,增长速率略小于模式1,该部分河段分别占总河段数量的3.67%和1.34%,空间分布无明显规律。若以Shreve法河网级别作为河网密度的表征形式,模型运行时间与Shreve河网级别之间的关系和模型运行时间与上游河段数量之间的关系一致。

Figure 10. Regression analysis between model running results and measured results
图10. 模型运行结果与实测结果回归分析
综上,我们利用模式1表征模型的复杂程度。
(4-1)
式中Z为模型运行时间,单位s;X为河网Shreve级别;Y为上游河网长度,单位m。
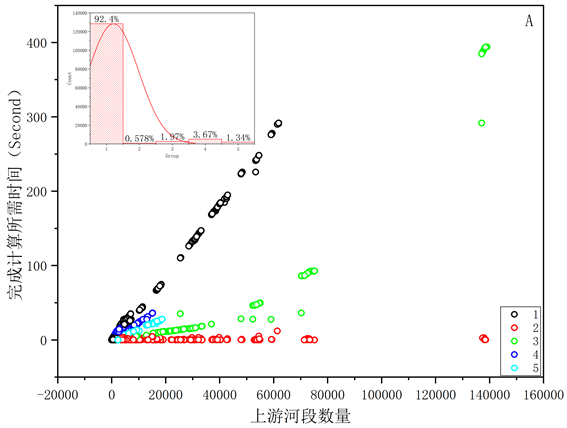

Figure 11. Model operation efficiency. (A. Relationship between model operation time and the number of river reaches. B. Relationship between model running time and river network density)
图11. 模型运行效率。(A. 模型运行时间与河段数量关系。B. 模型运行时间与河网密度关系)
5. 结论
相比较于Mike、SWAT等商用模型,本模型对于大流域河网水质的模拟效率较高,能够大幅度削减模拟消耗的时间,对于流域面积约8000 km2 (河网长度5571.72 km,Shreve河网级别3579)的流域,模拟时间仅为4.86 min。同时模型输入参数较少,模型复杂度较低,可控性较强。模型对于TP的模拟效果相比较于NH3-N稍差,这与TP复杂的削减过程有关,需要进一步完善TP在复杂水环境条件下的过程模拟,但总体来说对河网水质的模拟效果较好。在模型运用前景方面,在现阶段,模型可运用于大型流域综合决策过程中较大时间尺度下的水质响应关系的模拟以及河流水功能区环境容量的精细化计算,对于较小时间尺度(如应急响应)的运用有待下一步的开发。
NOTES
*通讯作者。