1. 引言
车牌信息识别技术是未来智能交通系统的一个重要组成部分,是智慧交通、智能驾驶技术的基础。对车牌识别技术的研究是目前非常活跃的前沿研究方向,如何又快又准确地识别车牌信息具有广泛的行业应用研究前景和极其重要的技术研究价值。
目前,车牌识别系统有很多种,其中,主要有基于颜色分割方法 [1]、基于边缘检测方法 [2]、基于灰度化处理方法 [3]、基于机器视觉的识别方法 [4]、基于神经网络的识别方法 [5] 等,这些识别方法的使用都过于单一化,识别的精度与速度还不够。
而基于融合算法的车牌检测的主要步骤是先使用Sobel边缘检测算法来迅速完成对车牌颜色区域的定位,然后使用HSV算法完成对车牌颜色的识别,使用预先已经训练过并配置调试好的SVM分类器来迅速进行分类识别,以确定检测到的图像是否存在车牌。字符识别方面,先使用ANN神经网络进行训练,并输出相应的模型,之后使用训练好的模型分割出车牌的字符,通过OpenCV调用模型来进行车牌的实时检测识别。本文提出的车牌智能识别检测系统由如下两部分组成:车牌检测和字符识别。

Figure 1. Realization process of automatic license plate recognition system
图1. 车牌自动识别系统实现流程
2. 车牌识别系统
本系统是一种基于数字图像采集处理功能与射频识别的融合技术构建数字化车辆自动识别技术系统。车牌识别系统的实现步骤可分为两个部分:车牌检测和字符识别。系统结构如图1所示 [6]。
图像采集一般通过特定的摄像装置来进行,摄像机系统通常由一组传感器相互连接。传感器探知到汽车行驶在一定地方时开启摄像机系统,在特定的视角下拍摄车牌的画面。而图像处理则是指通过对所收集的画面信息进行变换、缩小、增强和修正等工艺处理,以突出车牌的主体特点,获得适当的清晰度,克服了因为汽车的驾驶状况不同所导致的污损等原因引起的车牌清晰度不够的情况。车牌的确认和切割就是将拍摄到的实时画面通过图像处理技术产生灰度图像,并从中确认车牌的具体位置,同时,把含有车牌文字信息的画面从整个图像中切割开来,用于实现字符识别。文字预处理一般是包括图像二值化、去除噪声、将字符分离和归一化等步骤,以便于更高效地进行字符识别。字符识别就是对进行预处理后图像中的文字加以鉴别,然后转换成文字信息输出 [7]。
该系统通过多种识别算法进行融合,以实现对整体车牌的精确识别,其中,车牌智能检测的部分主要通过支持向量机(SVM)模型算法对所拍摄到的图片数据进行识别处理,判断是否含有车牌并提取出所想要辨识的完整车牌图像。字符的识别主要是使用一种机器学习算法——人工神经网络(ANN)的模型对车牌的字符信息进行识别,得到相应类型的字符串,最终实现车牌识别的目的 [8]。
3. 车牌检测
车牌检测部分主要是对每个含车牌的图片进行识别,最后截取出只含有单个车牌的图片。如果直接对原始的图片进行鉴别会非常慢,所以必须对原始图像进行预处理。这些步骤的主要目的就是为了减少在车牌识别流程中的计算量。这种流程中,可以通过机器学习算法SVM,去判断截取的图片是不是“真的”车牌。
车牌检测包括车牌定位、车牌判断两个过程,具体流程如图2所示。
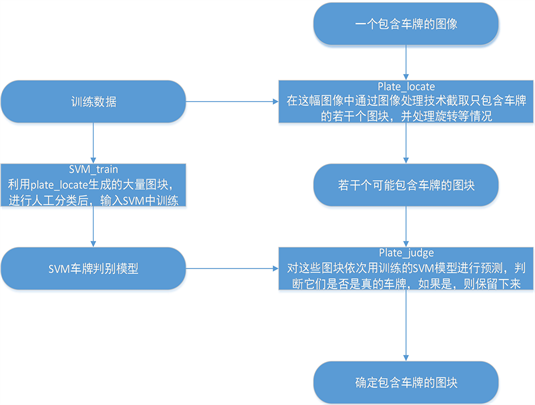
Figure 2. Process of license plate detection
图2. 车牌检测流程
3.1. 车牌定位
车牌定位主要是将图片中有可能是车牌的区域定位出来,方便后面进一步处理。本检测系统主要通过与Sobel边缘检测定位方法、SVM分类器检测等方法相互结合来辅助定位车牌的位置,再利用HSV颜色模型确定车牌颜色。
在进行车牌定位的时候,考虑不同拍摄环境下所拍摄的图片质量参差不齐,使用传统边缘检测算法进行车牌定位的方法会出现较大偏差,所以采用对Sobel算法定位后的区域边界进行缩小,使用HSV颜色再定位的方法,提高定位的准确性,车牌定位具体操作流程如图3所示。

Figure 3. Flow chart of license plate positioning
图3. 车牌定位流程图
3.2. 车牌判断
支持向量机分类(SVM)算法技术是由纽约大学Vapnik教授及其开发工作小组成员所提出来专门针对二类组别分类的技术问题而提出来的一种分类算法技术。支持向量机模型的基本构造思想是指在给定样本空间上或给定特征空间上,构造出可将样本分为正负两部分的超平面(或称判别函数),并通过训练学习寻找出一个最优的超平面,最终使此超平面与各种不同空间类型样本集之间的平均空间距离尽可能趋于最大,从而使其能够具有最大的自由度空间泛化能力 [9]。
关于训练数据集随机分类的概念,其在一般的神经网络理论中形成的原因,也能够简单地表述为:训练样本集中会随意地生成一个分割样本空间的超平面并且能够随意的移动它,直到各个训练数据集中属于不同类别的节点都同时或者正好处在这个分割超平面上的两个侧面,并且超平面两侧空白的区域达到最大 [10]。使用这些以计算机机制确定的神经网络算法所获得的分割面并不是最优的预测超平面,而是一部分的预测推广能力较差的次优超平面。使用SVM可以将最优超平面的求解过程转化为在某个二次不等式约束条件下的函数最小值问题,它是一种凸二次规划,具有唯一解,并将求解得出的确界值作为全局最优解。
使用SVM对车牌部分样本和非车牌部分的负样本进行识别训练,生成训练模型,进而实现对车牌的识别和分类。
4. 字符识别
字符识别的主要目的,就是利用上一环节车牌检测过程中所分割到的车牌图片,完成光学字符识别(OCR)这项程序。这里所用的机器学习算法是人工神经网络(ANN)算法。
字符识别包括字符分割、字符识别两个过程,具体流程如图4。
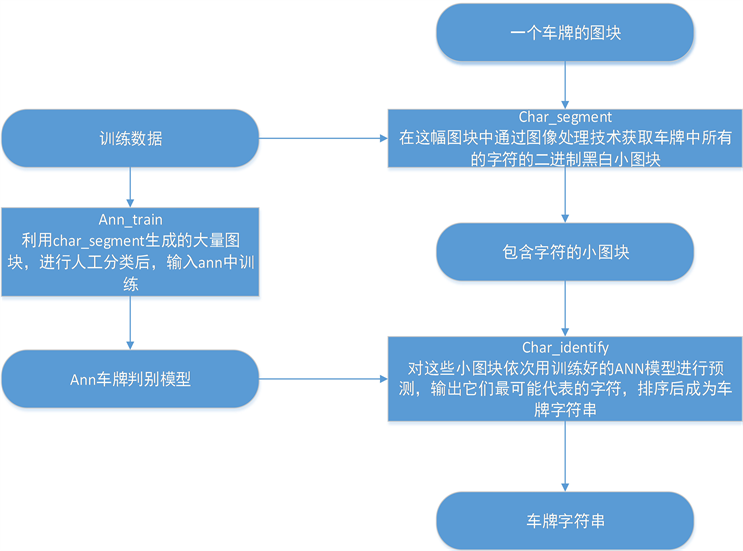
Figure 4. Process of character recognition
图4. 字符识别流程
4.1. 字符分割
对车牌的字符分割大致包含如下过程:1、使用OpenCV对定位到的车牌图像进行灰度化处理;2、将处理后的车牌图像进行二值化处理,并获取车牌中的字母和数字;3、提取最小的外接矩形,并根据矩形的宽高比和长度进行验证,然后切割出单独的字符图像,最后统一到相同的尺寸,并保留下来,字符切割的结果如图5所示。


Figure 5. Result of Character segmentation
图5. 字符分割结果
在进行字符信息的识别及检测前还需对字符信息图像进行一些预处理,以达到最有利于后续对字符信息的提取及识别 [11]。具体方法为:对经过OpenCV采集处理后的车牌灰度图像进行二值化处理。该处理方法的速度快、效率高,同时,经过二值化处理后的文字笔画更加饱满,从而减少了文字空心、笔画断裂等现象,利于对汉字字符的辨识。经过二值化处理后,测量得到的车牌图像,该图像可直接使用直方图投影原理分离出单个图形,单个图形中的文字点阵在经过归一化处理后可转变为一种拥有至少为16 × 16个像素的数字符文字点阵。通过实验结果分析后可得出结论,充分证实最少产生16 × 16个像素字符的车牌文字点阵,可实现在基本满足车牌与汉字识别系统的逻辑语言特征与功能,合理地降低了对车牌中汉字的输入与计算量,大幅加快了车牌字符的识别速度。
4.2. 字符识别
本系统主要通过ANN人工神经网络算法对汉字加以训练并识别,首先,将训练所得的文字通过仿射转换,将每个汉字统一大小并归一化到图像中间,同时,将字母的大小修改为30*30的尺寸。之后,提取字母的水平和垂直方向的累计直线图和最低辨识度图形,将两种图像作为ANN神经网络进行训练的两个样本,通过ANN神经网络内部的十个隐藏层输出相应的模型 [12]。在字符方面,首先,利用OpenCV和相应的函数对字符图像进行训练,并生成相应的模型,之后,再利用字符识别功能对车牌的各个特征进行分析,最后,经过实验测试得出对车牌中字符信息的识别准确率可以做到98%左右。
将每个字符图块里都分别放入一套事先经过训练并且准备制作好的ANN神经网络模型,通过分析此模型可以快速预测出在每个字符图块中所需要并能够被表示的所有最具体的字符。最后,将识别的各个字符整体输出 [13]。
4.3. 系统实验结果
为验证融合算法在车牌识别系统中的有效性,通过使用等比例缩小的车辆与车牌模型进行识别,使用的开发板为树莓派4b,在Linux系统下进行测试,使用Python 3.6版本,通过终端操作进行了车牌识别实验,搭载OpenCV的版本为3.2.0,程序编译使用Visual Studio 2020。所得输出结果如图6所示。
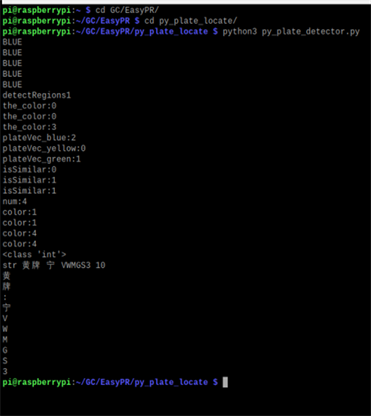
Figure 6. Result of license plate recognition
图6. 车牌识别结果
通过统计数据,与神经网络算法、传统SVM算法在识别率和识别总时间上进行对比,在相同的实验数据集上,实验结果如表1所示。由表1可以发现,融合算法与神经网络算法相比,具有更快的识别速度,且识别率差不多,与传统SVM算法相比,在识别速度和识别率上都有了较大的提升 [14]。

Table 1. Comparison of experimental results
表1. 实验结果对比
5. 结束语
本文提出了一种基于融合算法的车牌识别系统,通过OpenCV来进行实时的图片截取检测,实时采集车辆的多种特征信息。对识别系统的测试,共选择了约五百个不同数字、背景颜色的车牌进行检测识别,该系统的车牌定位成功率超过了98.93%,对车牌数字的识别度超过了97.43%。经试验,该系统适合应用于复杂条件下识别车牌,其具有对车牌的鉴定速度快、准确率高,对硬件配置要求低等优点,具有较为不错的实用价值。