1. 前言
指数追踪的目标是使得股票的投资者与股指期货空单对冲,由此来保值。指数型的基金管理者常常面临选择何种投资股票的问题,比较常用的有完全复制法和不完全复制法。其中,根据目标指数中每种成分股所占的权重来购买目标指数中的所有成分股,这种方法就叫做完全复制法。这种方法所需要的成本较高,在成分股较多的指数,比如沪深300这样的指数中并不适用。反之,购买目标指数中的部分股票的方法称为不完全复制法,然后最小化追踪组合收益率和目标指数收益率之间的误差获取资产比例,虽然存在一定的追踪误差,但是其投入的成本较低,更受投资者的青睐。
迄今为止,国内外学者们对指数追踪这一领域的研究还在持续不断的进行。Markowitz [1] 提出了投资组合理论(MPT),Markowitz将复杂的投资组合选择问题巧妙的变成了一个被约束的二次规划问题,风险大小用方差来衡量,这一理论成为了现代投资组合理论的核心内容。许多学者在此基础上发展了一系列的指数追踪模型。Roll [2] 提出了基于均值–方差模型,期望收益不变,对
进行约束,用最小化追踪误差的方差来进行建模。陈春锋和陈伟忠 [3] 对在此之前的指数追踪问题的研究方法、实证研究、研究模型等进行了深入的阐述。Walsh等 [4] 在追踪误差的理论下,对比不同的约束条件、不同的求解方法等对追踪误差的影响,以此来优化模型。刘磊 [5] 采用二进制和实数值混合编码的遗传BP网络对指数跟踪管理中的资金进行优化配置。获得较好的效果。倪禾 [6] 提出了一种基于启发式遗传算法的寻优方案,通过最大化效用函数来寻找一个最为经济的指数复制组合。倪苏云和吴冲锋 [7] 指出了线性跟踪误差最小化模型所具有的优点。Philippe Jorion [8] 探讨了受跟踪误差波动性(TEV)约束的活跃投资组合的风险和回报关系,也可以从风险价值角度来解释。杨虎,杨玥含 [9] 总结了多种多元回归方法在指数追踪中的应用。
股票市场中没有严格的函数关系,但很多变量之间是存在关联的,回归分析能够很好的刻画变量之间的相关关系。在设计阵病态或变量间存在多重共线性时,传统的回归模型不再适用,因为最小二乘估计本身设计的结构问题,当条件数过大时,均方误差也会迅速增大。当存在多重共线性时,有偏估计能够避免均方误差迅速增大的情况发生,所以本文选用经典的有偏估计模型,岭回归与逐步回归。
2. 模型介绍
2.1. 线性模型基本理论
一般的,设有p个解释变量
,与被解释变量Y有如下关系:
(1)
(2)
称(1)~(2)式为多元线性回归模型,线性函数
(3)
称为多元线性回归函数,
称为回归系数。它们与
均未知。
设
为
的实验数据,且
(4)
记
则(4)式表示为:
(5)
这就是通常所说的线性模型,它是统计学中极为重要的研究分支之一,式中X是一个纯量矩阵,称为设计矩阵或结构矩阵,在回归分析中一般假设X为列满秩,即
;
是n维零向量,
是n阶单位矩阵。
设
是
的估计量,则称
(6)
为线性回归方程。记
(7)
(8)
残差平方和为
(9)
对给定的观测数据
,
其实就是下面最优化问题
(10)
的最优解。因此
为
(11)
的解。由(11)式可得
(12)
(12)式为正规方程。因为
,所以
存在,故得到
得LS估计
(13)
从而,(8)式为
(14)
需要注意的是(13)式具有两重性。
如果
换成随机变量Y得一组随机样本
,则
是随机向量,为回归系数向量
的估计量;同样
可以看成
的观测值,从而(13)式又是一个纯量向量,是回归系数向量的一个估计值。
2.2. 岭回归
岭回归实质上是一种改良的最小二乘估计法,岭回归放弃了最小二乘的无偏性,以损失部分信息、降低精度为代价获得的回归系数更为符合实际,更可靠的回归方法,对病态数据的拟合要强于最小二乘法。岭回归模型如下:
为岭系数,I为单位矩阵(对角线元素全为1,其他元素全为0)。岭回归的代价函数加入了一个正则项(如果没有正则项则是无偏估计)。下面是岭回归的代价函数:
其中,
,通过对
值的选择,可以减少多重共线性的影响,取不同的
值,可以得到不同的估计。当
,
就是普通最小二乘估计。
2.3. 逐步回归
逐步回归的基本思想是将变量逐个引入模型,每引入一个解释变量后都要进行F检验,而后对以及选入逐步回归的变量进行逐个的检验,当后面选入的解释变量导致之前选入的解释变量不显著时将其剔除。由此可以保证每次引入新的解释变量,逐步回归方程里面的所有解释变量均显著。
有两种逐步回归的方法,一种是向前法:从模型中没有解释变量开始,反复添加最有帮助的解释变量,直到没有显著的预测变量选入回归方程。
首先,对p个自回归变量
,分别对因变量Y建立一元回归模型
计算变量
,并计算与之对应的回归系数的F检验统计量的值,记为
,取其中最大值
,即:
对给定的显著性水平
,记相应的临界值为
,
,则将
引入回归模型,记
为选入变量指标的集合。
建立因变量Y与自变量子集
的二元回归模型,共有
个。计算变量的回归系数F检验的统计量,记为
,选其中最大值,对应自变量脚标记为
,即:
对给定的显著性水平
,记相应的临界值为
,
则变量
引入回归模型。否则,终止变量引入过程。后面重复上一步,直到没有变量通过F检验为止。
还有一种方法是向后选择法,从完整模型中的所有预测变量开始,以迭代方式删除贡献最小的预测变量,直到没有不显著的解释变量从回归方程删除。
3. 实证研究
3.1. 数据介绍
本文的数据来自于上证50指数及其成分股在2022年5月4日至2022年7月4日的5分钟K线收盘价数据,数据共2016条。其中,训练集占整个数据集的3/4,共计1344个数据,测试集占整个数据集的1/4,共计672个数据。
3.2. 回归诊断
在多元线性回归模型中,需要假定随机误差项
服从
。在目前的应用中,绝大多数都采用这样一些假设。如果分析表明实际问题不满足随机误差项的正态性假设,则可以对数据作适当的处理,使其满足或基本满足这些假设。
利用R语言获得上证50指数与其成分股之间的经验回归方程如下:
模型检验结果如表1所示:

Table 1. Least squares estimation model test
表1. 最小二乘估计模型检验
虽然模型通过检验,但拟合优度接近于1,存在过拟合现象;特征值最大为25.82,最小特征值为 0.0026。条件数大于1000,所以变量间存在复共线性。
结合图1初步分析得到该模型残差基本满足正态分布,但有多个异常值点。从QQ图来看基本满足正态性。
W正态性检验:H0:残差服从正态分布。
,由W检验结果知P值不显著,接受原假设,即残差满足正态性假设;图2图显示绝大部分点都在置信区间内,说明残差符合正态分布假设。
图3给出了前9个变量的偏残差图,表明变量间呈现线性关系。
3.3. 岭回归
考虑上证50指数与成分股之间关系的岭回归方程。首先选择岭参数,HBK、L-W给出的
值分别是0.0684、0.0092,GCV的最小值是0.0529,这里选择最小
值0.0092,得到岭回归方程为:
将自变量的值带入岭回归方程中得到
的预测值,分析残差,以此求出普通残差。图4给出了岭回归方程的残差图,残差平方和为7083.679。
图4表明,岭回归方程刻画了上证50指数的趋势,但从方程的系数来看,负系数较少。理论上主成


Figure 1. Residual graph of SSE 50 index
图1. 上证50指数残差图

Figure 2. The QQ graph of the residual error of the Shanghai Stock Exchange 50 Index
图2. 上证50指数残差正太QQ图

Figure 3. SSE 50 Index Deviation Residual Graph
图3. 上证50指数偏残差图
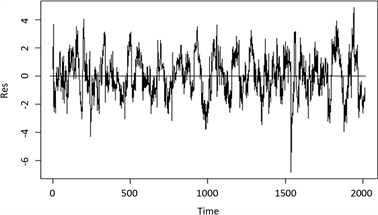
Figure 4. Residual plot of ridge regression equation
图4. 岭回归方程残差图
分估计和岭估计都能接近最小二乘估计的最佳残差,但主成分估计在应用中,会保留过多的主成分,会导致大量系数不显著,给进一步的分析带来困惑和隐患。
3.4. 逐步回归
通过逐步回归选择变量,第一步计算表明全部变量进行回归后
,有5个变量可供删除,删除后变量所能得到的最小值是
,对应删除的变量是
;第二步发现有4个变量可供删除,最小AIC值是−271.80,需要删除的变量是
,以此类推:
模型平均残差平方和为38.25973,标准差为5.947346。
从图5中能够看到残差图显示是白噪声序列,且预测效果较好。

Figure 5. SSE 50 index tracking chart with stepwise regression method
图5. 逐步回归方法的上证50指数追踪图
4. 结论与展望
在多元线性回归中,变量间存在多重共线性是非常普遍的现象,对多重共线性程度的检测非常重要,这一定程度上决定了用何种方法去解决某一特定回归的复共线性问题。在本文中,多重共线性问题存在,但不算特别严重,所以本文用了两个比较经典的方法来对数据进行处理,分别是岭回归与逐步回归,这两个方法都能很好的解决多重共线性问题。另外,在指数追踪领域中,多元线性回归的应用较少。在本文的实证研究中,岭回归与逐步回归的残差平方和分别为7083.679与1912.9865。因此,在本文选用的上证50指数中,逐步回归法进行的追踪效果更优。相较于其他多元线性回归分析,逐步回归具备更合理的自变量筛选机制,能避免因无统计学意义的自变量对回归方程的影响。