1. 引言
2019年12月下旬爆发的新冠疫情几周内在全球许多国家和地区蔓延。感染人数迅速增多,各地死亡人数激增,这一突发的公共卫生安全事件对全球各地的社会、经济造成了不同程度的破坏与深远的影响。截至2022年9月18日全球新冠累计确诊病例超过6.09亿人,死亡病例数超过650万人。随着对病毒了解程度的不断加深,世界各国政府采取戴口罩、保持社交距离、关闭各种场所等措施避免因大型聚集导致病毒进一步传播,但由于新冠病毒极高的传染力与变异性,该病毒仍在继续传播并影响人类的健康与全球经济。对疫情发展趋势进行预测,是防止新冠肺炎大流行传播的关键因素之一。准确的疫情趋势预测可以对政府当前所采取的政策的有效性以及对当前该地区医疗保健系统的压力做出反馈。利用现有数据,对病毒传播的趋势进行预测。可以使政府在分配医疗资源、放松或提高封锁水平等方面做出及时的响应与计划。
易感–感染–恢复(Susceptible-Infected-Removed, SIR)模型、易感–暴露–感染–恢复(Susceptible-Exposed-Infected-Removed, SEIR)模型是传染病动力学研究的经典模型。任磊等使用分数阶SIR模型 [1] 对新冠肺炎疾病传播进行预测。范如国等基于流行病SEIR动力学模型 [2] 对3种不同潜伏期状态下的疫情拐点进行预测,Alenezi等人使用SIR模型 [3] 分析和预测新冠肺炎在科威特的爆发,他们提出的SIR模型几乎与实际确诊的感染病例和康复病例相吻合。但由于每次疫情的爆发都具有其独特的传播特征、不同地区的防控政策以及人口的流动等因素都将增加传染病动力学模型的不确定性。因而传统的传染病模型难以对长期的预测提供可靠的结果。随着深度学习技术的发展,深度学习方法在预测领域表现出良好的性能。相对于其他方法而言,深度学习具有计算速度快、误差小、预测结果更加准确的优点。基于已有的新冠肺炎数据集,一些研究人员已经使用深度学习模型对新冠肺炎的传播趋势进行预测。Chimmula和Zhang使用LSTM神经网络 [4] 最先进的机器学习模型来预测加拿大大流行的可能结束时间。根据他们的LSTM模型,他们的模型短期准确率为93.4%,长期为92.67%,估计结束大流行所需的时间约为三个月。Ismail等人基于自回归移动平均(Autoregressive Integrated Moving Average, ARIMA)模型、LSTM、非线性自回归神经网络(Nonlinear Autoregression Neural Network, NARNN)模型 [5] 进行了一项比较研究,用于预测丹麦、比利时、德国、法国、英国、芬兰、瑞士和土耳其的新冠肺炎病例。他们研究发现与其他模型相比,LSTM提供了最小的均方根误差(RMSE)。Mehdi等使用递归神经网络(Recursive Neural Network, RNN)、LSTM、季节性自回归综合移动平均(Seasonal Autoregressive Integrated Moving Average, SARIMA)和霍尔特–温特(Holt Winter)的指数平滑和移动平均方法 [6] 来预测伊朗的新冠肺炎病例,他们对这些方法进行对比研究发现LSTM模型在伊朗感染预测优于其他模型。Parul等使用Deep LSTM、Convolutional LSTM、BiLSTM模型 [7] 预测印度新冠肺炎阳性数量,他们的研究结果表明BiLSTM模型在短期预测(1~3天)上的误差小于百分之三,具有非常准确的预测结果。Nahla等人提出使用LSTM、门控循环单元(Gate Recurrent Unit,GRU)模型 [8] 来预测埃及、沙特阿拉伯和科威特的确诊病例和死亡病例,他们的研究结果表明,LSTM在三个国家的确诊病例中表现最好,GRU在埃及和科威特的死亡病例中表现最好。Verma,H等设计了循环和卷积神经网络模型:vanilla LSTM、stacked LSTM、ED_LSTM、BiLSTM、CNN和CNN-LSTM模型 [9],预测印度及其四个受影响最严重的地区7、14、21天的每日确诊病例,通过他们的研究,发现BiLSTM及CNN-LSTM模型相对于其他模型具有更好的预测效果。然而,这些传统模型与深度学习模型均未考虑到由于疫苗接种、人口数量、医疗设施等因素对新冠疫情传播的影响。本文将综合分析疫苗接种状况、人口数量、医疗基础设施等信息与新冠肺炎确诊病例的相关性,选取相关程度较高的特征,使用BiLSTM模型预测澳大利亚、中国台湾、南美、以色列四个地区的滞后期为7天、14天、21天、30天的累计确诊病例并与LSTM模型进行对比分析。希望通过多特征下的BiLSTM模型提高新冠肺炎确诊病例预测的准确性。
2. 模型简介
2.1. LSTM模型
Hochreiter和Schmidhuber提出了LSTM模型 [10],LSTM神经网络模型是一种特殊的RNN模型,能够解决RNN模型梯度消失和梯度爆炸问题。LSTM改变了RNN隐藏层的内部结构,在RNN模型上增加了一个状态结构与三个门结构,分别是单元状态、遗忘门、输入门、输出门。遗忘门通过函数控制之前信息的输入程度,输入门用来控制当前信息的输入程度,输出门用来控制最终输出。LSTM的单元结构如图1所示,与RNN相比,在保留了RNN神经网路模型在处理时间序列问题上的优势基础上,LSTM能够综合处理长期与短期的时间序列输入问题。
在LSTM神经网络模型中,其执行步骤如下:
1) 通过遗忘门ft决定细胞状态中所需要剔除的信息,对负责t时刻的当前层输入向量xt选择忘记,通过计算ft控制上一单元候选状态Ct−1中的数据保留或忘记。此时,状态ft的表达式为:
(1)
其中,
为sigmoid激活函数,该函数将“记忆”权重设置为0~1之间的数值,当ft = 1时,上一单元信息全部被保留;当ft = 0时,上一单元信息全部被遗忘。Wf为上一单元隐藏层输出和当前输入数据相乘的权重矩阵;bf为遗忘门的偏置权重。
2) 由输入层it对候选向量进行控制更新,此过程中,输入数据xt和隐藏层ht−1经过输入门,得到向量it和内部状态
的表达式为:
(2)
(3)
其中,it为输出向量,
为临时神经元状态值;Wit为输入门it在t时刻的输入xt权重矩阵,Wc为新生成的信息在t时刻的权重矩阵;bi、bc分别为输入数据与新生成的数据在当前单元的偏置权重。
当遗忘门、输入门、临时设神经元状态完成计算后,当前神经元状态将会得到更新。此时,当前神经元状态Ct的表达式为:
(4)
其中,Ct由两部分组成,此过程用于抛弃当前单元中的无用信息,保留有用信息。
输入数据xt和隐藏层ht−1经过输出门,计算待输出结果ot,其中ot通过sigmoid激活函数控制得到初始输出,然后通过tanh层对下一时刻t + 1的状态进行处理,得到最后的输出结果ht,表达式为:
(5)
(6)
其中ot表示输出向量,ht为t时刻外部状态输出值。Wot为输出门ot的权重矩阵,bo表示偏置权重。
2.2. BiLSTM模型
BiLSTM模型的内部节点与LSTM模型相同,包含输入门,遗忘门,输出门。BiLSTM模型在LSTM模型的基础上添加了反向层,通过前向和后向信息获取神经网络预测结果,在进行预测时,BiLSTM模型往往优于LSTM模型。BiLSTM模型结构如图2所示。
2.3. 评价指标
本文选择以下两种指标来检验各模型的性能,包括决定系数R2 (反映模型的可靠程度)、平均绝对百分比误差MAPE(反映误差大小的相对值)。
(7)
(8)
其中:
为真实值,
表示平均值,
表示模型预测值,n代表预测天数。R2的范围一般在0~1之间,R2越接近于1,模型预测的效果越好,越接近于0,模型的预测效果越差,若R2为负数,则表明模型的预测误差过大;MAPE具有与尺度无关的优点,可用于比较不同尺度数据之间的预测性能,MAPE越小,模型的预测性能越好。
3. 基于BiLSTM模型的预测研究
3.1. 模型对比分析
通过对以往新冠肺炎传播趋势预测方法进行研究分析,可以将现有的方法分为传统动力学方法、时间序列预测方法、深度学习方法。我们发现,现有的方法均存在一定的缺点(见表1)。在现有方法中,深度学习方法是预测较为准确的方法 [4] - [9],但其依旧存在一定的缺陷。目前较多的基于深度学习模型预测新冠肺炎发展趋势是基于小样本数据进行训练,数据量和质量需要进一步提高。同时,不同地区政府的疫情防控措施相关因素的变化会对模型预测效果造成很大的影响,但在以往的对新冠肺炎发展趋势预测过程中未考虑到这些因素的影响。
本文针对上述缺陷,采用Our World in Data团队在GitHub中提供的数据集(https://github.com/owid/covid-19-data/tree/master/public/data),通过扩大数据量及加入政策性等其他因素的影响进行研究。在以往对新冠肺炎预测中LSTM模型预测性能优于传统动力学模型与时间序列模型,非常适合对新冠肺炎发展趋势进行预测研究,但LSTM存在对时间序列数据模型早期特征记忆效果较差,难以充分利用新冠肺炎传播趋势相关特征。因此,本文在LSTM模型的基础上提出基于多特征下的BiLSTM模型预测方法。
3.2. 数据预处理与特征选择
在本文中,所使用的数据集中包含少量缺失值,为避免缺失值对预测结果造成不必要的损失。本文在研究过程中使用填充法对缺失数据进行处理,当数据集中某个特征当天数据缺失时,我们使用前一天的该特征数据值进行填充。
相关分析可以衡量两个变量之间关联及其关系方向。相关值在[−1, 1]之间。相关系数越接近于1,变量之间相关程度越强;相关系数越接近于0,变量之间的相关程度越弱。本文使用最广泛的相关Pearson相关对数据特征进行相关分析,以下是用于计算Pearson相关性的公式:
(10)
通过对数据集中包含的所有特征进行Pearson相关分析(见表2),本文选取了与累计确诊病例(total cases)具有较强的相关性的十个特征进行预测分析。这些特征分别是:新增确诊病例(new cases)、核酸检测总数(total tests)、人口数量(population)累计死亡人数(total deaths)、接种的新冠疫苗加强剂总数(total boosters)、接种的新冠疫苗总数(total vaccinations)、至少接种一针疫苗人数(people vaccinated)、新增确诊7天平滑病例(new cases smoothed)、接种原始方案规定疫苗人数(people fully vaccinated)、累计死亡人数与往年同期百分比差异(excess mortality cumulative absolute)。

Table 2. Characteristic correlation analysis results
表2. 特征相关分析结果
在本文所选取的数据集中,选取的特征指标具有不同的量纲与数量级(见表3),从表3统计分析结果可以看出,各指标间的水平相差很大,特征指标之间得到差异会影响数据分析的结果,为消除特征指标之间量纲与数量级的影响、消除奇异样本数据造成的不良影响、缩短模型训练时间、加速loss下降速度、保证分析结果的可靠性,更好的拟合新冠肺炎数据之间的非线性关系 [11],需要对数据进行归一化处理。本文在研究过程中对原始指标数据使用‘MinMaxScaler’函数对数据进行归一化处理。MinMaxScaler函数表达式为:
(9)
其中,x*是特征归一化之后的数值,x是特征的原始数值,xmax为对应特征数据最大值,xmin为对应特征数据最小值。特征归一化处理结果见表4。此时从表4可以看出,通过归一化处理,所有特征数据取值范围在区间[0, 1]之间,在对区间[0, 1]内的累计确诊病例数进行预测后,进行逆运算,再次将其重新转换为相应的实际人数。
Table 3. Descriptive statistical analysis of features
表3. 特征描述性统计分析
Table 4. Descriptive statistical analysis of normalized characteristics
表4. 归一化特征描述性统计分析
对数据集进行预处理后,我们将数据集进行了划分,最后第30-60天作为验证集验证模型效果,将最后30天作为测试集,其他数据作为训练集。
3.3. 超参数与结构
经过多次实验,本文涉及到的模型由1个输入层、128个隐藏层和1个输出层组成,激活函数为Linear,迭代次数为1000,学习率为0.0005,批量处理大小为64。上一隐藏层的输出作为下一隐藏层的输入,输入层与隐藏层共同实现输入数据提取,最后一个隐藏层输出一维列向量,经线性回归处理后最终得到累计确诊病例预测值 [12]。
3.4. 实验结果与分析
新冠肺炎的流行对社会造成不利影响。在本文的研究过程中,我们设计了多特征下的BiLSTM模型与LSTM模型对比研究新冠肺炎在澳大利亚、中国台湾、南美洲、以色列四个地区的滞后7天、14天、21天、30天的累计确诊病例进行预测。如图3~图6分别表示了模型在四个地区预测7天、14天、21天和30天的预测累计确诊病例和实际累计确诊病例。从预测曲线(图3~图6)来看,BiLSTM模型在预测曲线上较LSTM模型与实际数据更贴合,且随着时间的推移,BiLSTM模型预测四个地区的累计确诊病例具有更好的效果。
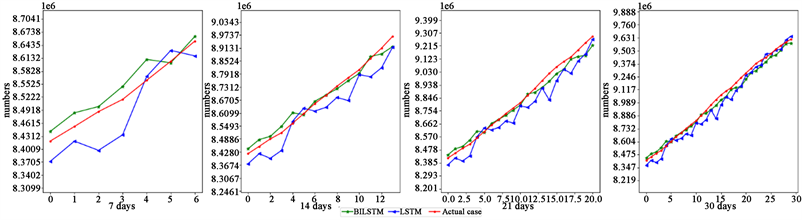
Figure 3. Predicted and actual cumulative confirmed cases in Australia at different times
图3. 澳大利亚在不同时间的预测与实际累计确诊病例
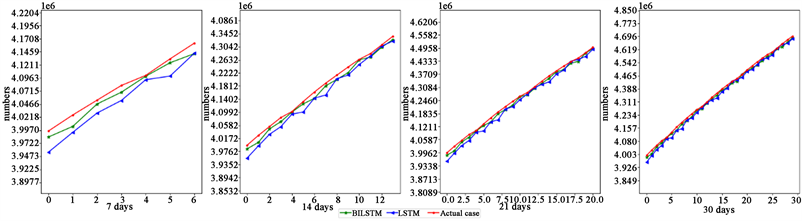
Figure 4. Predicted and actual cumulative confirmed cases in Taiwan, China at different times
图4. 中国台湾在不同时间的预测与实际累计确诊病例
通过计算2022年7月9日至2022年8月7日BiLSTM模型与LSTM模型的R2和MAPE,比较模型在测试数据上的相对性能,如表5所示。从表5中可以看出,本文研究的模型具有良好的性能,在不同的时间间隔预测中,BiLSTM在测试数据上的R2均高于LSTM模型,在测试数据上的MAPE均低于LSTM模型,说明多特征下的BiLSTM模型比LSTM误差更低,准确率更高。同时,随着预测时间间隔的增加,BiLSTM模型在测试数据上的R2有所提升,模型所对应的MAPE在0.0006%到0.0035%之间,模型相较于以往研究而言具有更大的R2与更小的MAPE,我们可以认为BiLSTM模型在预测新冠肺炎累计确诊病例上具有很好的预测性能。

Figure 5. Predicted and actual cumulative confirmed cases in South America at different times
图5. 南美洲在不同时间的预测与实际累计确诊病例
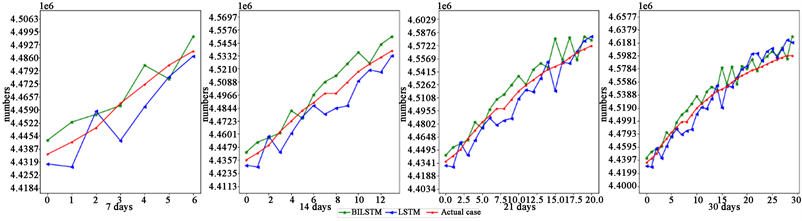
Figure 6. Predicted and actual cumulative confirmed cases in Israel at different times
图6. 以色列在不同时间的预测与实际累计确诊病例
Table 5. R2 and MAPE with various model from July 29, 2022 to August 7, 2022
表5. 2022年7月9日至2022年8月7日各模型的R2和MAPE
4. 结论与展望
在本文研究中,我们使用多特征下BiLSTM模型对澳大利亚、中国台湾、南美、以色列四个地区的新冠肺炎累计确诊病例进行预测并与LSTM模型进行比较。从评估指标R2与MAPE可以看出,多特征下的BiLSTM模型相对于以往的模型充分考虑到了防控措施动态变化对预测的影响,具有更好的预测性能。这些准确的预测可以帮助当地政府管理服务做出相应的决策,并且可能对未来流行病传播趋势的研究提供一定的方法。除了所研究的国家外,本文所提出的模型也可以应用于其他国家。
本文的工作还有进一步提升的空间,在后续的研究中可以考虑包括人口结构分布、流动人口系数等因素对新冠肺炎传播趋势的影响。
致 谢
感谢国家自然科学基金对本论文的支持,感谢给予引用权文献与数据所有者对本论文的论据支撑。
基金项目
国家自然科学基金面上项目(62076137)。
参考文献