1. 引言
1.1. 研究背景
温度产品一直以来都在不断追求预报精确度的提高,包括长时效预报和短时效的预报,用各种订正方法作用于不同的模式,寻求最契合实况的预报方式。随着科学的不断发展,气象预报技术的不断升级,温度预报的准确性也在逐渐提高。尤其是近年来,随着人工智能,机器深度学习等一系列新兴技术兴起后,都被融入到属于预报的工作中 [1] [2],类似分类回归,随机森林等机器学习方法被融入雷达观测的降雨预报之中,亦或者基于神经网络分析训练的订正方法诸如卷积神经网络、递归神经网络,对抗神经网络等,通过深度学习精细化预报效果。但是无论如何精细化,仍然与实况温度存在着误差 [1] [3] [4],以GRAPES模式为例,就去年2021年全年预报温度与实况温度对比,温江站地区的预报温度和实况温度最大残差可达7℃以上,对此,本文试图寻求订正方法。
对于GRAPES存在的观测异常亦或者运行失常的情况,现有研究显示 [5] [6],主要原因集中在两种情况:1) T213的资料没有收集全,由于GRAPES模式下不同时刻和不同的等压面均有文件,所以大量的数据文件,容易导致资料缺失,弥补该问题的插值补齐方法难以应对最后一个资料缺失的情况,进而导致GRAPES模式运行失常。2) 异常停止了三维变分同化模块,未曾生成分析场;亦或者在主模块的积分过程中异常停滞,导致没有生成全面的预报结果。
对于GRAPES预报模式的预报偏差,目前现存的基于个别站点的订正方法有空间局限性,而选择基于格点进行分析,则有较好的普遍性和参考价值。除了模式本身存在的缺陷,初值场的不确定性也会导致数值模式预报存在误差对于以上两点存在的问题,选用合理的插值算法对初值场减小误差,再利用误差订正技术对数值预报产品进行解释应用,可以有效地提高预报数据的准确度。
1.2. 研究现状
目前,GRAPES_Meso和SCMOC均为气象预报提供了参考模式,其中,全球中期数值预报系统(GRAPES-GFS)和区域中尺度预报系统(GRAPES-MESO)为我国具有独立知识产权的数值天气预报业务系统。在此基础上开发的GRAPES全球和区域台风预报系统、海浪预报系统、集合预报系统以及环境模式,可为气象防灾减灾及行业用户提供重要支撑。GRAPES_Meso自2006年投入运行以来,在科技水平不断提高的过程中,其时空分辨率和预报水平也得到了很大的提高 [7],但是其预报温度与实况温度相比总体而言呈现偏高的状态,需要采用合理的订正方法对其预报精确度进行提升 [8]。
现有的订正算法中,一元线性拟合订正算法 [9] [10],是在最小二乘法的基础上,以追求总体上最佳距平值的为前提,寻求最佳的拟合函数 [11]。但是在实际情况下,线性拟合的状态是一个理想化的状态,粗略地将自变量与因变量之间的变化看作是线性变化容易造成拟合结果有极大的误差,最终导致部分异常大值的出现,尤其是在气象数据中,初值场本身就有较大的不稳定性。因此考虑使用样条拟合,三次样条拟合是在原有的数据关系基础上,对自变量定义域进行重新划分,除去异常值重新拟合函数,在保证拟合结果的方差的基础上,也能估计到自变量与因变量之间的非线性关系。
不过在实际操作过程中,三次样条拟合应对较小的自变量函数区域上,极多的数值点时,很难做到拟合函数拟合效果好的基础上,仍能保持拟合函数的光滑,对此,便不得不舍弃部分数值点 [12]。本文采用的数据,在−1℃~33℃的范围内共有8760个数值点,故简单地使用三次样条拟合极容易造成大量数据点丢失 [13],最终本文选择在第一遍对预报数据做完拟合曲线后,设置隐藏层计算方式 [14],参考现行的诸多优秀订正算法如:最优集合预报订正方法 [15],一元线性回归法,卡尔曼滤波法 [8],MOS神经网络分析训练,对拟合曲线进一步进行神经网络分析训练,弥补其中的数据损失值,尽可能提高最终的订正算法的可信度。
1.3. 研究意义
温度产品的预报误差,会极大地影响人民群众的生活质量,进而会使人们质疑气象预报的可信性。同时温度产品还影响各行各业,其中尤其是精细化的工作,如:火箭发射,大型会议召开。针对性的观测探查,这些工作均对温度产品的精确度有着极高的要求。因此,对现有的GRAPES模式下的温度产品进行合理的订正,以提高其精确度,是当前诸多实际工程的现实需求。与此同时,每一次对预报温度精确度的改善提高,都是气象预报发展的一份助力,寻求更优的订正方法,是对于提高我国气象预报精确度做出一份贡献。
气候序列中个别时间段亦或者个别等压面上由于非自然原因造成的系统偏差,诸如包括台站迁移、观测规则、观测仪器改变、卫星更替等。这些因素可能会导致误报气候变化或其影响的定量评估,也会影响气候变化的原因探索。均一化即检测和校订时间序列中的非均一性,所谓非均一性,即认为两段数据之间的统计特征不一致了,比如均值和方差误差很大。几乎所有长期气象观测序列都混杂有多种非均一性,难以通过特定物理校订进行全面的均一化。由于上述原因,导致风速的观测值明显减小,造成资料的非均一性。为了使得较长时间段的风速资料保持统一,通过均一性订正,能去除城市化的影响。
现有的气象预报数据订正方法普遍以一元线性回归拟合为主,该订正算法有效避免了预报温度在长期预报时的不稳定的影响。但是在短期预报中,线性拟合订正算法容易舍弃部分数据,最终导致拟合结果在部分时间段有异常大的残差。针对此情况,本文考虑了三次样条拟合,对拟合结果做神经网络分析训练,进一步减少部分时间点,异常大残差给气象预报带来的误差。
2. 资料和方法
2.1. 数据资料
本文中,预报数据采用的是GRAPES模式下的grib文件资料,这些温度产品的是GRAPES_MESO区域集合预报业务系统产生的东亚区域模式预报产品。模式产品空间分辨率10 km,时间分辨率3小时。预报时效最高72小时,要素包括气压、位势高度、温度、假相当位温、温度露点差、风的u、v分量、垂直速度、相对湿度、降水量、水汽通量、水汽通量散度等。数据资料每天发0和12时次。采用grib文件,因为是基于格点分布,有效地提高了预报数据的普适性。
GRAPES_MESO中国及周边区域数值预报产品,主要针对的是东亚地区的气候数据观测,实时预报。自2015年12月29日开始获取数据至今,更新频率为1天2次。资料来源于中国气象局数值预报中心GRAPES区域集合预报系统。该模式对于强降水等强天气过程具有一定的预报能力,特别是高时空分辨率的产品能够在一定程度上较好地描述过程的发生发展。
采用的实况数据为ERA5数据文件,ERA5是欧洲天气预报中心的最新产品。ERA-Interim是再分析数据,其中提供有提供两套数据,一个是同化分析数据,一个是预报数据。
同化分析数据,以6小时的时间间隔,每12小时循环一次。例如,0、6、12和18UTC 分别产生一天四次的数据,而事实上,同化分析数据在12UTC时做过一次误差校正。
再分析数据是通过对各种来源(地面、船舶、无线电探空、测风气球、飞机、卫星等)的观测资料进行质量控制和同化处理,而获得了一套完整的再分析资料集,与观测资料相似度较高。
2.2. 研究方法
本文主要采用残差来评价订正方法的可信度,首先是原始数据经过Kriging插值后的温度与实况温度的残差,在随后的订正方法中,分别有线性拟合 [16],三次样条拟合,神经网络分析后的订正值与实况的残差,选取残差总体较小,过大异常值少的方法作为更优的订正算法。
三种订正方法的参数如下:
1) 线性拟合的斜率k以及截距b,均依赖于距平值分布确定最契合所有点的曲线。对于自变量x和因变量y的函数关系
,当该函数是为关于b的线性函数时,称这种拟合方法为线性拟合 [17] [18]。本文中的线性拟合选用基于距平值确定斜率和截距的方法。
最终结果的评估参数有总体平方和(SST,用于评价整体距平值)和误差平方和SSE,二者之差是回归平方和(SSR),拟合优度(R²)综合体现SSR和SST。R²越接近1,意味效果越好,拟合数据更接近于实况。
2) 三次样条拟合,是对于原有的数据点,进行一次、二次、三次拟合确定各点间的曲线,然后对自变量区间重新划分,最终呈现出最合适的拟合曲线且曲线凹凸性无突变 [19] [20] [21]。本文中较小的自变量范围内(−1.4℃~34.7℃)有大量的数据点(8760个),该因素可能是导致最终拟合误差较大的因素。3) 在神经网络分析训练中,根据输入数据中的重要性(赋予权重),通过激活函数后进行拟合。输入值、权重和激活函数会产生不同的影响 [22]。
本文采用的是前向神经网络,通过对单个神经元的输入层数据进行训练,拟合出最佳的曲线 [23]。选用多层感知器,设有一层隐藏层(SDG算法),针对输入数据,先进行线性的训练,再拟合部分异常值,尽可能确保最终拟合结果在整体上没有过分异常的数据,而后呈现出较符合实况数据的拟合数据。
3) 评分标准,本文中采用的温度预报温度评分标准公式为:
预报准确率:
(1)
其中,
表示站点的预报温度,
表示站点的实况温度,K为1, 2,分别指代预报温度与实况温度的差值小于1℃或2℃,这就是本文中展现订正方法拟合水平高低的残差值,将作为评分体现各个订正方法的优劣,
表示预报准确的次数,
表示预报总次数。
3. 三种订正方法的拟合结果
本文采用的线性拟合方法的拟合公式为:
(2)
由此最终确定的R²为0.7左右,误差较小,该订正方法可以有效提高预报数据与实况数据的拟合程度。
而本文中的神经网络训练拟合分为两步,第一步做3000次线性训练;第二步做(5000次)精细化拟合训练,尽可能保证其曲率光滑。对应的数据损失函数如图1。
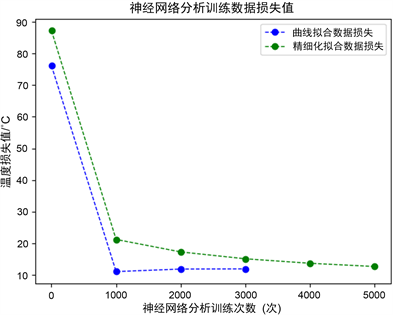
Figure 1. Training process of neural network
图1. 神经网络训练过程
3.1. 不同订正方法的拟合曲线和实况分布
如图2(a)所示,为了拟合距平的最佳曲线,线性拟合会舍弃部分点,出现与实况残差数值较大的点。其中,实况数据整体分布于拟合曲线两侧,且靠近拟合曲线,实况数据亦为分布密集区,但有少量的零星实况数据点较为离散。
受限于预报数据中,在−1.4℃~34.7℃的范围中,为了拟合效果,仅选择一次样条。样条拟合曲线与实况数据分布如图2(b)所示。样条拟合曲线并未覆盖的点主要是低的观测温度或预报温度比观测值低,即三次样条拟合在高温区域的拟合效果较差。
与线性拟合和三次样条拟合相比,神经网络分析训练后拟合曲线(图2(c))的曲率变化,更加贴近实况数据分布的密集区,在线性训练基础上的进一步拟合,大大提高了拟合曲线的拟合效果。
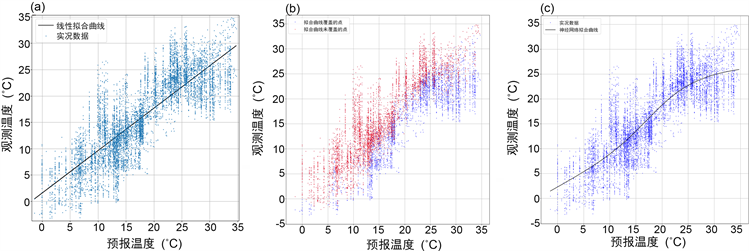
Figure 2. The curve of (a) Linear fitting, (b) Spline fitting, (c) Neural network fitting and live data distribution
图2. (a) 线性拟合、(b) 样条拟合和(c) 神经网络训练拟合的曲线与实况数据分布
3.2. 不同订正方法的残差分布图
经过线性拟合后(图3(a)),拟合数据残差的主要分布,集中于−3℃~3℃这一区间,相比起原先的插值数据仅有1℃~2℃这一区间分布较为密集;整体上拟合数据都更加贴近实况,能有效提升实际的预报效果。样条拟合后的残差分布(图3(b)),聚集在0℃附近,即多数实况–预报数据点的残差较小;但因数据损失,残差异常大值也增多。神经网络分析(图3(c)),在线性训练后进行再拟合,故不仅确保了残差主要分布在0℃附近,也有效规避了异常大值的出现。
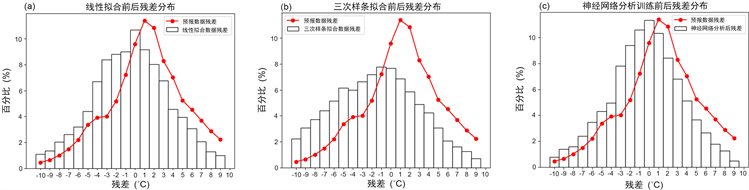
Figure 3. Residual distribution of (a) Linear fitting, (b) Spline fitting, (c) Neural network fitting
图3. (a) 线性拟合、(b) 样条拟合和(c) 神经网络训练拟合的残差分布
4. 比较各种订正方法的优劣
4.1. 订正前后残差对比
线性拟合和三次样条拟合订正后残差对比情况如图4所示,横坐标为预报数据与实况数据的残差,纵坐标为拟合数据与实况数据的残差。
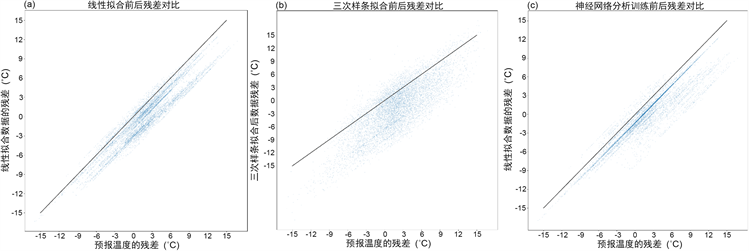
Figure 4. Residual of (a) Linear fitting, (b) Spline fitting, (c) Neural network fitting
图4. (a) 线性拟合、(b) 样条拟合和(c) 神经网络训练拟合的残差
残差点均在线性拟合合三次样条的正比例函数线下,整体残差减小,即预报效果有所提升。但是不同在于:1,线性拟合后,残差点集中在0℃附近,向两边逐渐稀疏,即残差值较小。而三次样条函数拟合后,部分残差点在±15℃外,引起预报误差;2,在线性拟合中,残差增大的点集中在0℃附近,订正引入的误差不明显。但三次样条拟合,订正后残差增幅3℃~5℃,引起更大误差。故线性拟合优于三次样条拟合。
由图4可以发现线性拟合后,残差从正比例函数曲线下移长度不等,分布较乱,但是神经网络分析训练后,残差点密集线集中在正比例函数曲线向下1℃左右,即神经网络分析训练订正后的效果比较统一,订正效果较为稳定。
4.2. 残差分布
如前文所述,线性拟合,三次样条拟合,神经网络训练分析均在原预报函数的基础上,有效地将残差分布的密集区向0℃附近聚集,如图5所示,三者对于数据订正均为有效且有不足。
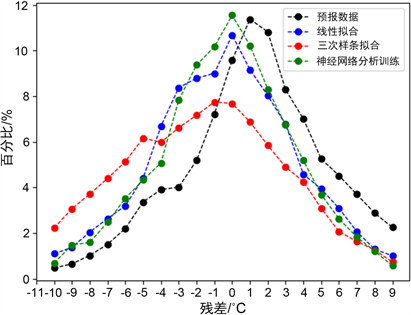
Figure 5. Comparison of three correction methods and residual distribution of original forecast data
图5. 三种订正方法及原预报数据的残差分布对比
图5中,三种订正方法均为残差较小的区域拟合值点密集,其中神经网络分析的小残差占比最高,在−2℃~2℃的残差区间内,每个小区间值点占比均比线性拟合高2~3个百分点,这意味着神经网络训练分析的拟合结果整体上以残差小值为主,极为贴近实际数据。同时,注意到在残差大值区域,尤其是在残差超过−5℃的几个小区间内,容易因拟合引入其他误差。
三次样条拟合残差分布较为扁平,
相比起原来预报数据的残差(黑色点虚线),残差分布的最密集区从1℃~3℃转移到了−1℃~2℃,意味着整体上残差数值变小了,三个订正方法均为有效,但神经网络分析最佳。
对此,令−2℃~2℃区间为残差小值区,T ≤−5℃或T ≥ 5℃的区间为残差大值区间,三种订正方法的各自占比如表1所示。

Table 1. Proportion of small residual error and large residual error in the three correction methods
表1. 三种订正方法中残差小值,大值占比
神经网络分析训练的残差小值占比最高,残差大值占比最低,故神经网络分析训练的订正效果更佳。
4.3. 评分效果
在采用了与实况残差1℃,2℃的评分标准后,原插值数据的评分以及三种订正方法的评分如图6所示,评分结果见表2。
经过订正后,线性拟合与神经网络分析训练的评分均提高,但由于三次样条拟合在面对较小的自变量范围内大量的数据点时,容易因为自变量的变化趋势迅速改变,引起三次样条拟合数据遗失过多,TT1评分有所降低。

Figure 6. Scoring results of each revised algorithm
图6. 各个订正算法评分结果
Table 2. Specific scoring data of each revised algorithm
表2. 各个订正算法具体评分数据
本次实验中,与实况观测数据,通过TT1和TT2综合评分对比,神经网络分析训练的订正效果更佳,拟合后的数据更为贴近实际数据。
5. 结论
总结全文,本文中采用的数据是针对具体地温江站附近,2021年全年的温度数据,故结果是在一个较小的范围内,分析的数据量较大。三次样条拟合显然在三种订正方法中效果最差,这主要是因为三次样条拟合对于大量数据点之间迅速的变化率改变难以有效适应,导致过多的数据点遗失,最终拟合效果甚至比之Kriging插值后的预报数据尚且不足。
而线性拟合与神经网络分析训练两种订正算法。线性拟合是在兼顾整体的方差,采用了线性回归,确实能提高整体的预报准确率,但是因为初值场本身变化、部分范围内数据分布分散,导致线性拟合的拟合效果差异较大。神经网络分析训练进一步能提升效果,均匀地减小残差数值,方便了预报实际操作。同时,神经网络分析训练很大程度上拟合了预报数据中的异常值,最终残差的大值极少,近半数偏差在±2℃以内,提升了预报准确度。故神经网络分析训练有效提升GRAPES模式的预报准确率。