1. 引言
中药材的产地对于衡量药材的品质尤为重要,是大众比较关心的问题。由于中药材的种类较多且不同地区名称也可能不同,导致中药材的产地难以鉴别。传统中药材鉴别方法很多,如来源鉴别、性状鉴别、显微鉴别、理化鉴别等,这些鉴别方法效率较低,鉴别准确度不高。DNA分子和色谱鉴别对中药材的鉴别准确率极高,但存在预处理较为复杂且分析的时间长、成本较高、操作繁琐,快速鉴别较难等不足。现如今的研究有:文献 [1] 将系统聚类方法运用至光谱分析;文献 [2] 采用监督分析法构建分类模型;文献 [3] 利用光谱指纹图谱对僵蚕进行鉴定;文献 [4] 采用质谱数据对中药材进行鉴定。本文主要研究根据中红外光谱数据鉴别中药材种类的分类模型的基础上进一步考虑提取近红外光谱数据的不同产地中药材在光谱数据中的差异性特征,提高中药材产地鉴别分类的精准度。对此,本文的研究有利于进一步贡献丰富中药材鉴定的研究结果、研究方法、理论基础。
2. 数据来源与分析
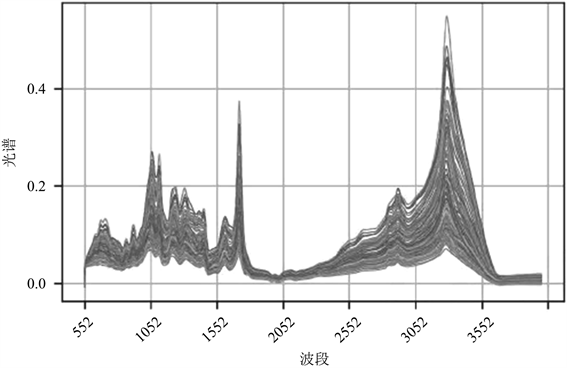
Figure 1. Mid-infrared spectral data plot
图1. 中红外光谱数据图
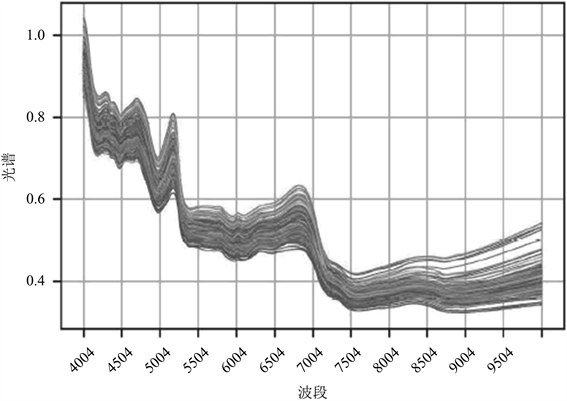
Figure 2. Near-infrared spectral data plot
图2. 近红外光谱数据图
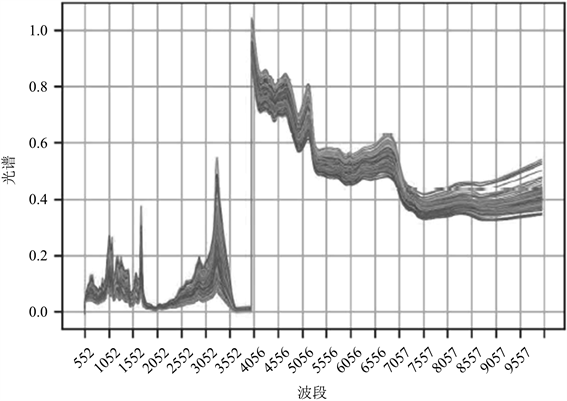
Figure 3. Combined mid-infrared spectra
图3. 中近红外光谱合并图
本文以2021年“高教社杯”全国大学生数学建模竞赛E题“附件3”的基础数据为研究对象,“附件3”中提供了255个中药材基础样本数据,其中No列为药材的编号,OP的名单显示了这种药材的来源。其它列第一行中的数据是光谱的波数(单位cm−1),第二行后的数据表示暴露于相应波段的编号药材的光谱吸光度(552~3999 cm−1 4004~10,000 cm−1) (见图1~3)。其中,245个样品为已知来源(编号为1至17),10个样品为未知来源。对附件3中的数据进行预处理,检查是否存在缺失值、是否存在异常值、是否存在大量重复值,通过处理明确了每条记录有光谱波数552 cm−1至3999 cm−1共878,985个数据项,光谱波数4004 cm−1至10,000 cm−1共1,528,980个数据项,均未发现大量重复数据和异常数据,光谱波数列中未发现缺失数据。表示产地的OP列除去需鉴别场地的17个缺失项外也无缺失项,数据完整性良好。
3. 分类模型
3.1. 欧式距离
欧几里得度量也称为欧氏距离 [5] ,是一种常用的距离定义和最常见的距离测量,它测量多维空间中点之间的绝对距离。它是指m维空间中两点之间的实际距离,或向量的自然长度(即点到原点的距离)。二维和三维空间中的欧氏距离是两点之间的实际距离。在计算相似性的场景中(例如人脸识别),欧氏距离是一种更直观和常见的相似性算法。欧氏距离越小,相似度越大。欧氏距离越大,相似度就越小。本文主要使用其算法来识别中红外光谱中药基础数据的相似度。欧氏距离的数学公式如下:
3.2. 支持向量机模型(SVM)
由于支持向量机 [6] 能够适应小样本的分类,因此分类速度快,其性能不低于人工神经网络 [7] 。因此,人们将SVM应用到各个领域。大量使用SVM模型的论文不断涌现,包括国内外基于固体统计理论的支持向量机。它是所有已知数据挖掘算法中最精确的方法之一,具有良好的学习能力和泛化能力。因此,使用支持向量机求解未知来源药材记录的模型是一种合适的方法。支持向量机的主要思想是找到一个超平面使其尽可能多的将两类数据分开,同时使两类数据点距离分类面最短。假设给定一个特征空间上的训练数据集
其中,
,
,
,
N表示为有N个样本实例,Xi则表示为第i个特征向量,
该假设的目标是要从中提取出一个分离超平面,并将正负类分别分在该超平面的两侧。
分离超平面的对应方程可写为:
当给定的训练数据值处于线性可分的状态时,存在无数个这样的分离超平面,感知机利用误分类的点来求解,则有无数个解。
SVM可以通过最大化间隔来获得最优超平面和唯一解。
假设分类决策函数为:
4. 结果分析
4.1. 欧式距离结果
从图1~3可知来自17个产地中药材的中近红外光谱数据图整体趋势差别不大,不同产地的药材吸光度差异较小,其数据曲线贴合度较高。本文对附件3中近红外光谱数据(见图4)、中红外光谱数据(见图5)、中与近红外光谱数据(见图6)进行一阶平滑处理,处理后图像如下。
Figure 4. First-order smoothing of near-infrared spectral data
图4. 近红外光谱数据一阶平滑处理后

Figure 5. Mid-infrared spectral data after first-order smoothing
图5. 中红外光谱数据一阶平滑处理后
Figure 6. Near-infrared spectral data after first-order smoothing
图6. 中近红外光谱数据一阶平滑处理后
我们定义,当一个光谱波数区间
上每个光谱波数
在所有药材记录中的吸光度Ai最大值减去最小值(即极差)大千所有波数吸光度的平均极差。则称该区间为特征区间 [7] 。记为
,即:
通过Python所计算出的结果,显示在附件3光谱波数区间共有六个特征区间,总长度为3005,即包含3005个不同且连续的光谱波数(区间与区间之间波数不连续)。在寻找到特征区间之后,以光谱波数作为x坐标,以吸光度作为y坐标。把我们将要分类的10条药材记录与已分类的245条药材记录在特征区间上计算曲线间的欧式距离,
使用Python计算出未分类的10条药材记录与已分类的245条记录之间的距离矩阵如下(见表1~3)。

Table 1. Near-infrared spectroscopy
表1. 近红外光谱矩阵
Table 2. Mid-infrared spectral matrix
表2. 中红外光谱矩阵
Table 3. Near-mid-infrared spectral matrix
表3. 近中红外光谱矩阵
将10条未分类药材记录与已分类的药材记录对比,若两者之间的欧式距离最小,则可以认为二者的光谱波数数据曲线在特征区间上重合度较高,即二者极大可能产自同一产地,光谱波数数据(见表4、表6、表8)。
筛选近红外光谱数据得到重合度最高的光谱数据与初步得出对应的产地为下(见表5、表7、表9)。
Table 4. Symmetry curve of coincidence degree is obtained from near-infrared spectral data
表4. 近红外光谱数据得到重合度对称曲线
Table 5. Preliminary origin identification based on near-infrared spectral data
表5. 根据近红外光谱数据初步产地鉴别
筛选中红外光谱数据得到重合度最高的光谱数据与初步得出对应的产地为下。
Table 6. The symmetry curve of coincidence degree is obtained from the mid-infrared spectral data
表6. 中红外光谱数据得到重合度对称曲线
Table 7. Preliminary origin identification based on mid-infrared spectral data
表7. 根据中红外光谱数据初步产地鉴别
筛选近中红外光谱数据得到重合度最高的光谱数据与初步得出对应的产地为下。
Table 8. Symmetry curve of coincidence degree is obtained from the near-mid-infrared spectral data
表8. 近中红外光谱数据得到重合度对称曲线
Table 9. Preliminary origin identification based on near-mid-infrared spectral data
表9. 根据近中红外光谱数据初步产地鉴别
4.2. 支持向量机(SVM)结果
本章节为作者提供“资助信息”的示例。通过欧式距离可以初步确定10种未分类药材记录的来源。为了提高识别的准确性,使用支持向量机求解来源不明的药材记录模型。
我们选择LLE降维方法 [8] ,局部线性降维。经过反复的参数调整,我们将数据维数降低到35维。这不仅保留了原始数据的主要特征,而且充分减少了计算量。
对于输入空间中的非线性分类问题,可以通过非线性变换将其转化为维度特征空间中的线性分类问题,并且可以在高维特征空间中学习线性支持向量机 [9] 。
输入训练数据集 [10]
输出分类决策函数;
选择适当的核函数
和惩罚参数C > 0来构造和求解凸二次规划问题:
使得:
得到最优解
计算,选择
的一个分量
满足条件
,
计算
分类决策函数:
调用python的sklearn库 [11] 中的函数SVC计算,将已知的数据分为训练集与测试集,通过反复调参,最终近红外光谱的模型在训练即使达到了91.9%的正确率,而且在测试集上达到98.0%的正确率。
中红外光谱的模型在训练集达到了86.5%的正确率,而且在测试集上达到98.3%的正确率。
近中红外光谱的模型在训练集达到了83.8%的正确率,而且在测试集上达到98.7%的正确率。鉴别出未知中药材产地如下(见表10)所示。
Table 10. Preliminary identification results of unknown medicinal materials
表10. 未知药材产地初步鉴别结果
因为支持向量机(SVM)被用来发现在不同的数据集上获得的结果并不完全相同,并且其在再训练集和测试集上的准确性是相同的。最后,使用从特征间隔差异较大的中红外数据获得的结果来校正从近红外数据和连接表数据得到的结果。综合考虑,最终得出以下结果(见表11)。
Table 11. Final identification results of unknown medicinal materials
表11. 未知药材产地最终鉴别结果
5. 结论
传统中药材鉴别方法有很多,如来源鉴别、性状鉴别、显微鉴别、理化鉴别等,这些鉴别方法效率较低,鉴别准确度不高。DNA分子和色谱鉴别对中药材的鉴别准确率极高,但存在预处理较为复杂且分析的时间长、成本较高、操作繁琐,快速鉴别较难等不足,而支持向量机(SVM)算法具有可用于线性或非线性分类,也可以用于回归,泛化错误率低,具有良好的学习能力且学到的结果具有很好的推广性。也就是说具有低成本、高效性且鉴别精度较高的特点。本文对原始数据进行了一阶平滑处理并且运用欧氏距离初步鉴别出中药材产地,之后进一步将原始数据进行降维处理,形成了包括原始数据在内的不同数据集利用机器学习中的支持向量机算法(SVM)进行鉴别分析,比较充分地衡量出不同中药材产地之间的差异性与区分度,为今后的中药材产地鉴别提供了一种新思路。
基金项目
ZY2022QNCX01 (青年创新人才项目)。