1. 引言
消费者在购买平台挑选衣服时不仅仅讲究是否合体,而且对衣服的款式、展示的风格有着更高的需求。用户也更偏向于选购自己喜欢的风格的服装。近年来对服装的检索多是基于用户购买历史数据来为消费者推荐服装 [1],如果消费者没有历史购买数据,或者数据较为杂乱,那么如何在没有这些背景信息的情况下了解服装风格不但能够帮助消费者选择衣服,而且能够协助设计者和制造商更好地设计消费者所要求的衣服。识别一件服装的风格是十分具有挑战性的,近年来,一个较为普遍的办法是将服装预定义为如图1所示,类似a:学院风,b:休闲风,c:朋克风等类型的风格集。最近使用该方法的是 [2] [3] [4],风格集是一些不同类别但风格相似的集合。但是使用人工来预定义风格的方法,几乎不可能精确的定义一组足以描述风格这种微妙的属性,在大量投入工作量的同时,还可能出现错误的风格分类。另外还有研究者通过主题模型来分析一件服装潜在的风格 [5]。然而这些研究只是为消费者识别出服装的风格,而我们要做的是为消费者找出风格相似或者风格兼容可搭配的其他服装单品。
在本文中,借鉴 [6] 在家具风格上的思想,我们提出了一个文本风格检索模型来检索相似的服装风格,将一整套服装集作为一个风格集,使用词向量模型Word2vec的思想,其中里面的每一件服装单品文本描述作为中心词,与之同一个风格集中的其他服装单品作为其上下文信息,将这些信息输入模型进行训练,获取到最终的模型。由于文字可表达的信息有限,本文另外提出一个图像风格检索模型,使用Vgg16提取图像特征,将选取的服装单品图像表示为一个向量,将同一风格兼容集的其他上下文项目映射为其权重向量。利用softmax函数将目标项向量与各上下文权重向量的内积化为概率,训练整个网络使概率之和最大化。最后,提出一个多模态融合模型,将文本与图像风格检索所获取到的特征进行融合,利用融合特征进行相似性检索。通过该模型在一个多模态数据集上的实验结果来看,本文提出的结合多模态特征融合的服装风格检索模型所得到的检索结果相较于单模态以及其他的多模态混合方法所获取的检索结果更佳。
2. 相关知识
2.1. 卷积神经网络
卷积神经网络是为了处理图像而生,其设计原理是把图像转换为像素值数字矩阵,由此,将图像转换为计算机可识别的形式,从而得到图像相应的具体特征空间。卷积神经网络由于引入权值共享和局部感受野等特性,可以在保证网络鲁棒性的前提下,使用卷积方法大大减少计算步骤。池化层可以有效的减小参数矩阵的尺寸,可以加快计算速度和防止过拟合的作用,全连接操作就是将不同维度特征连接在一起,整合特征提取层获取的较为重要的权重信息。如图2所示,这就是一个典型的神经网络结构。
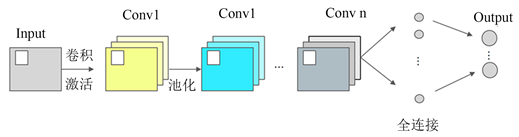
Figure 2. Convolution neural network diagram
图2. 卷积神经网络图
2.2. Word2vec模型
Word2vec [7] 将词汇表中的每个词表示为一个嵌入空间中的低维密集向量,并尝试从训练语料库中学习词向量,通过词之间的空间距离衡量词之间的相似性,例如,两个词在所表示的嵌入空间中越近,它们在语义和语法上就越相似。这些单词表示是基于分布假设学习的,该假设上下文相似的单词往往具有相似的含义。在这种假设下,word2vec提出了两种不同的模型架构:上下文Bag-Of-Words (CBOW)和跳字模型Skip-Gram with Negative Sampling (SGNS),用于从周围上下文中预测目标单词,接下来对CBOW做介绍:
CBOW模型共有三层结构,如图3所示,分别是输入层 Input layer 、隐藏层 Hidden layer 、输出层 Output layer。该模型的具体的计算过程如下描述,将目标词的上下文中的词的独热编码首先输入输入层;然后在隐藏层中,将输入的这些词同时乘以同一个矩阵后,将不同词得到的向量通过加权平均得到一个向量,最后将这个向量乘以矩阵后得到最终的一个向量。在输出层是一个softmax回归分类器,将最终得到的向量经过softmax归一化后,在该层的每个结点将会输出一个概率向量,将预测值最高的向量作为预测的结果向量,将其与该词的真实标签向量做误差计算。一般使用交叉熵损失函数来做计算,在经过每次前向传播与反向传播误差,从而不断变换上述中和的值。使得结果向量与真实标签向量误差最小化,在进行预测时,通过向前传播可以得到预测的中心字的结果。
由于softmax做计算比较复杂,使用负采样方法提高计算效率。负采样的思路是将由上下文词生成中心词或由中心词生成上下文词的过程拆分为两种独立事件的组合:正样本事件和负样本事件。
在CBOW模型中,假设每个词都用维度为d的向量表示,从数据集所得词典为
。对从词典中于所选中的第i个目标词,使用
和
表示第i个词的上下文词和该词的向量表示。假设由上下文词
生成中心词
是由两种独立的事件来近似,而:
正样本事件:上下文词与中心词出现在同一个窗口内,概率
;
负样本事件:上下文词
与噪声词
同时出现在窗口内,噪声词
按指的是非上下文词对应的中心词,其分布
由随机生成。设噪声词
在词典中的索引为
,因为噪声词也可以是中心词,则噪声词
的向量可表示为
,则概率可以写为
。
所以
可以改写为正样本事件与负样本事件的联合概率,如式(2-1)所示:
(2-1)
其损失函数为式(2-2)所示:
(2-2)
3. 模型介绍
3.1. 英文缩写
为了实现利用词向量模型进行风格检索的功能,借鉴 [6] 的思想,选择使用Word2Vec [7] 中的连续词袋模型(Continuous Bag-of-Words, CBOW),由2.2中介绍的其原理,类比于cbow中的中心词与上下文信息,将每一件服装单品的文本描述作为一个中心词,一套风格兼容集中的其他服装单品文本描述作为这个词的上下文信息,如图4所示,用该风格兼容集中服装图像的文字描述来形成上下文信息,按照CBOW模型的思想先把上下文信息输入输入层中,再将中心词作为输出向量,来训练CBOW模型。得到这样一个训练好的模型之后,利用这个模型来计算风格相似度。总结来说,如果两件服装单品出现在一个风格兼容集中,那么它们的风格是相似的,如果两件服装单品不在同一兼容集中,但是它们所在的风格兼容集里其他服装单品是相同或者相似的,即对应CBOW里有相同或者相似的上下文信息,那么两个服装单品也是相似的。
3.2. 基于图像的风格检索模型
基于文本所表达的特征有限,本文另外训练一个基于图像上文风格检索模型,参考3.1中词向量检索风格的概念,在使用图像检索相似风格任务时,使用两个经典的Vgg16网络模型,一个用于将选取的服装单品图像投影为一个表示向量,另一个用于将同一风格兼容集的其他上下文项目映射为其权重向量。利用softmax函数将目标项向量与各上下文权重向量的内积化为概率,训练整个网络使概率之和最大化。具体来说,让图像中第i个项目为
,将两种类型的网络参数化,对于输入的图像
定义为
,对于上下文项目
定义为
。两个网络使用相同的VGGNet结构,两个网络不共享参数,因为这两个网络具有不同的目的。两者的目标是学习
和
,使项目在样式集中同时出现的对数概率最大化。设F为所有时尚单品的集合。假设的训练数据集
中的每个风格集S都具有一致的风格。迭代S中的i项作为输入,S中除了i之外中的项作为上下文项。模型的总体目标是最大化D中每个S的平均log概率。公式如式3-1所示:
(3-1)
其中
and
。
与文本计算一样,由于计算softmax计算量非常大,因此同样也引入负采样的思想,随机选取k个不同于训练样本S中的项目,对每个(i, c)形成负样本集
,将目标函数变成如式3-2所示:
(3-2)
使得同一风格集中使用图像进行检索时也能获取到其同一风格兼容集中的图像,同时,也能使得两个有相似上下文信息的服装具有风格相似性。服装图像风格检索模型如图5所示。
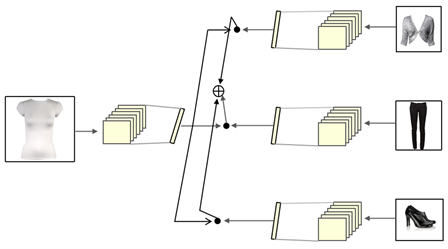
Figure 5. Image style retrieval of clothing
图5. 服装图像风格检索图
3.3. 基于多模态融合的服装风格相似性
多模态服装风格检索模型如图6所示:分为三个模块,第一个为特征提取模型,分别使用Vgg16模型提取图像特征,使用Word2vec中的CBOW模型获取文本特征,在特征融合模块,最后将两者特征使用一种特征融合的方式,即级联,将获取的两者特征融合。最后相似性检索模块中,softmax层通过计算,对最终结果进行预测,按照预测的相似度值的高低,返回预测检索结果列表。
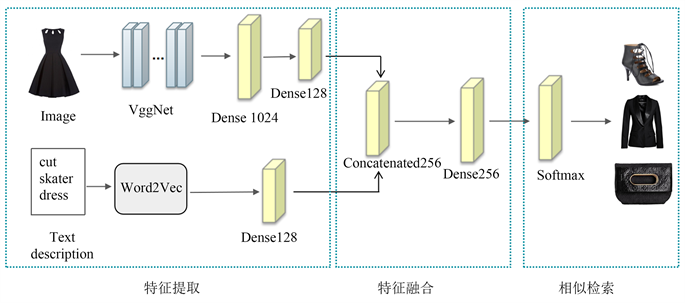
Figure 6. Multimodal clothing style search diagram
图6. 多模态服装风格检索图
4. 实验
41. 实验概况
对于利用文本进行风格相似性检索时,采用word2vec中的CBOW模型,将数据集中服装单品文本描述看作是一个单词,将一套服装的文本描述看作是一句话,如此来训练该风格检索模型。同时用负采样方法对模型中的复杂计算进行加速,词向量维度设置为400,窗口大小设置为为5,和其他文本分类任务不同,本实验对于所有出现过的单词都考虑进去。
对于本文提出的图像风格检模块,使用经典的Vggnet作为特征提取器,Vggnet的结构5层卷积层、3层全连接层和softmax输出层构成,每个层与层之间使用最大池化层分开,所有隐藏层的激活单元都采用ReLU函数。通过CBOW的思想对网络进行训练,最终将图像映射为一个1024维向量。网络模型中使用自适应矩估计(Adaptive Moment Estimation)优化器以及批归一化(Batch Normalization)进行训练,收敛速度较快且相对稳定。
4.2 数据源
训练和测试数据来自Polyvore数据集 [8]。该数据集中共收集了21,889套服装,每一套服装的里面有单独的服装单品对应图像,一套服装里平均有5个服装单品。此次实验训练集样本和测试集样本划分为训练集17,316套服装,测试集4573件。每一件服装单品在其套装都有相应的图像和文字说明。
4.3 评估指标
相似性评分:在这项服装风格检索任务中,沿用了以往研究者的相似性度量,如式4-1所示,首先,P是目录中所有可能的产品项目的集合。然后将
表示为包含风格兼容项目的所有集合的集合。检索两个项目
和
之间的相似性函数,确定它们是否合适。风格相似函数
如式(4-1)所示:
(4-1)
由于数据集中每件服装与其他服装的关联度不是很高,研究者添加了一个额外的相似性度量,如式(4-2)所示,该度量直接从描述的名称重叠中导出:
(4-2)
综上所述,如果满足以下两个条件之一,则被评估的配对被认为是相似的,即项目在同一套服装中共同出现或者是两个项目的名称在形式上重叠,记其为,其计算过程如式(4-3)所示:
(4-3)
列表内相似性:将最终得到的长度为k的生成结果列表R的平均列表内相似性定义为如式(4-4)所示:
(4-4)
即在生成的项目列表中的所有可能的对上计算的平均相似性得分。通过这样做,可以评估生成项目列表的整体风格相似性,风格检索结果的顺序无关紧要。
4.4. 实验结果
在将图像与文本风格相似性融合之前,分别对风格评估标准中的相似性结果进行对比,分别是
、
以及
。分别从图像与文本两个方式从数据集中检索相似风格,结果返回k值为5~20之间,比较了图像风格检索以及文本风格检索
、
以及两者风格检索最大值
,两种风格检索得到的相似性相差不大,如图7所示。因此,将4.3中的列表相似性计算作为最终的风格相似性评判是合理的。
对于多模态融合的风格相似性,对比单模态风格检索,以及对比其他多模态融合方法,包括后期融合,即指的是将视觉与文本分别按照相似性顺序返回二分之一个结果混合的最终结果,以及尝试还原了文献 [9] 和文献 [10] 的融合方法:
A. 文本风格检索;
B. 图像风格检索;
C. 后期融合;
D. 对目标项目使用图像相似性检索(此时的检索与风格无关)之后,再使用文本上下文风格检索,最终将查询文本作为检索条件(此时的检索与风格无关),最后将查询文本作为检索条件,检索出相似的结果;
E. 先对目标项目使用图像检索以及文本检索,对检索的最佳结果进行文本检索(此时的检索与风格无关),将这三部分的结果各取一部分,与目标项目的图像特征距离进行排列,得到最终结果。
F. 本文的方法,对一个目标的项目分别提取图像与文本特征之后,进行特征融合,通过与融合特征距离进行排列,得到最终检索结果。
为了比较,本文将相似度按照六个类别的方式进行呈现,分别是dress、coats、shoes、pants、hats、bags。对于D、E则将类别作为查询文本,此时将返回的列表长度设置为10,进行风格相似度的对比分析,表1为结果。分析单模态的上下文风格检索,图像风格检索比文本风格检索精度略高,表明了利用卷积神经网络进行服装图像特征提取的强大能力,同时,也证明使用word2vec网络架构的思想,所搭建的神经网络模型来完成服装风格检索任务是可以实现的。另外,通过与后期融合以及其他研究所采用的混合方法对比,本文提出的多模态服装风格检索获得了最高的风格相似性。对表中类别进行详细分析时,发现bags、hats、shoes这三类的服装单品相似度比较高,可能是因为这三种是作为配饰,类别并不是很多,没有复杂的颜色以及图案。

Table 1. Comparison of fashion style search results
表1. 服装风格检索结果比较表
为了对多个模态的结果有更直观的呈现,将本文的检索结果进行整理进行结果展示。检索文本在图像下标注,检索图像如图8所示。

Figure 8. Feature fusion result diagram (text retrieval content: women hooded faux leather jacket)
图8. 特征融合结果图(文本检索内容:women hooded faux leather jacket)
通过上图8进行的可视化展示,证明本文提出的多模态服装风格检索在视觉上有一定的相似性,对于该检索,是比较休闲的风格,所匹配的服装在颜色或者搭配上风格都较为相似。
5. 结束语
本章设计了一个多模态融合的服装风格检索方法。能检索出服装风格上的相似结果。介绍了所使用的Word2vec模型的原理以及风格检索模型的整体框架,额外添加了一个服装图像风格检索模型。介绍了融合服装图像和文本两种模态的混合风格检索策略,最后将提出的模型应用于Polyvore服装多模态数据集,从获取的服装检索结果来看,本章提出的模型有一定的风格检索效果。