1. 引言
当今社会,互联网的快速发展使得电子邮件在人们的日常生活中发挥了很大的功能,既可以提高工作效率、节约成本,又可以促进人们之间的交流和沟通。但同时,也有不少不法商人、不法之徒通过电子邮件做广告、散布不良信息,给人们的生活和工作带来了不必要的麻烦和困扰。用户经常会收到一些垃圾邮件,其内容毫无营养,有些包含一些恶意链接,可能会造成电脑中毒、网银被盗刷等危害用户安全的情况,扰乱网络安全环境。因此,如何快速准确地检测邮件是否为垃圾邮件是值得研究的重大课题。
迄今为止,国内外学者对垃圾邮件的识别技术进行了大量的研究,也取得了良好的效果。当前的研究方法有两大类,一类是基于邮件发送来源检测的技术,通过分析判断邮件的发送者地址和网络IP地址进行 [1] ,包括黑白名单识别查询技术和反向DNS技术等。第二种是根据邮件内容信息进行检测的技术,将邮件的内容特征提取出来,然后将这些特征转化为向量形式,利用分类器对其进行训练,从而获得一个分类模型,例如朴素贝叶斯 [2] 、SVM、K近邻 [3] 等算法。未知邮件再通过训练的分类模型得出该邮件的分类标签。近几年,深度学习发展迅速,在垃圾邮件检测领域,对卷积神经网络(Convolutional Neural Networks, CNN)模型的优化改进已经有了很大的进展。黄鹤等人 [4] 提出了基于Skip-gram的CNN模型,并结合了Highway网络,用低维度的特征向量反映文本特征,使得邮件分类模型的准确率得到提高。彭毅等人 [5] 提出了一种基于BERT_DPCNN的文本分类模型。通过BERT预训练模型获得文本向量,随后将其输入到DPCNN模型中,以获得更多的语义信息,避免了梯度消失,从而提高了模型的分类性能。目前,尽管已经有了很多垃圾邮件检测的方法,但是仍在某些方面需要改进,例如检测速度、检测准确率等。
CNN是一种具备特征提取能力和数据降维能力的神经网络。循环神经网络(Recurrent Neural Network, RNN)是一种用于处理序列数据输入的递归神经网络。之后,研究者们又提出了RNN的一种变体:双向门控循环单元 [6] (BiGRU)。BiGRU层由两个GRU组成,一个用于输入序列的前向处理,一个用于后向处理。这两个网络均与同一输出端相连,能够实现更完整的特征提取。GRU相比LSTM,能提供更快的计算和更高的效率,并且两者的准确率相当。垃圾邮件检测需要从电子邮件中提取关键词,注意力机制(Attention)可以给电子邮件中的关键词分配高权重,并提取重要信息。本文所提出的基于CNN的BiGRU-Attention模型,综合了以上三种模式各自的功能与优势,并与其它模型进行了比较,得到了较好的结果,数据集选取了公开的Trec06c邮件数据集。
2. 中文文本分类
本文中使用的垃圾邮件检测方法是基于对电子邮件文本内容的检测和分类,即基于文本的分类 [7] 。对于文本的分类 [8] 的任务是处理一个未知类别的文件,并确定它属于哪个或哪些类别。在这个过程中,使用一些已知的文本数据训练一个模型,来确定文本特征所对应的类别,训练好的模型再对其他文本进行分类。下面给出了一个基本的流程图(图1)。
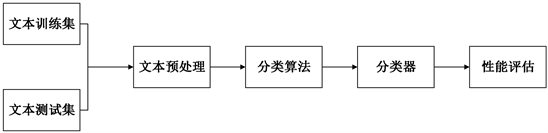
Figure 1. Basic process of Chinese text classification
图1. 中文文本分类的基本流程
从图1可以看出,文本预处理和分类算法是文本分类的核心部分。
3. CNN-BiGRU-Attention模型
传统的决策树、贝叶斯等文本分类方法都存在着高维度、高稀疏性、特征表达不强等问题。Kim [9] 在2014年提出了textCNN,CNN在文本分类问题上取得了比较好的效果。但是,该CNN模型的缺点也很明显:池化层容易丢失文本序列的有价值信息,不能解决文本时序特征的问题。RNN作为序列模型可以解决CNN对长文本处理效果不佳的问题,但无法解决长时依赖问题。因此,本文在CNN的基础上,引入了RNN变体模型:BiGRU。它能够更好地提取出文本的整体结构和特征 [10] ,而CNN则能够有效地提取出文本的局部特征,再通过引入注意力机制,突出显示文本的重要特征,从而提高分类模型的准确性和效率。如图2所示,CNN层从邮件文本数据中提取特征,然后经过第一个BiGRU层,将CNN层提取的特征和原始文本向量进行正反向的提取组合,将其输出向量输入进Attention层后进入第二个BiGRU层,以全面地获取邮件文本的特征向量,经过非线性层后最终经过
层得到分类结果。
3.1. 邮件文本预处理
要想计算机能够“理解”电子邮件文本内容被,就要对电子邮件文本的数据进行文本预处理,最终转换为格式化数据,为后面的特征提取做准备。预处理包括过滤非法字符、分词、去除停用词、词向量转换等操作。
3.1.1. 过滤非法字符
因为数据的采集来自于不同的网页,因此有可能出现大量的非法字符,比如标点符号、表情符号、链接、乱码或者其它的无意义的符号。在文本分类中,这些文字是没有任何用处的,所以必须对其进行过滤筛选,从而为提取邮件文本信息提供便利。
3.1.2. 分词
按照一定的规则将一个句子分成若干个词组的过程称为分词。分词可分为英文和中文分词 [9] 。在英文中,空格起到了自然分词的作用。然而,在中文文本中,词与词之间没有这样的天然分词器,这使得中文的分词比英文的分词更加困难和复杂。
本研究中的模型使用了“结巴 [11] (Jieba)”中文分词库,具有方便、快速、准确率高等优点。为了提高邮件正文的分词精度,使用了自定义词典来处理Jieba库无法处理的句子分词。目前,jieba是使用最广泛的分词方法之一 [12] 。
3.1.3. 词向量转换
经过上述步骤,图3中的数据已转换为图4所示的结构,从而产生更规整的电子邮件文本内容。

Figure 4. Preliminary processing of email text
图4. 邮件文本初步处理
但是,要让电脑“理解”电子邮件的文字,就必须把它转化成一个实数向量。词袋模型是一种传统的转换方法。该模型假定文档中每个单词的出现都是独立的,通过统计每个单词的出现频率作为分类器的特征,但是这种方法不考虑语法和单词出现的先后顺序。one-hot [13] 将是否出现该词作为词的权重。但一般在表达中,词语之间是有一定的相似性的,而one-hot无法判断这种相似姓,造成语义缺失。此外,现实生活中,词语的集合非常庞大,而每个向量的维度是和词语集合中词语的数量相匹配的,所以如果使用one-hot方法,需要用很高的维度来表示一个词。另外,若一个向量中仅有一个维度是非零的,该向量明显是过于稀疏的。
为解决one-hot模型的局限性,Word2Vec模型 [14] 用一个固定长度的向量表示每个词,再用这些向量表达单词间的相似程度。该模型包括跳字模型(Skip-gram)和连续词袋模型(CBOW)两种学习方法。CBOW假定在文本序列中的某个词是基于其前后的词产生的,Skip-gram模型假定的是根据文本序列中的某个词来产生其前后的词 [15] 。
Skip-gram模型具备训练时间短且效果好 [4] 的优点,故本文选择Skip-gram模型来构造Word2Vec模型,如下图5所示。
训练目标为:给定一个训练词序列
,最大化公式(1)中L的值:
(1)
其中,c是前后文的词数,N是训练样本的数量。
3.2. 卷积神经网络
在图像识别领域,卷积神经网络(CNN)作为一种前馈神经网络,有着良好的表现。由于其出色的提取局部特征的能力,CNN也被广泛用于文本分类领域 [16] 。
CNN的卷积层采用不同尺寸的卷积核,得到了不同的列向量。池化层可以从卷积层中抽取最大列向量,并能有效地克服因句子长度的差异而造成的差别。最后,
整合池化数据,完成全连接层的操作,以完成分类任务。在文本分类方面,CNN能够很好地从文本中抽取出局部特征。本文中的CNN架构负责从文本数据中提取特征,并整合分类,得到最终结果。
3.3. BiGRU
循环神经网络是一种对序列数据进行处理的神经网络,其内部结构设计使得网络可以捕捉序列之间的关系,并提取上下文的关系。但在训练长序列数据时,梯度消失、梯度爆发等问题时常出现 [17] 。
为了克服上述问题,Hochreiter等人 [18] 基于RNN提出了长短期记忆(LSTM)网络这一特殊的变体;Cho等人 [19] 又在其基础上提出了门控循环单元(GRU),它们都通过引入门控机制来控制梯度的流动,从而使得模型更容易训练和更好地捕捉序列之间的关系。GRU与LSTM模型效果相似,但是GRU计算复杂度相比LSTM要小,内部结构也相对较简单 [20] 。为了增强语义关联并提高分类精度,本文引入BiGRU双向门控循环单元模型,相比于单向模型,它更能有效地捕捉文本中的语义关系,从而获得更高的分类精度;并且在引入注意力机制后又引入了一个BiGRU,目的是为了更全面地获得文本全局特征。
双向GRU结构如图6所示,模型在每个时刻都有前向和后向的GRU作为输入,而输出则由这两个输入决定。这种结构可以更好地捕捉序列数据中的双向依赖关系,从而提高模型的性能和准确率。
如上图所示,t时刻的输入
以及(
)时刻的前向和反向隐层状态的输出
、
共同决定了BiGRU在该时刻的隐层状态。如公式(2)中所示,对当前时刻的前向和反向隐层状态
、
进行加权求和得到BiGRU在该时刻的隐层状态
[21] 。
(2)
3.4. 注意力机制
文本向量在经过第一层BiGRU层后,邮件信息已经较全面地被提取,但邮件中的需要重点关注的信息没有被突出强调。Attention机制将文本数据转化为由一系列的
数据对组成的Source数据,并基于Query与Key的相似度得出各个Key对应的不同Value的权值,最后对每个Value进行加权求和得出Attention数值,以实现对关键信息进行更精准的提取 [22] 。
注意力机制(Attention)可以从一堆复杂的输入信息中,找到对当前输出更重要的部分。在文本分类中,注意力机制被广泛应用于强化关键信息的权重,从而提高分类效果。本文为突出邮件的关键信息,引入了注意力机制,其实现过程如下图7所示。Attention机制将文本数据转化为由一系列的
数据对组成的Source数据,并基于Query与Key的相似度得出各个Key对应的不同Value的权值,最后对每个Value进行加权求和得出Attention数值,以实现对关键信息进行更精准的提取 [22] 。
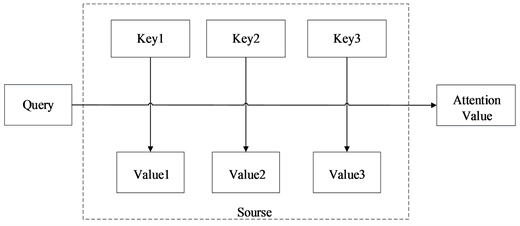
Figure 7. Implementation process of attention mechanism
图7. 注意力机制实现过程
Attention机制将文本数据转化为由一系列的
数据对组成的Source数据,并基于Query与Key的相似度得出各个Key对应的不同Value的权值,最后对每个Value进行加权求和得出Attention数值,以实现对关键信息进行更精准的提取 [22] 。
4. 实验与结果
4.1. 实验环境与超参数设置
本文实验环境为Intel(R) Core(TM) i7_9750 CPU@2.60 GHz以及16 GB内存,操作系统为Windows 10,显卡(GPU)为RTX2080Ti。模型超参数的设置如表1所示。

Table 1. Hyperparameters of the model
表1. 模型超参数
4.2. 实验数据
本文选取了国际文本检索会议提供的公开垃圾邮件语料库trec06c作为实验数据集,trec06c分为英文和中文两类邮件数据。正常邮件有21766条数据,垃圾邮件42854数据。实验采用的验证方法为十折交叉验证,即把trec06c数据集分成十份,其中一份作为验证集,另外九份则作为训练集,循环进行10次,以保证模型训练和评估的公正性和可靠性。
4.3. 评价指标
准确率(Accuracy)表示垃圾邮件检对率,以此来衡量邮件分类模型分类的准确程度;精确率(Precision)表示邮件识别的精确程度;召回率(Recall)表示垃圾邮件检出率、F1值是调和召回率与准确率的一个评价值,具体计算公式如下:
(3)
(4)
(5)
(6)
其中,A表示实际为垃圾邮件,系统判定也为垃圾邮件的电子邮件数量;D表示实际为正常电子邮件,系统判定也为正常电子邮件的电子邮件数量;B表示实际为正常电子邮件,但系统判定为垃圾邮件的电子邮件数量;C表示实际为垃圾邮件,但系统判定为正常的电子邮件数量;N为邮件总数。
4.4. 对比实验
为了测试本文的模型在垃圾邮件分类中的有效性,本文使用SVM模型 [23] 、CNN模型、CNN-BiGRU模型 [24] 、LSTM-Attention-CNN模型 [25] 、基于CNN的BiGRU-Attention模型进行了5个对比实验,并使用了相同的数据集和实验环境,以确保实验的公平性。
4.5. 实验结果
5组对比实验结果如表2所示。
从上面表格中可以看出,SVM模型准确率最低只有70.20%,传统分类方法分类效果较差;与SVM相比,CNN模型准确率大幅上升,数值提高至81.98%。CNN引入BiGRU之后,准确率进一步提高至89.13%;CNN引入LSTM的Attention机制后,准确率也大幅提升,达到91.34%;CNN引入BiGRU的Attention机制后,准确率达到91.56%。虽然这两组模型的准确率差异并不大,但在召回率、F1值上,基于CNN的BiGRU-Attention模型都高于基于CNN的LSTM-Attention模型,并且基于CNN的BiGRU-Attention模型的训练时间也短得多,即基于CNN的BiGRU-Attention模型的训练速度更快。
5. 结语
本文提出了基于深度学习的垃圾邮件检测技术的模型,具体为CNN-BiGRU-Attention模型,实验结果显示,该模型在训练速度、准确性等方面比传统的文本分类模型以及其他一些垃圾邮件检测算法的效果更好。
在本次实验中,模型训练与测试时,仅仅截取了邮件数据集中的内容部分,而没有把邮件的收件人和发件人地址等划入研究范围,但是这些部分对垃圾邮件的检测也有较大意义,具有研究价值。另外,目前已经出现许多图片型垃圾邮件,图片内容无用甚至非法,仅仅依靠对内容进行文本分类的方法还不够全面。综上,对垃圾邮件的检测和过滤的研究需要进一步改进、加强。
致谢
在完成本篇论文的过程中,我得到了来自各方面的支持和帮助。我想向所有为我提供帮助和支持的人表达我的感激之情。
首先,我要特别感谢我的导师禹素萍教授。她给了我在研究领域深入思考的机会,并在我的学术研究中提供了无私的指导和帮助。她的耐心和专业知识,使我能够克服在研究过程中的难题,同时对我的研究充满信心。我将永远感激她对我的帮助和支持。
其次,我要感谢我的朋友们在我生活中的陪伴,给予我鼓励和支持,使我更加坚强和勇敢地面对生活中的挑战。没有他们的支持,我将无法完成这篇论文。
最后,我要感谢我的男朋友宗某。他是我在学习和生活中的坚实后盾,他给了我无尽的爱和支持,鼓励我克服所有的困难和挑战。他的陪伴和支持是我完成本篇论文的最大动力。
在此,我再次向所有为我提供帮助和支持的人表达我的感激之情。我将永远感激你们对我的关注和支持。