1. 引言
人体行为识别是近年来深度学习与视觉分析领域的研究热点之一,其任务是利用神经网络模型从视频中提取人体行为动作特征,并依据提取出的特征对动作进行分类,进而达到识别的目的。行为识别技术已广泛用于视频监控、运动分析、虚拟现实和机器人技术等领域。国内外学者对此开展了大量研究并提出了一系列高效的行为识别算法,按照网络模型输入的数据模态不同,可将行为识别分为基于RGB视频流和基于骨架两类方法。由于骨架方法只记录人体关节点的位置坐标,其具有数据量小、语义性高、不记录背景等无关信息、模型表达鲁棒性强等优点,而且随着人体姿态评估技术的发展,可以更方便地获取到人体骨架数据。因此,基于骨架的行为识别受到越来越多专家学者的关注。
目前,骨架行为识别方法主要分为2类:基于手工特征的方法和基于深度学习的方法。基于手工特征的方法通过关节数据之间的关系提取动作特征。Hussein等人 [1] 将骨架关节位置的协方差矩阵作为序列的判别描述符,再通过传统的分类算法进行分类。Vemulapalli等人 [2] 使用旋转和平移来建模身体部位之间的几何关系,并将这种关系映射到李群代数向量空间中作为动作特征。Weng等人 [3] 受到朴素贝叶斯方法的启发,通过阶段中类间距离来对动作进行分类。然而,手工特征的方法存在难以提取深层特征与过度依赖数据集的问题,因此,深度学习方法开始替代手工特征方法。
由于循环神经网络(Recurrent Neural Network, RNN)和卷积神经网络(Convolutional Neural Network, CNN)强大的特征提取能力, [4] [5] [6] [7] 使用RNN和CNN的方法对骨架数据进行建模,并且取得了不错的效果。但是,这些方法在将原始骨架数据转换成伪图像作为神经网络输入时会丢失骨架的原始结构信息。为了解决此问题,Yan等人 [8] 首次使用图卷积(Graph Convolution Network, GCN)将骨架数据作为图进行建模,利用骨架数据中具有图拓扑关系的邻接矩阵提取空间特征,实现了性能的提升。但是由于特征聚合共享一个原始骨架固定的图拓扑,导致图卷积无法捕获原始拓扑之外关节的联系,Lei等人 [9] 和Li等人 [10] 通过构建一个可学习的图拓扑矩阵,以数据驱动的方式来寻求合适的图拓扑。由于特征图中不同通道代表不同类型的运动特征,并且不同运动特征下关节之间的相关性也不相同,上述方法对所有通道使用相同的图拓扑,这使得GCN在不同通道中聚合相似的运动特征,导致动作信息提取不充分,因此使用一个共享拓扑并非最佳选择。受到深度卷积的启发,Cheng等人 [11] 为通道设置不同组,在每个组里对图拓扑进行学习。
基于上述,虽然国内外诸多学者在骨架行为识别上开展了大量研究并取得了优秀的研究成果,但仍存在着一些问题:1) 现有图卷积在特征聚合阶段存在部分的冗余,无法提取更精细的特征;2) 时空信息通过图卷积与时间卷积分别进行提取,但未考虑时间与其它信息之间的关联性;3) 缺少对特定时间下关节和通道的关注,无法聚焦重要的动作信息。
针对上述问题,本文提出了一个时空注意力深度增强差分图卷积网络模型。首先,受Cheng等人 [11] 和Miao等人 [12] 的启发,提出了一种深度差分图卷积网络,该网络采用深度图卷积和差分图卷积两种图卷积的形式构建空间卷积模块,能够在空间模型中更有效的提取特征;然后,通过动态通道增强模型构造时间维度自适应通道权重,来加强深度差分卷积对动作特征的建模能力;再者,通过多尺度的二维时空卷积模型与时空注意力增强模型对时空关系进行建模,以捕获更多的时空信息;最后,在NTU RGB + D骨架动作数据集上进行了实验。实验结果进一步验证了本文提出的行为识别模型的时空建模能力及良好的识别准确率。
2. 基于时空注意力深度增强差分图卷积的行为识别模型
骨架序列的空间特征与时间特征能够表述骨架序列中动作的完整信息,且两者之间存在着一些隐式的关联。本文提出时空注意力深度增强差分图卷积网络模型对动作信息与时空关联信息进行建模,总体框架如图1所示。
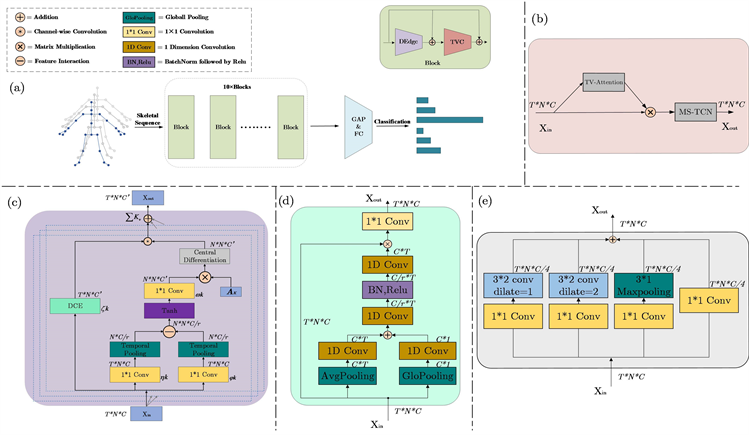
Figure 1. (a) ST-DEdGCN network structure; (b) Spatio-temporal attention enhance model; (c) Depth-enhanced differential graph convolution model; (d) Dynamic channel enhance model; (e) Multi-scalespatio-temporal convolution model
图1. (a) 总体结构;(b) 时空注意力增强模型;(c) 深度增强差分图卷积模型;(d) 动态通道增强模型;(e) 多尺度时空卷积模型
该模型主要分为2部分:深度增强差分图卷积(紫色)和多尺度时空注意力增强卷积(红色)。首先骨架序列经过动态通道增强模块与深度差分图卷积得到特征图内不同通道的细粒度空间特征。然后在时空注意力增强卷积中,通过时空相关性注意力机制获取骨架序列中内在的时空注意力权重,实现针对特定时空的关注。最后经过多尺度时空卷积获取全局时空信息作为模块的输出。
2.1. 深度差分图卷积模型
现有方法通过注意力或其他机制自适应的学习人类骨架的拓扑结构,并对所有通道使用拓扑,这迫使GCN在不同通道中聚合具有相同拓扑的特征,既限制了特征提取的灵活性,又在部分特征聚合存在着冗余。本文提出深度差分图卷积(Depth differential Graph Convolution Network, Dd-GCN),该方法通过构造通道级拓扑结构来探索不同通道上的运动特征,提高了模型特征提取的灵活性,并且利用更为细粒度的梯度信息对图卷积进行完善与补充,整体结构如图1(a)所示。具体而言,该方法包含三部分:通道节点拓扑建模、中心差分化、通道整合。
通道节点拓扑建模通过构建每个通道各自的图拓扑结构来学习不同通道上的运动特征。首先通过两个核为(1 × 1)的二维卷积对输入特征
进行线性变换,然后该部分经过时间池化生成两个
作为特征交互时的输入。之后经过特征交互函数得到初步关系的图拓扑矩阵
。最后通过一个核为(1 × 1)的二维卷积与非线性激活函数生成最终的图拓扑矩阵
,其表达式为:
(1)
其中,
和
是输入线性变换的权重矩阵,
是输出权重矩阵,
为非线性激活函数,M为特征交互 [13] 操作,目的是探索空间中各个节点之间的联系,为了更能直观的了解其原理,公式如下所示:
(2)
和
分别为输入线性变换后特征中N个节点特征之一。
由于中心差分卷积引入局部特征来增强模型识别能力,所以将中心差分化用来丰富特征信息,通过加入细粒度的梯度信息以完善原始的图卷积。该方法聚集采样点的中心梯度,只需要通过对邻接矩阵的第二维度求和来获得。因此中心差分化可以表达为:
(3)
其中,
表示元素级的哈达玛积,
是通过对邻接矩阵
对第二个维度求和之后(
)拓展得到的(
),公式如下:
(4)
向量里元素都为1。为了提供稳健和多样化的建模能力,分配一个权重将图卷积和中心差分组合在一起,其表达式为:
(5)
控制分配的比重,
越高说明中心差分信息非常有用。
通道整合为每个通道分配了一个动态的邻接矩阵去学习每个通道中不同节点之间的关系。该动态邻接矩阵(
)是由通道拓扑建模部分所生成,每个邻接矩阵与相应特征(
)进行特征聚合,其中下标
分别来自i通道。最后将各个通道上所生成的输出特征整合在一起输出最终输出Y,其公式如下:
(6)
为拓扑建模差分化后的邻接矩阵,
表示拼接函数。
2.2. 动态通道增强模型
上一小节介绍了深度差分卷积模型,该模型首先学习到通道级的邻接拓扑矩阵,然后通过该矩阵聚合相应的动作特征。但是骨架序列是一个具有时间维度的数据,所以不同时间帧上的动作特征表达内容也不同,然而深度差分卷积模型在特征聚合时结合全局时间帧的所有通道统一进行特征聚合,没有考虑到不同时间帧间通道所聚合的运动特征的重要性。因此为了解决该问题,本小节提出了一个动态通道增强模型(Dynamic Channel Enhance Model, DCE)来增强深度差分卷积模型中的通道级运动特征聚合能力。该模型根据上下文动态校准每个时间帧的通道权重,通过该权重模型可以区分空间下不同通道的重要程度,并且该时间帧自适应权重也探索了一定的时间关系有助于时间维高效特征聚合。
因为动态通道增强模型(DCE)生成的权重随时间帧而进行改变,所以不仅要考虑当前帧,更重要的是要考虑该时间帧的上下文内容,因此通过学习上下文局部信息和全局信息生成当前帧的自适应权重,其模型结构如图1(d)所示。此模块主要构成部分为全局特征提取、局部特征提取、特征加权。该模型通过对输入
进行全局和局部平均池化来获得更高效率的时间帧描述向量,其公式如下:
(7)
(8)
其中
,
。之后将全局和局部特征通过线性1D卷积后加权在一起,加权后的特征通过降维比为r的两层堆叠1D卷积来捕获不同时间的关联性,最终生成动态的时间通道权重。该权重能够表示不同时间帧下相应的通道权重,大大增强了深度差分卷积模型的动作特征聚合能力,总体公式如下:
(9)
其中输出
,
为偏重,
为元素传播相加。
2.3. 时空注意力增强模型
在骨架行为识别领域中,许多现有方法只关注空间节点之间的联系,而未考虑时间上的重要性。一些方法提出时间注意力机制 [14] 突出重要的时间节点,但是忽视了不同时间节点之间存在的联系。由于3DCNN体现了建模时空信息的优越性,本文提出时空注意力增强卷积对时空信息进行建模,丰富不同骨架帧之间的多样化表示,增强更具有辨识度的动作时空特征获取能力。该方法分为两部分:时空相关性注意力机制和多尺度时空卷积模型。
在骨架行为识别中,大部分动作信息可由少数关节表示,故聚焦特定关节能一定程度提升骨架行为的识别准确率。时空注意力增强模型(图1(b))用来探索不同时间关键节点间的联系,图2给出了TV-attention方法的详细细节。在图2中,输入特征
,其中N为批次大小,C为通道个数,T为时间维度,V为节点个数。针对输入特征通过简单的矩阵线性变换操作生成注意力热图
。其公式如下:
(10)
其中sigmod和relu为非线性激活函数,Conv是两层具有降维比的1 × 1卷积组成。该热图为不同时间节点分配权重,增强了不同动作特征之间的差异性,提高了模型的特征提取能力。
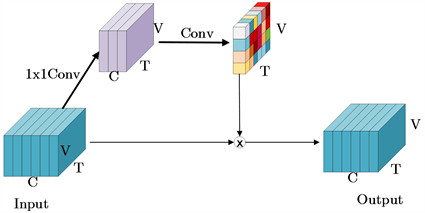
Figure 2. Schematic diagram of temporal attention mechanism
图2. 时空相关性注意力机制示意图
在对骨架序列的时间信息建模中,许多现有的工作 [8] 使用固定内核大小
的时间卷积来建模时间信息。作为多尺度空间聚合的自然拓展,许多工作 [15] [16] 通过多尺度的方法增强学习时间信息,但是这些方法仅仅在局部空间上进行时间建模,而没有考虑到全局信息的重要性。多尺度时空卷积模块通过二维的时间卷积,将内核大小固定为3 × 2,并使用不同的扩展速率而不是更大的内核达到对更大空间视野的建模。采取瓶颈结构设计,降低额外分支带来的计算成本,并且加入剩余连接来丰富特征信息。其框图如图1(e)所示。
3. 实验与分析
3.1. 实验数据集
NTU RGB + D. NTU RGB + D [17] 是目前使用最广泛的动作识别数据集,包含了56,880个3D骨架数据。该数据集共有60类和40个受试者,每个样本包含一个动作,最多有两个受试者,并且是由三个Microsoft Kinect v2深度摄像头从不同视图同时捕获。该数据集推荐了两个基准:1) cross-subject (X-sub):数据集分为训练集和测试集。训练集包含40,320个视频片段,验证集包含16,560个视频片段,两个子集中的受试者不同。训练数据来自20名受试者,测试数据来自其他受试者。2) cross-view (X-view):该基准测试中的训练集包含37,920个视频片段,由摄像头在0˚,45˚时拍摄,该验证集包含18,960个视频片段,这些视频片段由摄像头在−45˚时拍摄。
NTU RGB + D 120. NTU RGB + D 120 [18] 是NTU RGB + D的扩充版本,涉及更多的主题和动作类别,更具有挑战性。该数据集包含120个动作类中的114,480个动作样本,由106名不同的受试者执行。该数据集推荐了两个基准:1) cross-subject (X-sub):训练数据来自53名受试者,测试数据来自其他53名受试者。2) cross-setup (X-setup):训练数据来自设置ID为偶数的样本,测试数据来自设置ID为奇数的样本。
3.2. 实验设置
本文实验在Ubuntu16.04操作系统下进行,并采取PyTorch深度学习框架实现。所有实验均是在两张Tesla T4 GPU上进行。对于整个网络,使用10层时空注意力差分深度图卷积网络模块搭建模型,10层的输出通道数分别为(64, 64, 64, 64, 128, 128, 128, 256, 256, 256)。使用动量(0.9)权重衰减(0.0004)的随机梯度下降法(Stochastic Gradient Descent, SGD)对模型总共训练70代。利用交叉熵(cross entropy)损失,学习率设置为0.1并在第30和50代后以0.1比例衰减。对于NTU 60/120数据集,批量大小为64。原始骨架序列被缩小到64帧的固定大小。数据预处理采用的策略与 [19] 中介绍的相同。
3.3. 实验结果与分析
本文的关键点主要在于:1) 使用深度差分图卷积提取高效的运动特征;2) 通过动态通道增强模块加强深度差分卷积动态时间特征聚合能力;3) 通过多尺度时空卷积获取骨架视频时空特征,并加入时空注意力机制增强对特定时空关节的关注。下面分别评估这两个模块对识别性能的影响,并将最终架构中的各个组件及其配置与现有的流行方法进行具体的对比分析。本文实验对比以NTU RGB + D 60数据集的cross-subject节点流(joints)为基准。
3.3.1. 深度差分图卷积验证
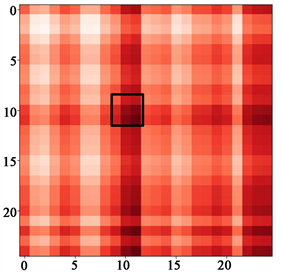 (a) 第10通道学习到的邻接拓扑矩阵
(a) 第10通道学习到的邻接拓扑矩阵 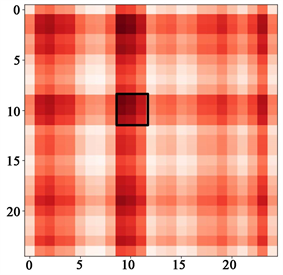 (b) 第50通道学习到的邻接拓扑矩阵
(b) 第50通道学习到的邻接拓扑矩阵
Figure 3. Neighborhood topology matrix for different depth channel learning
图3. 不同深度通道学习的邻接拓扑矩阵
带有深度差分的图卷积(Dd-GCN)相比于传统图卷积可以捕获到更高效的运动特征。因此为了验证Dd-GCN模块捕捉复杂空间特征的有效性,本小节首先对Dd-GCN模块进行可视化,其次与现阶段流行方法进行对比。如图3所示,给出了不同通道所学习到对应的自适应图拓扑矩阵的示例(第10和50通道)。该示例为一个“喝水”的动作,图中像素值越接近0 (白色)表示关节之间的关系越弱。可以明显看出,每个通道所学习到的邻接矩阵是不同的,这表明本文的方法可以根据不同通道的特定运动特征学习相应的拓扑邻接矩阵。并且在所有通道中,与动作相关的一些联系很强的节点信息也都保存着,如黑框标出的部分,在动作“喝水”行为中,不同通道对左臂的注意十分密切。
表1给出了本文算法中深度差分图卷积网络(Dd-GCN)与适应图卷积(AGCN),差分图卷积(CD-GCN),深度图卷积(DGCN),信道拓扑细化图卷积(CTR-GCN)的行为识别效果。本节使用各个组件逐步建立了验证模型,使用AGCN [9] 中的单流作为控制实验的基线,通过替换该方法空间特征提取层来进行更深层次的对比,其中所有模型的识别结果由本文自己运行得出。由表1可知:1) 相较于未使用通道级拓扑的图卷积模型,结合通道级拓扑增强结构的图卷积在实验准确率上具有优势;2) 对比其他通道级拓扑的图卷积模型,通过结合中心差分的方法,本文模型在(X-sub)的Top-1评价指标下识别准确率得到显著的提升,达到最高90.2%的识别准确率,其也充分证明了深度差分图卷积对于获取高效动作特征的有效性。因此,可以看出本文提出的方法不仅能够捕获到更高效的动作特征,且在空间特征提取部分识别准确率优于其他算法,表现出更好的性能。

Table 1. Comparison of spatial feature extraction ablation on NTU RGB + D 60
表1. 在NTU RGB + D 60上的空间特征提取消融对比
3.3.2. 动态通道增强模型验证
虽然深度差分模块的图卷积可以捕获到更高效的运动特征,但是该模型通过固定时间帧通道间的关系捕获运动特征,忽视了不同时间下运动特征代表不同的行为。因此为了验证动态通道增强模块(DCE)对深度差分卷积的加强性,列出了该模块与现阶段流行方法进行对比。
Table 2. Comparison of DCE module ablation on NTU RGB + D 60
表2. 在NTU RGB + D 60上的DCE模块消融对比
由于DCE模块是对动态通道的探索,所以表中都是在深度图卷积方法的基础上进行对比。从表2中可知:相较于未使用通道增强结构的深度图卷积模型,结合了动态通道增强的深度图卷积模型在joint流指标下识别率均为最优。其中相较于DGCN方法与CTRGCN方法,基于动态通道增强模型在X-sub下分别提高了1.1%与0.7%。实验结果进一步验证了动态通道增强模块对深度图卷积方法的增强性。
3.3.3. 时空注意力增强模型验证
时空注意力增强卷积模块通过多尺度时空卷积获取空间与时间之间的关联信息,并加入时空注意力机制增强对特定时空关节的关注。因此为了验证ST-ATTCN模块对时空信息建模的有效性,本小节首先对时空注意力增强模块进行可视化,其次对现阶段时间特征获取方法上进行了消融实验。如图4所示,该图为“喝水”动作的时空注意力部分层可视化结果图。图中横坐标表示的是节点,纵坐标表示的是时间,像素值越接近0 (深蓝色)表示关系越弱。并且可以清楚的看到在9~11帧里红框标出部分,左右胳膊节点和身体的部分节点之间存在更紧密的联系(0~5帧经分析属于基础行为部分,没有出现特定强相关动作特征信息)。
多尺度时空卷积模型来对时间域进行特征提取和特征聚合,仍然把AGCN作为本次控制实验的基线。首先,使用传统的多尺度时间卷积网络(Multiple Temporal Convolutional Network, MS-TCN)替代传统的
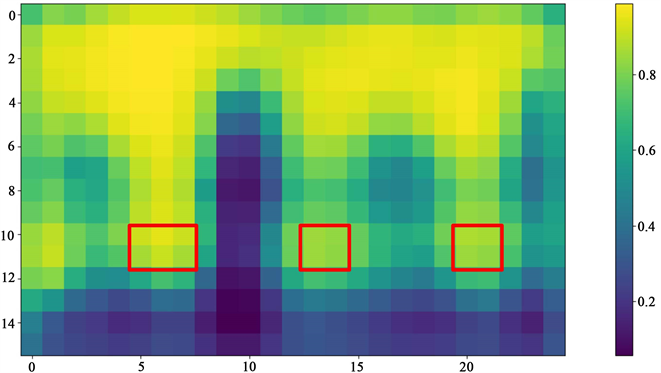
Figure 4. Visualization of temporal attention module
图4. 时空注意力模块可视化
时间卷积网络(Temporal Convolutional Networks, TCN),该模型受到GoogleNet思路的影响,把传统的时间特征提取增广成了多尺度的形式,从而丰富了特征的表达。如表3所示,把MS-TCN代替基线中的TCN,相比于基线准确性提升了0.5%,之后加入本文提出的时空注意力增强卷积(Spatiotemporal Attention Temporal Convolution Network, ST-ATTCN),在基线上准确性提高了0.8%,比MS-TCN准确性高出了0.3%。可以看出,在时间特征提取部分本文提出的ST-ATTCN捕获了不同时间不同节点之间的联系,提高了相似动作特征之间的差异性,与其他方法相比表现出更好的性能。
Table 3. Comparison of temporal feature extraction ablation on NTU RGB + D 60
表3. 在NTU RGB + D 60上的时间特征提取消融对比
3.3.4. 与主流网络对比结果
为了验证本文提出模型的性能,本文将自己提出的模型在NTU RGB + D 60和NTU RGB + D 120数据集上与其他前沿方法进行对比,对比结果如表4和表5中所示。本文模型在NTU RGB + D 60数据集的X-Sub和X-View两种评判标准下准确率分别达到了92.6%和96.7%;在NTU RGB + D 120数据集的X-Sub和X-View两种评判标准下准确率分别达到了89.1%和90.4%。在两个数据集上,本文方法明显优于基于GCN的基准方法 [8] ,与其他优秀的前沿方法相比同样有比较强的竞争力。
综上实验结果表明:基于时空注意力深度增强差分图卷积的行为识别模型相较于现阶段图卷积的行为识别方法,即实现了骨架序列中动作信息的高效提取与对时空关联信息和时空特定关节的注意力增强,又具有不错的识别准确率与泛化能力。
Table 4. Comparison of recognition accuracy of different action recognition algorithms on NTU RGB + D 60 dataset
表4. 不同行为识别算法在NTU RGB + D 60数据集上识别准确率对比
Table 5. Comparison of recognition accuracy of different action recognition algorithms on NTU RGB + D 120 dataset
表5. 不同行为识别算法在NTU RGB + D 120数据集上识别准确率对比
4. 结论
本文提出了一种新的基于骨架的时空注意力深度增强差分图卷积神经网络。通过分析现有模型的不足,提出了深度增强差分模块和时空注意力模块来加强相关性建模能力。为了验证所提出方法的有效性,分别从可视化结果、网络精度提升等方面进行实验验证。通过在骨架动作数据集上与其他主流方法进行比较,实验结果再次证明了改进后的模块有效性。本文方法在处理骨架序列中相似轨迹的数据时,无法提取表征能力较强的特征向量,这也是今后需要深入研究的地方。
参考文献