1. 引言
由于信道噪声的存在,信道编码是无线通信至关重要的研究领域,是保障信息可靠、准确、有效传输的关键。极化码是信道编码领域的新突破,是唯一一种在二进制离散无记忆信道中能够达到信道香农限的编码方案 [1] 。与LDPC码和Turbo码相比,极化码具有较好的译码性能和低复杂度。同时,极化码也被广泛应用于存储系统、深空通信、水下通信、光通信等场景 [2] 。
BP译码算法是一种并行迭代译码方案,具有译码延迟低、吞吐率高的特点。但在译码性能上,与SCL译码相比,存在一定差距。在低信噪比通信环境下需要较多次迭代才能成功译码,其性能很大程度上取决于迭代次数。研究者设计多种早停机制来提前结束译码,降低迭代次数来提高收敛速度 [3] 。为进一步提高BP译码算法性能,Elkelesh等人 [4] 提出了一种置信传播列表(BPL)译码器,其性能与极化码的连续取消列表(SCL)解码器相当。BPL译码器由多个基于不同排列极化码因子图的并行独立置信传播(BP)解码器组成。为了降低BPL译码器带来的空间复杂度,Doan等人利用比特索引来调度极化码因子图 [5] [6] ,使得串行BPL译码器可以复用同一个BP译码器。有研究者 [7] 提出了一种依赖于人工噪声的新型信念传播列表(BPL)译码器,该解码器将不同功率的噪声添加到并行独立的BP译器中解决译码过程中未收敛的问题。Geiselhart等人 [8] 利用循环冗余校验(CRC)作为停止条件,提出的CRC辅助信念传播列表(CA-BPL)译码算法,该算法译码性能接近CA-SCL。Ren等人 [9] 基于环路简化(Loop Simplification, LS)对极化码因子图进行筛选,所提出的LS-BPL译码算法相比于BPL译码算法具有更好的译码性能和更低的平均解码延迟。置信传播翻转(BPF)译码 [10] 算法不同于其他BP的优化算法,它利用解码过程中的信息,更有针对性地翻转易错比特。为了更有效地识别易错比特,广义BPF (GBPF)译码算法和增强BPF (EBPF)译码算法 [11] [12] 用来提高翻转集合识别错误比特的准确率和实现多比特翻转。
近年来,基于机器学习的极性BP解码器成为了热门的研究方向。Doan等人 [13] 将极化码因子图排列选择问题看作强化学习中的多臂老虎机问题,通过在线学习方式在BPL译码过程中选择最优的极化码因子图。同时,由于神经网络具有并行结构,可以泛化BP解码结构,常用于与BP译码算法相匹配来提高译码吞吐率和降低时延 [14] [15] 。Nachmani等人 [16] [17] 提出加权置信传播(WBP)译码算法,该算法使用深度神经网络模型训练加权BP译码算法。但当码字长度增加时,训练复杂度呈指数级增长。Lugosch等人 [18] 使用偏移最小和算法来代替求和–乘积算法,降低训练过程中的计算复杂度。Xu等人 [19] 基于WBP译码算法提出了一种适应各种码长的的多尺度置信传播(BP)算法。Teng等人 [20] 基于码本对递归神经网络权重进行量化,采用了迭代架构,使各种迭代间可共享训练的权重。Huang等人 [21] 提出了基于残差神经网络的BP解码器(ResNet-BP),以补充传统的BP算法,该算法具有较低复杂度的优势。Oliveira等人 [22] 等人利用强化学习来优化WBP译码算法的加权参数。Raviv等人 [23] [24] 最先将数据驱动集成方案应用于极化码,用于集成BPL译码和WBP译码,每个译码器都被训练来解码不同的数据,同时将CRC码作为门控器对码字进行分类和聚合。
BPL译码器提供了广度的译码范围,而WBP译码器则有着优于BP译码器的优势,所以两者集成是一种新颖的学习策略。本文基于两者优势,提出了一种基于集成学习的BP译码算法,通过分析BPL译码器与集成学习的结构特点,将WBP译码器作为弱学习器对其权重参数进行单独离线训练,并利用学习器筛选来组合强学习器用于信道译码,该算法可以有效地提升BP译码算法的性能。首先,将每个WBP译码器看作弱学习器,利用不同的数据集来分类训练,训练后的WBP译码器具有不同的译码能力,WBP译码器的训练可以离线完成。然后,再由学习器筛选组合一个强学习器(E-WBP译码器),该学习器有若干个弱学习器组合而成。最后,译码时只需要将训练权重参数送至E-WBP译码器中,对接收到的信源序列进行译码,由早停机制结束译码。
2. BP译码与BPL译码算法
2.1. BP译码算法
置信传播译码(Belief Propagation, BP)算法是一种基于极化码因子图的迭代算法,广泛用于Turbo码、LDPC码等。BP译码算法具有并行译码、高吞吐率的特点,硬件实现更容易。定义极化码
的码长N,码率
,信息位长度为K,信息比特集合
。其极化码因子图有n层,
,共包含
个节点,(i, j)表示第i节第j级的节点,其中
,
。令
和
分别表示节点(i, j)的左向传播和右向传播,每次左向传播和右向传播都会对节点信息更新如图1所示。
(1)
其中,
,式(1)已由最小和译码算法式(2)简化:
(2)
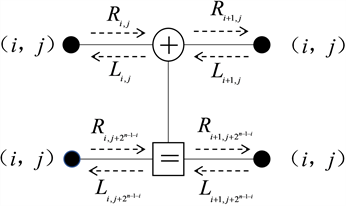
Figure 1. Polarization code BP decoding algorithm minimum computing unit
图1. 极化码BP译码算法最小计算单元
在极化码的BP译码前,BP译码算法需要
根据信道接收的后验LLR值初始化,
初始化是直接将冻结比特对应的
,
设置为无穷大,否则设置为0。当BP译码算法达到最大迭代次数
或满足其他早停条件时停止译码,通过硬判决公式计算出译码结果:
(3)
2.2. BPL译码算法
BP译码算法最小计算单元可以组成不同的极化码因子图,BP译码时使用不同的因子图会有不同的译码性能,这也是BPL译码算法增益的主要原因。码长为N的极化码可以得到最多
个因子图,对于BPL译码算法的难题就是从
个因子图中筛选出L个译码性能较优的因子图组成最后的译码方案。图2中图2(a),图2(b)展示了N = 8时,两种不同排列类型的因子图。
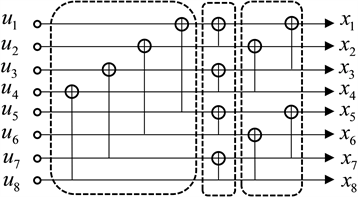 (a)
(a) 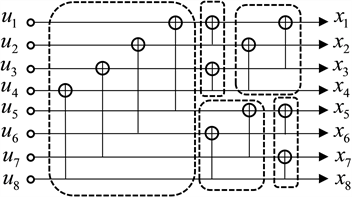 (b)
(b)
Figure 2. The arrangement of the two factor plots of polarization codes with a length of 8
图2. 码长为8的极化码两种因子图排列方式
由于因子图与码字位置见存在映射关系,可以利用置换比特索引的位置来表示不同的因子图,使得BPL译码算法可以复用同一个因子图。如果将因子图中的“XOR”运算看作1,“dot”运算看作0,可以将因子图的排序用矩阵向量的方式展示出来如,可以通过线性变换来实现矩阵向量的转换,这种线性变换也就是置换比特索引的表示形式。如图3所示,分别是图2(a)和图2(b)对应的因子图的矩阵形式,可以看作因子图与码字索引对应的关系,而且两者之间可以通过置换比特索引来改变索引排序,从而实现对BP译码器的复用。

Figure 3. The correspondence between different factor plots of polarization codes with a length of 8
图3. 码长为8的极化码不同因子图间对应关系
译码器接收到
时,会并行送到L个译码器,每个译码器因子图为
。所有的因子图将会获得相同的信号
,每个独立运行的译码器
都将经过多次迭代,输出相应的信源序列估计
和码字估计
,然后根据设置的早停机制可以提前终止
的译码。通常使用基于生成矩阵早停机制来判断编码约束关系
,判决是否结束
译码。最后再利用最小距离译码准则确定出最后的译码码字
。每个译码器都是具有不同结构排列的因子图,可以利用因子图与码字间的映射关系来使BP译码器可以复用,降低硬件实现难度。基于生成矩阵早停机制的极化码BPL译码算法流程图如图4所示。同时还有CRC早停机制,CRC早停机制就是在发送端对码字进行CRC编码,在迭代的译码周期中对估计码字
进行CRC检测,若通过则停止译输出最后的译码码字
。
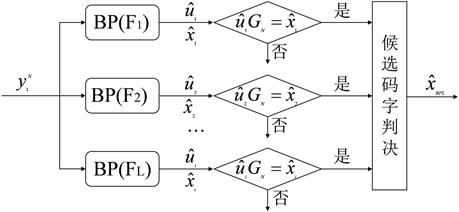
Figure 4. Flow chart of polarized code BPL decoding algorithm based on the generation matrix early stop mechanism
图4. 基于生成矩阵早停机制的极化码BPL译码算法流程图
候选码字的判决,采用BPL译码器最小距离译码准则:
(4)
3. 基于集成学习的极化码BP译码算法
集成学习在分类、聚类、半监督学习等方面表现出良好的准确性和稳定性,在很多不同的领域,如数据挖掘,文本分类,生物信息学和人脸图像分类等得到了应用,受到越来越多的关注。集成学习的主要思想是将多个弱学习器(弱学习器)结合,构建成一个有较强性能的机器学习器。
3.1. WBP译码算法
近几年机器学习在很多领域都被广泛使用,同时机器学习(深度学习)方法也被应用于通信的信道译码算法中,特别是与BP译码算法结合。神经网络由多层连接的神经元组成,包含输入层、隐藏层、输出层。基于因子图表示的BP译码算法经过多次迭代所形成的结构,可以看作是一种有固定计算方式的特殊神经网络。加权BP(WBP)译码算法利用因子图的迭代结构来实现,将因子图里的最小计算单元参数化。设置迭代过程中最小计算单元的每个节点都有两个额外的参数
和
分别表示在第t次迭代时因子图中(i,j)节点左消息和右消息的可训练权重。
(5)
WBP译码算法的神经网络架构基于T次迭代,每次迭代包含左向传播和右向传播,所以一个完整的WBP译码算法的神经网络结构包含1层输入层,
层隐藏层,1层输出层,如图5所示。
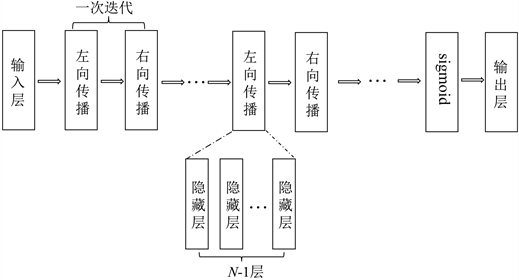
Figure 5. The BP decoding factor plot is transformed into an NN network with weights
图5. BP译码因子图转化为带有权重的NN网络
最后一层的激活函数采用sigmoid函数,用于在BP译码结束时将LLR值映射为(0, 1),可以看作是硬判决,便于译码器利用监督学习进行训练。
(6)
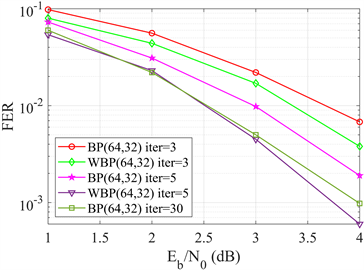
虽然更深层次的神经网络通常具有更大的解码能力,但也带来巨大的加权参数计算。所以,为了在误码率性能和复杂度之间保持良好的平衡,迭代次数的选择需要适当。与传统的BP算法相比,文献 [19] 在深度学习框架Tensorflow上,设置学习率0.001,采用Adam自适应优化器,训练加权参数。训练集经过AWGN信道传输后均为零码字。信噪比(SNRs)范围为1~4 dB。共生成24,000个码字,批次大小为120 (每个信噪比30个码字)。该模型采用早停机制来提前结束译码。权值初始化是神经网络训练的关键部分,为了避免局部优化,权重参数初始化为1。测试集由随机二进制消息(每个信噪比10,000帧)经过编码、二进制相移键控(BPSK)调制并通过AWGN信道传输后生成。训练神经网络的目的就是最小化损失函数并训练出最优的权重参数。仿真结果如图6所示,采用T = 5的WBP译码算法的译码性能优于T = 30的传统BP译码算法,可以实现更低的误码率。

(a)
(b)
Figure 6. Performance comparison between WBP and BP decoding algorithms
图6. WBP与BP译码算法性能对比图
3.2. 集成学习模型
3.2.1. 弱学习器及数据集
弱学习器通常是用一个现有的学习算法由训练数据训练产生,例如决策树算法、神经网络算法等。根据弱学习器所采用的学习算法是否相同可分为同质集成或异质集成。同质集成中,弱学习器由相同的学习算法生成,异质则由不同算法生成。鉴于神经网络模型的WBP译码算法在译码性能和时延两方面均优于传统BP算法,所以弱学习器选择基于神经网络的WBP译码器。为了实现集成学习性能优于弱学习器的目标,要求弱学习器要相互独立。对于同质集成来说,则需要利用不同的参数构成具有不同译码性能的译码器,所以需要独立的数据集来保证权重参数的不同。
WBP译码器的权重参数训练数据集一般采用全零码字,这种数据集包含的信息只有码长N及信息位K,由于无法区分,所以不能作为同质集成的训练数据集。为了保证数据集的独立,首先分析极化码信息传输过程。假设传输信道为加性高斯白噪声(AWGN)信道,采用二进制相移键控(BPSK)调制。信源序列u经过极化码编码后,由信道
传输,译码器接收信息序列为y:
(7)
式中w为AWGN信道噪声,服从
分布。
信息序列y对应的LLR值为
:
(8)
再由LLR值为
进行硬判决,得到
,
为未经BP译码的信源序列估计值。定义信道输出的二进制误比特分布
,其中
,c为传输码字,也就是全零序列。而由于信道不同,不同信道传输后的
有很大差别,所以可以以此来采样数据。二进制误比特集合为
,按照一定规律进行分类训练。定义二进制比特集合的不同误差分布:
(9)
训练数据集
,每个BP译码器都有一个独立的数据集:
(10)
汉明距离主要应用在通信编码领域上,常用于制定可纠错的编码体系。在机器学习领域中,汉明距离是一种常用的距离度量方式。当传输码字c为全零码字时,根据译码器接收到的未经译码的信源估计值
计算出非0比特的个数,作为二进制错误比特数据区分的依据:
(11)
3.2.2. 强学习器
强学习器是通过一定的方式对弱学习器集成,达到超越弱学习器性能的组合体。集成学习的结合策略主要有平均法、投票法和学习法。平均法是将各个弱学习器的输出进行平均或加权平均,作为集成学习的结果。投票法则是对各个弱学习器的输出投票打分,将投票结果作为集成学习的输出。学习法是将所训练出的弱学习器的学习结果作为输入,重新训练一个更好的学习器来得到最终结果。经过独立数据集训练出具有不同权重参数的WBP译码器相比于传统BP译码算法已经具有很大的译码优势,同时为了符合译码的特点,采用了类似BPL译码器的组合策略。
BPL译码算法基于不同排列的因子图来实现L个并行的BP译码器译码,除了随机选择,列表的选择可以基于多种方案,如最小欧式距离路径选择、和积路径选择、基于码字权重的路径选择等方案。这些选择方案是为了从多个BP译码器中筛选出译码性能最好的结果输出。但其并不能将BPL译码器看作是BP译码器的集成,因为BPL译码器提供的更多是一种广度搜索的可能,并没有集成为强学习器的功能。显然,集成学习是通过构建并结合多个弱学习器来完成学习任务,多个经过训练的弱学习器集成起来就是一个强学习器。更重要的是,BPL译码器的输入是相同的,利用一定规则来决定哪条路径更可能为正确译码。所以基于BPL译码器的思想,新提出一种学习器筛选机制作为结合策略,这种结合策略的目的是得到一个广度的搜索空间,以便于所提出的译码器可以适应更复杂的信道环境。
极化码译码的过程,受到信道环境的变化,理论上不存在绝对完美的译码器,译码器的译码结果只是译码的一种概率。为了获得更好的译码性能,利用学习器筛选机制从这
个学习器里选出译码性能更好的
个学习器,并将这些由不同权重参数的WBP译码器组合而成的学习器,称为强学习器,即E-WBP译码器。
所以E-WBP译码器组成不同于常用的集成学习结合策略,而是在广度上增加译码成功的选择,提高更多的译码可能。学习器的筛选机制可以借助BPL译码算法路径选择中一种常见简单的算法,即最小路径选择算法来筛选。测试集由随机二进制消息经过编码、二进制相移键控(BPSK)调制并通过AWGN信道传输后生成。定义u为测试集传输码字,
,定义c为码字经过BPSK调制
,然后经AWGN信道传输,则接收到的信息序列
,其中
,
。计算欧式距离:
(12)
将上式展开:
(13)
利用测试集,计算最小欧式距离,从
个学习器里筛选出
个学习器组成E-WBP译码器。
3.3. E-WBP译码算法流程
基于集成学习的BP译码器,该译码器集成了WBP译码算法和BPL译码算法的优势。E-WBP译码算法流程如图7所示。
独立数据集:训练数据集采用全零码字,为了形成独立的数据集,对信道传输后得到的信源序列y进行硬判决,从而得到未经译码的码字估计
,计算出二进制错误比特,再根据二进制错误比特的分布进行分区。为方便算法实现,采用简单的汉明距离来区分数据集。从而得到利用汉明距离分类器对训练数据集进行采集,形成不同的子数据集
。
WBP译码器参数训练:由不同的子数据集独立训练出WBP译码器
,
,
,
,
表示第
个子数据集,
为训练的参数,神经网络模型采用DNN网络 [19] ,共训练出
个弱学习器,网络中采用的二进制交叉熵损失函数来衡量WBP译码器的输入值和期望值的差距,并通过两者的差距来优化译码器的权重参数,得到译码性能更优异的译码器,其中输入值和期望值都是全零码字。权重参数的训练的最终目的就是最小化损失函数并得到最优的权重参数。二进制交叉熵损失函数
:
(14)
学习器筛选:由随机二进制消息生成测试集,并计算弱学习器译码后的最小欧式距离,筛选出
个弱学习器
组成E-WBP译码器。组成E-WBP译码器的权重参数
都可以进行离线训练。
E-WBP译码:E-WBP译码器接收到的信号序列
,离线训练得到的权重参数传至BP译码器,形成
个WBP译码器,同时也是集成后的强学习器(E-WBP译码器)。接收到相同的接收信号后,译码得到
个估计序列
,再利用生成矩阵的早停机制提前终止译码,最后再利用欧式距离判决来对候选码字进行判决输出最后的译码码字
。
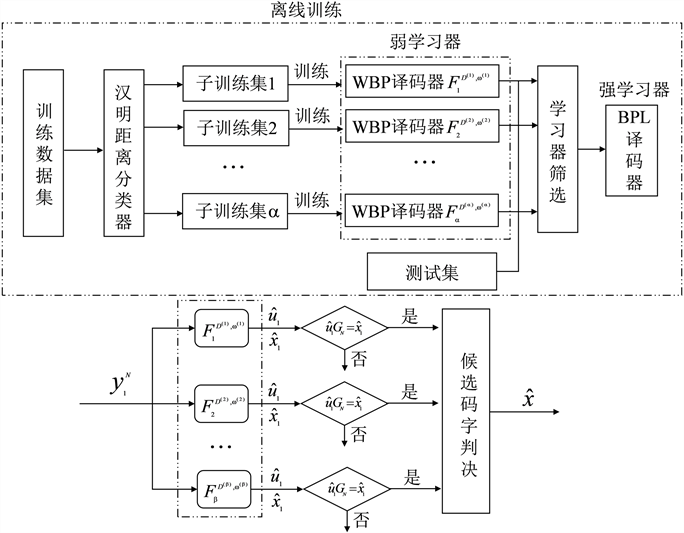
Figure 7. Schematic diagram of E-WBP decoding algorithm
图7. E-WBP译码算法流程示意图
4. 仿真结果与分析
由于弱学习器
可以采用离线训练形式,其训练过程的计算复杂度可以忽略。在训练过程中,每个WBP译码器最多迭代T次,每个最小计算单元会含有4个参数,每个弱译码器训练出
参数,N为码长,一般码长固定为{64,128,256,512,1024},E-WBP译码器需要离线训练
权重参数。学习器的筛选只是对训练出来的弱学习器进行评价,以便组合成强学习器,这里忽略其带来的复杂度。另一部分复杂度主要来自E-WBP译码过程中,E-WBP译码与BPL译码的过程相似。而BPL译码器的计算复杂度是
,同时极化码采用生成矩阵的早停机制,需要在每次迭代后检查估计的信源序列与码字估计的生成关系,是否满足
,如果满足条件,停止译码,其复杂度为
。所以E-WBP译码器在译码过程中的计算复杂度为
,空间复杂度为
。
如图7所示,E-WBP译码器由离线训练产生,主要包括权重参数的训练和测试。训练样本设置传输码字为全零码字,经过BPSK调制为全1序列,传输信道为AWGN信道,再根据接收到的信号
计算出对数似然比
,得到未经译码的全零码字估计值
,再由汉明距离区分为
个独立的数据集。训练阶段中
个WBP译码器每个训练批次包括10000个样本,每个样本由特定的信噪比
等概率生成。测试数据由随机信息序列编码生成,采用高斯近似构造,经BPSK调制后在AWGN信道上传输。训练好的弱学习器再经过测试集,再利用学习器筛选机制筛选出
个WBP译码器用于组成E-WBP译码器。设置
,
,组成E-WBP译码器。使用PyTorch框架搭建神经网络,使用NVIDIA GeForce RTX 3090显卡加速训练。弱学习器的训练参数如表1:

Table 1. WBP decoder training parameters
表1. WBP译码器训练参数
为了评估本文所提算法的译码性能,对该算法在不同码长情况下进行仿真模拟。首先仿真码长为
,
的BP、BPL [5] 、WBP [19] 和E-WBP译码算法的FER性能。迭代次数均为6次,BPL译码算法的L为4,与E-WBP译码算法的
相匹配。
由图8可以看出,在相同迭代次数时,传统的BP译码器FER性能弱于经过神经网络训练得到的WBP译码器,WBP译码器稍弱于于
的BPL译码器译码性能,但优势在于WBP占用更少的译码空间。E-WBP则具有接近于BPL的译码性能。图9则是对码长
,
的极化码的4种译码算法对比,可以看出E-WBP译码算法已经取得了与BPL相同的译码性能,同时相较于
时,译码性能具有0.3 Db的增益。另一方面,传统的的BP译码算法和BPL译码算法,消耗的计算资源多,时延较长,而E-WBP译码算法离线训练所需要的计算复杂度和存储空间占用少,以更少的迭代次数取得更好的译码性能,更适合部署在实际通信系统中。
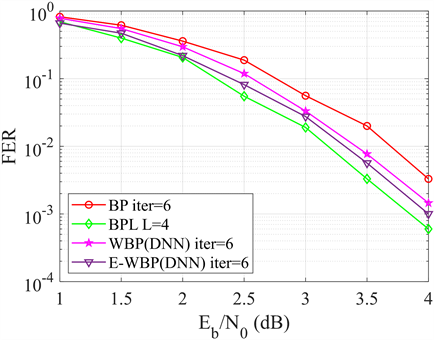
Figure 8. Comparison of FER performance of four decoder algorithms for polarized codes (256, 128)
图8. 极化码(256, 128)的4种译码器算法FER性能对比

Figure 9. Comparison of FER performance of four decoder algorithms for polarized codes (512, 256)
图9. 极化码(512, 256)的4种译码器算法FER性能对比
5. 结束语
本文提出一种基于集成学习的极化码BP译码算法,该算法通过集成WBP译码来构建强学习器形成新的译码器,达到由于WBP译码器的目的。同时,该算法利用离线训练,并且可以实现参数共享可以有效地减少内存开销和迭代次数。仿真结果表明,该算法在译码性能和复杂度之间取得良好的平衡,取得了与BPL译码器接近的译码性能。