1. 引言
图像恢复是计算机视觉、图像处理的基本问题之一,是图像处理与分析的基础,其目的是依据图像退化模型由观测图像恢复出理想图像。图像退化模型通常为图像出现模糊、失真的条件下附加额外噪声。作为非适定性的逆问题,其解不唯一,而变分法是解决这种病态问题的有效的经典方法 [1] 。该方法作为图像处理领域中的一类基础性方法,具有完善的数学理论体系,可通过最小化能量泛函对问题求解。对于能量泛函的求解,存在多种方法。Perona and Malik采用梯度下降法对非线性扩散方程求解 [2] 。为简化计算、提高计算效率,Chalasani等设计了临近梯度下降法(PG: Proximal Gradient Method) [3] ,Chan等设计了交替方向乘子法(ADMM: Alternating Direction Method of Multiplier) [4] ,Ono设计了原始对偶变量方法(PD: Primal-Dual Method) [5] 。这些优化方法具有较好的可解释性,且在执行过程中无需大量数据便可获得有效结果。但该类方法往往需要引入可调整的惩罚参数,模型的计算需反复次迭代完成。
基于变分模型算法展开策略设计深度学习神经网络是解决上述困难的有效途径 [6] 。Gavaskar等将迭代收缩阈值算法(ISTA: Iterative Shrinkage Thresholding Algorithm)展开为具有可学习参数的深度神经网络(PnP-ISTA: Plug-and-Play Iterative Shrinkage Thresholding Algorithm)以解决线性逆问题 [7] 。Zhang等训练一组快速有效的卷积神经网络去噪器作为模型先验,利用半二次分裂法(HQS: Half Quadratic Splitting)将其集成到基于模型的优化方法中,以解决不同的逆问题 [8] 。该算法因解耦保真度项和正则化项带来的简单性和快速收敛性被大量应用,解耦之后可得到规则项相关的高斯去噪器。
对于去噪器,可采用成熟模型作为先验应用到网络中,如Zhang等基于多个卷积与激活块结合,提出了利用IRCNN设计去噪器的方法 [8] ,又通过残差网络与批量归一化设计了DnCNN框架 [9] ;在FFDNet增加噪声映射图的基础上 [10] ,DRUNet模型将残差块整合到U-Net中,实现有效的去噪先验建模 [11] ;为确保观测一致性,DPDNN设计了一个简洁的U-Net子网络作为去噪器 [12] ,并与图像重建模块共同组成图像恢复的深度学习神经网络。此类模型不仅利用了DNN强大的去噪能力,即插即用的特性使得参数只需训练一次便可直接应用到其它图像任务中。尽管如此,这种经典的深度学习模型往往需要大量小尺寸卷积核与传统激活函数ReLU (Linear Rectification Function)等来实现非线性近似,其层数较深,参数量较大。
上述变分模型的规则项与其梯度降偏微分方程的扩散项对应,通过对扩散项的有效近似可设计紧凑、高效的深度学习网络。Chen等引入专家场模型(FoE: Fields of Experts)作为规则项 [2] [13] ,并将相应的非线性反应扩散模型中的扩散项用流函数表示,该流函数可设计为用径向基函数近似的神经网络激活函数。根据传统差分算子与卷积核的对应关系,文献 [2] 还基于离散余弦变换(DCT: Discrete Cosine Transformation)基设计了不同通道中的卷积核 [14] 。所设计的可训练非线性反应扩散网络(TNRD: Trainable Nonlinear Reaction Diffusion)具有较好的可解释性,并具紧致、高效特点,但DCT基仅包含图像变化的频谱特性,不能反映图像变化的尺度、方向等信息,而Gabor基函数包含了上述三类信息,并已在图像识别等应用的特征提取方面显现优越的性能 [15] [16] [17] 。
受此启发,本文将采用Gabor基函数设计卷积核,并在变分模型的半二次分裂迭代算法展开基础上设计端到端的图像恢复深度学习神经网络,其中的激活函数采用通用的高斯径向基函数近似。
2. 基于Gabor基与算法展开卷积神经网络的图像恢复模型
2.1. 图像恢复模型
图像退化模型为:
(1)
其中,y为观测图像,x为理想图像,n为噪声,A代表不同的退化问题。当A是子采样矩阵算子时,图像恢复问题为超分辨率问题;当A为模糊矩阵算子时,图像恢复问题为去模糊问题;当A为单位矩阵时,图像恢复问题为去噪问题。
公式(1)对应的图像恢复变分模型为:
(2)
其中,
为数据项,表示图像恢复前后的相似程度,
代表规则项,决定图像的恢复质量,
为惩罚参数。
2.2. 半二次分裂框架
引入辅助变量v,令
,(2)转化为:
(3)
为新引入的惩罚参数,对公式(3)交替优化得:
(4)
其中第一个子优化问题的梯度下降法求解公式为:
(5)
第二个子优化问题对应非线性扩散过程。当采用FOE规则项
(6)
时,其解与以下扩散模型对应
(7)
流函数表示为
,并对时间变量差分采用显式Euler法得到与残差网络结构对应的迭代格式:
(8)
其中,
和
分别代表基于Gabor基函数和高斯径向基函数设计的卷积核、激活函数。
为卷积核个数,t代表网络层数。
2.3. 基于Gabor基函数的卷积核设计
为克服傅里叶变换全局频域分析的缺点 [18] ,Gabor提出了称之为Gabor变换的加窗傅里叶变换。这是一种正弦函数调谐的高斯函数,即将信号划分出多个小的时间间隔,并通过傅里叶变换逐一进行处理,来确定信号在该时间间隔存在的频率。Gabor核函数可以在保留空间关系信息(时域)的同时,表示图像中的空间频率结构 [17] 。定义为:
(9)
其中,
、v分别代表方向和尺度参数,分别控制核信息的旋转角度与频率,
为
的
范数,
。
为保证不同通道的基函数之间具有足够差异性,在卷积时能够获取更多图像信息,本文将v和
嵌入到同一层网络的基函数中。实验针对不同方向尺度的组合设计了48组基函数,其中,选择n个不同的尺度,方向在0~π中等距取值,个数为48/n。
若所选择的Gabor基函数组为
,则不同网络层的各通道设计的卷积核为
(10)
其中,
为训练参数,
。
 −3−2−1 0 1 234 5 67
−3−2−1 0 1 234 5 67
Figure 1. Gabor basis functions corresponding to different scales (−3~7)
图1. 不同尺度(−3~7)对应Gabor基函数
为选择适当的Gabor基函数组,暂固定角度,并将不同尺度对应的基展示如图1。直观的观察可发现:当尺度在−2~4范围内信息变化较为明显,而随着尺度的增加,它们间的差异逐渐变小;当尺度为−3时,核含信息较少,无法携带足够的方向等信息。所以,下面的实验将在−2到4的范围附近选择尺度。以上的可视化思想在Zhang的研究中针对图像分类设计的神经网络中应用,能够提取更多图像特征 [17] 。
为调节Gabor基函数所涉及的权重以自适应网络,在编码卷积时,使用相同维度的学习滤波器与Gabor函数组通过凸组合生成特征卷积核。学习滤波器作为参数矩阵在反向传播时独立学习,基函数之间存在信息差异以及函数组的网络共享使得在相同网络层之间,不同通道的卷积核互不相同;不同网络层之间,卷积核特征相似但相互独立。如图2所示。
 Learned Filters Basis Functions Filters
Learned Filters Basis Functions Filters
Figure 2. Design process based on Gabor-based convolution kernel
图2. 基于Gabor基卷积核的设计过程
2.4. 基于高斯径向基的激活函数近似
考虑到高斯径向基函数(RBFs: Radial Basis Functions)的简单、通用,且在学习过程收敛速度快、泛化能力强等特点 [2] ,本文用高斯径向基函数的组合近似激活函数,其公式为:
(11)
(12)
其中,M是总的插值点个数,j为插值点,i代表通道数,标准差为
,
对应每个基函数的中心点,以等距的方式分布在
中。
2.5. 损失函数
在有监督的方式下,通过输出图像与真实图像之间的差异设计损失函数来训练网络。给定
为网络输出,
为真实清晰图像,得到损失函数:
(13)
2.6. 网络设计
图3为公式(6)所对应整个网络层的算法流程。针对其中的扩散模块,即公式(9),其子网络如图4所示。

Figure 3. The entire feedforward network process
图3. 整个网络算法流程
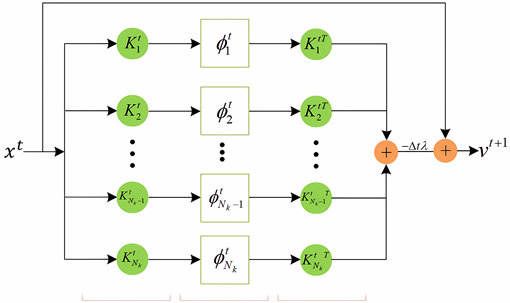
Figure 4. Diffusion structure based on Gabor basis function
图4. 基于Gabor基函数的扩散结构
3. 数值实验中网络超参数分析
本文模型训练与测试均在NVIDIA GeForce TEX 2080 Ti版本的GPU上进行。由于卷积操作会缩小图像,为保证输出图像大小与原图像一致,实验选取对称填充的方法复制边缘像素将图像长宽分别扩大12像素。
对于其它参数的设置,相邻两个Epoch选择较高峰值信噪比(PSNR: Peak Signal-to-Noise Ratio)进行参数保存;每三个Epoch降低一半的学习率,初始学习率为lr = 1e−3。
3.1. 层数与卷积核大小
在应用图像处理任务之前,以Set12为训练测试集来选择合适的网络层数与卷积核大小 [12] 。下图5是相关参数的PSNR折线图。为控制变量,当比较卷积核时,固定层数为5层,而选择层数时,固定卷积核大小为7 × 7。针对卷积核的大小,由图(a)看出,感收野越大,网络的性能越好,但当卷积核大于7 × 7时,性能无法再得到有效提升。对于网络层数的选择,根据图(b)发现,随着层数的不断加深,PSNR持续提高,而对应层数为5时,PSNR提升幅度最大,故根据性能与效率的综合衡量,以下实验将设置卷积核尺寸为7 × 7,网络层数为5层。
3.2. 基函数设置
对于一个DCT特征的卷积核,其能获取图像在某个频率邻域的响应情况,Gabor作为基于DCT的加窗傅里叶函数,在频率信息的基础上,加入了尺度、方向等信息,执行卷积操作时能够提取更多图像特征,实现良好的先验形式。图6中的(a)与(b)分别为两种基函数对应训练后的卷积核。由观察看出,(a)存在一定数量的小作用域卷积核,对应图(b)较少,(b)中更多的是高阶求导的卷积核,并且具有充足的方向、尺度等信息。因此Gabor基在信息提取方面有着更高的使用价值。
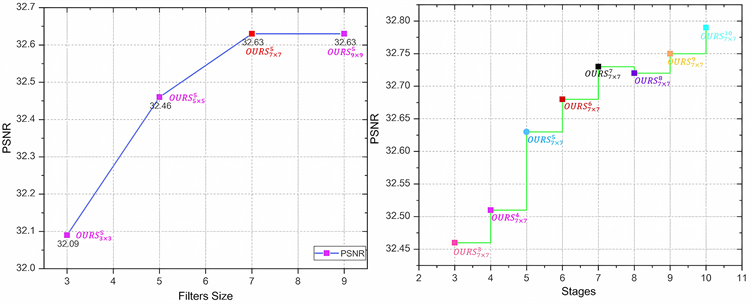 (a) Filters Size (b) Stages
(a) Filters Size (b) Stages
Figure 5. Performance comparison of different size convolution kernels and different network layers
图5. 不同大小卷积核与不同网络层数的性能比较
 (a) 基于DCT的卷积核
(a) 基于DCT的卷积核 (b) 基于Gabor的卷积核
(b) 基于Gabor的卷积核
Figure 6. Display of convolution kernel of DCT and Gabor in the first stage
图6. DCT与Gabor基的卷积核在第一层框架的图像展示
为比较两者性能,以TNRD为框架,用Set12作为训练集,BSD68为测试集进行实验验证 [13] 。由表1的实验数据可知,由Gabor基得到的PSNR值基本高于DCT函数。

Table 1. The performance comparison of Gabor and DCT basis functions and Gabor basis functions corresponding to different parameters at noise level σ = 15
表1. Gabor与DCT基函数以及不同参数对应的Gabor基函数在噪声级σ = 15的性能比较
此外,本文还比较了不同参数对应的Gabor核的去噪能力。为充分筛选参数,将尺度、方向个数分别设置为8、6,6、8和4、12。其中,尺度大体范围设置在−1~5,视其个数决定间隔大小。方向参数在0到π范围内等距选择。设置[a, b, c],代表在a ~ c范围中,每间隔b选择一个尺度。据表1的实验数据,当尺度范围为[1, 1, 6]、方向为8与尺度为[−2, 1, 5]、方向为6时,PSNR值达到最高。
为防止选择参数过程中易出现相同的基函数,本文所有实验的参数均建立在尺度与频率呈正比的关系上。对于不同的恢复任务,为调节出最优参数,可根据性能在一定范围内改变两者的正比关系以确保获得更多频率信息。
4. 实验结果与分析
为保证参数量一致以及排除其它因素的影响,凸显TNRD与GBAUCNN即本文模型的可比性,以下关于TNRD的实验数据均为自己训练得出,其中设置参数量与GBAUCNN相等,包括径向基函数31个、卷积核48个。
4.1. 图像去噪
本文使用文献 [2] 中400张180 × 180的图像作为训练集,进行裁剪、随机旋转等预处理操作,生成40 × 40像素图像块作为输入样本。其中,旋转包括上下翻转、旋转180度、270度以及逆向旋转90度。为评估模型的去噪性能,采用广泛用于高斯去噪测试的数据集Set12和Berkeley分割数据集BSD68作为标准测试数据集 [13] 。
实验主要针对高斯噪声的去除。对于单级别去噪网络,将图像分别加入σ = 15、25和50的高斯噪声。为验证网络有效性,对比实验选择几种较为先进的去噪算法,如BM3D、EPLL、CSF、MLP和TNRD [2] [19] [20] [21] [22] ,并且以峰值信噪比(PSNR)作为客观评价标准。
由表2、表3数据可得,TNRD模型在各个噪声水平下的性能明显优于BM3D、EPLL、CSF传统模型。在Set12中,MLP与TNRD基本持平。本文模型GBAUCNN能得到比TNRD更高的PSNR。根据表2的数据,当噪声级为15、25和50时,GBAUCNN的PSNR分别提高0.14 dB、0.07 dB和0.07 dB。图7、图8和图9为算法去噪结果的展示。σ = 15时,根据图7框中图像的放大效果,(b)没有保留住城堡的整体轮廓,(a)、(c)相比(b)虽保留了图像信息,但没有实现良好的去噪。(d)的去噪效果优于(a)、(b)和(c),但依旧有一些噪声残余,而(e)能够在保留图像信息的基础上更好的去除噪声,获得更平滑的图像。对于σ = 25,由图8看出,EPLL、BM3D、CSF、WNNM等传统模型能实现一定的去噪效果,但得到的边缘模糊。TNRD的去噪图像虽细节清晰,但是信息保留较少。GBAUCNN在去噪的同时边缘细节保留得更加细致充足,达到了更好的视觉效果。噪声级为50时,根据图9,TNRD获得的图像(c)相对于(a)和(b)而言更加清晰,但框中的人物面部细节依旧不足,(d)得到的面部表情则更加清楚自然。由此可知,以Gabor基为卷积先验的基础,GBAUCNN模型在实现去噪的同时能够获得更清晰的边缘信息。
Table 2. Comparison for PSNR of noise removal for Set12 by different algorithms
表2. 不同算法对Set12消除噪声的PSNR比较
Table 3. PSNR of different models on dataset BSD68 at different noise levels
表3. 不同模型对数据集BSD68在不同噪声级别上的PSNR
 (a) BM3D
(a) BM3D  (b) EPLL
(b) EPLL  (c) TNRD
(c) TNRD  (d) GBAUCNN
(d) GBAUCNN
Figure 9. Comparison of denoising at noise level σ = 50 with different algorithms
图9. 不同算法在噪声级σ = 50中去噪对比图
由于所提出框架的广泛适用性以及以Gabor为基础的扩散过程具有强化边缘、清晰图像的效果,作为扩展,本文模型将应用到图像超分辨率、图像去模糊与彩色去噪任务中以验证性能。
4.2. 图像超分辨率
对于退化矩阵A,引入双三次插值的方法实现 [23] 。考虑到各邻点间灰度值变化率的影响,该算法利用待求像素坐标反变换得到的浮点坐标周围16个邻近像素的权重,与对应像素点的灰度值作加权线性求和得到。双三次插值是一种较为复杂的插值方式,它能创造出比双线性插值更平滑的图像边缘,得到更接近高分辨率的图像效果。
在训练模型时,选用开源超分辨率重建数据集DIV2K中的800张训练数据与对应比例因子分别为2、3的低分辨率数据作为HR/LR训练集。本次实验只针对图像的亮度分量,因此,在预处理时,选择图像由RGB模式转化成YUV模式的第一维作为输入。实验采用 [12] 中的数据Set5、Set14、Urban100和BSD100对模型进行评估。
表4为四种算法在超分辨率问题上性能的比较,包括PSNR与结构相似性(SSIM: Structural Similarity)。通过分析可以看出,Bicubic与SR-CNN模型得到的PSNR值较低 [24] ,而TNRD略有优势,GBAUCNN模型在TNRD的基础上能得到更高的PSNR值。特别的,当比例因子为2时,表中各个数据集对应的PSNR指标分别高出0.08 dB、0.05 dB、0.15 dB以及0.06 dB。对于SSIM指标,几种算法生成的图像结构与原图像相似度大体相同,这意味着输出图像的结构在没有失真基础上都达到了较好的图像处理效果。图10为四种算法的图像展示,根据整体图像与框中放大部位的鸟喙处,SR-CNN算法对应图像比Bicubic要更加清晰,但与TNRD和GBAUCNN相比则较为模糊。本文模型依旧保留了更多的细节纹理,图像效果更加清晰真实。
Table 4. Comparison of the average performance (PSNR, SSIM) of different methods on the test set Set5, Set14, Urban100 and BSD100
表4. 不同方法在测试集Set5、Set14、Urban100以及BSD100平均性能(PSNR, SSIM)的比较
 (a) Bicubic
(a) Bicubic  (b) SRCNN
(b) SRCNN  (c) TNRD
(c) TNRD  (d) GBAUCNN
(d) GBAUCNN
Figure 10. Results of different algorithms for Set5 images
图10. 不同算法针对Set5图像的展示结果
4.3. 图像去模糊
为进一步验证模型的通用性,将实现TNRD与GBAUCNN的非盲去模糊实验。采用标准偏差为1.2、1.6以及2.0,大小为25 × 25的高斯模糊核进行实验。对于模糊之后的图像,加入标准差为2的高斯噪声得到输入图像。本文采取边训练边处理的预处理方式,将图像随机裁剪成64 × 64的图像块并模糊。选取DIV2K中的800张灰度图像作为训练数据,Set10作为测试数据,以此评估模型性能。
本文将GBAUCNN与IDD-BM3D [25] 、EPLL、TNRD进行性能的比较。表5列举了模糊核标准差分别为1.2、1.6和2.0的实验数据,其中,固定噪声级为2。根据表中的结果,EPLL与其它模型相比数据最低,TNRD比IDD-BM3D占优势。对于这三种不同的模糊核,GBAUCNN的峰值信噪比高TNRD模型平均0.1 dB左右。
Table 5. Comparison of the average performance of different methods on the test dataset Set10
表5. 不同方法在测试集Set10平均性能的比较
灰度图像上针对高斯模糊的效果展示如图11。在第一幅图的比较中,EPLL与BM3D在眼睛处略微模糊,整体图像也不够平滑。TNRD虽能得到较为光滑的图像,但框中的放大部分依旧不够清晰,GBAUCNN能够维持图像细节,在整体良好的视觉效果基础上保持足够的边缘信息。对于Lena图像的去模糊结果,可以看到(c)、(d)的面部表情稍微变形,(b)、(e)能较好地维持,且(e)图像具有更加清晰真实的视觉效果。
4.4. 彩色图像去噪
与灰度图像不同,彩色图像存在3个通道R、G、B,而本文执行的特征图固定通道为48,所以在操作之前,用大小为1 × 1的卷积核,将图像从3通道卷积成48通道,同时图像大小保持不变。为与真实的清晰图像对应,在去噪后的输出操作中用相同的方法将特征图卷积成通道为3的输出图像。本文以Berkeley分割数据集中的200张自然图像作为训练集,采用与图像去噪同样的预处理方式得到40 × 40的729,000个图像块,并随机进行图像旋转、翻转等操作实现图像增强。以下数据将采用CBSD68数据集与Kodak24作为测试集进行模型之间的比较。其中,CBSD68为伯克利分割数据集和基准的一部分,共包含68张图像,是用于图像去噪基准的彩色数据集,而Kodak24为数字图像处理常用数据集,大小为500 × 500的24张彩色图像。
σ = 15
由表6中的数据可知,对于以上两种数据集,GBAUCNN对比TNRD有着明显的优势。在CBSD68中,GBAUCNN模型在不同噪声水平下高于TNRD模型0.06 dB、0.13 dB和0.09 dB,而对于Kodak24数据集能高出0.24 dB、0.13 dB以及0.10 dB。根据图12的图像对比展示,噪声级为15、25时,从整体的视觉效果看,三种模型都能得到较好地去噪效果,但CBM3D去噪并不够彻底 [19] ,放大部分依旧残留少量噪声,TNRD与GBAUCNN在此方面更具优势,GBAUCNN还能获得更多的纹理信息。对于噪声级为50的图像,TNRD、GBAUCNN在清晰度与亮度方面均强于CBM3D,两者对于豹纹具有较高的边缘保持。同时,本文模型去噪效果更加明显,图像背景更加光滑。
Table 6. Comparison of PSNR values of different models at different noise levels
表6. 不同算法在不同噪声级的PSNR值比较
5. 结论
本文设计了基于Gabor基算法展开卷积神经网络的图像恢复模型。其算法展开基于图像恢复变分模型的半二次分裂方法,所分离出的扩散模型可用于设计高斯去噪器网络。卷积核基于Gabor基设计,能有效提取更多图像特征。针对多个标准数据集的实验表明,本文方法在图像噪声去除、超分辨率、去模糊等图像恢复方面综合性能指标超过现有相关深度学习方法。此外,所提出的网络构架和基于Gabor基的特征提取方法还可方便地应用于其它图像恢复任务的深度学习网络设计。在基函数组的选取中,本文并不能充分保证参数选择为最佳方式,因此未来工作可致力于探索如何处理不同基函数使得在信息不被破坏的前提下达到差异最大化。
致谢
在这里,我要以最诚挚的心意感谢潘振宽、魏伟波教授,感谢他们在我完成硕士论文的过程中提供的一切帮助,无论是指导研究课题的创新点,还是语言的润色,都让我收益匪浅。除此之外,还要感谢实验室的博士师哥、同级研究生和宿舍的伙伴,无论在学习上、生活上,还是论文课题上,都给予了我无私的帮助和热心的照顾,这将成为我研究生生涯最美好的风景。感谢国家自然基金和山东省联合基金以及本文引用的文献资料等的作者对我论文的大力支持。感恩之情难以用言语度量,谨以最朴实的话语致以最崇高的敬意。
基金项目
国家自然基金“曲面上图像处理的非局部变分模型与算法”(编号:61772294)和山东省联合基金“基于分布式FDGA平台的深度学习模型并行技术研究”(项目编号:ZR2019LZH002)。
NOTES
*通讯作者。