1. 引言
COVID-19疫情自2020年全球爆发以来 [1] ,对全球经济和人民的生命安全造成了极大的威胁。随着疫情的不断发展,各国政府采取了各种防疫措施来应对疫情,然而这些措施的有效性并不相同。因此,本文通过新冠肺炎预测模型选择和防疫能力评价,对各国防疫措施的有效性进行了研究和分析。
本文采用时间序列ARIMA模型对疫情进行了分析预测 [2] 。在经典的传染病动力学模型下,本文结合潜伏患者和死亡率等因素,建立了SEIRD模型对疫情进行预测。此外,本文还使用多种机器学习模型与滚动预测方法相结合,从而提高模型的精度,并通过平均绝对误差(MAE)来度量模型的预测精度。最后,本文还采用多变量LSTM模型对疫情进行预测,并在LSTM深度学习和多种机器学习的基础上建立了赋权组合模型,以得到更加准确的预测结果。本文还分析了感染率的影响因素,并采用多元线性回归模型分析各区域的防疫能力。在考虑人口密度分布的情况下,本文量化评价了我国各个区域的防疫能力,并从感染率的影响因素的不同角度提出了疫情防控工作的可行性建议,形成了一种精细的防疫模式。结果表明,有效的防疫措施可以有效控制疫情的传播,减少患者数量和死亡率,并为经济复苏提供了条件。在本文所采用的预测模型中,赋权组合模型的预测效果最好。因此,我们可以得出结论,通过综合运用时间序列分析、传染病动力学模型、机器学习算法和多元线性回归模型等方法,可以有效预测疫情,并评估各国防疫措施的有效性。另外,本研究还分析了各国在疫情期间采取的不同防疫措施的有效性,并结合SEIRD模型的预测结果进行评估。结果显示,一些措施如限制人员流动、加强社交距离等能够有效控制疫情传播,而一些措施如禁止公共聚集、关闭商业场所等虽然能够减少疫情传播,但对于经济影响较大。此外,一些措施如检测、隔离和追踪确诊病例等也被证明是有效的防疫手段。
综合分析结果,本研究认为,有效的防疫措施可以有效控制疫情的传播,减少患者数量和死亡率,并为经济复苏提供了条件。因此,各国应当继续加强防疫措施,包括但不限于限制人员流动、加强社交距离、加强检测和隔离等,以确保疫情得到控制,并在逐步恢复经济的过程中采取有效的措施,以避免出现二次爆发。另外,本研究提出了一些针对感染率影响因素的建议,如加强公共卫生意识,提高人们的健康素养等。总之,本研究通过多种预测模型和评价方法,对新冠肺炎疫情进行了全面研究和分析,为各国在防疫措施上提供了有益的参考,对于应对突发公共卫生事件具有一定的指导意义。同时,本研究还发现了一些有价值的问题,如各种防疫措施的有效性和经济影响等,这些问题值得进一步深入研究。
2. 预测方法
我们采用SERID、机器学习和LSTM分别预测疫情,根据得到的结果综合分析,选择一个最好的模型来预测疫情。
2.1. SEIRD预测
在已有的新冠疫情预测模型成果基础上,我们通过大量搜集和阅读本课题相关资料和数据,针对不同模型进行了相关的优化,主要对四个方面进行了研究:
2.1.1. 传统SEIR模型
SEIR是在SIR模型上面进行改进。SIR是易感者S被传染者I所感染,然后被治愈好称为移除者R(即治愈好不会在被感染的和死亡的)。在此基础上,如果所研究的传染病有一定的潜伏期,与病人接触过的健康人并不马上患病,而是成为病原体的携带者,归入E类 [3] 。此时可以建立微分方程:
(1)
(2)
(3)
(4)
守恒关系
。
根据查阅资料设置初始参数,绘制出以下的SEIR图,见图1:
2.1.2. 基于改进后的SEIRD模型
根据疫情期间的报告,存在着很多潜伏患者传染人的事件,所以传统的SEIR解决不了这类问题,所以我们基于SEIR上加上潜伏期患者感染易感者的概率β2和每天患者接触的人r2,所以得到每天潜伏期患者传染
人。在此之外,在疫情严重的时候,死亡人数也很多,为了方便研究,在SEIR上加上了死亡概率p,得到每天死亡人数p [4] [5] 。
以下为符号说明,以及根据查询的资料设置参数,然后确定概率参数、设计SEIRD模型。
建立微分方程:
(1)
(2)
(3)
(4)
(5)
综合分析每个参数,并根据实际情况,给出每个符号的初值,见表1。
采集印度的COVID-19感染者统计数据进行探索性分析,将COVID-19感染者统计数据和采用SEIRD模型模拟的结果进行对比,从数据走势可看出,实际数据曲线趋势与SEIRD曲线趋势相同,表明SEIRD模型能够有效反映COVID-19感染者数量的发展趋势。COVID-19存活时间为2~14 d,将平均潜伏期定为符合报道的7 d,死亡率设置为2%。在采取严格的防控措施下,感染者数量峰值显著降低,疫情高峰更早地到来。采用SEIRD模型,对重新调优后的模拟感染者曲线进行网格搜索,寻找最优参数。实验得出,β = 0.1、β2 = 0.03、s = 0.14、γ1 = 0.81、γ2 = 0.05,这条曲线拟合效果最好 [6] [7] 。
如下,得出模型示意图,如图2:
则根据以上的参数绘制的SEIRD图,见图3。
分析该模型的特点,在23天的时候感染者达到最大值,然后第50天的时候疫情已经比较平稳,此时几乎没有或者很少的人被感染。从图上得知,在21天的时候潜伏者的数量达到最大值,到感染者达到峰值有2天的时间,说明新冠潜伏者可能就是在患病的第二天就开始传染 [8] [9] 。综合考虑,得出结论:
1) 控制r和r2,即控制感染者和潜伏者接触到的人,所以需要疫情需要将感染者和潜伏者重点隔离。
2) 控制β和β2,即加强预防疫情,戴口罩,多消毒 [10] [11] 。
3) 减小σ和增大γ2,即减小潜伏期患者升级为患者的概率和治愈概率。根据研究表明潜伏者增加身体素质能力,保持乐观积极向上的态度,能增加自愈的能力。
4) 加大γ1,即增大患者治愈的概率。政府医院需要加大对患者的治愈能力 [12] [13] [14] 。
2.2. 机器学习预测
作为数据处理和预测的工具,机器学习算法具备自动学习和提高预测准确率的能力,无需手动调整参数和特征。它可以快速地处理大规模数据,对海量数据进行分析和处理,从而提高数据处理的效率和质量。此外,机器学习算法可以处理非线性关系和复杂的数据结构,并捕捉数据之间的关系,从而提高预测的准确性。这种算法可以应用于多个领域,如金融、医疗、交通等。在这些领域中,它可以提高预测的准确性和效率,减少人工干预和错误率,为决策提供更加科学的依据。因此,我们选择机器学习算法作为我们的数据处理和预测工具 [15] 。
2.2.1. 数据来源和预处理
本研究使用了来自中国卫生部的官方数据,包括每日确诊病例数、每日治愈病例数、每日死亡病例数、每日新增疑似病例数等数据。这些数据是从2020年1月1日开始的,并持续更新到疫情结束。在数据处理方面,我们首先对数据进行了清洗,包括去除缺失值、异常值和重复值。然后,我们对数据进行了可视化分析,以更好地了解疫情的发展趋势和规律。最后,我们使用Python编程语言将数据进行了特征工程和标准化处理,以便于机器学习算法的应用。
2.2.2. 机器学习算法
本研究使用了三种机器学习算法来预测中国新冠肺炎疫情的结果,分别是线性回归、决策树和支持向量机。
线性回归是一种广泛应用于预测的算法,它建立了一个线性模型来预测输出变量和输入变量之间的关系。在本研究中,我们将每日新增确诊病例数作为输出变量,将每日新增疑似病例数、每日治愈病例数和每日死亡病例数作为输入变量进行建模和预测。
决策树是一种基于树形结构的分类和回归算法,它将数据集分成一些小的子集,并生成树形结构,其中每个叶子节点代表一个类别或一个数值。在本研究中,我们将每日新增确诊病例数作为输出变量,将每日新增疑似病例数、每日治愈病例数和每日死亡病例数作为输入变量进行建模和预测。
支持向量机是一种用于分类和回归的机器学习算法,它利用高维空间中的超平面将数据分成两个类别或预测一个数值。在本研究中,我们将每日新增确诊病例数作为输出变量,将每日新增疑似病例数、每日治愈病例数和每日死亡病例数作为输入变量进行建模和预测。
2.2.3. 预测感染人数
我们使用了三种机器学习算法来预测每日新增确诊病例数,并将预测结果与实际数据进行比较。结果表明,支持向量机算法的预测效果最好,其均方根误差为0.2829,决定系数为0.87。线性回归算法的预测效果次之,其均方根误差为0.3159,决定系数为0.81。决策树算法的预测效果最差,其均方根误差为0.4756,决定系数为0.62。
利用支持向量机预测得到的结果,见图4,图5。
虽然机器学习的结果能反映出新增人数的大致的趋势,但是预测的误差比较大,说明机器学习还需要再进一步的改进。
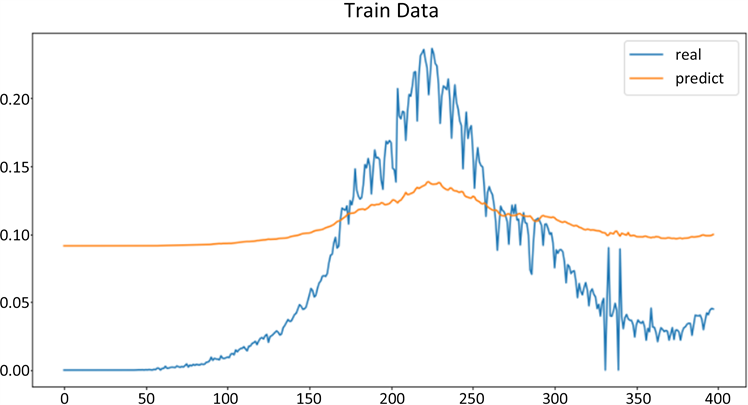
Figure 4. Prediction of support vector machine on the training set
图4. 支持向量机在训练集上的预测
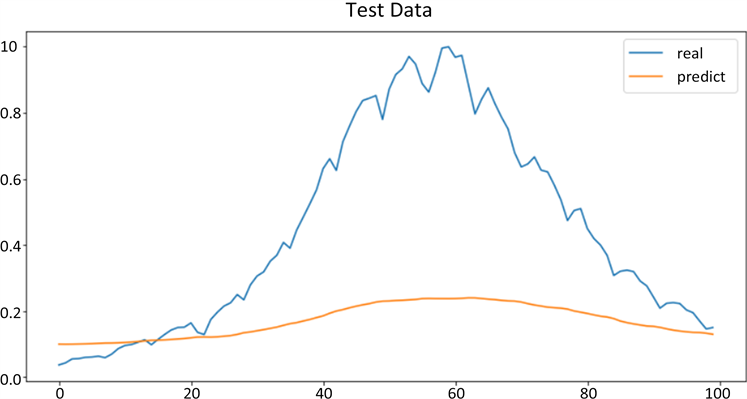
Figure 5. Prediction of support vector machine on the test set
图5. 支持向量机在测试集上的预测
2.2.4. 结论与建议
本研究使用机器学习算法预测了中国新冠肺炎疫情的发展趋势,并分析了影响疫情发展的因素。我们建议政府加强人口流动管控,优化交通状况,增加医疗资源投入,并制定更加有力的政策措施来应对疫情。
此外,我们也需要继续研究和改进机器学习算法,以提高预测的准确性和可靠性。同时,我们需要更加深入地分析不同地区的疫情发展规律和影响因素,以制定更加精细化、有针对性的防控措施,保障人民身体健康和社会稳定 [16] [17] [18] 。
2.3. LSTM预测
由于CNN (卷积神经网络)的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显示的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。LSTM则是特殊的CNN,其具有按时间顺序扩张的特性,在后文的感染人数预测方面具有更好的优越性。
2.3.1. LSTM介绍
长短时记忆网络(Long short-term memory, LSTM)是一种循环神经网络(Recurrent neural network, RNN)的特殊变体,具有“门”结构,通过门单元的逻辑控制决定数据是否更新或是选择丢弃,克服了RNN权重影响过大、容易产生梯度消失和爆炸的缺点,使网络可以更好、更快地收敛,能够有效提高预测精度。它具有记忆功能,所以适合预测时间序列。由遗忘门,输入门,输出门构成。
首先将数据切分,如图2~6,将数据切分为i个样本,时间步长为14,每一个时间步长表示为xt,即有
。并且每个时间步长为3,即[传染率,治愈数,死亡数]。总结起来这个数据集的格式变为(i,14,3),见图6。
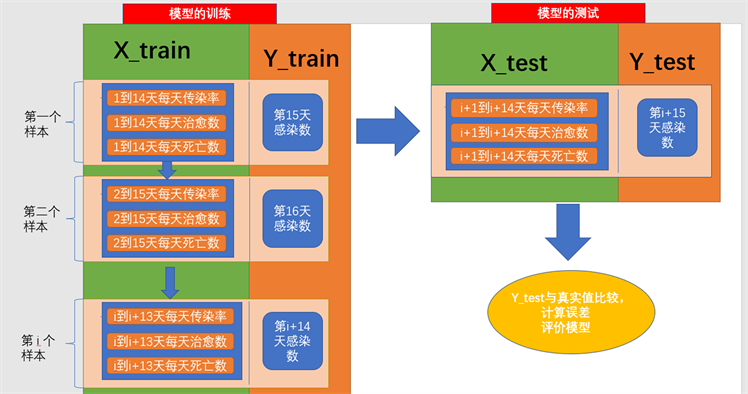
Figure 6. The principle of data splitting
图6. 数据切分原理
LSTM的运行原理,见图7。
a) 遗忘门
遗忘门决定了来自上一时间步的单元状态Ct-1中的多少信息需要忘掉,见图8
其中遗忘门输入的是上一状态的隐藏状态,也就是上一时间步的结果ht-1和当前时间步xt。s表示激活函数,作用是将值映射到0~1之间。Wf是权重,bf是偏置。
最后将得到的结果ft乘以上一步单元状态Ct-1。这里的ft的范围是在[0,1]。当ft趋近于0时,表示忘记所有记忆,同理趋近于1时,保留所有记忆。
b) 输入门
输入门的原理和遗忘门一样。输入门决定了当前处理的时间步中多少信息需要加入到当前的单元状态Ct中。见图9。
根据输入的ht-1和xt得到it,it的范围也是在[0,1]。同理可以得到
,这里的tanh也是一个激活函数,将值映射到[−1,1]之间。最后,见图10,将得到的
与输入门的输出值it相乘,并与经过遗忘门处理的来自上一步的单元状态(ftCt-1)相加,作为下一个时间步的单元状态Ct。
c) 输出门
输出门决定当前单元状态Ct中的多少信息作为处理当前时间步的输出值yt与隐藏状态的值ht。见图11。
2.3.2. 数据清洗,切割数据
结合图6,我们选取印度的数据,假设时间段为14天,即时间步长等于14,介绍LSTM多变量模型的实际操作步骤:
1) 按照训练集:仿制滚筒模型,首先选取第1天到第14天每天传染率、治愈数、死亡数作为第一个混合的训练集,第15天的感染数作为测试集;第2天到第15天每天传染率、治愈数、死亡数作为第二个混合的训练集,第16天的感染数作为测试集,一直怎样往复下去,直至第i个训练集。
2) 使用训练好的LSTM模型对第i+1天到i+14天新增确诊进行预测。
3) 对预测的结果和真实的结果计算MSE误差(均方误差)。
4) 重复以上步骤,选取不同的时间步长,计算出误差,最后找到最小的误差,最为最终的时间步长。
2.3.3. 调参
调整参数时,采用GridSearchCV网格搜索寻找LSTM模型最优参数,以及手动调节训练的步长。
1) batch_size的选择。batch_size定义为一次训练所选取的样本数。batch_size的大小影响模型的优化程度和速度。同时其直接影响到GPU内存的使用情况,假如你GPU内存不大,该数值最好设置小一点。对batch_size在5到32中进行网格搜索,得到最好的batch_size为6最好。
2) 迭代次数的选择。首先假定迭代次数为300。按照上述样本和batch_size等于6进行训练,得到的训练集的误差和测试集的误差,见图12。
loss是训练数据上的损失,衡量模型在训练集上的拟合能力。val loss是在测试集上的损失,衡量的是在未见过数据上的拟合能力,也可以说是泛化能力。模型的真正效果应该用val loss来衡量。从图中可得,模型在迭代125次时就已经最优了,所以更新到迭代125次重新训练,见图13。
总结,该模型最好的参数选择:batch_size为6;迭代次数为125。
2.3.4. 预测
最后得到batch_size为6;迭代次数为125的模型重新训练,对模型进行预测。如图14。
观察其结果,可得该效果很好,充分的反映了预测的趋势。则我们可以利用该模型对未来走势的预测。
3. 总结
综上,将所有模型计算出的误差(MSE, MAE)进行汇总,这里并没有考虑SEIRD模型,因为SEIRD模型得到的结果并不能很好反映对未来的预测(太依赖于对参数的取值),仅用于理论研究更好,而机器学习和LSTM得到的结果,见表2。
综上,根据得到的误差分析,LSTM模型比较好,所以我们将采用LSTM模型对印度的疫情预测,结果预测出在未来印度的疫情,会受到新冠疫苗的接种,应急药品和应急设备设施储备的增加,疫情的监控和预警这些措施的影响后呈下降趋势,新增人数会愈来愈少 [19] [20] ,见图14。
基金项目
本文收到重庆市大学生创新创业项目(s202211551027)支持。