1. 引言
图像去噪是指减少数字图像中噪声以从噪声图像中恢复干净图像的过程。噪声是图像干扰的重要原因。一幅图像在实际应用中可能存在各种各样的噪声,这些噪声可能在传输中产生,也可能在量化等处理中产生。根据噪声和信号的关系可将其分为三种形式:加性,乘性与量化噪声。总的来说,目前图像去噪可以分为三大类:经典的滤波器方法,模型驱动的去噪方法和数据驱动的深度学习去噪。下面我们将总结和讨论图像去噪的发展和最近的趋势以及我们提出的可逆去噪网络对此的改进。
1.1. 经典的滤波器去噪
经典的基于滤波的方法有中值滤波和维纳滤波等,他们的原理是利用某些人工设计的低通滤波器来去除图像噪声。中值滤波器 [1] 把数字图像或数字序列中一点的值用该点的一个领域中各点值的中值代换。自适应维纳滤波器 [2] 能根据图像的局部方差来调整滤波器的输出,滤波器的平滑作用随着局部方差的增大而变强。对于同一个图像中具有很多相似的图像块,可以通过非局部相似块堆叠的方式去除噪声,如经典的非局部均值(NLM)算法 [3] 、基于块匹配的3D滤波(BM3D)算法 [4] 等。但是,由于块操作会导致部分模糊输出并且需要手动设置超参数。所以很难轻量化应用于复杂多变的真实环境。
1.2. 模型驱动的去噪方法
基于模型的去噪方法原理是尝试对自然图像或噪声分布进行建模。它们使用模型分布作为先验,从而获得清晰的图像和优化算法。通常用基于最大后验(MAP)的优化问题来定义去噪任务,其性能主要依赖于图像的先验。如Xu等人 [5] 提出了一种基于低秩矩阵逼近的红外加权核范数最小化(WNNM)方法。Pang等人 [6] 引入了基于图的正则化器来降低图像噪声。
基于以上所述,尽管基于模型驱动的去噪方法实现了比较高的去噪质量,但是大多数基于先验图像先验方法在不牺牲计算效率的情况下很难获得高性能。虽然这些基于模型的方法有很强的数学推导性,但在现实环境的多重噪声下恢复纹理结构的性能将显著下降。此外,由于迭代优化的高度复杂性,它们通常是耗时的。
1.3. 数据驱动的深度学习去噪
近些年来,为了追求去噪结果的完美性,基于深度学习的去噪方法迅速发展起来。由于基于学习的方法侧重于学习有噪声图像到干净图像的潜在映射,比基于滤波、基于模型以及传统的基于学习的方法获得了更好的去噪结果。
Ding Liu等人受图像非局部相似度的启发,将非局部操作纳入到的循环神经网络中 [7] 。Anwar等人 [8] 提出了一种带特征注意力的单阶段去噪网络。Zhang等人 [9] 通过叠加卷积、批归一化和校正线性单元(ReLU)层,提出了一种简单但有效的去噪卷积神经网络(CNN)。
DnCNN [10] 、FFDnet [11] 、CBDnet [12] 逐步泛化,逐步考虑增加噪声复杂,将图像去噪应用到了更加复杂的真实噪声世界。近年来,去噪问题的研究焦点已经从AWGN (添加高斯白噪声)如BSD68、Set12等转向了更真实的噪声。最近的一些研究工作在真实噪声图像方面取得了进展,通过捕获真实的噪声场景,建立了几个真实的噪声数据集如DnD、RNI15、SIDD等,InvDN [13] 首先将真实噪声数据集输入图像分解为两部分:干净的LR图像HFInfo组件对嵌入在输入图像。随后通过丢弃来实现去噪网络逆向运行中的HFInfo。最近提出的InvDN [13] 最初设计用于图像去噪,它具有解决噪声图像缩放任务的潜力,因为它内在的IRN式结构促进了对真实图像去噪的研究。
1.4. 可逆网络去噪
近年来兴起的可逆网络在图像去噪方面有许多创造性的突破,因为它们相比于较为繁琐复杂的其他网络更加轻量化,另一个好处体现在信息传输的过程中所丢失的图像信息更少,并且在逆向传播过程中更加节省内存。
近年来提出的InvDN [13] 将噪声输入转换为低分辨率的干净图像和包含噪声的潜在表示。为了去除噪声并恢复干净的图像,InvDN [13] 在还原过程中使用从先前分布中采样的另一个噪声代表来替换噪声代表。InvDN [13] 的去噪性能优于现有的竞争模型,为SIDD数据集实现了比较先进的结果,同时具有更少的运行时间。另一方面,与DnCNN [10] 相比,InvDN [13] 的大小要小得多,只有4.2%的参数量。此外,通过不断调整噪声潜在表示,InvDN [13] 还能够产生更类似于原始的噪声的图像,这也体现了网络的可逆性。
InvDN [13] 中采用了与其他深度去噪模型不同的特征提取方法。已有的深度去噪模型通常采用卷积层来提取特征。但是由于填充使网络不可逆或者卷积的参数矩阵可能不是全秩等原因导致它们不可逆。所以为了保证可逆性,需要考虑使用可逆的特征提取方法,如压缩层和可逆离散小波变换(DWTs),挤压操作是根据棋盘图案将输入重新形状为具有更多通道的特征映射,然而InvDN [13] 中对比了挤压操作和Harr小波变换两种提取特征方法的峰值信噪比(PSNR)。具体来说,InvDN [13] 应用Haar小波代替棋盘分解处理图像,由于Haar小波是最简单的小波函数,具有良好的局部性质和快速计算的优点。但是,Haar小波的频率响应不够平滑,容易产生振铃现象,对于图像的低频部分分解效果不佳。
考虑到双正交小波不会在图像中引入视觉失真,且正交变换可以保证能量损耗降到最低,我们采用多贝西小波。多贝西小波变换提取原始输入的平均池化以及垂直、水平和对角线导数。同时,多贝西小波是一类具有紧支集和多项式逼近性质的小波函数,具有良好的频率响应和局部性质,不同阶数的多贝西小波可以用于不同分辨率的图像分解,但是高阶多贝西小波计算复杂度较高。最后综合考虑使用二维的多贝西小波进行分解图像。
2. 可逆神经网络模型
2.1. 可逆神经网络
可逆神经网络的基本构建块是Real NVP模型推广的仿射耦合层。它的工作原理是将输入数据分成
两部分,这两部分由学习函数
(它们可以是任意复杂的函数,且函数本身不需要是可逆的)转换并以交替方式耦合:
输出即是
的连接。如图1所示:
用公式表示为:
而给定的输出也可以得到其逆过程:
如图2所示:
用公式表示为:
相比于其他神经网络,可逆网络最大的特点是可以通过双射函数将一个分布转换为另一个分布,而不丢失任何信息。因此,可以利用可逆网络,通过映射一个给定的潜在变量z (遵循一个简单分布
),到一个图像实例
,即
,其中f是网络学习的双射函数。由于双射映射和精确密度估计特性,可逆网络受到越来越多的关注,并已成功地应用于图像生成和缩放等领域。
2.2. 可逆神经网络应用于图像去噪
InvDN [13] 的实现原理是首先训练InvDN使潜在表示的前三个通道和低分辨率的干净图像相同,由于可逆网络能够保留所有输入的信息,所以有噪声的信号留在了其余通道中。为完全去除噪声,InvDN [13] 丢弃所有包含噪声通道,但同时也丢失了一些与高分辨率干净图像对应的信息。所以需要另外考虑重构这部分缺失的信息,InvDN [13] 中实现重构的方法是从先验分布中抽取一个新的潜在变量,并将其与低分辨率的图像相结合,从而恢复干净的图像。
2.2.1. 设计理念
首先用y表示原始的噪声图像,而用x表示去噪后的干净图像,用n表示噪声,用公式表示为:
上述公式表明利用可逆网络学习到的观测y的潜在表示同时包含噪声和干净信息。
大部分基于深度学习的去噪模型都采用卷积层来提取图像特征。这虽然是通用有效的方法,但是由于卷积层填充的参数或者是它的参数矩阵不可逆会直接导致了整个网络不可逆的原因,考虑采用可逆的方法来提取图像特征,如压缩层和离散小波变换 [7] ,如图3所示。
同时使用Haar小波变换代替棋盘分解来划分通道 [13] :

Figure 3. Invertible transforms. The squeeze operation on the left extracts features according to a checkerboard pattern. The wavelet transformation on the right extracts the average pooling of the image, as well as the vertical, horizontal and diagonal derivatives
图3. 可逆变换。左图的挤压操作根据棋盘分解提取特征。右图利用小波变换提取图像的平均池,以及垂直、水平和对角线导数
二维的Haar小波变换将图片分解为四个部分:
A:低频信息
H:水平高频信息
V:垂直高频信息
D:对角高频信息
采样理论表明,在向下采样的过程中,高频信号会被丢弃。因此,如果我们能让转换后生成的隐藏表示的前三个通道和下采样之后的清晰图像一致,高频信息就会被编码到其他的通道中去,通过观测,高频信息中包含有噪声。我们可以放弃直接分离干净和噪声信号,而是分离噪声图像的低分辨率和高频成分。这个过程用公式表示为:
(其中
表示低分辨率的干净图像。
表示
在重建原始干净图像时无法获得的高频信号)
由于很难实现直接分离
和n,又为了完全去除空间噪声,所以我们选择放弃代表
的所有通道,也就是所有包含高频信息的通道。然而,这就会导致
的丧失。为重建
,我们考虑对缺失的
进行随机采样。
然后训练可逆去噪网络对
进行变换,再结合低分辨率的干净图像
,来恢复干净的图像x。通过这种方式,丢失的高频干净信息
就能够嵌入到
中。
总的来说,我们使用INN来学习一个观察y (带噪声图像)的隐藏表示并且能解耦噪声和清晰图像并利用多贝西小波变换将图片分解为四个部分:低频信息、水平高频信息、垂直高频信息、对角高频信息。考虑到分离高频分量和噪声的过程更加繁琐、困难,我们对高频分量直接舍弃。为了重建图像,我们使用了一个从高斯分布中采样的样本
来替代,这样因为丢弃而损失的细节又被嵌入到了隐变量
中。
2.2.2. 网络架构
我们首先采用一种有监督的方法来指导网络在转换过程中分离高分辨率和低分辨率信息。经过可逆变换后,原始噪声图y被转换为相应的低分辨率的干净图像信号
和高频信号z,我们按照如下公式最小化正向目标:
其中,
为网络学习到的低频分量,对应于正向传递中输出表示的三个通道。M是像素大小。
是m范数,m可以是1,也可以是2。为了获得地面真实的低分辨率图像
,我们通过双边变换对干净图像x进行降采样。为了恢复
的干净图像,我们使用逆变换
,从正态分布
中随机变量
采样。逆向目标被写成:
其中,x是干净的图像。N是像素大小。我们通过同时利用正向和反向目标来训练可逆变换g,我们提出的可逆变换g是一个多尺度的体系结构,由几个降尺度块组成。每个降尺度块又由一个Haar小波变换和一系列可逆块组成。模型的整体体系结构如图4所示:

Figure 4. Overall structure of the model
图4. 模型的整体结构
红色虚线框代表每一个可逆块
黄色虚线块代表每一个降尺度块
F2代表操作
;F3代表操作
;F4代表操作
蓝色操作和白色操作在前向操作(Forward)中代表
,在向后操作(Backward)中代表
。
2.2.3. 可逆块的实现
我们遵循的可逆块是仿射耦合层。假设可逆块的输入为x,输出为
。表1列出了这个块在前向和后向传递中的操作。分割(Split)操作将大小为(H/2, W/2, 4C)的输入特征图x划分为
和
两部分,分别对应(H/2, W/2, C)尺寸的低频特征和(H/2, W/2, 3C)尺寸的高频特征。Concat(·)是Split(·)的逆操作,它将特征映射沿着通道连接起来,并将它们传递到下一个模块中。在表中向后传递过程的第二步和第三步中,只要将加(+)和乘(*)运算转换为减(−)和除(/),而
是由神经网络实现的转换函数,它们不会影响耦合层的可逆性。因此,
可以是任何网络,包括卷积层网络。
基本可逆块中的可逆操作。如表1所示:在前向传递中,每个可逆块的输入和输出分别记为x和
。在后向传递过程中,只需要转变运算加(+)和乘(*)为减(−)和除(/)。
可以是任何神经网络。

Table 1. Reversible operations in basic reversible blocks
表1. 基本可逆块中的可逆操作
用上述方法可以将低分辨率特征传递到深层。使用残差块作为操作
。
3. 可逆神经网络的改进
3.1. 用于特征提取的可逆变换
在InvDN中对比了挤压操作和Harr小波变换两种提取特征方法的峰值信噪比(PSNR)。为了找出相比之下收敛速度最快、最稳定的特征提取方法。我们分别对挤压操作,Harr小波变换以及多贝西小波变换进行了对比实验。最终选取了性质相对较好的多贝西小波变换作为我们的可逆特征提取方式。
多贝西小波变换代替棋盘分解
在图像分解中,本文使用了二维多贝西小波变换(2D DWT)。2D DWT将图像分解成四个子带,分别是LL、LH、HL和HH。其中,LL子带包含图像的低频信息,LH、HL和HH子带则包含图像的高频信息。通过对这些子带进行逐层分解,可以进一步提取图像的细节信息。而对LH、HL和HH子带进行阈值处理,从而实现图像去噪。
3.2. 可逆块
3.2.1. 残差块
如图所示,假设原始输入信息是x,而我们希望得到的理想映射是
。图中左半边虚线框中的部分需要直接拟合出该映射
,而右边虚线框中的部分则需要拟合出残差映射
。但是相比之下,残差映射在现实中往往更容易优化。如果将恒等映射作为我们希望得到的理想映射
,那么只需要将途中右边虚线框内上方的加权运算(比如仿射)的权重和偏置参数设为0,那么
即为恒等映射。实际中,当理想映射x极接近恒等映射时,残差易于捕捉恒等映射的细微波动。如图5所示,图中右半边就是残差块(residual block)的基本结构。
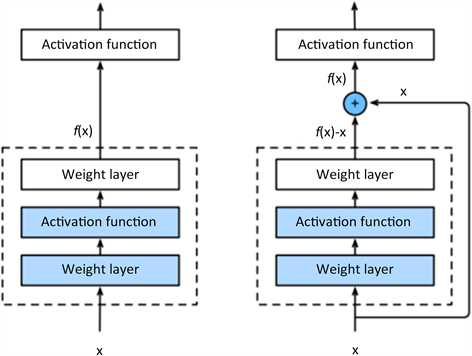
Figure 5. Basic structure of residual block
图5. 残差块的基本结构
值得提出的是,在残差块中,输入的信息可以通过跨层数据线路更快地向前传播,因此残差块被广泛应用到可逆网络的深度学习中。
3.2.2. 密集块
构成密集连接网络的基础模块叫做密集块(dense block)。密集块由于本身不需要重新学习另外特征图的特性,比传统的卷积网络需要更少的参数。传统的网络前馈结构可以看成一种层与层之间状态传递的算法,每一层先接收前一层的状态,然后将新的状态传递给下一层,它改变了状态,但是也传递了需要保留的信息。然而密集块中每个卷积层都很窄(如每一层有12个滤波器),仅仅增加很小数量的特征图到网络的“集体知识”,并且保持了这些特征图不变。
3.2.3. 去噪精度对比
基于以上介绍,对于可逆神经网络的构建,在一些需要比较强的表达能力的任务中,可以优先考虑使用密集块;而在一些需要较快的训练速度和较少的参数量的任务中,则更倾向于使用残差块。InvDN中也进行了密集块和残差块体系结构的去噪精度对比,通过对比结果发现,通过对比结果发现,在迭代次数很高的情况下,具有残差块的体系结构得到的峰值信噪比使用密集块的更高。但是如果我们将迭代次数控制在一定范围内时,结果显示使用密集块作为我们的可逆块能够实现更高的去噪精度。如图6所示,为了实现去噪精度的最优化,我们考虑将密集块和残差块同时作为我们的可逆块进行训练。
利用残差网络恒等映射的思想,在图像进入可逆块前对其进行采样预降噪,降低噪声信息与干净图像信息之间的距离,从而提高可逆块中高频细节参与重建图像的数量。

Figure 6. Structure diagram of optimization model
图6. 优化模型结构图
4. 实验
4.1. 数据集与数据预处理
我们在真实世界的去噪基准上评估InvDN。SIDD是由五个具有小光圈和传感器尺寸的智能手机相机拍摄的。我们使用SIDD作为训练集,包含320对干净噪声对用于训练,以及来自其他40对的1280个裁剪补丁用于验证。在每次训练迭代中,我们将输入图像裁剪成多个144 × 144个补丁,以输入网络。
我们的InvDN有两个降尺度块,每个块由8个可逆块组成。所有的模型都是以Adam为优化器,批量大小设置为14,初始学习率固定为2 × 10−4,每50 k次迭代就会衰减一半。使用paddle上作为实现框架,培训在一个2060-TiGPU上执行。
4.2. 实验结果
我们在SIDD数据集上的图像去噪结果如下图7~9。
4.3. 实验结果比较
我们对与其他神经网络在相同SIDD下处理的数据结果。

Figure 7. Comparison between the original image and the improved image
图7. 原图像与改进后图像对比

Figure 8. Comparison between denoising results of other network models and improved InvDN denoising imags
图8. 原InvDN模型去噪结果与改进后InvDN去噪图像对比

Figure 9. Comparison between denoising results of other network models and improved InvDN denoising imags
图9. 其他网络模型去噪结果与改进后InvDN去噪图像对比
Table 2. SIDD training results under different models
表2. 不同模型下的SIDD训练结果
如表2所示,通过比较,更加凸显了可逆神经网络(InvDN)具有参数量小,并且其去噪后图片的峰值信噪比(PSNR)与结构相似性(SSIM)也很好。
4.4. 加入残差网络预处理
Table 3. Comparison of network training time
表3. 网络训练时间对比
如表3所示,加入残差网络预处理后的训练时间比加入前的稍微有所增加但总体影响几乎可以忽略。
Table 4. PSNR metrics for each method
表4. 各方法PSNR指标
通过表4的PSNR指标对比可以看出:
1、残差网络对图像进行预处理后对可逆神经网络的图像去噪的效果有所促进,但是效果优化幅度很小并不明显,随着数据的选取类别不同,是否有促进效果具有随机性。
2、可逆神经网络对比传统图像处理方法的去噪效果更好。体现出了可逆神经网络在图像去噪领域的巨大优势和发展前景。
3、应用残差网络对图像做预处理,其网络结构设计太过简单,无法发挥其模型优势,仍需对其进行深入学习,充分利用恒等映射,填充层等结构,来优化网络训练,达到更好的去噪效果。
4.5. 降尺度块中不同图片分解方式对比
Table 5. Comparison of different image decomposition methods
表5. 不同图片分解方式对比
如表5所示,通过对比Haar小波变换和棋盘分解与二维多贝西小波变换在不同数据集下的结果,说明我们将Haar改为多贝西后的实验结果有一定的提升。
5. 总结
本文在真实世界的去噪基准上训练了可逆去噪网络,并通过实验将其应用于实际的图像去噪中,证明了可逆网络在图像去噪方面确实取得了非常好的效果。此外,相对于其他去噪网络,可逆去噪网络模型更轻、占用内存更小并且能够实现信息无损传递。鉴于可逆去噪网络的良好特性,本文对已有的可逆去噪网络InvDN做出了部分改进,实现了在相对较少的参数下执行图像去噪任务。我们采取了可以降低能量损耗的正交小波变换代替一般的卷积层来进行特征信息的提取,避免了引起视觉失真的可能。另外,我们还将密集块和残差块同时作为我们的可逆块进行训练,在很大程度上提高了图像的去噪精度。最后,我们将训练好的网络应用于我们的图像数据集上,实验结果表明,得到的去噪后图像相比于原始图像都得到了一定性能的提高。