1. 引言
视觉三维重建即通过物体的二维图像重建出它的三维模型,能广泛应用于数字孪生城市、无人驾驶、元宇宙等新兴领域。相比于激光扫描等三维重建方法,视觉三维重建具有低成本、高效率的特点,适用场景更广泛。视觉三维重建的精度和速度受多种因素影响,包括输入数据的质量、算法的准确性和稳定性,以及应用场景的要求等。
基于视觉的三维重建以原始图像集作为基础,而往往图像中并非只有待重建的对象,还存在大量无用信息,如果基于原始图像直接进行计算,就会耗费大量计算资源去重建无用模型,如图1所示。

Figure 1. 3D reconstruction results with original image as input
图1. 以原始图像为输入的三维重建结果
为了解决这一问题,有研究人员从图形获取层面进行无用信息削减(将环境背景设置为纯色),这样的方法对于针对小物品的三维重建可能会有效果,但不能适用于大场景(如建筑)。
本文的目标是从重建层面消除无用信息,提高计算效率。为此,本文以SfM进行稀疏重建,以MVS进行稠密重建,来完成三维重建任务,并在其中加入智能裁剪功能。具体来说,本文的智能裁剪功能有以下流程:
1) 获取原始图像集;
2) 对原始图像集进行智能裁剪(分割、抠图)以获得新的图像集;
3) 将原始图像的详细信息(相机信息、图像信息)加入到新图像集中;
4) 用新的图像集进行稀疏重建及后续工作。
本文采用PP-Matting抠图模型作为智能裁剪方法,以重建时间、重建精度等指标进行对比分析,探寻有效的方法,使得三维重建的效率和精度有所提高。
2. 国内外研究现状
2.1. 视觉三维重建
基于视觉的三维重建已经发展了数十年,取得了巨大的成功,无论是传统方法还是深度学习的方法都展示出了很好的效果。
传统的视觉三维重建算法发展历程较长,相关方法较为完整,目前为止依然是主流。M Farenzena等 [1] 提出了一种基于分层聚类树的结构和运动恢复方法,用于从多张图像中估计场景中的点和相机的3D位置和姿态。N Snavely等 [2] 介绍了一种基于计算机视觉和计算机图形学技术的方法,利用从互联网上获取的大量图片,生成高质量的三维重建模型,从而实现对不同场景的浏览和探索。
基于深度学习的视觉三维重建算法依据处理的数据形式主要分为体素、点云和网格的处理。Eigen等 [3] 基于体素形式,直接用单张图像使用神经网络恢复深度图,将网络分为全局粗估计和局部精估计,并用一个尺度不变的损失函数进行回归。Choy等 [4] 基于体素形式提出的3D-R2N2模型使用Encoder-3DLSTM-Decoder的网络结构建立2D图形到3D体素模型的映射,完成了基于体素的单视图/多视图三维重建。Yu等 [5] 利用潜在空间中的特定类别的多模态先验分布训练变分自编码器,利用潜在空间的子集就可以找到先验分布的目标模态,获取类别的先验信息,随后将先验信息和图像特征共同送入解码器重建三维模型。Fan等 [6] 提出了用点云做三维重建的开山之作,解决了训练点云网络时候的损失问题。Chen等 [7] 通过对场景的点云进行处理,融合三维深度和二维纹理信息,提高了点云的重建精度。Wang等 [8] 用三角网格来做单张RGB图像的三维重建。
2.2. 图像抠图
传统抠图方法可以分为三类。首先是基于色彩采样的方法,这类方法依赖于像素之间的强相关性,从已知的前景或背景颜色中采样并将它们应用于未知像素 [9] ;其次是基于相似性的方法,这类方法通常计算相似度矩阵来表征相邻像素之间的相似性,并相应的将alpha值从已知区域扩散到未知区域 [10] [11] [12] ;最后是基于色彩采样和相似性的优化方法,以获得更稳健的解决方案,达到更好的效果 [13] [14] 。尽管这些方法通过综合设计在预测结果方面取得了显著的进步,但它们的表示能力受到低级颜色或结构特征的限制,难以将前景细节与复杂的自然背景区分开来。此外,由于这些方法中的大多数都需要手动标记辅助输入,因此抠图结果通常对未知区域的大小和模糊边界非常敏感。
基于深度学习的抠图算法可以分为两类,即基于辅助输入的抠图算法和自动抠图算法。基于辅助输入的抠图算法有三种方法论:一是使用单个one-stage CNN将输入图像和辅助输入的连接直接映射到alpha上 [15] [16] ;二是将one-stage CNN与自定义的模块相结合使用,以利用侧分支的辅助输入所提供的丰富特征来提高抠图的质量 [17] [18] ;三是利用并行双模态或多模态结构将抠图任务分解为显式子任务 [19] [20] 。对于自动抠图方法,也有三种主要的方法论:一是one-stage结构,可以选择性地包括一个全局模块作为指导,直接从单个输入图像中预测出抠图结果 [21] ;二是顺序两步结构,首先生成中间分割掩码或trimap,然后与初始输入组合以产生最终的alpha遮罩 [22] ;三是并行的双模态或多模态结构,它将抠图任务分解为几个子任务,例如前景和背景或全局语义掩码 [23] 和局部细节 [24] [25] 。
2.3. 结合图像分割的视觉三维重建
通过将图像分割技术应用于三维重建,可以更好地理解场景的结构、提取物体的几何信息,并实现更准确的三维重建结果。
J McCormac等 [26] 提出了一种使用卷积神经网络进行密集的三维语义建图的方法,将深度学习与稠密三维重建相结合,实现了准确的三维语义建模。JJ Park等 [27] 将深度学习与三维形状表示相结合,通过学习连续的有符号距离函数来表示物体的几何形状。Shuaifeng Zhi等 [28] 在基于nerf的三维重建训练中,加入语义分割的训练,并证明了联合nerf重建和语义分割,可以对粗糙或者错误的语义label有矫正的作用,并可以用于自动化标注。
抠图算法是图像分割中的一种,其本质都是根据图像原始信息或标注信息来分离特定的对象,但因其工作侧重不同,两者之间也存在些许区别。具体来说,图像分割是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程;图像抠图是将图像分为前景和背景,提取出感兴趣的前景再进行后处理。对于三维重建而言,往往只需要感兴趣的前景,而不需要环境背景,因此在抠图算法比分割算法更适合本文的研究内容。
3. 三维重建算法
3.1. 图像抠图
3.1.1. 抠图技术
图像抠图是指从图像中提取出我们所感兴趣的前景目标,同时过滤掉背景部分。一张图像可以简单的看成是由两部分组成,即前景和背景。简单来说,抠图就是将一张给定图像的前景和背景区分开来。
假设原始图像用SI来表示,α表示对应的Alpha通道,FI和BI分别表示对应的前景图像和背景图像,那么一张具有RGBA通道的图像可以分解为如下几部分的组合:
(1)
当α为0时,图像为背景图像;当α为1时,图像为前景图像。对于图像中的每个像素点,均可以表示为一个类似于上述的线性方程组。因此,抠图的主要目标是根据原始输入图像,来获得前景、背景和透明度。
3.1.2. PP-Matting算法
PP-Matting是Guowei Chen等 [29] 于2022年提出的一种能实现高精度自然图像抠图的无trimap网络架构,由语义上下文分支(SCB)和高分辨率细节分支(HRDB)组成,分别用于预测语义图和细节图。最后将语义图与细节图相融合以实现相互增强,生成准确的alpha遮罩。
PP-Matting网络由语义上下文分支(SCB)和高分辨率细节分支(HRDB)组成,两个分支共享一个公共模块作为编码器,即公共编码器。在SCB之前,利用金字塔池化模块(PPM)来加强语义上下文。此外,指导流(guidance flow)用于连接SCB和HRDB,有助于通过正确的语义指导进行细节预测。网络架构如图2所示。
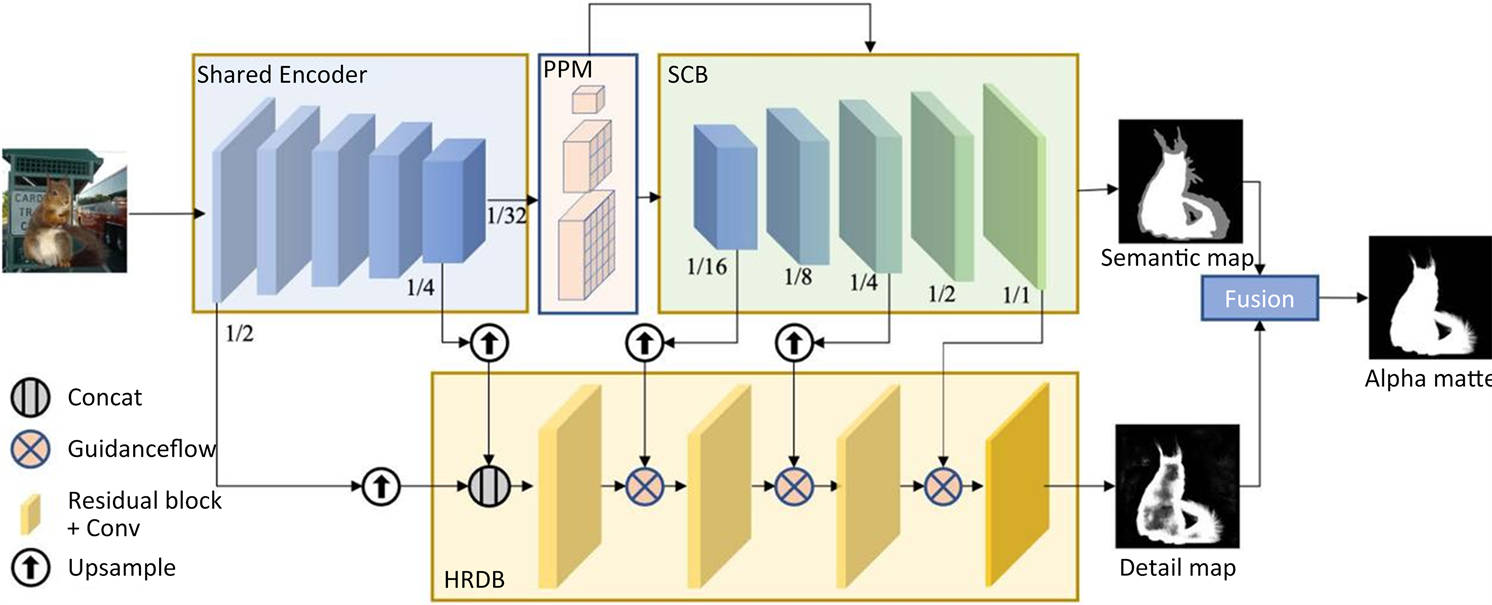
Figure 2. PP-Matting network architecture [29]
图2. PP-Matting网络架构 [29]
模型运用了三种损失函数。第一个是SCB中的语义损失,表示为Ls,这是3类分割任务的交叉熵损失:
(2)
其中
表示语义图中的三个类,
是第i个像素处第c类的预测概率,
是相应的真实值,Ω表示图像中所有的像素:
(3)
其中
分别表示前景像素、背景像素和过渡像素。
第二个损失是HRDB中的细节损失,表示为
:
(4)
其中
是alpha预测损失,
是梯度损失。
第三个损失是最终alpha遮罩中的融合损失,表示为
,由alpha预测损失、梯度损失和合成损失共同组成:
(5)
其中
是真实RGB颜色与真实前景、背景和预测的alpha遮罩合成的预测RGB颜色之间的绝对差异。
最终的加权损失计算如下:
(6)
3.2. 增量式SfM
增量式SfM是一边三角化(triangulation)和pnp (perspective-n-points),一边进行局部BA (Bundle Adjustment,捆绑调整)的一种稀疏重建方法,重建结果是稀疏点云。BA算法是对初始结果进行非线性优化以均匀化误差和获得更精确的结果,从本质上来说,BA是一个优化模型,其目的是最小化重投影误差。在已知结果的情况下对求解的参数进行误差最小化,使得求解结果更加精确的过程。一般使用重投影误差来对该问题进行优化:将特征匹配点记为观测点,三维空间点为求解点。根据求解的相机外参数(旋转矩阵、平移向量)将三维空间点重投影到相机成像平面中。由于误差的存在,该点与观测点不会重合,优化的目标就是使得重投影误差最小。优化模型如下:
(7)
(8)
上式中,
代表三维空间中的第i个坐标点
,
为第j个相机的内参,
是
在第i个相机中的投影点,
为观测点。由于并不是每一个视角的相机都能在另一个相机中找到对应的投影点,因此若
在第j个相机中可见,则
,否则
。BA算法的目的是最小化
,找到使得
最小时的
,即优化
。最终,经过BA算法的优化可以得到最小化的
值,在第5章中以Rmse体现,作为重建质量评价指标之一。
4. 实验
4.1. 数据集
本文在5个数据集上进行实验:PPM-100 [30] 、Composition-1k [31] 、Distinctions-646 [32] 、AIM-500 [33] 、AM-2K [24] 。在PPM-100中,训练集包含90张原始图像和对应的alpha遮罩,测试集包含10张原始图像和对应的alpha遮罩;在Composition-1k中,训练集包含431张原始图像和对应的alpha遮罩,测试集包含50张原始图像和对应的alpha遮罩;在Distinctions-646中,训练集包含596张原始图像及其相应的alpha遮罩,测试集包含50张原始图像及其对应的alpha遮罩;在AIM-500中,包含500张原始图像及其对应的alpha遮罩;在AM-2K中,训练集包含1800张原始图像和对应的alpha遮罩,测试集包含200张原始图像和对应的alpha遮罩。本文选取上述5个数据集中3417张原始图像及其相应的alpha遮罩作为训练集,310张原始图像及其相应的alpha遮罩作为测试集。
4.2. 实验流程
4.2.1. 训练
本文使用上述的数据集对PP-Matting进行了微调。为了使得输入图像保持一致,在训练阶段将输入图像尺寸调整为512 × 512 (Mat(512)模型)和1024 × 1024 (Mat(1024));随机梯度下降(SGD)优化器中的动量参数设置为0.9,权重衰减为4e−5;学习率初始化为0.01,并通过多项式策略进行调整,指数为0.9,迭代次数为100,000;方程中的系数设为
。本文的所有实验都是在RTX 3080单个GPU上进行,batch_size为2。
训练结果如表1所示。由训练结果可知,Mat (512)模型最佳SAD (绝对差总和)值为108.7288,最佳MSE (均方误差)值为0.004,最佳iter (迭代次数)为37000;Mat (1024)模型最佳SAD (绝对差总和)值为63.5426,最佳MSE (均方误差)值为0.003,最佳iter (迭代次数)为58,000。Mat (1024)模型的SAD值与MSE值都小于Mat (512)模型,说明Mat (1024)模型更为准确,预计其预测效果优于Mat (512)模型。
4.2.2. 测试及预测
利用训练得到的best_model对测试集图像进行抠图测试,部分结果如图3所示。
从图3可以看到,模型在测试集上展示出了比较好的抠图效果,接下来将它用于三维重建中的原始图像抠图。如图4所示,使用抠图模型对待重建的原始图像进行抠图,得到抠图后的图像序列。可以发现,从该抠图模型获得的新图像序列很好的达到了本文实验要求,即仅包含待重建对象,不含其余无用背景信息。




Figure 4. Cuts out the original image. The top is the original image, and the bottom is the cutout image
图4. 对原始图片进行抠图。上是原始图片,下是抠图之后的图片
4.2.3. 三维重建
经过以上抠图处理,获得抠图后的新图像集,将原始图像集的exif信息逐个写入该新图像集,得到用于三维重建的图像集。依次进行SfM以及MVS,如图5所示,最终得到三维模型。
 (a) SfM生成的稀疏点云
(a) SfM生成的稀疏点云  (b) MVS生成的三维模型
(b) MVS生成的三维模型
Figure 5. Reconstruction results of SfM and MVS
图5. SfM与MVS的重建结果
5. 结论分析
图6展示了不同流程的三维重建效果。首先仅从视觉上观察,未加入抠图流程(SfM + MVS)的重建结果相对比较完整,重建质量比较好,未发现明显缺失,但模型中存在大量无用的背景信息;加入Mat (512)抠图模型的重建结果不含有无用的背景信息,但重建质量相对于SfM + MVS而言稍差,存在部分模型缺失的情况;加入Mat (1024)抠图模型的重建结果同样不含无用信息,且重建质量相比于Mat (512)抠图模型的结果稍好,未出现明显的模型缺失。
表2展示了三种不同三维重建流程的部分重建参数,由表可知,从重建时间和模型内存来看,Mat (512) + SfM + MVS流程最优;从SfM场景RMSE来看,SfM + MVS流程更优(“人像石雕”中的RMSE值存在意外,推测可能是因为原始图像中的背景被虚化,导致背景信息对重建过程造成了干扰)。
总体来说,加入抠图算法后的三维重建虽然其重建质量有所降低(降低的程度取决于原始图像的背景信息质量),但能获得更高的重建效率,同时能够减少大量的无用信息存储,只保留有用部分,大大节约了存储空间。这样的特性对于某些行业和研究方向来说具有很高的需求性,比如三维模型资产存档、文物数字化归档、三维重建业务平台、针对物品的三维重建等等。

Table 2. 3D reconstruction parameters of different processes
表2. 不同流程的三维重建参数
6. 结论与展望
本文提出了一种融合PP-Matting抠图和增量式SfM的三维重建方法,该方法在使用SfM和MVS算法完成三维重建之前,对物体的原始图像进行抠图。本文利用Distinctions-646等多个图像集对PP-Matting抠图模型进行微调训练,得到仅包含待重建物体的图像。实验结果表明,本文提出的方法在重建效率方面取得显著提升,并且能够降低存储空间需求。
但是经过抠图后的图像集存在三个问题:一是由于大量的信息被消除,因此在特征提取时所能提取的特征点减少,导致SfM计算三维坐标的精度下降,最终体现为SfM生成的稀疏点云不够精确,MVS生成的三维模型质量会有所降低;二是抠图算法往往是沿着待处理对象的边缘进行提取,这导致了边缘像素模糊化,因此图像中的待重建对象的边缘信息会有所减少,在最终的三维模型中体现为表面纹理不平整,甚至有所缺失;三是以这样的方案来进行三维重建,其重建质量很大一部分取决于抠图质量的好坏,因此抠图模型必须要能准确无误地对前景进行提取,但就目前而言,想要在任何场景下达到这样的理想效果还比较困难。
基于此,本文在此提出对未来工作的几点展望:① 对抠图算法做特定修改,使其扩大边缘范围,不丢失边缘信息;② 在抠图算法中加入语义识别分割算法,能够智能选取特定对象;③ 不使用图像抠图,直接分割稀疏点云,不丢失辅助点信息。