1. 引言
据报道,目前全球有柴胡属植物200种,我国已报道的有43种。尽管1963年版《中国药典》就规定柴胡或狭叶柴胡干燥根为柴胡正品供用药,但有研究者实际考察发现,我国药材市场流通的商品柴胡竟达十多种,多地柴胡用药不符合规定,实际应用繁乱,因此研究柴胡鉴别技术对规范柴胡市场、加强药材质量控制和促进中药产业可持续发展具有重要意义。
近年来,太赫兹光谱技术作为一项在线检测技术 [1] ,在农业、医学、食品安全、航天等领域应用广泛。基于太赫兹光谱技术的分类方法有很多,但如何选取一种适合数据集的分类器才是关键。基于太赫兹时域光谱数据的分类研究中使用较多的方法有SVM、KNN等。如在文献 [2] 中基于太赫兹光谱技术,结合均值偏移算法(MeanShift)和主成分分析法(PCA),提出以支持向量机(SVM)为基础,通过改进步长和平衡全局搜索与局部搜索的策略优化布谷鸟算法(SPCS),得到SPCS-SVM分类模型,提供了一种太赫兹中草药数据快速识别的方法。文献 [3] 中针对黄连、掺杂牛黄和天然牛黄等的太赫兹时域光谱数据,分别构建随机森林(RF)模型和三种参数优化的支持向量机(SVM)模型,对六种物质的太赫兹吸收光谱进行分类鉴别,结果表明,RF模型和SVM模型均可达到95%左右的分类准确率。文献 [4] 中利用三组相似中药炙甘草和生甘草、南柴胡和北柴胡、山豆根和北豆根的太赫兹光谱数据,构建三种不同的SVM,并建立误差反向传播神经网络(BP神经网络),结果表明,SVM是实现太赫兹光谱技术对中药快速、精确分类的有效方法之一。文献 [5] 中基于相关向量机(RVM)理论,提出了改进的多分类相关向量机(ImRVM)分类模型,实现了八种转基因棉花种子的有监督分类识别。另外,为使太赫兹光谱技术应用于鉴别时准确率更高,测量速度更快,一些文献中引入了深度学习分类算法。如文献 [6] 中提出一种融合ResNet和长短时记忆网络(LSTM)的太赫兹时域光谱隐匿危险品识别方法,按照批次进行分析预测,以此来选择模型最优结构。文献 [7] 中通过对CNN的网络结构和重要权值参数的优化,提出了一种改进的CNN分类模型。该模型在提高太赫兹吸收光谱识别精度的同时,可以有效解决由于太赫兹光谱数据量不足而容易陷入局部最优的问题。以上分类算法通常具有较高准确性和稳健性,但也存在分类算法对比不足的问题。
为了解决分类算法对比不足的问题,本文提出一种多分类器测试对比方法,以太赫兹光谱柴胡数据分类为例,对12种分类算法进行了综合对比,以期为研究者提供有益参考。
2. 数据介绍
实验使用的柴胡太赫兹光谱数据共有13个批次,每个批次包含10个样本,总计130个样本,3类柴胡。图1给出了所用柴胡太赫兹吸收系数谱图,其中左图为全部吸收系数谱曲线图,右图为柴胡的吸收系数谱均值曲线图,其中绿色线代表藏柴胡,蓝色线代表锥叶柴胡,红色线代表北柴胡。
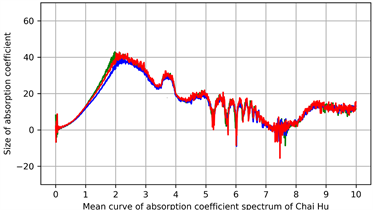
Figure 1. Spectra of the absorption coefficient of Bupleurum Terahertz
图1. 柴胡太赫兹吸收系数光谱图
根据图1得,原始数据高频段噪声较多,需要对原始数据进行频段选择。经反复测试,本文选取0.4~1.8 THz这一相对平稳且噪声较少的频段用于后续实验,具体如图2所示。
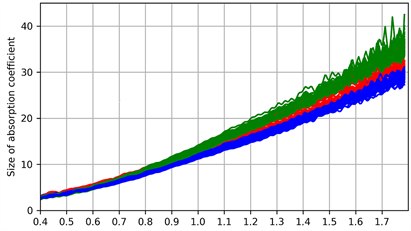
Figure 2. Terahertz absorption coefficient spectra in 0.4~1.8 THz
图2. 0.4~1.8 THz波段的太赫兹吸收系数光谱
为提高分类器的分类性能,本文使用正态标准化方法对数据进行预处理。该方法通过计算数据的标准差,将数据按照其与均值的偏差进行标准化处理。这种处理方式可以使得数据具有零均值和单位标准差,能有效缩放数据,减小不同频段数据之间的尺度差异,进而提高模型的性能和效率。
3. 分类器介绍
本文使用的分类器包括:支持向量机(Support Vector Machine, SVM)、最近邻(K-Nearest Neighbor, KNN)、决策树(Decision Tree, DT)、随机森林(Random Forest, RF)、Logistic回归(Logistic Regression, LR)、多层感知(Multilayer Perceptron, MLP)、伯努利朴素贝叶斯(Bernoulli Naive Bayes, BNB)、自适应提升(Adaptive Boosting, AB)、梯度提升决策树(Gradient Boosting Decision Tree, GBDT)、极端随机树(Extremely Random Forest, ERF)、极致梯度提升(eXtreme Gradient Boosting, XGB)和轻量梯度提升机(Light Gradient Boosting Machine, LGBM)等。以下对各算法进行简要介绍:
1) SVM:是一种适用于二分类和多分类问题的有监督学习算法。其目标是找到最优超平面,以有效分开不同类别的样本并最大化分类间隔。具有丰富的核函数、通过引入软间隔和松弛变量,在一定程度上提高了SVM的鲁棒性和处理噪声的能力 [8] 。同时,SVM对小样本集、非线性数据集表现较好。但对大规模数据,SVM计算复杂度较高,需进行特征缩放。
2) LR:是用于二分类问题的线性回归算法。它最早由赫尔曼·菲舍尔在20世纪30年代提出,并在50年代由David Cox发展成现代逻辑回归。LR通过逻辑函数将线性模型输出映射到概率空间,适用于线性可分和不可分问题,简单、快速且易于实现 [9] 。近年来,通过集成学习等方法,LR在实际应用中变得更强大。但在处理复杂非线性问题时,LR表现较差,容易受异常值影响。
3) KNN:是基于实例的学习算法。KNN主要用于分类和回归,通过最近的K个邻居的标签进行预测。算法简单易懂,适用于非线性问题和多类别分类。但其计算复杂度较高,对样本不平衡较敏感,需要确定合适的K值。
4) RF:通过构建多个决策树并对其结果进行投票或平均来进行分类或回归,是一种集成学习算法。由Leo Breiman于2001年提出。如今,RF在分类和回归问题中具有较高准确度,适用于处理大量的特征和样本,对噪声和异常值具有较好的鲁棒性。但其模型解释性相对较差,对于高维稀疏数据可能表现不佳。
5) DT:是一种基于树结构的分类和回归算法,通过逐步划分数据集,生成一棵树来做出预测,是许多集成学习算法的基础。DT算法具有易于理解和解释的优势,不需要特征缩放,能够处理数值型和类别型特征。但DT容易产生过拟合,对于数据中的噪声和离群值较为敏感。
6) BNB:是朴素贝叶斯算法的一种变体,具有简单、快速的特点,适用于文本分类等特征二元分布的场景,但对于特征间相关性较强或具有连续特征的数据表现较差 [10] 。
7) MLP:是一种基于前馈神经网络的学习算法,由多个层次的神经元构成。随着深度学习的兴起,MLP及其变种成为计算机视觉、自然语言处理等领域的主要算法之一。它适用于复杂的非线性问题,具有较强的拟合能力,在大规模数据集上表现优秀。但其训练时间较长,需要大量数据来避免过拟合 [11] 。
8) AB:是一种集成学习方法,通过加权组合多个弱分类器构建一个强分类器。作为经典集成算法,它激发了更多其他的集成学习方法的发展。AB相对于单一弱分类器显著提高了准确率和泛化能力,尤其在高维度数据上表现优异。但对噪声和异常值相对敏感,可能导致过拟合,且计算开销较大。后续出现了许多改进算法如GBDT和XGB,在解决实际问题上表现更好。
9) GBDT:是一种集成学习算法,最早由Jerome H. Friedman于1999年提出,通过迭代地训练一系列决策树并使用梯度提升策略来改进预测性能。自提出以来,其在机器学习领域广受关注,发展出了更高效的改进版本如XGB和LGBM。GBDT算法具有高准确度、较好的鲁棒性,特别擅长处理复杂问题。但需要调整大量超参数,也可能会导致过拟合问题 [12] 。
10) ERF:作为随机森林的改进版,致力于提高模型的泛化能力。相较于传统随机森林,ERF引入了更多的随机性,减少过拟合风险,增强模型的多样性,有效地降低树之间的相关性,但也增加了计算开销。在使用时,需要综合考虑优势与计算成本。
11) LGBM:是一种基于梯度提升的决策树算法 [13] ,旨在提高训练速度和准确度。随着大数据和工业界应用的增多,LGBM成为梯度提升算法的重要代表,为解决大规模数据问题提供了强有力工具。该算法训练速度快,内存占用低,在大规模数据集上表现出色,但调整超参数对数据质量和噪声较为敏感。
12) XGB:在GBDT的基础上融合了加权策略和正则化技术,是高效的梯度提升算法 [14] 。XGB具有高准确度和效率的特点,尤其适用于大规模数据集,支持并行处理和缺失值处理。但使用需要调整超参数较多,对于非结构化数据不太适合。
4. 实验设置
4.1. 批次划分方法
批次留一法适用于小规模数据,它通过按批次划分数据集来避免样本泄露导致的得分偏高的问题,使实验结果更具科学性、合理性。
结合柴胡数据多批次的特点,避免随机采样造成的样本泄露问题,本文采用按批次进行划分的方法,将数据划分为n − 1个批次进行分类器的训练和调试,剩余的1个批次数据进行测试。通过这种方式,对分类器进行13次训练与测试,能有效地提高了分类器的准确性和鲁棒性。
4.2. 参数设置
本文模型训练基于Python 3.9.13环境,采用网格搜索法对十二种分类器的参数进行调优。通过对每个分类器的各项参数可能出现的取值进行排列组合,生成一个参数组合的“网格”。遍历这个参数网格,对每个组合进行评估,并计算评估指标,如得分标准差、准确率和召回率等。通过系统地搜索所有可能的参数组合,确定最佳参数配置,从而获得给定数据集上表现最佳的分类器的最佳参数。
相关参数设置如表1所示,其中,C:惩罚系数,kernel:核函数,gamma:核尺度参数,n_estimators:学习器个数,min_samples_split:最少样本分割数,max_depth:学习器最大深度,inter:线性模型的截距,solver:优化器,Criterion:损失函数,weights:权重,algorithm:算法,learning_rate:学习率,min_samples_leaf:各叶子节点包含的最少样本数,Alpha:拉普拉斯或利德斯通平滑的参数,Binarize:特征二值化的阈值,class_prioc:类的先验概率,Activation:激活函数,hidden_layer_sizes:隐藏层层数及每层的节点数。

Table 1. Parameter setting for each classifier
表1. 各分类器参数设置
4.3. 评价准则
本实验主要的评价准则是准确率。假设测试样本正确分类的样本数量为Nres,测试样本总体数量为N,则准确率的定义为:
由于本实验中同一批次的样本数据类别相同,故本实验基于同一批次的分类结果计算投票得分,进一步提出批次内投票前的准确率得分(Before_vote_sore)和批次内投票后的准确率得分(After_vote_score)。设投票前正确分类的样本数量为Nres_b,投票后正确分类的样本数量为Nres_a,则二者的计算公式为:
同时,实际分类过程中,会更多的关注分类器对某一类或多类柴胡的识别性能,本实验补充召回率得分(Recall_score)。假设测试样本中属于A类的样本数量为M,分类器预测为A类正确的样本数量为Mres,则召回率的计算公式为:
为充分考虑样本类别不均衡的情况和综合评价分类器的性能,本实验结合精确率(Precision)、召回率和标准差得分,并考虑到召回率在实际分类任务中占更重要的地位,故本文采用F2得分(F2_score)用于进一步完善评价准则,假设分类器预测为A类的样本数量为H,其中预测正确的样本数量为Hres,则F2的计算公式为:
为展示各度量的稳定性,本实验引入标准差指标。标准差是一组数据平均值分散程度的一种度量。标准差数值越大,代表大部分数值与其平均值之间差异较大;标准差越小,代表数值接近平均值,总体比较稳定。假设样本数据的算数平均值为,样本数据的数量为n,则标准差的计算公式为:
5. 实验结果及分析
本实验采用多种分类模型对样本数据进行分类 [15] ,在实验前需要对样本数据进行批次划分,随后进行数据标准化处理。各种分类模型在最优参数下的分类情况如表2、图3所示,score1、score2、score3、score4分别对应Before_vote_score、After_vote_score、Recall_score、F2_score。其中,score1、score2通过加减标准差显示其得分稳定性。
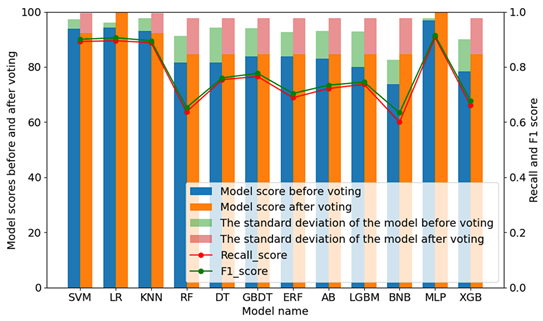
Figure 3. Accuracy of different classifiers before and after voting
图3. 投票前后不同分类器的准确率
由表2可知,各模型分类精度普遍较好,在投票后,各模型都能达到80%以上的准确率。对比分析表2和图3可知,投票前准确率得分最佳的模型是MLP,得分96.92、其次是LR、SVM,得分最低的是BNB;投票后准确率得分最佳的分类模型是MLP、LR,得分100,其次是SVM、KNN,其余分类器得分一致;而用时最短的分类模型是KNN,最长的是GBDT。综合各衡量指标,MLP和LR分类模型性能最优,其中MLP在重要指标上都优于LR模型。因此,对本样本数据而言,最优的分类模型是MLP,其次是LR,最差的是BNB。
由于THz数据为连续特征数据,BNB分类器不适用于处理连续特征,导致在所有分类器中,它的分类效果最差。相比之下,MLP算法由大量的非线性神经元组成,拥有较强的拟合能力和解决非线性问题的能力,因此在所有分类器中,它的分类效果最好。
6. 结束语
本实验通过可视化太赫兹光谱柴胡数据,截取频谱范围在0.4~1.8 THz内的数据,根据批次划分训练集和测试集,使用12种不同的分类器模型对数据进行训练与测试并输出得分结果。结合得分标准差、准确率和召回率进行综合性评估分析得出结论:在众多分类模型中,传统的MLP、LR、SVM及KNN表现较优,优于当前一些热门的分类方法如GBDT、AB、LGBM等;在众多文献中表现优异的ERF、XGB表现欠佳。本文实验结果表明,没有一流的算法,只有合适的算法。
本文的相关结果对研究人员在后续进行太赫兹光谱数据分类时具有一定的借鉴意义。仍有部分问题需进一步的研究与探索:
(1) 本文使用的批次留一法具有很好的避免样本泄露问题,但该方法仅适合小规模数据。而在使用大规模数据集时,则存在实验次数过多的问题,需采用其他按批次的随机样本划分方法。
(2) 本文使用网格搜索进行参数调优对于参数较少时效果较好,当参数较多时,搜索空间急剧增大,导致搜索效率低下。在后续的研究中,可考虑其他如遗传算法、贝叶斯优化方法等,以提高搜索效率。
(3) 本文的THz频段选择方法主要基于直观和经验,后续可进一步探索排序和搜索的频段特征选择方法,以进一步提高算法性能。
NOTES
*通讯作者。