1. 引言
据统计,中国有1730万盲人,位列世界第一,全球范围内也有约22亿人患有视力障碍的疾病。出行是盲人融入社会需要面对的首要问题,而我国关于盲人的基础设施建设并不完善,使得盲人的出行受到很大限制,因此很多盲人选择封闭自己,不愿与外界联系,这就是盲人数量如此之多,我们却很难在日常生活中看到他们身影的原因。由于传统辅助手段如盲道、导盲犬等不能很好地解决盲人出行问题,基于计算机视觉的辅助方法迎来新的挑战和机遇,其中深度估计技术是解决盲人出行中避障问题的关键 [1] [2] 。
近年来,随着深度学习的飞速发展,计算机视觉技术也越发成熟,被更多地应用于实际生活中,如VR虚拟现实、自动送货机器人、无人机自主飞行等 [3] [4] 。这些应用得以实现的基础之一便是深度估计,即估计相机获取的图片中每个像素点与相机之间的实际距离。传统深度估计的方法大致可分为两种,一是通过激光雷达获取精准的深度信息;二是通过双目摄像头获取同一物体不同视角的图片,进行立体匹配计算出深度信息。相对来说,激光雷达获取到的深度信息更为精确,但结构精密、造价昂贵,普通盲人家庭难以承受。双目摄像头虽然成本上降低了很多,但其需要复杂的相机标定,两个相机的视差也需要精确的匹配,考虑到盲人在生活中可能碰到的各种突发情况,其维护成本太高,也不利于推广。相比之下,单目深度估计成本更低,实际使用中更方便,所以近年来基于深度学习的单目深度估计技术被更多人关注 [5] 。
最早在2014年,Eigen等人 [6] 提出了在深度估计中使用卷积神经网络(Convolutional Neural Network, CNN),利用全局粗尺度网络粗略估计场景深度,再用局部精细尺度网络优化局部信息。2015年,Liu等人 [7] 提出了深度卷积神经场模型对单张RGB图像的深度进行预测。2016年,Laina等人 [8] 首次将残差网络(ResNet)应用到深度估计领域,将ResNet作为编码器提取信息丰富的特征图,再由解码器逐步恢复场景深度信息。DenseNet [9] 是以ResNet为基础的模型,受到ResNet的启发,它也被应用于深度估计领域。2017年,Jung等人 [10] 将生成式对抗网络引入深度估计领域,生成器根据场景图片生成深度图,判别器判别生成的深度图是否为真实深度。2021年RanFtl等人 [11] 首次尝试使用自然语言处理领域的Transformer [12] 结构替换卷积神经网络提取特征,通过融合局部与全局注意力能够获得较准确的深度信息。2022年,Yuan等人 [13] 优化了条件随机场(Conditional Random Field, CRF),通过将输入分割成多个窗口,构建全连接的CRF,捕捉像素之间的更多关系,在深度估计问题上取得了良好的效果。
目前,为了满足高精度的要求,设计的网络结构越来越复杂,计算量较大,难以部署到用于辅助盲人出行的边缘设备上。轻量化网络对于恢复物体细节特征,精确获取深度信息上又略显吃力。为了平衡两者,以满足盲人出行辅助设备所需的实时性和准确性,本文提出了一种基于DenseNet的单目深度估计算法,主要贡献包括一下几点:
① 建立编码器和解码器之间的跳跃连接,并引入RHAG (Residual Hybrid Attention Group)残差混合注意力组,激活更多像素,提高解码过程中深度图边缘定位的准确性,有效提升了模型的深度估计精度。
② 在解码器之后增加AdaBins模块对输出特征图进行全局统计分析,通过全局信息优化输出的深度图,以更好地恢复RGB图像中的深度信息。
③ 将原网络中的卷积核替换为ABC (Asymmetric Convolution Block)非对称卷积块,增强卷积核骨架,提高模型对特征的提取能力,以此提升深度估计精度。
2. DenseNet-169网络介绍
DenseNet-169网络主要包括4个DenseBlock和3个Transition层 [14] ,如图1中所示。
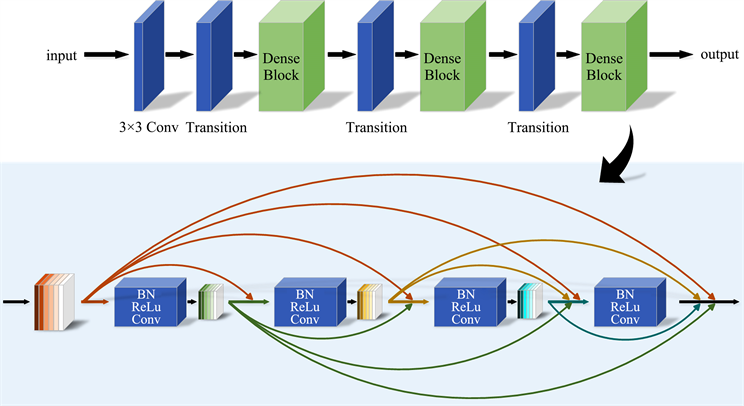
Figure 1. DenseNet-169 network structure
图1. DenseNet-169网络结构图
DenseBlock包含5层layer,其中每一层由1 × 1卷积和3 × 3卷积组成,输入来自于前面所有层的输出,它的输出也将直接连接到后面层的输入,以此建立低层次和高层次之间的密集连接,实现特征重用,即对不同layer的特征进行总体性的再探索,最大化前后层之间的信息交流,一定程度上解决了梯度消失的问题,提升了效率。值得说明的是,在卷积之前会先进行归一化操作,使得每一层在接收前面所有层的输出特征时,能够解决在特征重用时碰到不同层的输出特征的数值差异问题。
Transition层通过1 × 1卷积和平均池化操作衔接两个DenseBlock,整合上一个DenseBlock获得的特征进行下采样,降低特征图的大小,起到了压缩模型、提高计算效率的作用。
密集连接的方式必然会面临增大的参数量,DenseNet很好的处理了这个问题,不仅将每一层设计的很窄,还在相邻DenseBlock之间用Transition层连接,这种结构降低了网络的冗余度,减少了运算时的参数量,同时,特征重还可以起到抗过拟合的效果。
3. 算法改进策略
本文整体网络结构如图2所示,编码器使用的是DenseNet-169,通过建立前后层的密集连接,利用低层次和高层次特征在通道上的连接实现特征重用,最后将提取的特征作为编码器的输入。解码器部分采用双线性插值的方法上采样逐步恢复图像的细节特征,并建立编码器与解码器之间的跳跃连接,融合低层像素信息和高层语义信息,使恢复的深度图边缘定位更准确,最后输出特征图。在编码器与解码器的跳连接中引入RHAG残差混合注意力组激活更多的输入像素以实现更好的单目深度估计。由于难以恢复在编码过程中丢失的如特征分辨率等信息,所以经过解码器后,将输出的特征图交由AdaBins模块进行信息的全局处理,更好的恢复出原图像中的深度信息。同时为了获取到更好的特征表达,使用ACB非对称卷积块对DenseBlock中的3 × 3卷积核骨架进行增强,以提高深度估计的准确率。
最后,本实验中采用平均绝对误差(L1_Loss)作为损失函数,计算预测深度与真实深度之间的误差,并求其平均值:
(1)
式中n表示像素点个数,
表示像素的真实值,
表示预测值。
3.1. RHAG残差混合注意力组
表示像素点个数,在计算机视觉领域,注意力机制的出现,使得神经网络能像人类视觉系统一样在面对大量的图像信息时,能聚焦于图像中的有用信息,避免将计算资源浪费在无关紧要的信息上,从而提升模型的整体性能。对于本实验中的编解码网络结构,由于编码阶段连续的卷积和下采样,使得解码后恢复的深度图边缘定位不准确,导致预测的深度信息不准确,所以在编解码的跳连接中引入RHAG残差混合注意力组。
如图3所示,RHAG包含多个HAB (Hybrid Attention Block)混合注意力块,一个OCAB (Overlapping Cross-Attention Block)重叠交叉注意力块和一个带有残差连接的3 × 3卷积层 [15] 。HAB模块由窗口自注意力机制和通道注意力机制组成,通过结合不同类型的注意力机制来激活更多的像素,同时利用局部和全局信息,实现更好的重建效果。在HAB中,首先对输入特征进行归一化处理,然后窗口注意力机制将特征图划分成若干个局部窗口,并在每个窗口内计算自注意力,可以通过此操作捕获到局部区域的关联信息。接下来,通过通道注意力机制引入全局信息,利用全局信息对特征进行加权,从而激活更多像素。最后将窗口注意力机制和通道注意力机制的加权和输出,并通过残差连接与输入特征相加。OCAB模块通过引入重叠交叉注意力层,利用窗口内部的像素信息进行查询,建立窗口之间的交叉连接,以增强网络特征表达的能力,提高网络深度估计任务的性能。
3.2. AdaBins模块
单目深度估计中,由于场景的复杂性以及深度分布的无规律性,例如:客厅、卫生间等图像中包含的深度信息大部分分布在一个较小的范围内,而走廊这种场景的图像中包含的深度信息可能从网络支持的最小值到最大值。这使得深度估计的准确性很难达到理想的状态。因此本文引入了AdaBins模块,通过对解码器输出的特征图进行全局统计分析,并通过后处理构建块对输出进行优化,进而分析和修整深度的分布值。AdaBins模块的结构如图4所示。
其中mini-Vit Block为Transformer结构,结合局部结构信息和全局分布信息,估计深度范围更可能出现的层段。解码特征张量输入到mini-Vit Block,经过p × p大小的嵌入式卷积(Embedding Conv)核重构成一个空间平坦的张量,并作为Transformer的输入 [16] 。之后通过MLP层归一化后深度信息被划分为若干个深度区间相同的单元
,每个单元的中心深度值
计算公式为:
(2)
式中:
和
分别指数据集中真实深度的最大值和最小值。
之后将输出的向量通过一个1 × 1卷积核和3 × 3的卷积核来获取范围注意力图R (Range attention maps)。之后,范围注意力图R经过1 × 1卷积核得到N通道,并进行softmax激活,将得到深度单元中心在每个像素处的概率 [17] 。最后,将softmax得到的概率和深度单元中心
线性组合得到每个像素的最终深度图:
(3)
式中:
指第k通道,其中每个像素的数值为该图像的深度值落在第k个区间的概率。
3.3. ACB非对称卷积块
ACB非对称卷积块可以替代模型中的普通方形d × d卷积核,在推理阶段不需要额外的计算成本的前提下,提升模型的准确率。ACB由(d × d)、(1 × d)、(d × 1)的三个卷积核组成,三个平行层相加可以对方形卷积核的骨架进行增强。
对于输入特征图I,先进行
和I卷积,
和I卷积后,再对结果进行相加得到的结果,与
和
的逐点相加后再和I进行卷积得到的结果是一致的 [18] 。如式(4)所示,这也解释了为什么ACB非对称卷积块能在获取更好的特征表达的同时,又不增加网络推理阶段的任何计算量。
(4)
以图5中3 × 3卷积核为例,可以使用3 × 3、1 × 3和3 × 1的三个卷积核组成的ACB来替换3 × 3卷积核,将三个卷积层的计算结果进行融合得到最终输出。在推理阶段,强化后的网络结构与原网络是完全一样的,只是强化后的网络参数采用了特征提取能力更强的参数即融合后的卷积核参数,因此在推理阶段不会增加计算量。
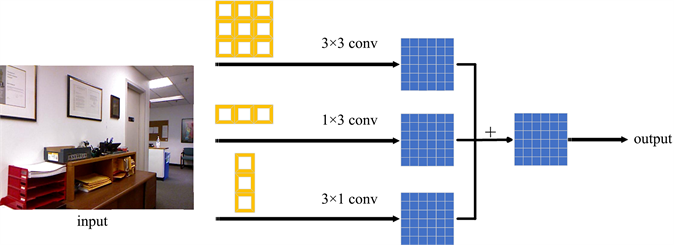
Figure 5. Asymmetric convolution block
图5. ACB非对称卷积块
4. 实验结果与分析
4.1. 数据集
实验数据集使用的是目前最广泛最常用的公开数据集NYU Depth V2 [19] ,同样采用该数据集进行评估测试。这个数据集是由微软Kinect的RGB和Depth摄像机记录的视频序列组成,深度范围为0.5~10 m,共有407,024帧RGB-D图像对,其中有1449张标注的RGB图像和深度图,来自3个城市,包含464个场景,分辨率均为640 × 480。其中795幅RGB-D图像对用于训练,654幅RGB-D图像对用于测试。
4.2. 实验环境与评价指标
本文实验基于Ubuntu 20.04.1操作系统,显卡使用内存大小为24 G的NVIDIA GeForce GTX 3090,python版本为3.7,cuda版本为11.2,采用Pytorch 1.7.1框架。学习率设置为0.0001,batch size设置为4,epoch设置为20。
单目深度估计的评价指标主要是通过计算预测深度与真实深度之间的误差和准确率。目前较为常用的评价指标包含:阈值精度(
)、均方根误差(RMSE)、对数均方根误差(
)、绝对相对误差(AbsRel)。具体公式如为:
阈值精度:
(5)
均方根误差:
(6)
对数均方根误差:
(7)
绝对相对误差:
(8)
其中N表示像素总数,
表示第i个像素的真实深度值,
表示对应的深度预测值。
4.3. 实验结果
4.3.1. 消融实验
为了验证本文提出的算法改进策略对整体性能的影响,以及整个模型的有效性,在NYU Depth V2数据集上进行消融实验对比分析。
从表1可以看出,与原网络相比,引入ACB卷积后,准确率提升了约0.3%,误差下降了约0.2%,验证了ACB非对称卷积块优于普通卷积。引入RHAG模块之后,模型阈值准确分别上升了1.41%、0.9%、0.1%,均方根误差下降了2.7%,对数均方根误差减少了0.3%,绝对相对误差减少了1.2%,说明了在编码器和解码器之间的跳跃连接引入残差混合注意力组能有效提升模型精度。引入AdaBins模块后,模型阈值精度提升了1.62%、0.82%、0.2%,均方根误差下降了1.9%,对数均方根误差下降了0.29%,绝对相对误差降低了1.67%,说明了在解码出特征图后,经过AdaBins后处理优化后能更好的恢复出场景深度信息。同时通过对各个模块的组合,模型整体性能均得到了提升,同时融入三个模块之后模型的各项指标达到最优,进一步验证了本文提出的改进策略能很好的提升模型深度估计的整体性能。

Table 1. Results of ablation experiment
表1. 消融实验结果
4.3.2. 不同模型对比
为了进一步验证本文提出的算法改进策略的整体性能,使用文献中不同的算法进行了深度估计对比实验,均使用相同的数据集NYU Depth V2进行训练,如表2所示,定量实验中,文献 [20] 提供了一种利用迁移学习以实现高分辨率深度估计的算法,与文献 [20] 中的评价指标进行对比,阈值精度
分别提升了4.96%、1.1%、0.25%,均方根误差减少了3.7%,对数均方根误差减少了0.4%,绝对相对误差减少了2.17%,取得了良好的结果。对比MonoDepth [21] ,阈值精度
提升了2.2%,绝对相对误差减少了1.3%。从定量分析的角度证明了本文算法的有效性,通过对整体模型的改进,能通过单张RGB图像获取到更精确的深度图。
Table 2. Comparison of different methods on the NYU Depth V2
表2. NYU Depth V2数据集上不同方法对比
 (a) 原图 (b) MonoDepth (c) 文献 [20] (d) Ours
(a) 原图 (b) MonoDepth (c) 文献 [20] (d) Ours
Figure 6. Comparison of depth estimation results
图6. 深度估计结果对比
在定量对比的基础上,为了更直观的展示本文方法的优势,图6展示了本文方法与MonoDepth和文献 [20] 的方法预测的深度图进行对比,定性分析结果。图中第一列为原始RGB图,后三列依次为MonoDepth、文献 [20] 和本文改进算法分别进行深度估计后得到的深度图,从图中可以看出本文算法能较好的恢复场景中的细节部分,并且在场景中物品的边缘较为明确,如图中白色方框标注的区域,与前二者对比可以明显看出本算法对于深度信息的恢复更为精确。第一行标注出来的浴缸旁边的架子,MonoDepth及文献 [20] 中的算法对此部分处理的结果都较为模糊;第二行中沙发边缘及旁边的桌子,本文算法都能较好的恢复出二者的界限;第三行中对于远处的沙发,相较与其他两种方法,本文算法能较好恢复出沙发扶手的细节;第四行中标注出来的椅子及茶几,也能通过本文算法恢复出真实场景中的层次感。
4.4. 真实场景测试
如图7中所示,在实际场景中使用本文中训练好的网络进行深度估计,展现出良好的效果,深度图中可以看出层次感更为清晰,对于座椅、办公桌等物品能精确的恢复其边缘信息,预测结果较为准确。由真实场景测试可知,本文中模型具有良好的泛化能力,可以很好的预测盲人出行中碰到的障碍物的距离,具有一定的实用价值。
 (a) 真实场景
(a) 真实场景 (b) 预测深度
(b) 预测深度
Figure 7. Real scenario test results
图7. 真实场景测试结果
5. 系统设计与平台移植验证
为了进一步验证本文中改进的单目深度估计算法在实际工程中的应用,在服务器上训练完成后部署到边缘计算设备上进行实验。实验基于高性能NVIDIA Xavier NX边缘计算板设计了主从式的视障人群智能出行监护系统,主设备为NX,从设备为Air820和香橙派Range Pi。其中,NX主要负责目标识别、单目深度估计以及各从设备的任务调度,Air820包含GPS定位、摔倒检测、电话短信、基于LD3320的语音交互等功能,香橙派负责完成定点导航的功能。图8为整个系统的流程框图。
将本文提出的算法和双目深度估计算法移植到视障人群智能出行监护系统中进行对比实验,对于障碍物距离预测,双目深度估计在立体匹配阶段浪费了大量的算力,只能达到每秒4帧的检测频率,而本文中提出的算法能达到21帧的检测频率,满足了盲人出行时,对障碍物检测所要求的实时性和准确性。

Figure 8. Flow diagram of monitoring system
图8. 监测系统流程框图
6. 结束语
为了解决盲人出行问题,本文提出了一种基于DenseNet的单目深度估计改进模型,用于恢复RGB图片中的深度信息,检测障碍物与相机间的距离。通过在编解码之间建立跳跃连接并引入RHAG残差混合注意力组,结合不同的注意力机制,利用局部和全局信息,提高深度图中边缘定位的精确性,实现更好的深度恢复效果;引入AdaBins模块对解码器输出的特征图进行后处理,通过全局统计对深度图进行修整优化;同时通过替换卷积核以加强卷积核骨架,增强模型特征提取能力,提升深度估计精度。实验结果表明,所提出的改进算法深度预测准确性为89.5%,绝对相对误差为0.101,因此该算法能实现较好的单目深度估计效果。同时将算法部署到边缘检测设备NVIDIA Xavier NX也满足盲人出行时对障碍物距离实时监测的要求,具有一定的实用价值。后续的工作仍需在模型深度估计精度问题上继续研究,同时深入研究算法在部署到边缘设备时的运算耗时,提升运算效率,使其拥有更好的实时性,实现在盲人日常出行时快速准确的检测障碍物。
基金项目
贵州省基础研究(自然科学)项目黔科合基础-ZK [2021]重点001资助。
NOTES
*通讯作者。