1. 引言
在过去的十年里,互联网实现了飞速的发展,但与此同时,恶意软件及其应用程序也井喷式的增长。恶意软件作者通常会诱导用户下载恶意文件,其中恶意文件包括病毒、特洛伊木马、蠕虫、rootkit、广告软件、勒索软件和一系列恶意的可执行程序。恶意软件会有目的性获取用户信息、窃取用户财产、破坏用户体验和锁定用户主机。根据McAfee2021年度报告,相比2020年,2021年的恶意软件开发量大幅增加,平均每分钟会新增588个恶意软件 [1] 。国家互联网应急中心2021年上半年,捕获恶意程序样本数量约2307万个,日均传播次数达582万余次,涉及恶意程序家族约20.8万个 [2] 。对此,为了有效保障人民的财产和数据信息安全,有效防止恶意软件入侵,所以长期以来,对于恶意软件检测的研究一直以来都是网络安全领域中的热点之一。
恶意软件检测有两种基本的分析检测方法:静态分析检测和动态分析检测。静态分析检测是在不执行恶意软件程序的情况下对其进行反编译,并对哈希值、操作码、N-gram、PE (Portable Executable)头信息和字符串等信息进行特征提取,建模分类。而动态分析检测是通过创建虚拟环境执行恶意软件程序并捕获API调用,注册表项更改、新日志条目和网络活动等信息进行特征提取,建模分类。本文是基于静态分析检测方法对反编译后的数据进行降维处理,训练分类。
目前,机器学习中的许多网络模型已经被应用到恶意软件检测中。引入机器学习模型的检测方法与传统需要人工标注的检测方法在效率上大大提升,且减少了人力成本。文献 [3] 提出了通过主成分分析对恶意软件数据进行降维,并使用支持向量机(Support Vector Machine, SVM)算法对降维后的数据进行分类,提高了恶意软件检测效率,但SVM相较于深度学习中的网络框架,存在着特征提取不充分的问题,从而导致检测准确率较低。文献 [4] 提出了一种由卷积神经网络(Convolution Neutral Network, CNN)进行特征提取,决策树进行分类的端到端的检测框架,并提出了一种特殊的损失函数。但CNN和决策树结合的网络模型不能精确地关注到恶意软件数据中的重要特征,从而导致检测的准确率不高。文献 [5] 提出了一种异步学习框架,通过结合API、函数调用和动态链接库的使用频次来作为训练数据,并通过贪婪分成来提高模型的泛化效果。文献 [6] 将恶意软件转换为RGB图像,并提出了一种动态路由的胶囊网络框架用于恶意软件图像的分类。文献 [7] 提出了一种改进的ResNeXt模型,通过嵌入一种新的正则化技术来限制模型拟合能力,减缓收敛速度,从而改进分类任务。文献 [8] 改进了现有深度神经网络(Deep Neural Network, DNN)模型,通过引入定向Dropout正则化方法,提高了模型的迁移性。文献 [9] 结合了机器学习和深度学习的优势,引入了一种具有多流输入的新型DeepMalware架构,用于解决现有关键安全设备上恶意软件检测的性能开销问题。文献 [10] 通过反编译物联网设备平台恶意软件获取样本静态指令序列,使用Word2Vec将词频转换为向量,再通过构建一个多层的Transformer模型学习恶意软件中结构化序列和函数的语义表示,利用Transformer模型中的并行的多头注意力机制对输入特征进行自适应加权,从而能够关注到重要的特征,该方法充分考虑到恶意软件数据特征各项的内部相关性。但Windows平台的恶意软件特征维度较大,且有大量冗余数据,实验结果表明,在Ember数据集上,先对数据进行降维,再使用Transformer模型进行分类的检测准确率会比不使用PCA降维的检测准确率高 [11] 。而VIT是Transformer的改进版本,跟适用于图像分类领域,虽然VIT模型有着众多的优点,但在局部感知方面不及SE-ResNet,且单一在检测精度方面有所欠缺。
综合上述恶意软件检测方法中存在的问题,本文提出一种基于PCA和SE-ResNet-VIT的恶意软件检测方法。将原始的软件数据转换为浮点型数据,再对高维的软件数据进行PAC降维处理,充分提取数据中的有效主成分,去除数据中的噪声和冗余,再转换成灰度图像输入到SE-ResNet-VIT集成模型中进行检测分类。并在Ember数据集与现有的多种检测方法进行了对比实验,通过实验结果验证该方法的有效性。
2. 基于PCA和SE-ResNet-VIT的恶意软件检测方法设计
2.1. 整体结构
本文提出基于PCA和SE-ResNet-VIT的恶意软件检测模型如图1本文网络结构模型图所示,结构包括将原始PE文件转换为浮点型数据、PCA主成分提取降维、最大最小值归一化、改进的SE-ResNet、VIT、对两个模型的结果加权重计算和输出检测结果。
集成模型是一种提高模型准确率的方法,模型之间的差异越大,集成后的性能改善越大 [12] 。两种不同的特征提取方法提取软件图像的特征,可以更全面地区分图像之间的差异,并获得更好的分类结果。SE-ResNet-VIT集成模型结合了两种完全不同的特征提取方法,即改进的SE-ResNet模型和VIT模型以提取软件图像信息的特征并进行分类。将改进的SE-ResNet模型的输出结果乘以系数0.7,VIT模型的输出值乘以系数0.3,然后将这两个结果相加作为最终预测结果。
卷积神经网络在恶意软件检测领域已经取得不错的效果 [13] [14] ,但由于反编译PE文件得到的函数调用块是具有先后时间顺序的,单一的卷积神经网络并不能有效的提取时间特征,为了解决这一问题,本文将机器翻译领域的Transformer与卷积神经网络相结合,利用Transformer模型中的多头注意力机制能够解决中长特征的依赖问题这一优势。因为在集成信息的时候,当前的特征项与整条数据中的任意特征项发生联系时,都会通过正弦位置编码保留输入特征之间的相对位置信息,从而使得Transformer模型能够更高效提取恶意软件中的时间序列特征。
2.2. 数据预处理
本文采用Ember数据集,通过反编译工具将其解析,经过提取后得到七组主要特征类,其分别是:通用文件信息类、PE头部信息类、区块信息类、字节统计信息类、字符串信息类、导入和到处函数类。将所有类的信息进行组合打包,添项,将数据转换成维度为2401的浮点型数据。
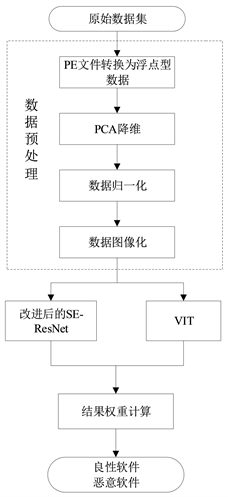
Figure 1. Network model structure diagram of this paper
图1. 本文网络模型结构图
归一化处理,对转换成浮点型的数据进行归一化,将数据标准到[0, 1]的区间内。
其中Yij表示标准化后的值,i表示第几个样本,j表示第几个维度,为该特征项的最大值,为该特征项的最小值,则标准化如公式(1)所示:
(1)
主成分分析(Principal component analysis, PCA)是机器学习领域中使用最广泛的数据降维算法之一 [15] 。同时也被广泛应用到恶意软件检测领域,文献 [16] 将PCA和LDA (Linear discriminant analysis, LDA)算法与多种检测模型组合,并在多个数据集上进行实验对比,结果表明,PCA算法比LDA算法在降维方面有着更好的效果。本文通过PCA算法将原本2401维度的原始数据,通过主成分提取,降维到900维度。假设一个数据集中有m个对象,每个对象包含n个变量。要获得主成分,其步骤如下:
1) 将原始数据组成m行m列矩阵X。对矩阵X进行标准化后得到新矩阵Z:
(2)
其中,
,
。
2) 计算出协方差矩阵:
(3)
3) 用特征值分解方法求出协方差矩阵C的特征值及每个特征值对应的特征向量。
4) 将特征向量按对应特征值大小从大到小排序按行排列成矩阵,取
前行组成矩阵P。
5)
即为矩阵X即为降维到
维后的数据。
2.3. 基于Transformer-Encoder模型
Transformer是由Vaswani A.等人在2017提出的一种机器翻译领域的新模型 [15] 。Transformer模型主要由编码器(Encoder)和解码器(Decoder)两个大的模块组成,本文使用了Vision Transformer所改进的Encoder模块 [17] 。如图2 Transformer Encoder模块结构图所示,Transformer Encoder模块由多个Encoder模块堆叠形成。单个Encoder模块有两个子层,一个是多头注意力机制(Multi-Head Attention, MHA),利用self-attention学习软件灰度图像中的特征结构。另一个是多层感知机(Multilayer Perceptron, MLP),通过线性映射将MHA放大后的维度缩小,再次输入到Encoder模块当中。每个子层前都使用了LN (Layer Normalization)数据标准化方法,每个子层后都是用了残差链接。与传统的递归神经网络(Recurrent Neural Network, RNN)和CNN相比,Transformer采用MHA并行计算,从而提升模型训练速度,并且,多头注意力机制允许每个特征关注所有其他特征,这使得每个特征都可以在其完整的特征中被考虑。多头注意力机制是自注意力机制的拓展,而自注意力机制则来自一个更一般的Scaled Dot Attention函数,其定义为:
(4)
其中Q、K和V分别是由Attention中的query向量、key向量、value向量组成的矩阵,为隐藏层的维度,softmax函数的作用是通过指数特性将所有预测结果映射在0到正无穷的区间内,再通过归一化将所有预测结果转化为0到1之间的概率分布。多头注意力机制是由多个并行的Attention构成,定义公式如下:
(5)
其中
而
,
分别表示模型的维度和隐藏层的维度。
在Vision Transformer中,线性嵌入层是的一个重要结构。线性嵌入层将图像分割成多个块,然后将每一块扁平化为一维张量,再将位置编码和类别编码共同嵌入到张量中,并输入到Transformer编码器当中。再由编码器提取特征后输出到全连接层当中,由全连接层执行一个分类任务。本文是一个恶意软件检测的二分类任务,因此Vision Transformer最终输出为良性软件或恶意软件。Vision Transformer检测模型如图3所示。
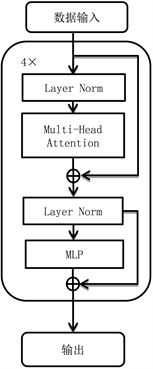
Figure 2. Transformer Encoder module structure diagram
图2. Transformer Encoder模块结构图
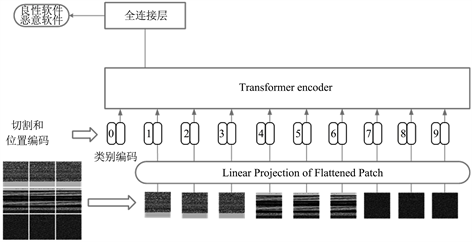
Figure 3. Vision Transformer detection model
图3. Vision Transformer检测模型
2.4. 改进的SE-ResNet卷积神经网络检测模型
卷积神经网络一直是计算机视觉、机器翻译、图像识别、目标检测等多个领域的主要模型架构。SENet (Squeeze-and-Excitation Networks)是Jie Hu等人在2018年提出的一种用于图像分类的卷积神经网络模型 [18] ,其结构如图4所示。图中Ftr与常规的卷积操作相同,将输入通道数为C',高度为H',宽度为W'的矩阵向量X,提取为通道数为C,高度为H,宽度为W的矩阵向量U,SENet的核心是U后面的SE模块,首先SENet对U进行一个Squeeze操作,通过global average pooling将每一个通道上整个空间特征编码为一个全局特征,从而提升卷积的感受野。接下来的Excitation操作学习每个通道上全局特征的关系,得到不同通道的权重,最终再将Excitation输出的权重和U相乘得到最终特征。SE-ResNet是将SENet中的SE模块插入到ResNet [19] 中的每个残差块之间,利用SE模块捕捉通道之间的相互关系,提高模型的泛化能力。SE-ResNet的Squeeze操作是通过全局池化实现的,全局池化将整个输入的特征图进行池化,能够将每个特征图的信息都汇总在一起,但它不考虑特征图中的位置信息,从而导致损失空间信息。同时在反向传播中,梯度可能会在多次池化之后减小到很小的值,导致梯度消失,从而影响整个模型的性能。
本文通过一种双线性池化融合机制,具体结构如图5所示,通过融合全局池化和最大池化的Squeeze操作,既保留了全局池化将特征信息汇总在一起的优势,又增加了最大池化能够保留了每个池化窗口中的最大值,从而不会丢失特征图中的位置信息。
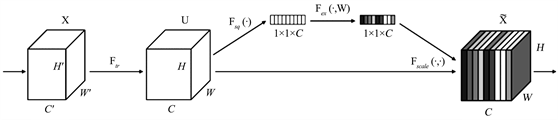
Figure 4. SENeT network model structure diagram
图4. SENeT网络模型结构图
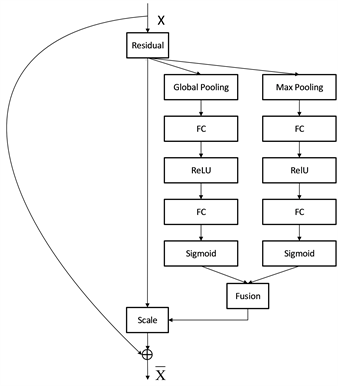
Figure 5. Improved SE-ResNet architecture diagram
图5. 改进的SE-ResNet结构图
3. 实验结果及分析
3.1. 实验环境
文实验的环境搭建在CentOS 7操作系统中,其中编程语言采用的是Python 3.7,深度学习框架采用的是Pytorch 1.10.1,中央处理器为Intel(R)Xeon(R)CPU E5-2620 v4 @ 2.10 GHz,显卡为NVIDIA Tesla P100。
本文采用的Endgame在2018年发布的一个关于恶意软件的开源数据集Ember,这是可用于研究Windows平台恶意软件检测的最大数据集之一。Ember数据集扫描了110万个恶意软件样本,其中90万个训练样本,20万个测试样本。而训练样本中包括30万个未标注样本,这些样本在模型训练中没有用处,会在预处理数据集时进行删除,表1是删除未标注样本后的数据分布。

Table 1. Type and quantity of experimental data
表1. 实验数据的类别与数量
3.2. 评价指标及参数设置
3.2.1. 评价指标
在本文采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值(F1 Score)对恶意软件检测方法性能进行评估。其指标详细定义为公式(6),(7),(8)和(9):
(6)
(7)
(8)
(9)
其中TP (True Positive)表示真实数据为恶意软件样本且模型预测结果也为恶意软件的数据总数,TN (True Negative)表示真实数据为良性软件样本且模型预测结果也为良性软件样本的数据总数,FP (False Positive)表示真实数据为良性软件样本且模型预测为恶意软件样本的数据总数,FN (False Negative)表示真实数据为恶意软件样本且模型预测为良性软件样本的数据总数。
3.2.2. 参数设置
本文中使用的PCA提取的主成分特征数目为625,SE-ResNet-VIT网络模型中有两层卷积层,滤波器数目分别为10和20,滤波器大小分别为4*4,6*6,降采样层的大小为2。VIT中设置为6个多头注意力机制,encoder迭代4次。优化器选择SGD,初始学习率为0.003,batch size设置为256,epoch为200。使用warm-up策略来提高优化器SGD在训练过程中的稳定性。
3.3. 实验结果分析
图6是本文提出模型的训练集和测试集准确率变化曲线图。由图可见,模型的训练轮次达到100个Epoch之后,测试集的Accuracy已经停止增长,稳定在0.97,说明模型已经拟合了。
3.3.1. 单一模型和组合模型对比
为了验证SE-ResNet-VIT组合模型的检测效果,将组合模型与改进的SE-ResNet和VIT进行比较。由表2的实验结果表明,组合模型在Accuracy、Precision、Recall和F1四个指标方面均有明显提升。
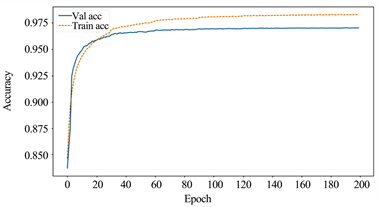
Figure 6. Model accuracy change curve of this paper
图6. 本文模型准确率变化曲线图
Table 2. Single model and combined model performance comparison (%)
表2. 单一模型和组合模型性能对比(%)
3.3.2. PCA对组合模型的影响
为了验证PCA降维消除冗余后的所有软件数据对模型中有着更优异的表现,本文将经过多次降维比对后确定降维后的维度为900。降维后的数据与原始数据使用相同参数的CNN-Transformer模型进行训练并测试模型性能,通过表4的实验数据能够说明,在加入PCA降维之后,能够有效的去除Ember数据集中的冗余特征项,提高CNN-Transformer模型的特征提取效率,从而使得模型在Accuracy提高了0.61,同时单轮训练时间由原来的53.41 s降低到42.75 s,减少10.66 s,模型训练速度大幅降低。实验结果如表3所示:
Table 3. Comparison of model performance after dimensionality reduction using PCA
表3. 使用PCA降维后模型性能对比
3.3.3. 与现有检测模型对比
为了验证本文提出模型性能的先进性,将本文提出的PCA-SE-ResNet-VIT模型与文献 [3] 提出的PCA-SVM模型、文献 [8] 改进的DNN模型、文献 [10] 的Hierarchical Transformer进行实验比较和现有的多种深度学习模型在Ember数据集上进行对比,实验结果表明,通过PCA降维去除冗余后,再结合卷积层和多头注意力机制的优势,该SE-ResNet-VIT检测模型在Accuracy、Precision、Recall和F1四个指标方面均优先现有的恶意软件检测模型。实验结果如表4所示:
Table 4. Detection effect of different models on Ember dataset (%)
表4. 不同模型在Ember数据集上的检测效果(%)
4. 结束语
本文对恶意软件的原始数据进行了降维,去冗余,并将降维前后的数据和SE-ResNet-VIT集成模型展开研究,合并卷积层和多头注意力机制二者的优势,将其应用到恶意软件检测中。通过在Ember数据集上的实验结果表明,本文提出的方法在Accuracy、Precision、Recall和F1四个评价指标方面均优于文献 [3] ,文献 [8] ,文献 [10] 所提出的模型,且高于现有常见的深度学习网络模型,从而证明了本文提出模型的有效性。下一步将本文的模型应用在其他的恶意软件数据集上,尽管Ember数据集的数据已经很广泛,涵盖了大多数种类的恶意软件,但它并不包括所有可能存在的种类,但现有的数据集更新速度难以跟上恶意软件的迭代速度,未来将通过自行收集恶意软件样本,在自行收集的数据集下测试本文提出模型的性能。
基金项目
广州市重点领域研发计划项目(202007010004)。