1. 引言
目标检测作为计算机视觉的一项基本任务,也是计算机视觉领域中研究热点之一,在无人驾驶、智能视频监控、生物检测等方面有着广泛的应用。随着基于深度学习目标检测算法的研究与发展,其主要检测算法可以划分成两类:基于候选区域的双阶段目标检测算法和基于回归分析的单阶段目标检测算法 [1] ,前者第一阶段生成大量的候选区域(region proposal),第二阶段把候选区域放入分类器中,执行分类定位任务,该类算法检测精度高但速度慢 [2] ,主要算法有:R-CNN [3] 系列和SPPNet等;后者直接进行端到端检测,生成目标的类别概率和位置信息,大幅度降低了计算资源消耗,该类算法简单高效、检测速度快,但准确度较低 [4] ,主要算法有:SSD [5] 和YOLO [6] 系列等。
SSD算法对小目标检测性能不佳,主要原因有:特征信息少,正负样本不平衡、数据集不完备以及锚框设计难等 [7] [8] 。针对以上不足,研究人员提出很多改进算法。DSSD [9] 针对浅层特征图表征能力不强,引入反卷积模块,通过反卷积层学习得到上采样特征图与浅层特征图融合,充分利用上下文信息。M2Det [10] 针对传统FPN网络的特征层对于目标检测任务不够代表性且特征图仅包含单层信息,提出了多级特征金字塔网络,构建多尺度多层级的特征金字塔。STDN [11] 引入骨干网络DenseNet [12] 和尺度转换层(Scale-transfer layer),通过reshape函数将通道数转化为特征图的宽和高生存大尺度预测特征图,极大减少了算法的参数量和计算量。文献 [13] 针对传统交并比框回归效果差及收敛速度慢,提出基于关键点距离交并比算法,降低定位损失,减少目标漏检情况。
本文基于传统SSD算法的不足,设计了一种基于群体感受野模块与坐标注意力机制的改进SSD目标检测算法。在前两层较浅预测特征图后添加RFB模块,增加感受野。并在ResNet50网络中引入坐标注意力机制,不仅获取通道间信息,还考虑了方向相关的位置信息,有效地提升模型的准确率。比较实验结果,改进后的SSD算法检测精度有明显提升。
2. 本文模型
2.1. 网络结构
基于群体感受野模块与坐标注意力的改进SSD目标检测算法结构如图1所示。网络架构设计遵循的主要原则是在主干网络中降低特征信息损失,采用ResNet50 [14] 网络作为特征提取的骨干网络,其残差连接方式可以有效的抑制神经网络因深度增加而带来的梯度衰减问题,提高模型对图像特征的表达能力。
在主干网络提取出来的(38, 38)、(19, 19)和(10, 10)特征层后,考虑通道之间远程依赖关系,经过坐标注意力模块进行编码。为增强信息表达能力,将深层特征层与浅层特征层进行有效信息融合,(19, 19)和(10, 10)尺寸特征层采用线性插值方式将其放大到(38, 38)尺寸,并进行Concat方式融合。同时为改善网络的梯度,防止梯度爆炸,实现归一化,采用BN层处理。在生成预测特征层上,采用反卷积方式再次进行特征融合 [15] ,并为增加感受野,获得更大的上下文信息,添加了RFB模块。从可以得出,低层特征层分辨率较高,包含更多图像细节。
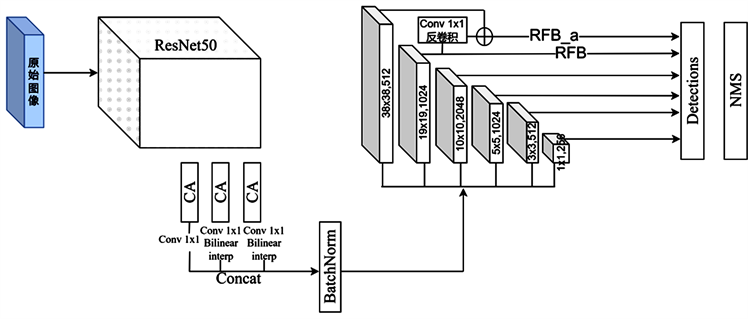
Figure 1. SSD object detection algorithm based on RFB and attention mechanism
图1. 基于RFB与注意力机制的SSD目标检测算法
2.2. 坐标注意力模块
坐标注意力模块 [16] 如图2所示。为了缓解二维全局池化导致的位置信息损失,坐标注意力将通道注意力分解为两个并行的一维特征编码过程,分别沿两个空间方向聚合特征,有效地将整合空间坐标信息输入到生成的注意力特征图中。
具体来说,输入的特征图为X,大小为
的特征图,其高和宽为H和W,高度为 的第c个通道的输出
为:
(1)
式中
为第i行特征向量。
宽度w的第c个通道的输出
为:
(2)
式中
为第j列特征向量。
通过上述操作可以获得全局感受野和位置信息。拼接两个输出结果后,再使用1 × 1卷积操作可以得到空间信息经过编码后的中间特征图F。
(3)
式中
为所有高度为h的通道的输出;
为所有宽度为w的通道的输出;
为特征图在垂直和水平方向上的拼接;F1为卷积操作;
为非线性激活函数。
然后将F切分为2个单独的张量,再分别利用1 × 1卷积变换成X相同的通道数,最后利用Sigmoid激活函数得到注意力权重
和
。
输入特征图X的第c通道上高度为i宽度为j的特征
经过坐标注意力模块后的输出
为:
(4)
式中:
表示第c通道上高度为i的水平注意力权重,
表示第c通道上宽度为j的水平注意力权重。
2.3. RFB模块
RFB模块 [17] 是通过多分支结构是由于不同尺寸的卷积核卷积同一张特征图可以得到不同大小的感受野,模拟人类视觉感受野的不同范围。网络结构借鉴Incetion思想,核心结构包括多个分支,分别对应不同的感受野,最终通过Concat函数合并在一起。感受野随着卷积神经网络层数的增加而变小,影响了网络对特征的提取能力和检测效果。
本文采用的RFB模块的两种结构如图3所示,由多分支卷积结构和空洞卷积构成。先用一个1 × 1的卷积减少通道数,再加上一个3 × 3的卷积,RFB_a模块第1个分支为一个空洞率为3的3 × 3空洞卷积,第2个分支先经过一个3 × 3的普通卷积,再经过一个空洞率为3的3 × 3空洞卷积,第3个分支首先经过两个3 × 3的卷积,其效果等于一个5 × 5的卷积,之后经过空洞率为5的3 × 3空洞卷积,最后通过Concat通道级联。RFB-b和RFB_a相比主要采用1 × 3和3 × 1卷积层代替3 × 3卷积层,主要增加了模型的非线性特征并减少计算量。
3. 结果与分析
3.1. 数据集和评价指标
数据集:本文采用公开数据集PASCAL VOC 2007 + 2012进行实验,该数据集总共有20种常见类别,此次实验为扩大训练集数据,合并了VOC 2007和2012的训练集,测试数据为VOC 2007测试集。
评价指标:mAP作为目标检测领域重要评估指标之一,综合考虑了所有的类别以及定位精度等问题,其值越大模型的检测性能越好。计算方法为式1~式3。
(5)
(6)
(7)
实验平台配置:本实验操作系统为Windows11,具体配置如表1所示。

Table 1. Experiment configuration parameters
表1. 实验配置参数
3.2. 结果与分析
为了验证改进后模型的有效性,本文设置了对照实验:① 标准SSD模型作为实验对照组;② 使用ResNet50作为骨干网络,在特征提取阶段融合不同深度特征图;③ 在实验2的基础上,增加坐标注意力模块;④ 在实验3的基础上,增加RFB模块,同时将19尺寸特征图反卷积操作与上层特征图融合。
4种模型的实验结果平均精度值mAP如表2所示,分析实验结果,在原SSD模型基础上每改进后,mAP值均有提升,其中引入坐标注意力模块和RFB模块后,mAP值分别提升了0.92%和0.85%。实验表明,坐标注意力模块和RFB模块对于传统SSD算法性能的提升有着显著的效果。
Table 2. Comparison of PASCAL VOC 2007 test sets
表2. PASCAL VOC 2007测试集对比
20种目标类别检测准确率AP如表3所示,绝大部分类别的准确率均有显著提升,其中aeroplane、bird、diningtable和tvmonitor尤为突出,分别提升了4.21%、3.62%、4.45%和4.28%。
Table 3. 20 categories of different algorithm test results
表3. 20种类别不同算法测试结果
VOC2007测试集数据有4952张,测试阶段通过单张批量测试得到分类损失、定位损失及总损失,以传统SSD算法作为基线模型,对比每个组件对模型的检测性能的作用,本文模型的总损失值最低且收敛速度略优于原模型,表明了本文模型能有效降低分类定位损失,提升算法的检测性能。分类损失和回归损失的总损失效果对比如图4所示。
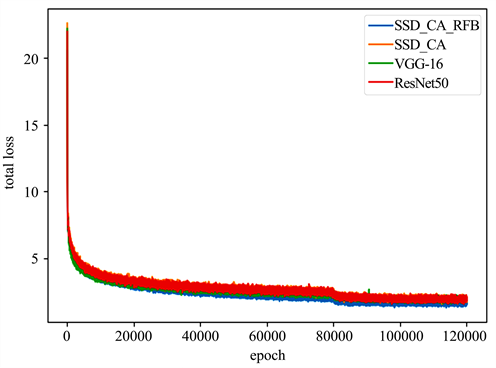
Figure 4. Comparison chart of different algorithms
图4. 不同算法loss对比图
4. 结论
本文设计了一种基于群体感受野模块与坐标注意力机制的改进SSD目标检测算法,采用ResNet50网络作为特征提取的骨干网络,并引入轻量级坐标注意力机制,能够同时考虑通道间关系以及长距离的位置信息,利于模型更准确定位目标信息,增强识别能力,且坐标注意力模块轻量灵活仅带来少量的计算消耗。在特征提取阶段通道拼接融合不同深度卷积层输出,丰富预测特征图上下文信息,同时在预测过程中加入RFB模块,通过不同尺寸卷积核的多分支结构和空洞卷积来提高感受野,增强特征提取能力。通过实验验证,叠加各个模块后,算法的检测精确度均有提升。实验表明,改进后目标检测算法在PASCAL VOC数据集上各类别的检测准确率较传统SSD算法有着显著提高,mAP比传统SSD算法提升了1.91%。
基金项目
国家自然科学基金(61872190);江苏省博士后科研资助计划项目(2020Z058)。