1. 引言
随着大数据信息技术的高速发展,电商行业的销售模式也随之而转变,会应个人喜好、生活习惯、价格区间等各类因素的综合参考,来决定某件商品的销售策略、方式及价格。因此,各大销售平台开始注重商品销售量及需求量的准确预测问题,可利用人工智能的方法 [1] 快速准确地实现商品销量、需求量的预测,高效提升整个商品生产供应链的绩效,大幅度提升市场竞争力,维持商品销量的稳定发展。然而,在过往的研究中,大部分商品的销量预测或需求量预测问题,均采用了时间序列预测方法 [2] [3] 或机器学习的预测方法进行处理。如:胡小芳(2022) [4] 和Yasaman (2022) [5] 等采用了神经网络、传统时间序列模型等方法对零售店的商品销售情况进行了预测。但时间序列预测方法对原始数据集的时序长度要求较高,需在保证有较长的时序长度信息的条件下,才能更丰富地提取时序信息与目标变量间的关系,实现高精度的预测任务。考量本文采用的数据集,其时序信息既不连续也不充足,导致无法准确提取到丰富的时序信息。
同时,还有较多学者采用了机器学习或集成机器学习的方法实现商品销量的预测 [6] [7] [8] [9] ,如:刘辰阳(2022) [10] 、吴霆辉(2023) [11] 和谢勇(2019) [12] 等分别采用了特征工程与机器学习模型结合的方法或是几种机器学习模型集成的方法来预测了电力负荷、住房月租金和商品销量等目标,其中吴霆辉就将LightGBM模型与XGBoost模型相融合,使模型的拟合优度提升到0.98左右。王晓辉(2020) [13] 提出了基于遗传算法与随机森林的XGBoost改进方法的研究,使模型的拟合优度提高了0.01%~2.1%左右。霍佳震(2023) [14] 则在GBDT模型的基础上提出了基于EEMD-Holt-Winters-GBDT模型,在零售商品销量多步预测问题中表现出良好的预测性能。还有Wang (2022) [15] 和Yuanyuan (2020) [16] 等采用了LightGBM模型与TCN网络方法、K近邻算法的结合。各类机器学习方法、特征工程处理方式的相融合的方法,能实现相对于单个机器学习模型预测精度的提升,但多种机器学习方法融合的方式存在一个计算时间缺陷。由于单个机器学习模型实现预测任务时,训练时间较长,融合多个模型的同时,虽然提高了一定的准确性,但计算速度较慢,使其模型若投入产品应用中并不能达到理想状态。
在该基础上,本文即思考和探索是否能在保证高效计算速度的同时,实现模型预测性能的提升,并将此作为文章的主要任务。近年来,陈俊龙教授(2018) [17] 提出了一种宽度学习系统(BLS),可通过增强节点的引入来增加网络中的非线性因素,以此更大信息化地提取输入数据集的特征信息。该方法在各类预测任务中也得到了广泛的应用,如:苏理云(2023) [18] 等提出了一种宽度学习方法与多头注意力机制相结合的框架,可捕获关键的时空特征信息以实现更高的预测性能;还有褚菲(2020) [19] 则从理论上提出了基于lasso和elastic net的宽度学习系统(BLS)网络结构稀疏方法;杨光雨(2022) [20] 提出了一种基于最大信息挖掘宽度学习系统多核最小二乘支持向量机进行了短期电力负荷预测,得到了较高的预测精度。基于已有学者将宽度学习融合应用的方法,发现宽度学习模型优秀的运算速度、可自动捕捉数据集特征及非线性特征的优点,均能恰好弥补机器学习中树模型的缺陷,于是本研究即考虑通过实证分析的方式来验证是否宽度学习模型能帮助机器学习模型,提升在订单需求量预测任务上的预测性能,并增强其泛化能力。
2. 研究设计
数据来源
本研究的实证数据来源于第十一届泰迪杯B题中提供的企业面向经销商的出货数据,主要涵盖近60万条商品销售数据,其中数据集包含5个不同地区、8种商品大类、12种商品细类,近一千多种商品类别的销售情况数据。数据集的样本区间为2015年9月1日至2018年12月20日。
数据来源网站参考如下:https://www.tipdm.org/。
3. 研究方法
3.1. 特征工程
特征工程(Feature Engineering)是选择、操作和将原始数据转换为可用于监督学习变量特征的过程,以便于将所提取的变量特征应用到构建的预测模型中,达到提升模型预测对未知数据的准确度。简而言之,即通过特征工程的处理方式提取出自变量X中存在的显著影响特征和信息。
本研究中即应用特征工程提取了商品销售数据的节假日信息、促销日信息、月末月初等时序信息,继而还对数据进行了去重处理和商品价格信息的分箱处理,以平均价格(
)压缩了价格特征,即:
(1)
其中T为日期;code为同个商品的编码。
由于商品的大类和细类数据属于离散型数据,为了使机器学习模型能更好的识别到该类变量的特征信息,还采用了特殊的编码处理方式。最后,考虑到商品的历史订单需求量数据与当期需求量数据间的相关性,进而提取了该变量的滞后特征和趋势特征。
3.2. 特殊编码处理
1) 均值编码:
当数据集中存在定性特征时,由于定性特征表示某个数据属于一个特定的类别,其数据均表现为类别的离散型数据,为了充分提取分类变量的信息量,均值编码通常的处理方式即把概率替换成均值,y为目标变量,x为定性特征变量:
(2)
其中:
表示
对应的y均值,
是整个训练集上y的均值。
2) 独热编码:
独热编码又称哑变量,是将离散特征的取值扩展到欧式空间上,且离散特征的某个取值分别对应欧式空间上的某个点,根据特征之间的距离进行编码,且编码后的特征,每一个维度的特征都可以看成连续的特征,能实现从离散到连续的转换。且每列变量被拆开为连续性的均标注为0或1。
3.3. 宽度学习模型
宽度学习(Broad Learning System)系统是一种有效且高效的增量学习系统,与深度学习不同,它是一种不依赖于深度结构的神经网络结构。实质是一种随机向量函数链接神经网络,但与CNN不同,该网络并不通过反向传递改变特征提取器的核,而是通过求伪逆计算每个特征节点和增加节点的权重。
首先,需要构建输入数据到特征节点的映射,其映射的特征节点即实现了高效特征提取的能力。在特征学习阶段,原始输入数据通过特征映射节点随机转换为特征,然后将其连接到增强节点作为输入。
假定存在m组特征节点,且每个映射节点具有q个特征,假设输入数据为
,其中
为输入样本数,也即嵌入维数;则第一映射特征节点的映射特征公式如下:
(3)
其中:
表示随机生成的权重,
为第i组映射节点;
表示输入数据的激活函数。
级联的映射特征
和D会被进一步连接到增强节点。假设存在增强节点,则第j组的增强信息可通过如下的公式得到:
(4)
其中,
和
分别表示随机产生的权重和偏差,且
是激活函数。
则最终得到增强特征的输入即:
(5)
3.4. 基础模型介绍
3.4.1. 随机森林模型
随机森林(Random Forest, RF)属于Bagging算法之一,可通过组合多个弱分类器,最终结果以投票或取均值的方式,使整体模型的结果具有较高的精确度和泛化性能。且采用的CART决策树是基于基尼系数来选择特征的。
对未知样本x的预测可通过对所有单个回归树的预测取平均来实现:
(6)
3.4.2. 梯度提升决策树模型(GBDT)和XGBoost模型
GBDT和XGBoost模型均是属于集成学习中Boosting提升算法,其中GBDT主要是借助梯度下降的优化方法,且使用损失函数的负梯度,没有加入正则化项。而XGBoost则是基于二阶泰勒展开优化损失函数,在GBDT的基础上引入了正则化项
,提高模型的计算精度,并将其目标函数变为:
(7)
其中
是线性空间上的表达;k表示第k棵树,
即第i个样本
的预测值。
3.4.3. LightGBM模型
LightGBM (Light Gradient Boosting Machine)是一种开源的分布式高性能梯度提升,原理和GBDT类似,但具有更高效的训练,更低的内存使用以及更高的结果准确性等特性。相比较于GBDT和XGboost算法,LightGBM使用的是直方图算法,占用的内存更低,且数据分割的复杂度也更低,能够在不损害准确率的条件下,加快GBDT模型的训练速度。其思想主要将连续的浮点特征离散成K个离散值,并构造宽度为K的Histogram,通过遍历训练数据,统计每个离散值在直方图中的累计统计量。
综合对比以上梯度提升树模型各自的技术特点,发现随机森林(RF)模型具有对数据质量较低,且基学习器出错不会对整体结果造成较大影响的优势;GBDT则将所有决策树的结果进行求和得到最终结果,在数据质量较好的情况下具有更好的精度;XGBoost模型引入正则化项后,在GBDT模型的基础上缓解了过拟合的情况,并减少了运行时间;LightGBM与XGBoost模型类似,保留了原本XGBoost的优势,并增进了可直接处理连续或离散特征的特点,在保证精度的同时再次提升了模型的计算速度。
3.5. 集成宽度学习算法
由于机器学习模型多从数据指标自身提取特征信息,来实现模型的预测,未充分考虑到特征变量间的非线性特征信息,继而导致降低了模型的预测精度。然而宽度学习算法(BLS)恰好可以解决这类问题,可充分提取特征变量间存在的非线性关系。于是本研究提出了集成宽度学习算法的模型框架,即分别将随机森林、GBDT、XGBoost和LightGBM模型与宽度学习(BLS)算法进行集成融合,其集成算法的基本实现步骤如下:
Step1:经特征工程处理后得到的指标变量
和目标变量
,首先将指标变量
分别输入Random Forest(随机森林)、GBDT、XGBoost和LightGBM模型中,经模型训练后得到不同区域商品订单需求量的预测值
(m表示选取的预测模型)。
Step2:其次,将Step1中得到的四个模型预测值,根据区域的不同依次纳入Step1中的指标变量
中,重新进行特征融合后,得到新的指标数据集:
,即分别添加一维不同区域对应的
后得到的
,其中Step1所提到的四种预测模型,将这些新的
依次作为新的输入特征。
Step3:最后,采用宽度学习(BLS)的方法,分别对新的特征数据集
实现商品需求量的预测任务,得到由RF-BLS、GBDT-BLS、XGB-BLS、LGBM-BLS这四类集成算法得出的最终预测结果
。具体流程可参考如下图1和图2,其中图2为图1中宽度学习算法(BLS)的基本框架图,作为图1的补充。
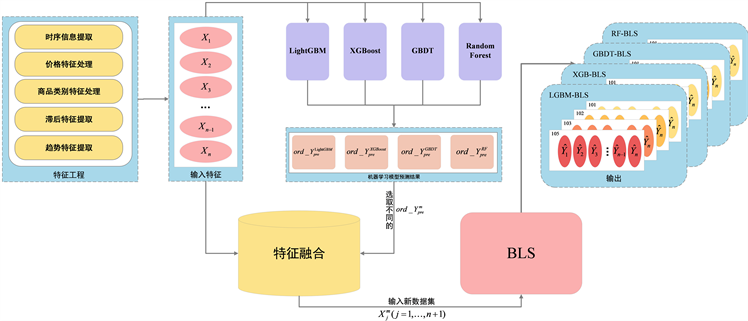
Figure 1. Integrated width learning algorithm framework diagram
图1. 集成宽度学习算法框架图
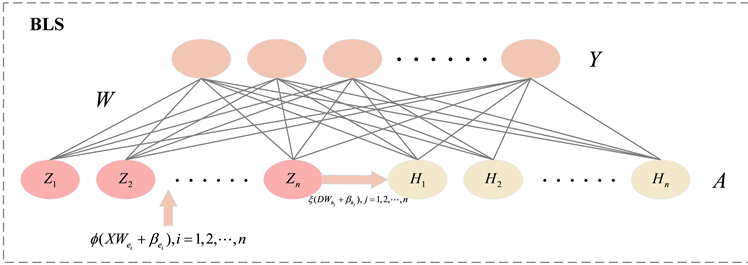
Figure 2. Width learning algorithm framework diagram
图2. 宽度学习算法框架图
4. 实证结果与分析
4.1. 特征工程及其分析结果
为了提升模型的准确度,本研究构建了特征工程,来提取原始数据中对商品需求量的直接影响变量和潜在影响变量。原始实证数据涵盖的变量信息有:订单交易时间、商品区域代码、商品编码、商品大类编码、商品细类编码、销售方式、产品单价及订单需求量。目标预测变量即为订单需求量(ord_qty),考虑到原始数据集本身存在时间信息,特征工程的第一步即提取了原始数据集中潜在的时间信息,如:是否节假日、是否工作日、是否月中月末、是否促销日等信息,其中促销日和节假日信息对商品的需求量存在显著的影响。
其次,观测整个数据各类商品的数据分布情况,发现共计有1294种商品,但每种商品对应的订单数据量并不相同,且每次订单数据产生的时序信息也并不均匀、时间段并不连续。某类商品还存在同一天具有多条订单信息的情况,为了充分提取商品的价格信息,本研究考虑将该类同天存在多条订单信息的价格数据进行压缩处理,采用均值处理日期相同、且商品相同的价格数据,使同天内,同类商品的价格数据信息仅保留其对应日期的均价;然而,由于数据集中各类商品的价格信息波动范围较大,其原因可能是由于商品种类的不同,而导致价格波动范围也存在较大差异,为了更好的提取因类别造成价格差异的特征信息,添加了平均价格分箱特征,来获取商品间的差异性。除此外,还根据商品线上线下的销售方式,添加了不同商品的线上线下销售比这一特征信息。其中,各类商品的时序分布情况如下图3所示。
根据不同商品时序图的分布情况,发现各类商品对应的时序长度存在较明显的差异,数量较多的时序长度基本分布在[0, 50]天,而超过100天的时序长度较少,且分布不均匀,同类商品中还存在时序信息不连续的情况。故针对该类时序数据分布不均,且长度较短的数据集,若采用时间序列模型预测商品需求量并不合适,因为数据本身体现的时序信息不能充分的识别到商品需求量信息随时间变化的规律,反而可能造成错误的信息干扰,从而影响模型的预测准确度。据此因素,且结合考虑数据集中存在定性特征,本研究则选择了随机森林、GBDT、XGBoost类型的树模型及宽度学习模型来识别指标变量特征,预测订单需求量。
最后,因考虑到商品的历史需求量数据对当期订单需求量数据的影响,添加了需求量变量的1, 2, 3, ∙∙∙, 48, 60阶的滞后项特征,获取历史需求量的波动信息;还添加了商品需求量的移动平均特征,获取相邻日期间需求量数据间存在的影响;需求量数据的变化趋势特征也同样属于目标变量的直接影响变量,故特征工程中也添加了该变量的趋势特征。由于商品大类和细类等分类数据,属于定性数据、均是离散分布的,于是针对类别数据分别采用了均值编码和独热编码的特殊编码处理方式。
最终,经过特征工程处理后,得到59维输入特征变量。
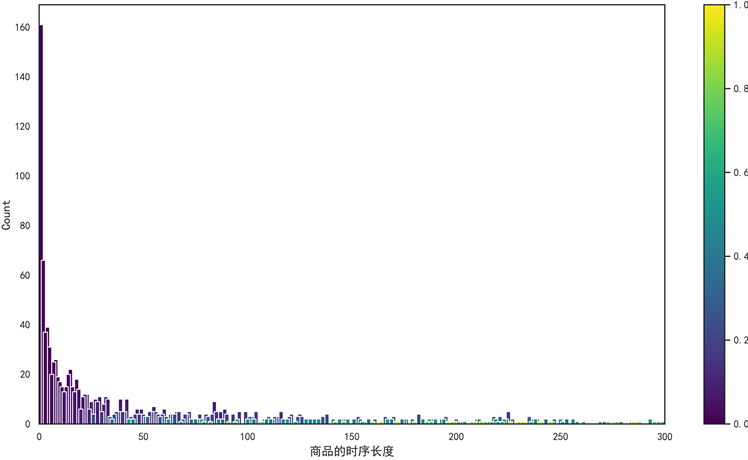
Figure 3. Statistical chart of chronological lengths for all categories of goods
图3. 全类商品的时序长度统计图
4.2. 模型效果评价指标
为了衡量模型的预测性能,本研究选择了均方误差(Mean Square Error, MSE)、平均绝对误差(Mean Absolute Error, MAE)、均方根误差(Root Mean Squared Error, RMSE)、平均绝对百分比误差(Mean Absolute Percentage Error, MAPE)作为评价指标,并结合模型计算耗时(Time)来综合评定模型效果的优劣。各模型的评价指标计算公式如下:
(8)
(9)
(10)
(11)
4.3. 集成模型与机器学习模型的对比分析
4.3.1. 基于机器学习模型的区域全商品需求量预测
综合文献分析,发现电商订单需求量预测任务中,较多学者采用随机森林(Random Forest)、梯度提升决策树(GBDT)、XGBoost和LightGBM这四种机器学习模型 [2] [3] [4] ,而为了在此基础上,探索一种精度更高且计算速度更优的模型框架来帮助更好地解决电商订单预测问题,即需首先探究这四种模型在本研究中数据集上的表现能力,并便于根据不同模型的预测能力分析其优缺点。
因原始数据集中,商品存在区域差异,为了更准确的预测出全品类商品的订单需求量,将训练集数据按区域拆开,分别对各区域(101、102、103、105区域)的订单需求量进行预测。其中,训练集数据的时间维度为2015年9月1日~2018年12月12日,共113,332条商品订单数据,测试集数据时间维度为:2018年12月13日~2018年12月20日,共计12,593条不同商品的订单数据。经实证结果比较发现,四种机器学习模型中Random Forest 和XGBoost模型是效果最好的,且各模型在103地区均表现最优,则此处仅列举了103地区各模型的评估结果:

Table 1. Area 103—evaluation results of machine learning models
表1. 103地区——机器学习模型的评估结果
综合比较表1中四种模型的结果发现,机器学习模型预测精度的排名依次为:Random Forest > XGBoost > GBDT > LightGBM,计算速度的排名依次为:LightGBM > GBDT > XGBoost > Random Forest。很明显LightGBM模型在本研究数据集上表现出了较差的预测精度,仅在计算速度占据了较强的优势,但通常情况下LightGBM较XGBoost模型相比具有更优越的准确性和计算速度,而在本研究的数据集上,Random Forest和XGBoost却表现出了更优越的预测性能,其原因可能是由于数据特性造成的,机器学习模型的预测效果均较依赖于特征工程的处理,同时XGBoost模型中提供了较多的正则化选项,有助于控制模型的复杂性。即GBDT、XGBoost和LightGBM模型对数据质量的要求较高,更适用于数据特征信息丰富且存在显著关系的数据集,而Random Forest对数据质量的要求相对较低。
于是考虑到电商订单预测问题的实用性,需实现产品订单需求量的高效预测。本研究考虑探寻既能保持LightGBM模型计算速度的优势,又能高效提升LightGBM模型预测精度的方法。因宽度学习模型具有可自动从原始数据中学习有用的特征,不依赖于特征工程的处理;且模型中添加了L1和L2正则化,有助于限制模型的参数大小,控制其复杂性和防止过拟合等优点。且这些优点均是LightGBM模型所欠缺的,于是本研究就宽度学习和LightGBM的互补性,提出了一种融合宽度学习的集成算法框架,并通过实证分析的方式探究了机器学习模型和宽度学习模型的融合方式,是否能帮助模型提升其预测精度和计算速度,达到更好的预测性能,尤其是LightGBM模型是否能达到预期目标的效果,以下3.3.2小节对此展开的具体分析。
4.3.2. 集成宽度学习模型实证对比
根据2.5小节提出了集成宽度学习算法结果,分别采用RF-BLS、GBDT-BLS、XGB-BLS、LGBM-BLS这四种集成算法对同样的数据集进行实证分析,经模型评估结果的对比发现该四种模型在103地区的表现最优,105地区表现最差,于是为对比集成算法模型和机器学习算法的预测能力,仅需在预测能力表现最差和最优的地区均呈现出集成模型更优的预测性能即可,以下即为集成宽度学习算法和机器学习算法分别在103和105地区的模型评估结果:
Table 2. Evaluation results of integrated algorithmic models and machine learning models
表2. 集成算法模型及机器学习模型的评估结果
*注:RF为Random Forest缩写;GBDT为梯度提升决策树的缩写;XGB为XGBoost缩写;LGBM为LightGBM缩写;BLS为宽度学习(Broad Learning System)的缩写;(+0.4567)和(+0.6501)分别为LGBM-BLS模型与LightGBM模型的计算速度差。
根据表2中模型的评估结果可观测到,融合宽度学习的集成算法模型与原始机器学习的模型预测精度相比,基本均有所提升,使改进后的集成算法模型均在预测精度上得到了较大幅度的提升,且计算速度基本保持不变,其时间误差控制在了1秒以内。此外,交叉比较四种传统机器学习模型和四种集成算法模型的效果,容易发现LGBM-BLS模型的预测性能最优,它不仅表现了模型最优的预测准确性,同时也兼顾了优越的计算速度,很好地融合了BLS和LigntGBM模型本身的优点,与LigntGBM模型相比其计算时间仅相差0.5秒左右,与其他三种集成算法相比,具备更强的预测能力,达到了订单需求量预测任务的预期目标。且表明文章所提出的该四类模型适用于样本量及特征量丰富、存在分类特征信息的数据集,例如:电商数据分析、股票数据分析以及能源相关数据分析等。
为了便于更直观地观测到集成宽度学习算法预测精度的大幅提升,在表2的基础上选取了RMSE指标,绘制了传统机器学习模型与集成宽度学习算法间RMSE指标对比图,并计算了两类模型对应RMSE指标的降幅(见图4):
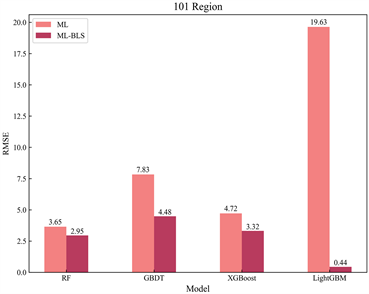

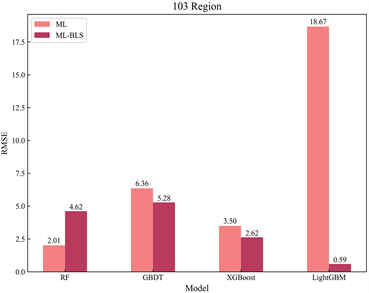
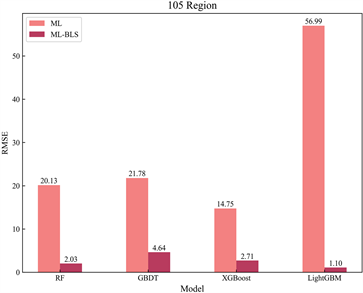
Figure 4. Comparison chart of RMSE metrics between models
图4. 模型间RMSE指标对比图
图4中ML表示机器学习模型(Machine Learning),ML-BLS表示与宽度学习融合的集成算法;各柱子上方的数值标签即为集成算法与传统机器学习方法对应的RMSE误差值。对比ML和ML-BLS,显然LGBM-BLS是降幅最大的,在各地区该模型的均方根误差(RMSE)均下降了90%以上,说明LGBM-BLS的预测精度最优。进而,本研究继续将LGBM-BLS模型在测试集上的预测效果进行了可视化,得出了预测值与真实值间高度吻合的结论(见图5):
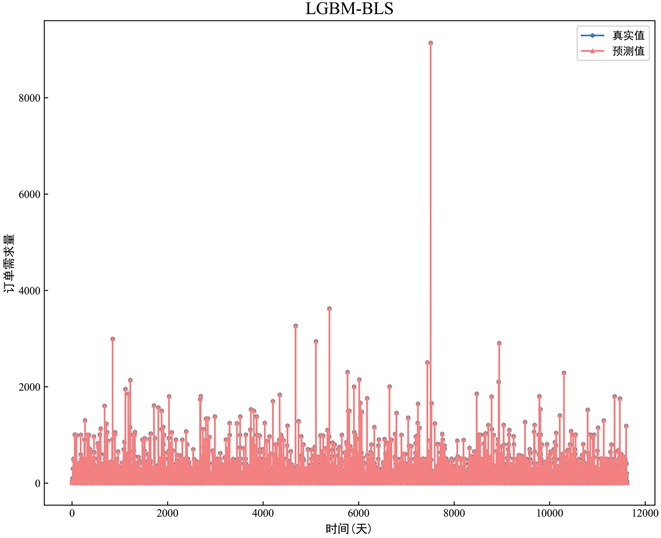
Figure 5. Test-set prediction effects of LGBM-BLS modeling
图5. LGBM-BLS模型的测试集预测效果图
最后,对集成宽度学习算法和机器学习模型的计算性能进行了可视化,以下为ML和ML-BLS分别在101、102、103和105地区测试集上的计算时间对比图。
图6中各柱子上的数值标签为集成宽度学习算法与对应的传统机器学习模型在测试集上的计算时长,从该数值的大小能直观观测到,集成算法均继续保持了ML模型原有的计算速度,并未因为算法的融合而出现更高的时间复杂度;同时,更容易发现LGBM-BLS模型的计算优势远超于其他模型。

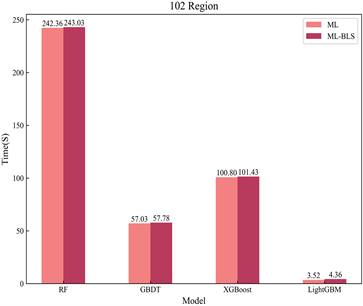


Figure 6. Comparison chart of computation time for each model (test set)
图6. 各模型计算时长对比图(测试集)
5. 结论与建议
不同的模型均存在各自的优缺点,随机森林(Random Forest)、GBDT、XGBoost和LightGBM模型中,LightGBM具有较明显的计算速度优势;但是,若要同时兼顾预测模型的精度和计算速度,显然仅靠LightGBM模型的效果是不够的,且当采用LightGBM处理大规模数据集时还容易产生过拟合的情况。然而LightGBM-BLS的融合却很好地解决了该问题。由于正则化项的存在,有效地防止了模型的过拟合,且能避免模型精度容易受到特征工程效果的影响,因为宽度学习模型能自动从原始数据中学习有用的特征,降低了模型对特征工程的依赖度,使模型能最大信息化利用原始数据集的丰富特征,实现预测任务。
因此,本研究结合宽度学习模型的优势,提出了宽度学习模型与机器学习模型集成的算法框架,均在一定程度上提升了RF、GBDT、XGBoost和LightGBM模型的预测精度。尤其是LightGBM-BLS模型很好的达到了预期为实现高效计算且高精度预测的目标,为销售行业的订单分析及预测问题,提供了较好的思路方法,具有丰富的参考价值和实际意义。
基金项目
2023年重庆市教育委员会人文社会科学研究重点项目(23SKGH251)和2022年重庆理工大学研究生教育高质量发展行动计划资助成果(gzlcx20223313和gzlcx20223314)。
NOTES
*通讯作者。