1. 引言
我国在线知识付费市场规模日渐扩大,预估在2025年我国在线知识付费金额可以达到2900亿元,而在线付费用户数也将超过6亿。在线知识付费行业已经成为互联网新的增长点,具有很大的市场规模和用户人数,在线知识付费已经成为互联网用户获取高质量信息、专业知识、专业技能等相关内容绕不开的渠道。但是我国在线知识付费行业虽然在高速发展,但是同时也会遇到很多的困难和挑战。在线知识付费平台提供的内容不能满足用户的旺盛需求。知识付费行业虽然产出很多“新的”内容产品,但是同质化内容高,缺乏自主创新性,更为突出的是宣传虚假问题,缺乏对用户的长远吸引力和复购欲。所以如何扩大推荐用户群体,如何增强用户黏性是当下知识付费平台应关注的重点。
关于知识付费概念尚未统一,学者们从不同角度对知识付费进行定义。张晓燕 [1] 认为知识付费是认知盈余的人作为知识贡献者,用户以满足自身需求为知识或经验进行付费的行为。杨昕雅和胡鑫 [2] 认为知识付费并不仅指用户为获取知识而购买知识产品,而是一种为获取虚拟知识和移动社交分享的新型共享经济形态。方军 [3] 认为知识付费以满足人们需求为目的,购买知识产品或服务从而进行知识有偿传播与共享的行业模式。Jin等 [4] 研究发现用户知识贡献行为会受到多方面因素的影响,包括其他成员的认可程度、用户的自我呈现和社会学习机会等因素。Lee等 [5] 研究证实了金钱激励、内在动机(乐趣、学习机会、利他因素)对用户知识贡献行为的积极影响,金钱激励越高及用户自身知识贡献行为的内在动机越大,越容易促进用户的知识贡献行为。张杨燚等 [6] 研究指出,知识付费用户需求聚焦于知识供给者能否为其提供专业性、交互性、同质性显著的优质知识服务。刘齐平等 [7] 基于社会资本理论分析发现知识供给者的评分情况、评论数量、教育背景等条件会对用户的知识付费行为产生显著影响。刘周颖等 [8] 研究指出,知识焦虑、娱乐视听、能力提升、自我表达等用户需求驱使人们产生知识付费行为。金小璞等 [9] 研究指出,用户对于知识付费平台的需求主要体现在平台系统可靠性、导航的有效性以及页面布局的清晰性等方面。范建军 [10] 研究表明,知识付费平台的可用性和易用性是用户追求的主要需求,充值、学习、交互、反馈等过程的繁琐可能会降低用户的使用体验感。
对于知识付费影响因素的研究,赵菲菲等 [11] 基于技术接受模型,通过问卷调查法与结构方程模型方法,研究探究用户的个人收入、工作年限与其知识付费意愿的关系。张帅等 [12] 选取18位知识付费用户进行半结构化访谈,对访谈资料进行质性研究,探究个体需求是影响用户知识付费行为最关键的因素。李武等 [13] 从感知价值视角出发,采用问卷调查法和结构方程模型方法展开研究,探究内容收益和经济收益对在线付费问答平台用户的感知价值的影响。方爱华等 [14] 通过问卷调查法共获取321份有效样本数据,对数据进行实证分析探究感知收益与用户知识付费意愿之间是否呈正相关的关系,从而感知成本对用户付费意愿的影响。李钢等 [15] 基于计划行为理论,采用结构方程模型方法分析研究在线知识付费平台用户的付费意愿及行为是否受到知觉行为控制的直接影响,以及感知成本与付费行为之间的关系。齐托托等 [16] 爬取知乎“Live”平台中的真实数据,运用文本分析法及稳健回归分析法进行分析知识产品描述的详细、生动是否会对用户的支付意愿产生显著影响。赵杨等 [17] 爬取知乎“Live”上的知识付费数据进行回归计算,探究知识提供者的粉丝数量、文章发表篇数、回答问题数量、收获点赞数量、个人信息真实性是否会对用户知识付费行为产生重要影响。王大庆 [18] 以得到APP为例,采用结构模型方法研究发现意见领袖的知名程度、专业性与交互性对用户对知识付费平台的信任影响。陈昊等 [19] 收集了282份有效问卷数据,运用结构模型方法展开实证研究,价格合理性是否为影响用户知识付费意愿的关键因素之一。刘齐平等 [20] 针对线下专业性知识付费平台“在行网”展开了研究,爬取平台用户的真实评论数据进行质性分析,研究认知因素及情感因素对知识付费平台用户的持续使用行为的影响。
目前众多学者对影响在线知识付费意愿的因素进行了深入探讨,仍存在着考虑的影响因素偏少以及理论模型较为单一等各种不足。本文将通过问卷调查和机器学习算法进行综合研究,并且研究在线知识付费平台推荐意愿的影响因素,相比仅付费,推荐意愿强的用户,不仅会进行付费,而且通过用户的推荐会带来更有价值的用户,往往给平台带来更大的收益。通过搜集的问卷数据建立模型,科学地为平台运营商确定用户在线知识付费推荐意愿影响因素,定位满足用户需求,采取更为完善的运营措施以提升用户在线知识付费率以及推荐率,实现在线知识付费平台长久发展,为后续学者有关在线知识付费研究提供实证支持。
2. 模型建立及分析
2.1. 数据处理
由于问卷中存在9道多选题,多选题的选项分别单独构成一个变量,因此实际上共有111个自变量,自变量过多可能会出现多重共线性,导致解空间不稳定,模型泛化能力弱,影响模型的鲁棒性,因此首先通过方差过滤法,进行特征筛选,去除一些方差小于0.5的一些特征,从而增强特征重要性的有效性。通过方差过滤法最后剩余55个特征变量。
通过将数据分割为训练集及测试集,通过模型在训练集及测试集上的表现,衡量不同参数对应模型推荐意愿预测的分类效果,选出最优模型,为影响因素的分析提供模型基础。
通过网上发布的问卷,原始数据共计465条数据,将465条数据分割的比例为7:3,最终得到训练集325条数据,测试集140条数据。在建模时,首先在利用训练集建立在线知识付费的意愿程度的分类模型,调整模型中不同的参数信息,选取在训练集上分类效果最优的模型作为最优模型,最终利用测试集来评估最优模型的分类效果。因变量“向他人推荐在线知识付费产品推荐意愿程度”在分割后的训练集和测试集分布特点相同,各类别的占比基本一致。因此,认为该数据分割后仍然保持原始数据的分布特征,利用以上两个数据集分析的结果是可靠的。
2.2. 模型建立
2.2.1. XGBoost算法
XGBoost算法是Boosting算法之一,其基本思想是通过组合多个单一决策树模型,将多个弱分类器组合成为一个强分类器。XGBoost不只需要一阶导数的信息,而且要对损失函数进行了二阶泰勒展开,使得损失函数可以更快地收敛到全局最优,大幅度提升了模型效率,且增加了L1、L2正则化,可以降低模型的过拟合的风险。
设样本集:
预测值为
,其中F是所有决策树集合,
,
为不同叶子权重组成的单棵决策树。
设目标函数为:
(1)
其中
是衡量预测值
和真实值
之间差异的损失函数,
表示L2正则化,能够降低模型的复杂程度,避免过拟合,为正则化因子。
为了求得目标函数的最小值,接下来将
在
处进行二阶泰勒展开:
(2)
其中
为损失函数对
的一阶导数,
为损失函数对
的二阶导数。
结合公式(1)和公式(2)可得:
其中
为叶子结点j所包含样本的一阶偏导数累加之和,
为叶子结点j所包含样本的二阶偏导数累加之和。
2.2.2. 支持向量机算法
支持向量机(SVM)是一种用于二元分类的强大机器学习算法。其基本模型被设计为在特征空间中找到一个具有最大间隔的线性分类器,以实现对训练数据集的最优分类。与感知机算法相比,SVM的独特之处在于它不仅仅追求正确分类训练数据,更追求找到一个最优的分离超平面,使得不同类别之间的间隔最大化,并且保证分类的准确性。因此,SVM通过最大化训练数据集中不同类别之间的边界距离(即间隔)来进行分类。这个技术在寻找最优超平面时,支持向量被用来表示训练数据集中最接近分类界限的数据点。这些支持向量对于确定超平面和预测新的数据点非常重要。在二维空间中,我们所求的是最佳分类线,推广到高维空间上,求最优分类线就变为求最优分类面了。
设训练数据集
,其中
为样本的特征向量,
为样本的标记。假设超平面的方程为
,其中
是法向量,b是截距。则对于任意一个样本
点,其到超平面的距离为
。
假设超平面能将训练样本正确分类,即对于
,若
,则有
;若
,则有
,若距离超平面最近的几个训练样本点使上述等号成立,这几个点被称为“支持向量”,两个异类支持向量到超平面的距离之和为
。
为了找到具有“最大间隔”的划分超平面,我们需要解决以下凸二次规划问题
(3)
同样,为了间隔达到最大,需要
值达到最大,等同于
达到最小值。因此,公式(3)可以替换为:
(4)
公式(4)本身是一个凸二次规划问题,能直接用现成的优化计算包求解,对于上述问题,为每个约束添加拉格朗日乘子
,其中i表示训练样本的索引。然后,可以构建该问题的拉格朗日函数:
令
对
和b的偏导为0可得:
(5)
将公式(5)代入,即可将
中
和b消除,就得到最开始的对偶问题:
求解上述问题可以使用一些优化算法,如序列最小优化算法(Sequential Minimal Optimization, SMO)等。求解出
后,就可以得到超平面的方程。
2.3. 模型建立
2.3.1. 度量指标
AUC的基本思想需要同时考量分类器辨别正负样本的分类效果,在模型的正负样本失衡的前提下,AUC对于分类器效果的衡量依然能够较为合理和准确。本文中将使用AUC作为在线知识付费产品推荐意愿程度分类模型效果度量的指标。由于因变量“向他人推荐在线知识付费产品意愿程度”取值分别为:强意愿=1,弱意愿=0,而且由由于强弱意愿比例差距大。因此,可以通过计算AUC来衡量模型对于总体的在线知识付费产品推荐意愿的预测效果。
AUC可以简单理解为统计所有正样本个数M,负样本个数N,遍历所有正负样本对,统计正样本预测值大于负样本预测值的样本对个数。
准确率(Accuracy)是指正类和负类被正确预测的比例,因此我们可以通过计算不同类别的准确率来评估模型对各个类别的预测效果。该模型准确率使用推荐意愿的预测结果与问卷收集结果y计算得到,计算公式如下:
2.3.2. 模型分析
为了更好地验证本文模型的优越性,将数据通过不同模型进行训练,可得到两个分类模型的十折交叉验证结果,使用准确率和AUC值进行对比。SVM分类器的准确率为0.766,XGBoost准确率为0.886,表明基学习器并不适合对这类数据进行分类处理。集成算法中在准确率指标上表现最优。XGBoost模型的预测精度很高,通常比其他机器学习算法的预测精度更高。通过图1和图2可知,通过ROC曲线对比,XGBoost模型的AUC值为0.77,SVM的AUV值仅有0.56,其实和随机判断没有差别,预测效果并不好。非线性的模型表现更好,这表明该数据表现出复杂的非线性关系,所以基于非线性的模型往往可以获得更好的分类效果。
综上,基于AUC值和准确率选择XGBoost算法作为预测模型,并且XGBoost可以自动从训练数据中选择最有用的特征,可以选取重要特征作为影响因素。
2.4. 模型调优
基于XGBoost算法分类模型在建模过程中,需要调优的参数如表1所示。

Table 1. Parameter tuning and interpretation of a classification model based on the XGBoost algorithm
表1. 基于XGBoost算法分类模型调优参数及释义
首先,在设定学习率learning_rate=0.1的基础上,对决策树数量n_estimators进行调优。模型分类的AUC值随着决策树数量的增大而显示出降低趋势,在决策树数量n_estimators=181时模型的平均准确率为0.951,此时分类效果最佳,因此选定n_estimators=181为决策树数量的最优值。
其次,对模型中的max_depth以及min_child_weight参数进行调试,见图3。不同max_depth和min_child_weight参数组合在训练集上的分类效果也在变化,XGBoost分类模型随着max_depth的增长,模型对于局部样本的学习能力增强,在训练集上的平均准确率越来越高,但是随着模型中min_child_weight的增加,模型欠拟合越要越严重,导致在训练集上的平均准确率降低。XGBoost分类模型max_depth和min_child_weight参数的不同组合在训练集上的平均准确率在max_depth=7、min_child_weight=0.1时最高的0.962,因此选取此参数组合为最优组合继续进行参数调优。
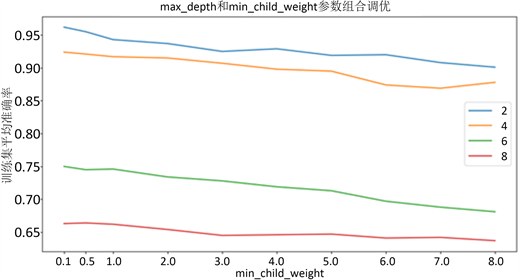
Figure 3. Optimizing the max_depth and min_child_weight parameters for the XGBoost model
图3. XGBoost模型的max_depth以及min_child_weight参数调优
最后,针对XGBoost分类模型的正则化参数gamma进行参数调优,gamma参数可以降低模型复杂度,从而提高模型表现,这个参数的值越大,算法越保守。当gamma值在0至1的范围内变化时,模型正在训练集上的平均准确率变化不大,但是在gamma取值在1至10的范围内变化时,模型在训练集上的平均准确率明显降低。XGBoost分类模型在gamma取值为0.1时,在训练集上预测结果的平均准确率为0.969,因此选择gamma=0.1作为最优参数取值。
综上所述,通过调整XGBoost模型中的learning_rate取值为0.1,n_estimators取值为80,max_depth取值为0.1,min_child_weight取值为7以及gamma取值为0.1为最优模型,其AUC=0.969,准确率提升12.7%。
3. 在线知识付费推挤意愿影响因素及预测
选取的最优分类模型在测试集上的AUC值为0.784,XGBoost模型的推荐分类预测效果比较令人满意。在强弱意愿样本不平衡的情况下,仍对在线知识付费人群的推荐意愿程度不同类别作出合理的评价,因此下面将此模型的变量重要性,作为推荐意愿影响因素重要性的衡量标准。
XGBoost分类模型在进行预测时,其内部会生成变量重要性排序,其模型内的变量重要性算法Feature_importances指标是基于Gini系数计算的,该系数表示不同变量在每个弱分类器上节点所对应观测值的异质性所带来的影响,就可以判断不同变量的重要性大小。Feature_importances指标值越大,也就是这个变量越重要,但是其重要性的衡量并不代表具有因果关系。基于XGBoost模型内部变量重要性排序结果如图4所示,图中展示了变量重要性排名前十的变量
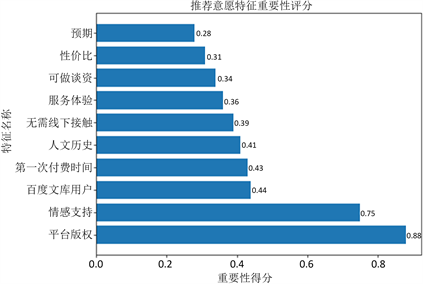
Figure 4. Top 10 variables in importance ranking
图4. 重要性排名前十的变量
选取得分大于等于10的变量,一共可以分为四类,分别从所有用户个人画像、所有用户使用画像、是否为购买型用户的重要因素以及产品画像进行分析,得出下述结论。
第一类为所有用户的个人画像,如:行业、每月可支配收入、教育程度、职业、所在位置,这五个特征对于用户是否愿意推荐有一定的影响,可以对用户进行基本判断,粗略对用户的推荐能力进行判断。
第二类为所有用户的使用画像:使用这些平台的普遍方式、对于在线知识付费的了解程度。通过平台的使用方式区分用户为免费使用、还是长期使用等。用户的使用方式不同,对于推荐意愿也会起一定作用。而对于在线知识付费的了解程度更能体现用户的感兴趣度,越了解表示用户对于在线知识付费越感兴趣,也就越会向他人推荐。
第三类针对是否为购买型用户分别进行分析。尚未有在线知识付费经历的原因针对免费使用在线知识付费平台的用户。这样的用户虽然不购买,但是却有着推荐的效果,扩大购买群体,因此到底是何种原因导致用户未购买,平台可以“因材施教”。而购买在线知识付费的最主要影响因素针对购买在线知识付费平台的用户。通过分析可知,他人推荐购买会影响用户的购买行为,而购买的用户又会影响推荐意愿,二者是相互影响不断促进。
第四类为产品画像,产品如何激发用户的购买意愿也就是产品的特色也是用户是否愿意推荐的关键因素。用户的购买意愿,往往是该产品的吸引点,也就是未来用户的推荐点,因此根据不同的购买意愿,可以判断用户的推荐意愿。
针对上述分析结果,提出如下建议:
第一,优化用户个人服务特点。对于所有用户都能够进行初步的用户画像,精准定位不同客户的行业、每月可支配收入、教育程度、职业、所在位置,对于某些行业或者收入的用户应该增强推荐奖励,从而促使用户主动推荐在线知识付费平台。
第二,提升产品质量稳定价格体系。通过分析可知:用户的购买意愿是会影响用户的推荐意愿。用户较多关注是否为原创、平台是否可靠以及价格较低这几个因素,因此平台应该选择建立知识在线平台及产品的合理标准定价,削弱用户的免费使用想法,减少用户因同品类产品价格相差较大,而选择更便宜产品的。
第三,建设平台了解信任体系。分析结果表明,了解程度与推荐意愿的关系得到实证支持,所以必须全面、加快建立在线知识付费平台的了解体系。增强人们对于在线知识付费的了解程度,让更多的的人更深刻的认识知识付费,增强信任度,就是增强推荐意愿。
4. 结论
本文利用问卷调查获取数据,基于XGBoost机器学习算法,研究在线知识付费平台推荐意愿的影响因素。相比仅付费,推荐意愿强的用户,不仅会进行付费,而且通过用户的推荐会带来更有价值的用户,往往给平台带来更大的收益。通过搜集的问卷数据建立模型,科学地为平台运营商确定用户在线知识付费推荐意愿影响因素,定位满足用户需求,采取更为完善的运营措施以提升用户在线知识付费率以及推荐率,实现在线知识付费平台长久发展,为后续学者有关在线知识付费研究提供实证支持。
本文主要针对问卷发布范围内的人群进行调查与数据搜集,虽然具有一定的代表性,但样本范围也有局限性。未来可以通过网络爬虫等手段收集相对较多的数据进行建模,从而提升模型在多场景中的普适性。
致谢
文末置笔,忽觉岁短。
求学的三年时光中,一个怀揣理想的追梦少女,一路跌跌撞撞走到现在。有过迷茫,有过颓废,更多的是那些数不清的欣欣向荣的美好。的确美好的东西总是稍瞬即逝的,比如烟花、比如青春、比如这三年。纵有万般不舍,但必将抖抖灰尘迈向全新的征程。人生没有完美的选择,唯一确定的就是不确定的人生。
十分感谢求学路上为我亮起的一盏灯,在我丧气的时候。总是仗义的过来按我门铃。