1. 引言
脑卒中是最常见的脑血管疾病,具有较高的发病率和死亡率,仍然是全世界第二大死因 [1] [2] 。大多数脑卒中病例是缺血性脑卒中 [3] ,因此,对于减少中风事件发生问题,精确监测和评估颈动脉斑块在临床上具有重要意义。目前,有多种医学成像方式可用于可视化颈动脉斑块,包括X射线、计算机断层扫描(Computed Tomography, CT)、磁共振成像(Magnetic Resonance Imaging, MRI)和常规超声(Ultrasound, US)。在这些成像技术中,常规超声具有无创、便捷、无辐射和价格实惠等特点 [4] ,因此被广泛用于颈动脉斑块诊断。超声造影技术(Contrast-enhanced ultrasound, CEUS)是在常规超声的基础上发展的一种新型的非侵入性影像学检查方法,可显著提高对病变组织的检测精准度 [5] 。在颈动脉斑块治疗过程中,医生需要通过CEUS图像来确定斑块的形态和大小 [6] 。然而,这一过程需要医生手动标注病变区域,人工标注费时费力且标注准确性存在主观性。因此,基于CEUS图像自动分割斑块已成为目前医学人工智能的重点研究内容,主要包括传统方法和深度学习方法。
通常来说,基于传统方法的颈动脉斑块分割涉及多个组件的组合,包括图像预处理、感兴趣区域(Region of Interest, RoI)特征提取和斑块分割。大多数传统分割算法的重点在于从图像中提取更具代表性的特征。一些方法仅关注颈动脉血管边界的分割。Sumathi等 [7] 尝试使用基于边缘映射的水平集分割方法分割远端血管壁的内中膜厚度(IMT)。Nagaraj等 [8] 提出一种基于支持向量机(Support Vector Machine)的感兴趣区域提取和内中膜分割算法。许多其他方法明确地检测超声图像中的斑块。Destrempes等 [9] 利用运动场估计并将其整合到贝叶斯模型(Bayesian model)来分割超声图像中的斑块。Mehdi等 [10] 提出了一种改进的空间模糊C均值和集合聚类方法,用以识别颈动脉超声图像中的斑块。Loizou等 [11] 提出了一种基于斑点减少滤波和参数化活动轮廓的方法用于分割颈动脉粥样硬化斑块。许多研究者利用传统算法研究了基于CEUS图像的颈动脉斑块分割问题。例如Hoogi等 [12] 利用主动轮廓法分割管腔,并拟合抛物线来估计动脉壁,使斑块分割在单个帧中。Zeynettin等 [13] 提出了一种新的分割算法尝试在常规超声和超声造影图像上同时分割颈动脉斑块。尽管这些方法在颈动脉斑块分割领域已经取得了实质性进展,但传统算法仍然存在不可忽视的局限性。由于超声图像质量低,基于超声图像的几何、灰度和纹理特征的方法鲁棒性较差。此外,手动选择的特征通常带有主观性。因此,传统的颈动脉斑块分割算法分割性能一般,分割结果不够准确,而且缺乏足够的鲁棒性。
近年来,深度学习的全面进步推动了医学领域的众多发展。许多基于深度学习的方法致力于颈动脉超声图像斑块分割。由于斑块通常生长在颈动脉血管壁(Carotid Artery Wall, CAW)中,因此也有一些关于颈动脉血管壁分割的研究,这种类型的分割通常用于评估颈动脉内膜–中膜厚度(Intima-Media Thickness, IMT)。Carl等 [14] 提出了一种新的深度神经网络用于自动描绘中外膜边界(Media-Adventitia Boundary, MAB)和管腔内膜边界(Lumen-Intima Boundary, LIB)。Zhou等 [15] 提出了一种基于动态卷积神经网络和改进的U-Net的深度学习分割框架,用于从颈动脉三维超声图像中分割MAB和LIB。然而,这些方法只负责分割颈动脉血管壁,不进一步分割斑块。因此,许多方法明确地分割颈动脉超声图像中的斑块。Mi等 [16] 通过设计一个具有三分支的多支特征融合模块的分割算法以实现更好的斑块分割。Xie等 [3] 通过集成两级和双解码器卷积U-Net,用于超声图像中颈动脉血管腔和斑块的分割。Meshram等 [17] 提出了一种扩展的U-Net架构来分割颈动脉斑块。Pankaj等 [18] 将注意力机制与U-Net架构结合,用于识别颈内动脉(Internal Carotid Artery, ICA)和颈总动脉(Common Carotid Artery, CCA)图像中的颈动脉斑块。尽管这些基于深度学习的方法减轻了一些手工方法的限制,但现有的颈动脉斑块分割方法仍然面临一些挑战:1) 由于卷积运算中感受野的限制通常会阻碍捕获全局上下文和构建远程依赖关系,影响了分割精度的进一步提高。2) 由于超声造影图像的噪声干扰和低质量,病变区域的边界通常模糊不清,这经常导致边界分割效果不理想。3) 很多分割方法将来自编码器和解码器的特征通过简单的跳跃连接直接结合,忽略了有价值的中间特征,导致低效率的融合。因此,如何更有效地利用颈动脉CEUS图像以更准确地分割颈动脉斑块仍然是一个挑战。
在过去的十年中,卷积神经网络(Convolutional Neural Networks, CNN),特别是全卷积网络(Fully Convolutional Networks, FCN) [19] 和U-Net [20] 及其变体在医学图像分割方面表现出色,已被广泛应用于各种医学图像分割任务。U-Net的提出掀起了医学图像分割的热潮,它采用了编码器–解码器结构,通过跳跃连接将编码阶段和解码阶段的特征进行拼接,用于生物医学图像分割。UNet++ [21] 设计了一系列嵌套的、密集的跳跃连接,旨在减少编码器和解码器之间的语义鸿沟。Attention U-Net [22] 提出了一种注意力门(Attention Gate, AG)机制,使模型能够关注不同形状和大小的目标,在突出显著特征的同时抑制不相关的特征。MultiResUNet [23] 使用多尺度卷积思想对U-Net中的卷积模块进行改进,在多个医学图像数据集上都提升了分割性能。DoubleU-Net [24] 通过堆叠两个U-Net架构并且采用空洞空间金字塔池化(Atrous Spatial Pyramid Pooling, ASPP),成为医学图像分割领域的强大基准模型。
作为Transformer在计算机视觉领域的首次杰出尝试,ViT [25] 通过充分利用预训练的模型,在图像分类方面取得了显著成功。此外,为了获得多尺度特征表示,通过从不同尺度提取信息来提高精度和效率。Swin Transformer [26] 使用一种有效的基于移位窗口的方法在局部计算自注意力,在图像识别和密集预测任务(如目标检测和语义分割)中达到了最先进的性能。受到Transformer在CV取得显著成功的启发,它在医学图像分割领域获得了极大的关注。TransUNet [27] 首次尝试将Transformer和U-Net相结合,利用Transformer获取全局上下文信息,结合U-Net结构恢复局部信息。TransFuse [28] 通过并行的方式将Transformer和CNN结合在一起,在不丢失浅层特征的前提下提高全局上下文建模效率。Swin-Unet [29] 提出了一种基于Swin Transformer的U形架构的纯Transformer模型,用于多器官和心脏分割。DS-TransUNet [30] 采用基于Swin Transformer的双分支编码器来捕获不同粒度的语义信息,用于学习多尺度特征表示,在多种医学图像分割任务中表现出色。
为解决劲动脉超声造影图像斑块分割领域中分割精度和性能方面的限制,本文提出了一种新颖的医学图像分割框架:DATU-Net,旨在提高颈动脉CEUS图像中斑块准确分割效果。DATU-Net集成了Swin Transformer、双注意力机制和U形架构的优势。编码器分支采用Swin Transformer模块进行构建,主要用于捕获远程依赖关系和建模全局上下文信息。同时,通过设计基于CNN的辅助分支,充分利用卷积操作的局部特性以增强对细节信息的分割能力。在该框架中,我们还开发了双级注意力(Double-Level Attention, DLA)模块,具有提取图像特定的位置特征和通道特征的能力,旨在优化编码器获得的多尺度特征。此外,在解码器部分引入了Swin Transformer 模块,以增强网络的解码能力。为了评估本文提出的DATU-Net的有效性,我们在超声造影颈动脉斑块数据集上进行了广泛的仿真实验,实验结果充分证明了所提方法的卓越性能,为颈动脉超声造影图像的精准斑块分割提供了一种有效且可靠的解决方案。
2. 方法
2.1. 网络概述
本文提出的DATU-Net架构如图1所示。给定输入图像的尺寸为
,其中
表示输入图像的空间分辨率。DATU-Net采用典型的编码器–解码器架构,该框架基于Swin Transformer模块构造编码器分支,用于捕获全局上下文信息并构建分层特征表示;同时基于CNN在视觉任务中所具有的先验知识设计辅助分支对输入图像进行下采样,以有效提取斑块的低级细节特征。DATU-Net将双级注意力(DLA)模块集成到每层的跳跃连接中,以优化编码器传递的特征,过滤不相关信息,从而更准确地向解码器传递特征并改善图像分割性能。在该模块中,通道注意力模块(Channel Attention Module, CAM) [31] 和位置注意力模块(Position Attention Module, PAM) [31] 被用于有效提取和利用图像特定的位置特征和通道特征。此外,我们将Swin Transformer模块引入到解码器中,以进一步探索上采样过程中的远程上下文信息。最后,DATU-Net可以准确地获得大小为
的像素级分割图。
2.2. Swin Transformer作为编码器
我们将Swin Transformer模块和图像块合并层(Patch Merging)堆叠在一起,构成DATU-Net的特征编码路径。该路径主要由包含四个阶段的Swin Transformer构成,每个阶段包含一定数量的Swin Transformer
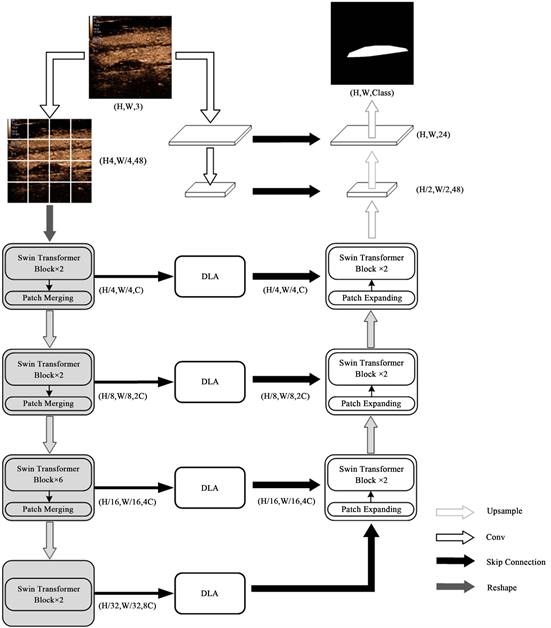
Figure 1. The overall architecture of the proposed DATU-Net
图1. 提出的DATU-Net的整体架构
模块。不同于传统的标准MSA模块,为了高效建模,Swin Transformer模块基于移位窗口的思想构造了更合理的多头自注意力机制。图2显示了两个连续的Swin Transformer 模块,每个模块由LN (Layer Normalization)层、多头自注意力模块、残差连接和具有GELU非线性激活函数的双层MLP (Multi-layer Perceptron)组成。基于窗口的多头自注意力(Window-based Multi-head Self Attention, W-MSA)模块和基于移位窗口的多头自注意力(Shifted Window-based Multi-head Self Attention, SW-MSA)分别应用于两个连续的Swin Transformer模块中。
基于这种窗口划分方法,连续Swin Transformer模块可被定义如下:
(1)
(2)
(3)
(4)
其中,
和
分别表示两个MSA模块和MLP模块的输出;W-MSA和SW-MSA中自注意力的计算方法可写为如下形式:
(5)
其中Q,K,
是query、key和value矩阵。d表示query或key的维数,
表示窗口中的图像块数量,
表示相对位置偏置。

Figure 2. Swin Transformer block
图2. Swin Transformer模块
在医学图像被送入到Swin Transformer模块之前,它被图像块划分模块(Patch Partition)按照4 × 4大小进行分割成一系列不重叠的块。每个图像块都被视为一个“token”,并将通过线性嵌入层(Linear Embedding)将通道数调整到C维(C = 96)。随后,这些图像块序列被输入到包含四个阶段的Swin Transformer中执行特征表示学习,其中特征维数和分辨率保持不变。为了获得多尺度特征同时产生层级式表示,随着网络的深入,通过块合并(Patch Merging)层来减少图像块的数量。具体而言,块合并层将输入的图像分为4部分并将它们沿通道维度拼接(Concatenate),然后在拼接的特征上应用线性层。这将使图像块数量减少2倍,执行2倍的分辨率下采样,并将输出特征维数增加2倍。因此,四个阶段的输出特征图分辨率分别为
、
、
和
,通道数分别为C、2C、4C和8C。
2.3. 双级注意力(Dual-Level Attention)模块
如图3所示,本文提出的双级注意力(DLA)模块作为DATU-Net的关键组件,有效提取和利用了图像特定的位置特征和通道特征,能够分别在空间维度和通道维度上实现特征增强,从而获得更详细和准确的特征集合。DLA模块同时能够优化跳跃连接中来自编码器的传输特征,过滤掉跳跃连接中的无关信息,方便解码器重建更精确的特征表示。因此,我们将其集成到跳跃连接中以提高模型的分割性能。DLA由两个主要组件组成:一个具有位置注意力模块(Position Attention Module, PAM),另一个包含通道注意力模块(Channel Attention Module, CAM),两者都借鉴了DANet [31] 。
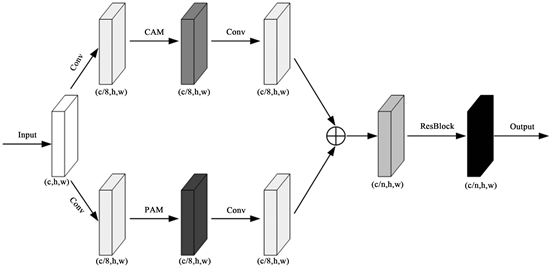
Figure 3. Dual-Level Attention module structure
图3. 双级注意力模块结构
2.3.1. 位置注意力模块PAM
如图4所示,PAM捕获特征映射的任意两个位置之间的空间依赖关系,通过所有位置特征的加权和更新特定特征。权重由两个位置之间的特征相似度确定。因此,PAM在提取有意义的空间特征方面是有效的。位置注意力模块将更广泛的上下文信息编码为局部特征,从而增强了它们的表示能力。
给定PAM的初始输入特征图记为
,然后A将输入到卷积层中,得到三个新的特征图,即B、C和D,每个特征图的尺寸为
,接下来将B和C重塑为
,其中
表示像素数量。之后,在B和C的转置之间执行矩阵乘法,并应用softmax层获得空间注意力图
:
(6)
其中,
表示第i个位置对第j个位置的影响。同时将D重塑为
,然后与S的转置执行矩阵乘法,并将结果重塑为
。最后,我们将其乘以参数
,并于特征图A进行元素求和运算,从而得到最终的输出
:
(7)
其中
初始化为0,并逐渐学习获得更多的权重。由于E是所有位置特征和原始特征的加权和,所以它具有全局上下文特征,同时能够根据空间注意力图选择性地聚合上下文。因此,PAM具有很强的空间特征提取能力,可以有效地提取位置特征,同时保持全局上下文信息。
2.3.2. 通道注意力模块PAM
通道注意力模块CAM结构如图5所示,它擅长提取通道特征。与PAM不同的是,我们直接将原始特征图
重塑为
,然后将A与其转置进行矩阵乘法。随后,我们应用一个softmax层,得到通道注意力图
:
(8)

Figure 4. Position attention module structure
图4. 位置注意力模块结构
这里,
衡量第i个通道对第j个通道的影响。接下来,对A和X的转置执行矩阵乘法,并将其将结果重塑为
。最后,将结果乘以参数
,并于A进行逐元素求和运算,得到最终的输出
:
(9)
其中
从0开始学习权重。与PAM类似,在CAM中提取通道特征时,每个通道的最终输出特征都是由所有通道特征和原始特征的加权和生成的,从而赋予了CAM模块强大的通道特征提取能力。
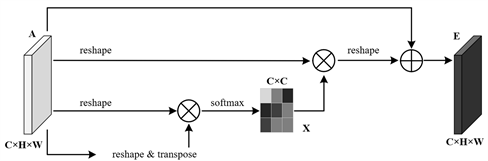
Figure 5. Channel attention module structure
图5. 通道注意力模块结构
2.3.3. 双级注意力模块DLA
如图3所示,我们给出了双级注意力模块DLA的架构示意图。该模块将位置注意力模块(PAM)的强大位置特征提取功能与通道注意力模块(CAM)的通道特征提取优势相结合。DLA由两部分组成,第一部分以PAM为主,第二部分以CAM为主。第一部分获取输入特征图,并执行一次卷积,将通道数量缩小为原来的1/8,得到
。然后经过PAM执行位置特征提取,再进行卷积操作,得到
。具体的计算公式如下所示:
(10)
(11)
另一部分的组件是相同的,唯一的区别是PAM模块被替换为CAM模块,其计算公式如下所示:
(12)
(13)
经过两层注意力模块之后得到输出特征图
和
,接着进行元素求和,并送入残差模块(ResBlock) [32] 传递融合特征,同时恢复通道数,从而得到最终的输出结果。具体计算过程如下所示:
(14)
这种设计新颖的DLA模块很好的集成了PAM和CAM的优势,以有效增强特征提取,使其成为提高模型整体性能的关键组件。
2.4. 解码器
如图1所示,我们基于Swin Transformer模块构建了DATU-Net的解码器,用于探索上采样过程中的远程依赖关系。受到Swin-Unet [29] 的解码器设计的启发,我们在解码器中使用了图像块扩展层(Patch Expanding)对提取的深度特征图进行上采样。解码器主要由三个阶段组成,每个阶段都包括块扩展层和Swin Transformer模块。解码器每一个阶段都会将特征图的分辨率提高2倍,并相应地将特征维数降低2倍。因此,这三个阶段的输出特征图分辨率分别为
、
和
,通道数分别为4C、2C和C。同时,也构造了两个常规的解码器模块用于获得分割预测图,每个模块由卷积层、BN层和ReLU激活函数相继组成。经过这两个常规解码器单元执行上采样操作,然后所有的输出特征将被用于获得
的最终分割预测图,其中
表示类别数量。
2.5. 损失函数
为了获得高质量的区域分割和清晰的边界,根据实验我们选择将损失函数定义为混合损失,BCE损失 [33] 是二元分类和分割中使用最广泛的损失函数。IoU最初是为衡量两个集合的相似性而提出的,随后被用作目标检测和分割的标准评估指标。最近,IoU损失 [34] 被广泛用作训练损失函数。我们使用的损失函数的计算公式如下:
(15)
(16)
(17)
其中
表示像素点
的真值标签,
表示显著目标的预测概率。
3. 实验
3.1. 数据集
在本文的实验中,我们收集了146名颈动脉斑块患者的CEUS检测视频,这些视频由上海交通大学医学院附属同仁医院超声科提供,并通过了机构审查委员会的批准。在具有10年以上临床经验的临床医生的指导下,对病变区域的像素级标签进行标注,并由多名临床医生进行验证。最终得到的数据集共包含1200张CEUS图像,并按照8:1:1的比例进行划分训练集、验证集和测试集。
3.2. 数据预处理
在实验中,为了增加训练样本的多样性,我们通过数据增强对原始图像进行多种变换。这一举措不仅有助于提高网络的鲁棒性,降低过拟合的风险,还能有效提高图像分割任务的准确性。在CEUS图像尺寸方面,我们进行了裁剪和缩放操作,使其统一为512*512。同时,我们进行了归一化处理,确保数据在训练过程中保持一致性,提高训练效率。为了更全面地覆盖各种情景,我们还采用了常见的数据增强方法,如图像旋转、图像翻转以及亮度调节等。这些策略的有机结合旨在有效实现数据增强的目标,为模型的仿真训练提供更为丰富的输入信息。
3.3. 实验设置
本文提出的DATU-Net的编码器部分采用了Swin-Tiny [26] 作为主干网络,并通过在ImageNet数据集上预训练的权重进行参数初始化。在训练过程中,我们设置了300个epoch的训练轮次,批处理大小为8,初始学习率为0.01。为了优化模型的性能,我们选择了Adam优化器,其中动量设置为0.9,权重衰减为0.0001。DATU-Net的实现基于PyTorch框架,并且所有实验都是在NVIDIA RTX 3090 GPU上进行的,以确保计算效率和模型训练的顺利进行。图6展示了DATU-Net训练300个epoch的仿真曲线,其中x轴表示模型训练的轮次,y轴表示模型训练的轮次对应的损失值。我们可以观察到训练损失曲线稳步下降,直至趋于平稳,表示模型的训练效果良好,能够正确地捕捉到训练数据中的规律。
3.4. 评价指标
在本文中,我们旨在利用多种评价指标来评估所提出方法的性能,包括Dice系数(Dice coefficient score, Dice)、交并比(Intersection over Union, IoU)、精确度(Precision)和召回率(Recall)。这些指标的取值范围在0到1之间,取值越高表示算法的分割性能越好。Dice系数评估的是预测像素和真实像素之间的整体相似度。IoU指标通过计算真实像素与预测像素的交集和并集的比值来衡量分割的准确性。精确度反映了预测样本与真实样本的匹配程度。召回率用于衡量正确识别预测样本的比率。上述指标的公式可定义如下:
(18)
(19)
(20)
(21)
式中,TP (True Positive)表示斑块区域像素的正确分类数;TN (True Negative)表示非斑块区域像素的正确分类数;FP (False Positive)表示斑块区域像素的错误分类数;FN (False Negative)表示非斑块区域像素的错误分类数。
3.5. 对比实验
在本节中,我们针对CEUS图像颈动脉斑块分割任务,将提出的DATU-Net与多种先进的分割方法(包括U-Net [20] 、UNet++ [21] 、Attention U-Net [22] 、MultiResUNet [23] 、PSPNet [35] 、DeepLabV3+ [36] 、DenseASPP [37] 、TransUNet [12] 、Swin-Unet [13] )进行了全面比较。定量分析结果如表1所示,其中每列中的最佳结果以粗体标出。我们可以发现DATU-Net在所有评价指标上都始终优于其他分割模型,具体而言,Dice和IoU分别达到了85.48%和 76.32%的最佳水平,显著优于U-Net。与U-Net的各种变体相比,如UNet++和MultiResUNet,DATU-Net在U形框架的基础上结合了Swin Transformer模块,增强了传统编码器–解码器架构的功能性和灵活性。我们观察到Attention U-Net通过引入跳跃连接中的注意力门机制相较于U-Net有效提升了各项性能指标。相比之下,本文提出的DLA模块减少编码器和解码器之间的语义鸿沟方面更为有效,可以有效过滤掉跳跃连接中的无关信息,增强了模型的鲁棒性。PSPNet、DeepLabV3+和DenseASPP通过ASPP模块获取更大的感受野,涵盖更广泛的上下文信息,进而提高了分割指标,其中DeepLabV3+和DenseASPP分别取得了79.08%和80.14%的Dice系数。相比之下,DATU-Net通过在编码器和解码器中引入Swin Transformer模块,有效地建模全局上下文信息和远程依赖关系,同时生成多尺度特征表示,提高了医学图像语义分割质量。基于Transformer的模型,如TransUNet和Swin-Unet,性能指标明显优于上述模型。其中,Swin-Unet在Swin Transformer模块的指导下取得了第二好的分割成绩,突显了Swin Transformer相较于标准Transformer的更强大性能。相较于TransUNet和Swin-Unet,DATU-Net不仅利用Swin Transformer模块构造编码器和解码器以有效获取全局依赖和多尺度上下文,还通过将DLA模块集成到跳跃连接中,在减少冗余特征的同时提取更有价值的信息,显著提高了整体性能。此外,DATU-Net中的辅助分支保持了一定的空间细节,有助于获得更准确的斑块分割边界。值得注意的是,DATU-Net在各项指标上均明显优于排名第二的Swin-Unet,Dice和IoU分别提高了1.4%和2.1%,并且获得了最高的精确度和召回率,分别为87.46%和88.63%,显著优于其他竞争对手。

Table 1. Quantitative analysis results of different methods
表1. 不同方法的定量分析结果
图6显示了本文提出的DATU-Net与其他分割模型的定性可视化仿真结果比较。如图7所示,我们的模型在分割CEUS图像颈动脉斑块任务中表现出色。可以看到,我们的方法始终能够产生最佳的分割结果,这表明DATU-Net在整体分割结果和斑块边缘预测方面具有更好的分割能力。总体而言,这些比较结果充分验证了我们提出的DATU-Net的有效性和优越性,并且突显了该方法在CEUS图像颈动脉斑块自动分割方面的显著优势。

Figure 7. Visualization of plaque segmentation results for different methods
图7. 不同方法的斑块分割结果可视化
3.6. 消融实验
Table 2. Ablation experimental results
表2. 消融实验结果
为了评估DATU-Net中每个组件对分割性能的影响,我们针对CEUS图像颈动脉斑块分割任务进行了消融研究,实验结果如表2所示,其中每列中的最佳结果以粗体标出。我们将标准的U-Net视为基准模型,并基于U形结构进行后续实验。具体来说,“U/SE”表示基于Swin Transformer编码器的U形模型,“U/SD”表示基于Swin Transformer解码器的U形模型,“U/SE + SD”表示同时基于Swin Transformer编码器和解码器的U形模型,“U/SE + SD + CAB”表示在“U/SE + SD”的基础上增加了基于CNN的辅助分支,“U/SE + SD + CAB”是完整的DATU-Net架构。可以看出,在“U/SE”中用基于Swin Transformer的编码器替换传统的基于CNN的编码器后,Dice和IoU分别显著提高了6.71%和7.04%。此外,与“U/SE”相比,在“U/SE + SD”中引入基于Swin Transformer的解码器后,Dice和IoU分别提高了3.22%和2.15%。通过引入基于CNN的辅助分支,“U/SE + SD + CAB”分别将Dice和IoU提高了1.94%和1.08%,这一改进表明,该辅助分支可以有效地增强局部细节,从而提高分割性能。可以看到,“U/SE + SD + CAB + DLA”进一步将Dice和IoU分别从83.36%提高到85.48%和74.62%提高到76.32%。如此显著的提升无疑证明了DLA模块的巨大贡献,在每个跳转连接层添加DLA模块可以有效增强特征提取,为解码器提供更精细的特征,从而减少上采样过程中的特征损失。基于上述消融实验结果,我们认为本文提出方法的所有设计组件都是必要的,因此,完整的DATU-Net架构可以实现最卓越的分割性能。
4. 结论
在本文中,我们提出了一种新的医学图像分割方法,即DATU-Net,该方法融合了Swin Transformer模块、双注意力机制和U形结构,旨在提高CEUS图像颈动脉斑块的分割准确性。我们充分利用Swin Transformer模块构建编码器分支,以对全局上下文信息和远程依赖关系进行建模,同时得到多尺度特征表示。基于CNN的辅助分支专注于提取细粒度的局部特征,确保获得准确的斑块分割边界。在解码器中引入了Swin Transformer模块,以全面建模整个网络的全局上下文信息。我们还提出了一个设计新颖的DLA模块,并将其集成到跳跃连接中,有效弥合编码器和解码器之间的语义鸿沟,同时优化输出特征,从而增强了图像分割性能。实验仿真结果表明,DATU-Net实现了更准确的颈动脉斑块分割,显著提升了分割性能。总体而言,本文提供了一种有效的颈动脉超声造影图像斑块分割方法,有望推动该领域的进展,为临床医生提供更快速的颈动脉斑块识别和相应诊疗支持。
基金项目
上海理工大学医工交叉项目(10-21-302-413)。
NOTES
*通讯作者。