1. 引言
(一) 研究背景
1、不断做强做优做大我国数字经济
党的十八大以来,党中央高度重视发展数字经济,将其上升为国家战略。十九届五中全会提出,要发展数字经济,推进数字产业化与产业数字化,推动数字经济和实体经济深度融合,打造具有国际竞争力的数字产业集群。2021年,习近平总书记在致世界互联网大会乌镇峰会的贺信中指出:要激发数字经济活力,增强数字政府效能,优化数字社会环境,构建数字合作格局,筑牢数字安全屏障,让数字文明造福各国人民。
2、各省系列前沿政策举措促发展
为促进数字经济的发展,各省份也陆续发布系列前沿政策。2022年3月22日,湖北省首次发布《湖北省数字经济发展白皮书》,通过采集全省及各市州2018~2020年数字经济相关数据,梳理全省数字经济发展形势、总体情况,有针对性地提出了政策建议。4月26日,江西省推出18条举措,对全省数字经济领域市场主体实行2年发展“包容期”管理,积极营造数字经济发展一流生态,大力推进数字经济做优做强。
(二) 研究目的与意义
1、经济发展在不同程度上受到新冠肺炎疫情的影响,后疫情时代下复苏经济迫在眉睫,而数字经济的发展已是推动经济复苏的核心。
2、基于2013~2020年全国31个省份的数据,构建科学的指标体系,测算各省份数字经济发展情况,从时空维度展开综合评价。
3、本文创新地使用主成分分析、聚类和熵权法等模型,定性定量对各省份的数字经济评估,针对建模结果提出可行性建议。
本文研究框架,如图1所示。
2. 文献综述
(一) 基于研究发文量和主题分布的分析
如图2所示,首先通过中国知网检索“数字经济”得到2011~2022年(截止到2022年5月24日)国内相关研究的发文数量,可以看出这一时期内发文数量明显突变时间为2016年。在2011~2015年,每年发文量保持在100篇以内,之后发文量呈现直线增长趋势,2020年发文量达到4787篇,2021年创造年度最高8500篇,而2022年仅前5个月就达到了4023篇之多。由此可见,近年来数字经济已成为我国学术界关注的一大热点,表明了国内学者对数字经济的重视和数字经济发展的重要性。

Figure 2. The number of publications on domestic digital economy research from 2011 to 2020
图2. 2011~2020年国内数字经济研究发文量
其次,从“数字经济”相关的文章的关键词频数出发,分析研究的主题分布,统计出发文数量排名前10的主题如图3所示。明显看出“数字经济”主题对应发文量遥遥领先,超过了其余9个主题的发文量,达到5630篇;而数字化转型、高质量发展等主题依次递减;而由于部分高新技术和新领域,如工业互联网、区块链和数字中国等是近几年才出现在大众的视野中,因此这些主题相关的文献发文量相对偏少,但不可否认的是各类技术和新领域的诞生对数字经济的高质量发展大有裨益。
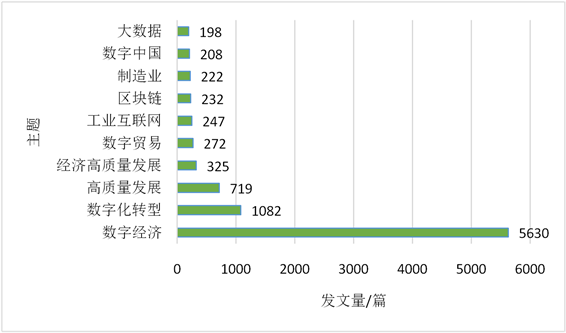
Figure 3. Distribution of research themes on domestic digital economy
图3. 国内数字经济研究主题分布
(二) 理论方法文献综述
20世纪90年代,Tapscott (1996)首次提出数字经济,他表示数字经济刻画的是一个充分利用ICT技术的经济体系,包括电子商务和基础设施等 [1] 。洪兴建(2019)考虑到学术界和政府部门的出发角度存在差异,因此分别从统计核算、全流程、驱动力和显著特征等出发,界定了数字经济的内涵 [2] 。当前,根据国内外政府部门和学术界的研究,数字经济的测度大致分为直接法和对比法两类,前者是在界定范围内度量一定区域的数字经济规模,后者是构建综合评价体系评价不同区域的数字经济发展情况,具体如表1所示。

Table 1. Classification of measurement methods for digital economy
表1. 数字经济测度方法分类
陈梦根等(2020)指出,数字产业化部分的增加值为国民经济核算体系中的不同行业信息产业增加值总和,可借助KLEMS模型测算 [3] 。李英杰等(2020)综合数字经济的外延与内涵,分别从数字产业化和产业数字化构建数字经济发展量化体系,根据熵值法测度了中国2010~2018年数字经济发展形势,另外用灰度预测模型预测2019~2028年的数字经济进展 [4] 。许宪春等(2020)在梳理数字经济发展后构建了核算体系,确定数字经济产品,筛选出数字经济产业,对2007~2017年中国数字经济的各项指标进行测算 [5] 。金星晔等(2020)以关键要素的生产应用为基础,重新定义数字经济,重点界定产业核算范围,对数字经济产业活动分类,讨论了不同产业的核算方法 [6] 。
韩兆安等(2021)通过Kernel密度估计和Dagum基尼系数评估法,测算中国各省数字经济规模 [7] 。陈亮等(2021)参考国内外对数字经济分类的经验,制定出符合中国国情的数字经济分类框架,对2012年和2017年的规模进行测算 [8] 。李洁等(2021)为针对我国数字经济规模进行科学测算,同时注重方法和框架具有国际适用性,运用投入产出模型针对中国2012年、2017年和2018年的数字经济规模测算 [9] 。陈梦根等(2022)利用投入产出序列表数据,结合数字经济内涵和增长核算方法,创立数字经济规模和全要素生产率测算体系,考察中国数字经济的结构特征 [10] 。
3. 数据与预处理
(一) 数据来源与变量说明
查阅大量文献后,参考各界对数字经济发展指标体系的构建流程,本文基于指标的科学性、系统性和可比性,选取了4个维度、共19个二级指标构建数字经济发展指标体系 [11] ,见表2。由于覆盖31个
Table 2. Construction table of indicator system for digital economy development
表2. 数字经济发展指标体系构建表
省份2013~2020年的面板数据,可全面反映各省份数字经济的发展。其中X1~X7查自国家统计局和《中国统计年鉴》,X11~X16、X17~X19来自《中国第三产业统计年鉴》和《中国信息产业年鉴》、X7~X10来源于北京大学数字普惠金融指数。
(二) 数据预处理
1、缺失值处理
本文“信息服务业产值”和“信息服务业产值”指标存在少量缺失值,基于回归插值法,根据同一省份的现有数据,对缺失值进行估算。具体思路为构建自变量
与目标变量Y的关系,则第k个缺失值的插补估算值可由公式(1)计算 [12] ,其中
指随机因素。
公式(1)
2、异常值处理
异常数据可能来自数据本身、存储或转换过程,可删除记录或视为缺失值。设各指标在各年取值为
,算出各指标平均值
及取值的误差
和指标标准差
。
若某测量值
的剩余误差
满足
,则认为
应予修正。本文指标“数字金融覆盖广度”和“网上移动支付水平”存在异常值,采取该准则对数据进行处理。
3、数据标准化
不同指标有不同的单位,会影响分析结果。本文为消除不同量纲的影响,采取归一化方式对数据标准化,使得原始数据结果映射到0~1之间,即公式(2):
公式(2)
其中,
为多指标面板数据,
表示第i个样本在t时刻的第j个指标的原始观测值。
为标准化结果,
和
分别为指标的最大值和最小值。
4. 基于时空主成分分析和聚类的评价
(一) 主成分分析
1、相关性分析
设两变量为
和
,按照公式(3)计算相关系数r,表示变量
与
间的相关性。
公式(3)
19个指标在不同时期的相关系数见表3 (详细见附录),表3仅展示变量x1与其他18个变量之间的相关性。同一变量在不同年份的相关性均较强,可通过显著性检验,对各指标间的相关系数展开分析 [13] 。
以指标光缆长度为例分析为例,其与移动电话基站数之间、互联网宽带接入端口数、规模以上工业企业R&D项目(课题)数、电信业务量之间的相关系数均为正。光缆越长,相应的依靠光缆发展的业务越强劲,光缆长说明发展电信业务具备的基本条件充分。其他指标也可作类似分析。
Table 3. Secondary indicator correlation coefficient table
表3. 二级指标相关系数表
2、基于时空的主成分分析
本文共使用基于时空的主成分分析,即两次主成分分析评价中国数字经济的发展状况。第一次是在不同年份分别进行,结合特征值大于1的原则提取主成分,通过回归获得主成分综合得分 [14] 。第二次是
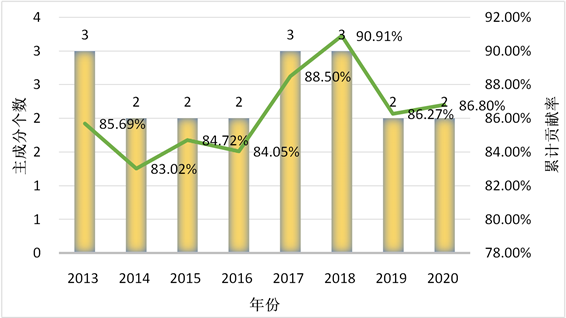
Figure 4. Principal component of the first principal component analysis
图4. 第一次主成分分析主成分
基于前面各次分析的主成分综合得分,筛选第二次分析的主成分,通过回归获得综合得分,最终运用该结果评价31个省份的数字经济发展。
在固定年份,将31个省份的19个指标作为样本观测值,计算相关系数结果显示整体呈现较强相关,适合主成分分析 [15] 。根据特征值大于1的原则,选取各次分析的主成分个数和累积贡献率见图4。运用回归方法得到各省份的综合得分进行排名的结果见表4。
Table 4. Results of the first principal component analysis
表4. 第一次主成分分析结果
广东在数字经济发展方面稳居第一;北京、江苏、浙江和上海排名较稳定,维持在2~5名;河南、湖南、江西、广西、贵州等省份从2013年到2020年进步较大;而黑龙江、辽宁、内蒙古、新疆等省份退步较大;甘肃、宁夏、西藏、青海排名时常垫底,其他省份的变化不太明显,趋于平稳。
Table 5. Skewness and kurtosis of the comprehensive score of the first principal component
表5. 第一次主成分综合得分偏度与峰度
第一次主成分综合得分的偏度与峰度结果见表5,峰度最大为1.28,说明全国数字经济的发展不受极端值的影响。偏度均大于零,说明数据分布右偏,中位数小于平均数,即全国有一半以上省份数字经济低于全国平均水平。第二次主成分分析运用第一次主成分分析的综合得分,分析前先进行相关分析,结果如图5所示。可知相关关系很强,说明8年间31个省份的数字经济发展较稳定,这得益于国内稳定的政治经济环境,可再一次进行主成分分析。

Figure 5. Heatmap of correlation coefficients for the comprehensive score of the first principal component
图5. 第一次主成分综合得分相关系数热力图
根据特征值大于1的原则,在2013~2016年、2017~2020年和2013~2020年各选取一个主成分,进行第二次主成分分析。考虑了时间间隔的影响,重新评价各省份的数字经济发展,排名结果见图6。结合2013~2020年的表现,可知在三个时段,各省份排名浮动不大,广东、北京、江苏和浙江始终排名前四;甘肃、西藏和青海排名一直位于后四位。2017~2020年较2013~2016年排名进步超过3位的有:湖南、江西、贵州和西藏,2017~2020年较2013~2016年排名下降超过3位的有:辽宁、黑龙江与宁夏。其他省份的变化比较平缓。2013~2020年整体来看,变化较大的省份为上述提到的七个省份,其他省份的变化也较为平缓。
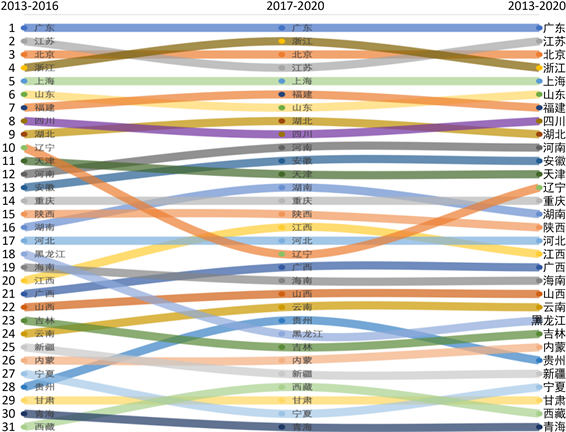
Figure 6. Results of the second principal component analysis
图6. 第二次主成分分析结果
对各时段综合得分进行偏度与峰度分析,结果见表6。按照时间来看,偏度值在下降,说明全国各地区的数字经济发展水平在不断上升且逐渐平缓,即全国各地区小于全国数字经济平均发展水平的地区数量逐渐减少,这是区域均衡发展的趋势。峰度也能说明类似结果。考察各省在不同年份排名的Spearman等级相关系数,结果见图7,发现相关性都较强,其中2018年与2013年、2014年的等级相关系数最小为0.91,表明我国经济系统比较稳定。
Table 6. Skewness and kurtosis of the comprehensive score of the second principal component
表6. 第二次主成分综合得分偏度与峰度
根据31个省份在不同阶段数字经济的综合得分,利用python绘制综合得分热力图以展示数字经济发展的整体情况。(以2013~2016年和2017~2020年地图为例,见图8、图9)由图8可知,数字经济发展存在区域差距,沿海与内陆地区的差异明显。广东省的数字经济发展最好,综合得分为2以上。数字经济发展较好地区一般集中于东南沿海地区,当地经济发展水平也相对更高;其他地区的发展水平较为接近,都属于数字经济发展较不发达地区。这反映了我国数字经济发展存在不平衡问题,在基础设施建设等方面的差距不利于数字经济的发展,造成了内陆地区发展受阻。

Figure 7. Heatmap of spearman rank correlation coefficients
图7. Spearman等级相关系数热力图
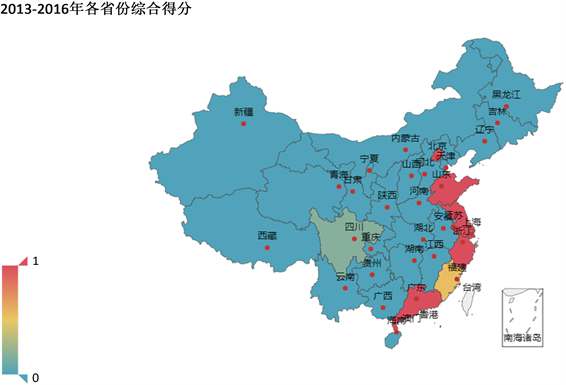
Figure 8. Heatmap of comprehensive scores for each province from 2013 to 2016
图8. 2013~2016年各省份综合得分热力图
由图9可知,与2013~2016年相比,湖北、四川等省份数字经济进步明显,综合得分在较发达地区和发达地区整体呈逐年递增趋势。区域数字经济发展差距主要表现在内陆与沿海地区的差距。从东部往西部差距逐渐递减,且数字经济发达程度的区位与我国宏观经济发展存在高度一致。要想缩小区域数字经济的差距,推动欠发达地区数字经济的发展是当务之急 [16] 。
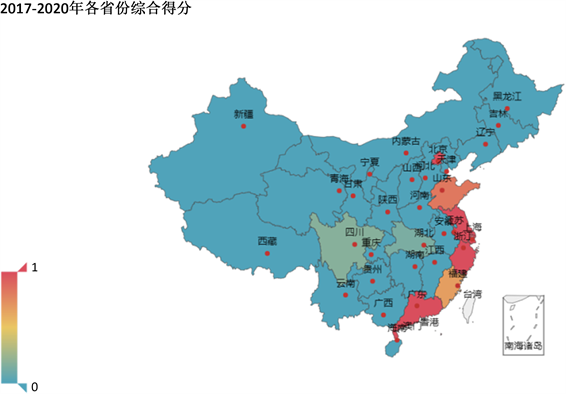
Figure 9. Heatmap of comprehensive scores for each province from 2017 to 2020
图9. 2017~2020年各省份综合得分热力图
(二) K-Means聚类
1、算法说明
K代表类别数量,Means代表每个类别内的均值,所以K-Means算法又称K均值算法 [17] 。它能根据数据样本间的相似性,将数据样本自动分为K个簇,相似样本会尽可能被聚到一个簇。如果几个样本相似,就会被聚为一类,形成一个个簇。每个簇有一个中心位置,被称作为质心。
算法目的是选择合适质心,使得在每个簇内各样本与质心之间距离尽量小,保证簇内样本相似性较

Figure 10. Within-cluster sum of squares error for k-means clustering
图10. K-means聚类簇内误差平方和
高,不同簇中数据尽量不同。要确定应该把样本分为几类合适,可以借助肘部法则,即取不同的K值,多次进行聚类,并获取每一次的簇内误差平方和(公式(4)),然后将结果进行绘制;随着K值增大,质心变多,SSE会随之降低,当下降幅度趋向于缓慢时,认为是最佳K值 [18] 。
公式(4)
其中,k为簇的数量,
为第i个簇含有的样本数量,
为第i个簇的质心,
为第i个簇中每个样本
与质心
的距离。
2、实证分析
根据2013~2016年和2017~2020年的综合得分,运用K-Means聚类对31个省份进行聚类,取不同的K值聚类得到每次簇内误差平方和,绘制结果见图10。根据肘部法则可知在K = 4时,增加K值能让聚类的效果显著提升,故可将省份数字经济分为高水平、较高水平、中等水平和低水平四类,见表7。
Table 7. Cluster results of digital economy in various provinces
表7. 各省份数字经济聚类结果
5. 基于熵权法和TOPSIS计算的测度与分析
(一) 理论基础
1、熵权法计算 [19]
1) 对原始矩阵
进行线性Max-Min标准化:
公式(5)
由于所有的指标均为正向指标,所以对数据进行标准化时采用相同的方式。
2) 计算第j项指标在第i年的数值占该指标比重
:
公式(6)
3) 计算第j项指标熵值
。当
时,
,
公式(7)
4) 计算第j项指标差异系数
:
公式(8)
5) 计算第j项指标的权重
:
公式(9)
6) 由标准化矩阵和各指标权重可得加权标准化矩阵:
公式(10)
7) 计算正负理想解:
公式(11)
公式(12)
8) 计算各指标与正负理想解间欧氏距离:
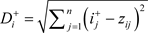 公式(13)
公式(13)
公式(14)
9) 计算综合评价值,显然
,且
越大
越小,即越接近最大值:
公式(15)
数字经济综合评价指标
在一定程度上反映了各省数字经济的发展水平,其值越接近1,表明该省份的经济发展水平越高,数字经济活力越强 [20] 。本文按照
对全国31省份进行排序,结果如图11所示。
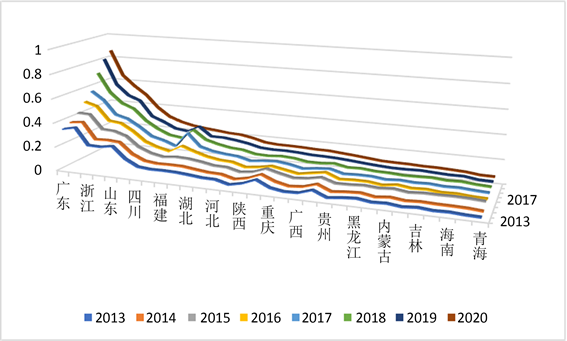
Figure 11. Ranking of comprehensive evaluation of digital economy in various provinces
图11. 各省份数字经济综合评价排序
由图11可知,全国数字经济整体水平稳步提高,但各省份经济发展存在严重的地域不平衡性。发展形势较好的地区主要是东南沿海省份如广东、江苏及浙江等;中部省份江西、山西、陕西等省份的数字经济发展指数较为平均,处于缓慢上升的趋势中,没有拉开较大的发展差距,其中福建省在2015~2017发展速度较快,但近几年增速下滑;西北省份如青海、西藏、宁夏等省的数字经济发展相较于其他省份明显处于劣势,发展速度较缓慢,其中西藏数字经济发展水平在2016年之后发展较快,反超甘肃、宁夏。
在沿海省份中,广东的数字经济水平遥遥领先,在2017后快速发展,2018年达到了的24%的增长率,增速大大超过了江苏的8.9%和浙江的14.4%,发展水平增速突出,逐渐与排在之后的江苏和浙江拉开差距。相比而言,同为沿海省份的山东、福建,天津相比江浙粤发展动力欠缺,发展速度较慢,在2020年仅分别达到了0.38507,0.237196,0.136356,相比一些内陆省份犹有不及。
本文根据数字经济评价指标将各省发展程度分为了以下三个层次,第一梯队为广东、江苏、浙江、北京、山东五省份,显著高于平均水平;第二梯队为发展水平处于中等水平的四川、河南、福建、安徽、湖北五省为代表(发展水平处在均值附近),第三梯队以明显较为落后的吉林、甘肃、海南、宁夏、青海五省为代表。
2、分维度评价

Figure 12. Distribution diagram of secondary indicators for high-level echelon
图12. 高水平梯队二级指标分布图
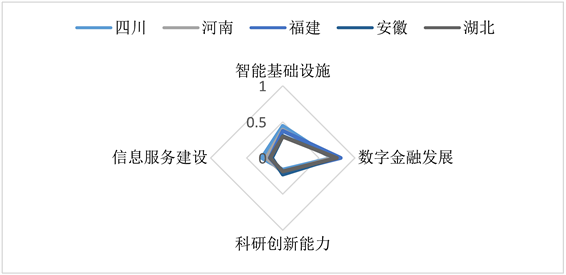
Figure 13. Distribution diagram of secondary indicators for medium-level echelon
图13. 中等水平梯队二级指标分布图
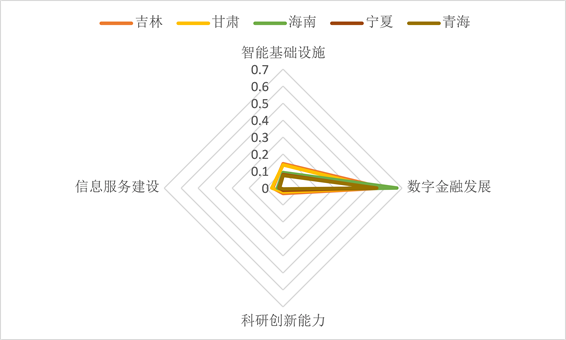
Figure 14. Distribution diagram of secondary indicators for low-level echelon
图14. 低水平梯队二级指标分布图
在高中低三个层次中,本文以2020年为例,分别以4个维度:智能基础设施(A),数字金融发展(B),科研创新能力(C),信息服务建设(D),评价不同层次的地区数字经济发展水平。
根据三个梯队二级指标分布绘制雷达图,如图12、图13和图14所示。对比发现:数字经济发展水平较高省份在四个维度均有良好表现,没有明显短板,具有全方位驱动的特征。中等发展水平省份在智能基础设施方面具有较好表现,而在科研创新能力和信息服务建设方面较弱,尤其是前者上存在巨大的短板。低发展水平的省份在四个维度处于落后,但在数字金融方面有较好表现,这与全国范围的数字金融使用深度加深,移动支付水平提高等有关。
6. 政策建议
(一) 政策建议
1、全力推进“东数西算”工程,协同联动东西部
全国大数据中心体系总体布局一体化设计的完成,标志着“东数西算”工程的全面启动。首先,政府部门要同推动“西电东送”、“西气东输”和“南水北调”工程一样,充分发挥我国体制优势,优化资源配置,促进东西部的协同联动,提升资源使用效率。其次,相关部门要根据算力需求和业务对网络的要求,将数据中心自东向西梯度布局、统筹发展,比如人工智能推理、远程医疗等可布局于粤港澳大湾区、京津冀和长三角等算力枢纽,而离线分析、存储备份可优先向西部转移。同时要大力打造一批“东数西算”示范线路,加快完善数据中心产业生态体系,着力于提升8个枢纽的影响力和集聚力。
2、加快形成数字经济省域协调发展空间布局
相比内陆省份如青海、贵州和宁夏等省份,广东、浙江和江苏等沿海地区省份在智能基础设施、数字金融发展、科研创新能力和信息服务建设四个维度上全方位领先,显著优势。从习近平总书记坚持全国一盘棋的角度出发,发展水平较高的沿海地区应该对中西部内陆地区开展如“一对一”、“点对点”的帮扶,缓解地区间发展的不平衡。党的十九大提出,我国数字经济应从短平快的发展道路转换为高质量发展,中西部地区应借助这一东风,在十四五期间实现阶段性跳跃。
3、全面提高智能基础设施建设水平
各地区应积极打造互联网智能基础设施,加快建立大数据中心,推动数据的智能化和绿色化发展,构建高效数据处理系统,提速5G网络的部署工作,推进各类感知设施布局,真正形成共建共享的城市物联网。全面促进新技术在传统设施上的使用,加快交通、能源等基建的数字化改造,推进能源互联网建设,响应国家双碳政策,实现公共服务一体化、智慧化。最后,科学规划创新基础设施体系,推动人工智能等高新技术的有机融合,以智能制造、信息安全为核心领域,更快推进产业创新平台的建立,建设智能车间和数字化工厂,提高相关领域的交通设施车联网的改造速度,促进核心系统能力的培养。
4、大力发展数字金融和普惠金融,弥合数字鸿沟
当前仍存在金融服务的数字鸿沟,对包容性发展形成了障碍。中国的互联网普及率在2020年年底已达到73%,但仍存在较大地区差异。第一,这抑制了金融服务的正常获取,尤其是低收入群众等特殊群体理解能力差,使用数字经济的能力偏低;第二,一些小微企业的金融服务获得感受挫,因为它们的数字转型能力较弱,数据开发投入较少,可使用的数字化工具有限,无法储存足量数字化资源;第三,让相关机构获能够滥用金融交易支撑数据,利用算法欺骗消费者,使得金融数据存在安全隐患。相关部门应深入研究,积极促进平台经济健康发展,推动腾讯、京东等大型互联网金融平台不断为人民的生活提供高质量服务。
5、不断提高科研创新能力,以科技兴国
实践证明一个国家必须把握核心技术,才能从根本上保障国家安全。“卡脖子”技术对我们来说,是挑战也是机遇。国家应继续大力推崇自主创新,强化战略科技力量,提高创新效能;明确企业、高校和科研院所的创新主体定位,激发创新活力。