1. 绪论
随着互联网计算机技术的飞速发展,人们逐步陷入了一个“数据丰富,处理苦难”的尴尬地步。如何从海量数据中挖掘出有用的信息,并进行分类分析得出想要的信息已经越来越成为专家学者关注的课题。因此,基于机器学习的数据挖掘方法已经成为当前研究的热门话题。常用的几种方法有KNN算法、决策树、支持向量机,它们大量应用到生活、教育、医疗等各个方面。医疗资源短缺是现阶段医疗领域中突出的问题,疾病被正确诊断的有效率是人们所关心的问题。但是一名合格的医生培养需要大量的时间、金钱的投入,因此,利用机器诊断疾病成为专家学者研究的方向。目前,已经有很多疾病,例如冠心病、癌症、哮喘等,有了系统的研究,但是基于胎心宫缩监(cardiotocography, CTG)的研究相对落后。
Haritopoulos M等 [1] 提出了处理CTG信号最常见的步骤,并研究了过去十年的胎心率分析的特征提取方法,一些特征分类方法的也被提出,以供进一步的研究。Chamidah N [2] 通过使用K-Means方法对UCI中的CTG数据进行选择,将从原始特征中提取出来的7个抽象特征利用SVM模型进行分类,达到了较高的准确率。聂磊 [3] 利用机器学习的若干办法研究了胎儿窘迫临床数据,从数据中提取计算机能够识别的病理特征,针对病理特征建立模型并进行准确分类,得到了比较好的分类效果。刘志康 [4] 将胎儿监护的CTG信号数字化,针对不同强度的宫缩信号进行自动分类,在CTG胎儿智能监护方面提供了理论支持和技术基础。
本文所感兴趣的是使用邻近算法、决策树、支持向量机三种分类方法对胎心宫缩监数据(CTG)分别进行分类分析。
2. 相关理论
2.1. 邻近分类
邻近分类是一种非参数学习的方法,它是把具有相似属性的事物划分为一类,即“物以类聚,人以群分”,其主要步骤在于计算距离以及k的数值确定。这里的距离不仅仅包含传统的距离,还包含两个案例之间的相似性。常用的距离为欧氏距离:
其中,p、q是两个案例,
是案例p、q的第n个特征的值。k值的选取往往在3~10之间。一种做法是设置k2等于训练集中的事件数目,另一种做法是各种测试数据测试多个k值,选择一个分类效果最好的k值。
2.2. 决策树分类
决策树是基于特征的值把数据分解成很多较小的子集,这些子集的元素都是相似的,因此,决策树的核心思想就是分而治之。决策树的难点在于如何进行分割,熵常被用来度量纯度,以此来确定分割的标准,用信息增益来决定根据那个特征进行分割,信息增益越高,表明分割以后的分区越平衡。
2.3. 支持向量机
20世纪90年代初,Vapnik等人 [5] 基于统计学习理论提出了一种新的机器学习方法——支持向量机。为了确保学习机器的实际风险达到最小,以结构风险最小化准则为理论基础,合适的函数子集和判别函数可以用该准则选择,从而保证了得到误差很小的分类器。核函数的确定是支持向量机的核心,对于不同的支持向量,它们满足Mercer条件的核函数也不同,不同类型的算法就由此产生。
3. 实例分析
本文选择胎心宫缩监数据集作为数据源 [6],它来源于Frank and Asuncion (2010)。该数据集包含了2126个观测值以及23个变量,其中,前20个变量为定量变量,后3个变量分类变量;前22个变量为自变量,后一个变量为因变量,它是一个分类变量,也就是本文所感兴趣的变量,将它的三个水平数值化:1代表正常,2代表疑似,3代表病态,它们分别有1655,295,176个观测数据。本文将使用精确度、十折交叉验证的平均误差率和Kappa统计量的值来评估分类方法的好坏。
3.1. 邻近分类法
在读取数据之后,将 NSP变量重新编码为normal,uncertain,disease。初步分析原始数据,发现有77.8%的胎儿是正常的,有13.9%的胎儿疑似不正常,只有8.3%的胎儿被认为是病态的。
将这些特征进行min-max标准化后,选取数据的80%作为数据的训练集,20%的数据作为测试集,也即是有1701个训练的样本,425个测试的数据。本文选取的k的值为6,并利用测试数据集合进行预测,得到的结果汇入一个交叉表中,见下图1:
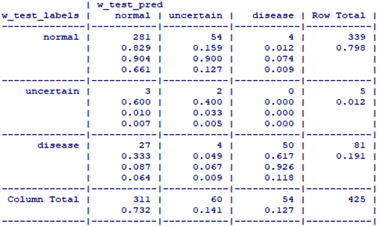
Figure 1. The neighbor classification result
图1. 邻近分类结果图
在图1中,第一列代表原始测试集数据之中每个胎儿的分类情况,第一行代表预测测试集的每个胎儿的分类情况。有4个胎儿是正常的,但是被判定为病态,有27个是病态的被判定为正常的,这个方向上的错误可能会产生极其严重的后果。主对角线代表预测结果与实际结果一致的情况,有281个被判定为正常,2个被判定为疑似,50个被判定为病态,正确的判断率为82.9%。通过十折交叉验证后,得到其平均误差率为0.3791054。此外,计算其Kappa统计量的值为:
3.2. 决策树分类
同样的,这里选取80%的数据作为训练集,20%的数据作为测试集,树的大小为13,如图2。
图2仅仅显示了决策树的前几个分支,括号中的数字表示符合该决策准则的案例数量以及根据该决策不正确分类的案例的数量。如果CLASS大于7的条件下,如果小于等于9,那么就判断为患病,(95/1)表示有95个案例符合该决策树的条件,有一个被错误地归类为不患病;如果大于9,则判定为疑似,且有197个案例符合此条件,只有一个被错误判断。
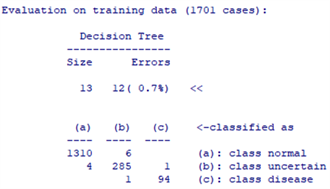
Figure 3. Confusion matrix of decision tree
图3. 决策树的混淆矩阵
从图3中得出,模型对1701个训练子集分类,有12个被错误分类,错误率为0.7%。共有6个正常地被错误判定为疑似,4个疑似被错误判定为正常,1个疑似被错误判定为患病,1个患病地被错误判定为疑似。利用训练集的数据模型来预测测试集的分类结果,如图4所示。
在425个测试结果中,我们的模型正确的预测了328个为正常,4个为疑似,81个为病态,模型的准确率为97.18%。该模型错误地把11个正常为判定为疑似、1个疑似的判定为正常,但是这并没有产生十分严重地错误。总的来说,该模型比较好的对数据进行了分类。通过十折交叉验证后,得到其平均误差率为0.0146011。此外,计算其Kappa统计量的值为
3.3. SVM分类法
这里的训练集和测试集与决策树的训练集和测试集一样,使用的核函数为高斯径向核函数。将得到的测试数据的预测值与其真实值进行对比,得到如下图5结果:
从图5看出,425个预测结果中,有338个被正确判定为正常,4个被正确判定为疑似,有48个被正确判定为病态,正确判定率为91.29%。有33个病态的被判定为正常的,有1个疑似的被判定为正常,1个正常的被判定为疑似。通过十折交叉验证后,得到其平均误差率为0.01552904。计算其Kappa统计量的值为
4. 结论
通过以上三种方法对CGT数据的研究表明,我们可以得到下表1:

Table 1. The evaluation of the three classification methods
表1. 三个分类方法的好坏评判标准
从表1可以看出,准确率最高的是决策树分类的方法,为97.18%,其次是支持向量机,准确率为91.29%,最低的是邻近分类法,仅为82.9%。经过十折交叉验证后,得到邻近算法的平均误差率为0.3791,决策树的为0.0141,支持向量机的为0.0155。它们的Kappa统计量的值分别为:0.842,0.919,0.680。因此总的来说,决策树的准确率最高,平均误差率最低,kappa统计量的值表现出很好的一致性,在实际中我们应推荐使用决策树的分类方法。
NOTES
*通讯作者。