1. 研究背景
大数据时代的繁荣,使得数据成为重要的战略资源,如何运用海量数据提升燃气企业精细化管理、降本增效成为急需解决的关键问题。在工业用气中,对于一些负荷量大的工业用户 [1],当用户行为发生较大变化或计量设备损坏时,用户标况瞬时流量就会出现较大波动。燃气公司以标况总量计费,标况瞬时流量和累计流量呈现线性相关。因此标况瞬时流量异常意味着流量计可能发生故障,流量计是燃气公司结算费用的重要仪器,因为缺乏智能化管理,通常总是遭受损失很久后燃气公司才后知后觉,因此如何对燃气数据分析对于推动燃气公司逐步迈向智能化监测具有重要意义 [2] [3]。
目前对于异常值检测算法已经有了较为成熟的研究,文献 [4] 采用GPR模型融合距离相关系数的方法检测卫星数据流;文献 [5] 采用了基于层次聚类的异常检测算法对数据降维,发现对降维后的数据进行异常检测能保持90%以上的精准率。除了基于统计原理和聚类原理的异常检测方法 [4] [5] [6] [7],基于机器学习的异常点检测方法也有丰富的进展 [8] [9] [10] [11] [12]。文献 [8] 在网络运行环境下构造了数据的特征,并搭建了三种基于神经网络和基于语义与空间等网络异常行为检测研究模型。文献 [10] 采用了基于机器学习的无线传感器网络异常值检测算法,对用聚类算法处理后的数据生成支持向量机并采用鲸鱼优化算法进行优化,提升了模型的准确率和模型的泛化性。在与燃气领域相似的电力负荷异常检测方面,文献 [13] 提出了基于变分自编码器的负荷检测方法。文献 [14] 通过基于距离的聚类检测算法确定最佳聚类数目,结合K-means设计了一套用户异常用电嫌疑等级报警算法。文献 [15] 通过小波变换,过滤掉原始数据的噪音,使异常点在高通滤波器的应用下更为突出,更容易被检测出来。文献 [16] 通过LOF离群点算法建立用电异常评价指标,将异常用电检测方法推广到反窃电系统中。
本文基于网格寻优的密度聚类方法结合分段聚合近似表示方法对工业燃气用户的标况流量数据进行异常检测。通过对原始数据(标况状态下由流量计记录的瞬时负荷数据)分段聚合绘制日负荷曲线,利用K近邻距离图综合具体条件遍历区间筛选出最优参数,在包含噪声的数据集中通过寻找工业燃气数据的内在分部规律和聚类效果的变化来识别异常曲线,文章的技术路线如图1:
2. 异常负荷曲线检测算法
2.1. 分段聚合近似算法
分段聚合近似表示方法(Piecewise Aggregate Approximation, PAA) [17] 是按某种规则把序列分段表示的方法,利用序列分段后的平均值映射原始信息从而达到降维的目的。降维后的数据保留了原始序列的主要信息。给定时间序列
,将n个数据做m等距分段,第
段的计算方法为:
(1)
,
,N为正整数。
2.2. 密度聚类算法
密度聚类(Density-Based Spatial Clustering of Applications with Noise, DBSCAN)是基于一组邻域参数
来描述样本分布紧密程度的方法 [18] [19]。
定义 [20] [21]:给定n维向量空间记
,将X分为m组.
,
,
,每个组有
个元素。且
,
。
1)
-邻域(Eps):对
,其
-邻域包含
中与
的距离不大于
的所有样本。
(2)
2) MinPts:
-邻域内样本个数最小值。
3) 核心对象:若
的
-邻域至少包含MinPts个样本
,则
为一个核心对象。
4) 密度直达:若
,且
是核心对象,则称
由
密度直达。
5) 密度可达:对
与
,若存在样本序列
,其中
,
,
均为核心对象且
从
密度直达,则称
由
密度可达,且密度可达关系满足传递性。
6) 密度相连:对与
,若存在
使得
与
均有
密度可达,则称
与
密度相连。
密度聚类的簇里面可以有多个核心对象。如果只有一个核心对象,则簇里面所有样本都应在这个核心对象的
-邻域里;这些核心对象
-邻域里的所有样本的集合组成一个DBSCAN簇。和传统的K-means算法相比,DBSCAN最大的不同就是不需要输入类别数k,当然它最大的优势是可以发现任意形状的聚类簇,同时它在聚类的同时还可以找出异常点。对于一个数据点若新数据是一个核心对象,且不属于任何一个已存在的簇内和此数据的密度可达点中没有已存在簇的核心点,则组成一个新的簇;如果在领域内没有核心点,且邻域内最小样本个数小于阈值,则将此数据标记为异常点 [22] [23] [24]。
异常检测的准确率计算公式为:
(3)
其中R:准确率;f:未检测出的样本与检测错误的样本之和,N:总样本。
2.3. 参数寻优
DBSCAN算法不需要提前给定簇类别只需要计算eps参数和MinPts,这两个参数在通过DBSCAN密度聚类算法创建正确的簇中起着重要的作用。在以往的研究中这两个参数大都根据经验或比较试错得出有很大的主观性。由于文中采用的是曲线聚类,计算复杂度随之提升。因此提出以下改进方案:结合K近邻曲线图和网格搜索法(Grid Search)遍历区间内的所有参数,并将各个参数的可能取值进行排列组合,综合燃气日负荷曲线原始曲线筛选最佳参数组合,参数确定的主要流程如表1:

Table 1. Parameter optimization algorithm based on K-nearest neighbor distance graph and grid search method
表1. 基于K-近邻距离图和网格搜索的参数寻优算法
3. 实验分析
3.1. 异常检测
以广州某陶瓷工厂燃气标况流量数据为例进行实验分析。实验数据共3720个,大约10分钟左右采集一次。由于数据的采集时间是不规律的对数据做如下预处理:首先把时间间隔转化为10分钟一次,缺失的以相邻数据填补。根据工业原理,工厂在一小时的用气量是相对稳定的,经过24段聚合后的流量曲线如图2所示。绿色线段是分段聚合近似算法处理后的结果相比于处理之前,处理后的曲线降低了曲线平滑度使得段内特征减弱,段与段之间的差异则更加凸显。分段聚合近似算法实现了日负荷曲线分段降维,同时增加权重在后续的相似性分析中使得相似度精度更高。
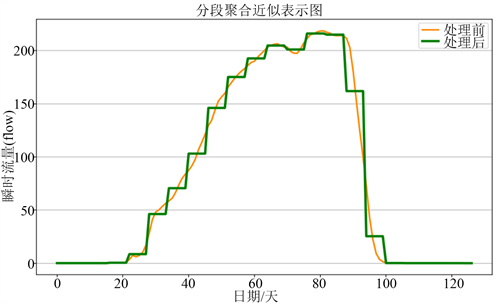
Figure 2. Piecewise aggregate approximation representation graph
图2. 分段聚合近似表示图
通过K-近邻曲线图和网格搜索法来确定密度聚类的参数,图3为日负荷曲线的近邻距离图可以看出数据集于第5条曲线开始出现突变。因此可以初步得出MinPts为5,然后根据拐点处的y值可以得出
为88。再根据天然气使用规律可知日负荷曲线在纵向和横向上表现出聚类特性,对于一个工业用户来讲,其每天的用气量应与之前的用气量具有相似性,且由于实际中工厂在休息日和工作日的负荷曲线具有差异性,因此排除异常天的情况下聚点应至少为两类,且异常点应属于少数点,利用网格搜索法寻优的结果如表2所示,从中自动筛选出的红线框住部分为合适的参数,可以观察到异常值n_clusters处于突变中,stats样本聚类数分部较平均。因此综合考虑选择的参数为
。
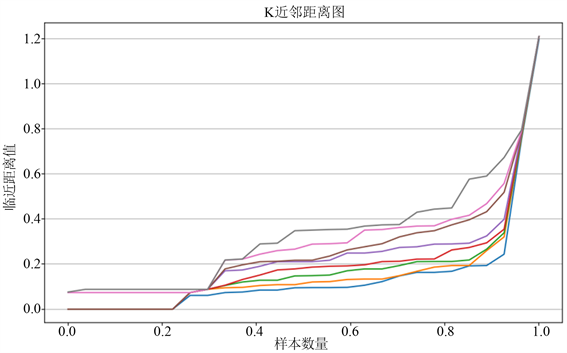
Figure 3. K-nearest neighbor distance graph
图3. K-近邻距离曲线图
Table 2. Grid search method parameter optimization
表2. 网格搜索法参数寻优
对该工厂日负荷曲线做密度聚类(DBSCAN)的聚类结果如下图4所示,可以发现:日用气流量曲线分为两类,一类是橙色曲线描述了工厂正常运行时的日流量走势,另一类是绿色曲线描述了工厂停工时的少量用气曲线,剩余的紫色曲线为异常曲线。再由每日用气曲线制作的标签表3中可以看出异常曲线对应的日期为8月8号和8月13号,而实际中陶瓷工厂开始运转后用气量应该是平稳上升一段时间后经过中午短暂的下降后再回升再下降为零的,异常天的负荷曲线呈现出大幅的波动,因此不符合工业用气机理,具体的异常原因还需结合工厂实际情况进行分析。另外26为正常天,正常天又分为两种用气特征曲线,正常工业用气和停业小幅用气。由日负荷曲线聚类结果可以看出该工厂的用气量大致呈图中橙色曲线和绿色曲线两种类型,其中出现了2次异常曲线,异常曲线和正常曲线的对比如图5所示。
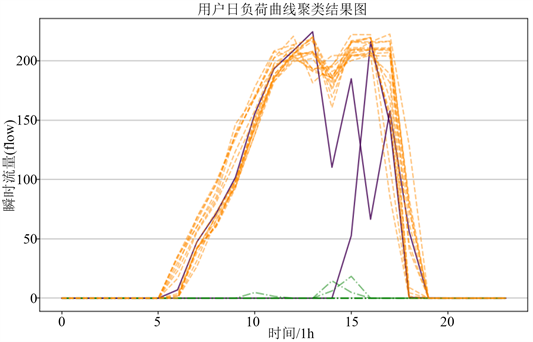
Figure 4. Daily load curve clustering result graph
图4. 日负荷曲线聚类结果图
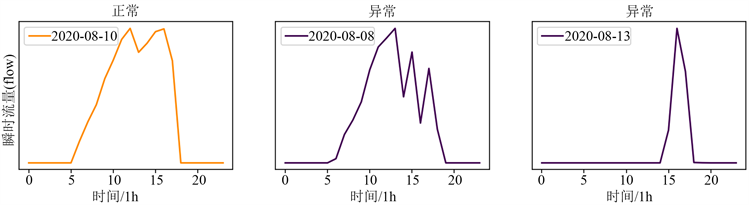
Figure 5. Comparison chart of daily load curve
图5. 日负荷曲线对比图
Table 3. Daily load curve classification table
表3. 日负荷曲线分类表
对聚类结果做一些转换可以得到密度聚类的以小时为单位的结果如下图6所示,黄色和绿色分别为两类不同的簇,紫色为异常点,从图中可以看出小时图更清晰的反映了该工厂运营时出现的异常用气行为。
通过对陶瓷工厂进行研究发现:陶瓷产品必须要达到规定的温度状态下才能烧制成功,否则做出来的就是残次品;因此工厂处于工作状态时对温度有着严格的把控,而该工厂在8月8日和8月13日的下午使用燃气时流量数据不足以产生达到制成产品所需的最佳温度,但根据回访工厂当天生产的产品却是合格的,因此我们判断该工厂存在异常用气行为。
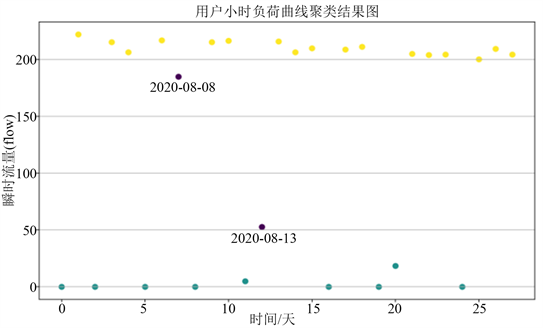
Figure 6. Clustering results of hourly load curve
图6. 小时负荷曲线聚类结果图
3.2. 多用户大规模比较分析
为了验证算法的有效性,选取了325家燃气工业用户(2020.1.1~2021.4.30)进行大规模测试,其中随机选取四家工业用户的日负荷数据聚类结果如下图7所示,相关参数如表4所示。
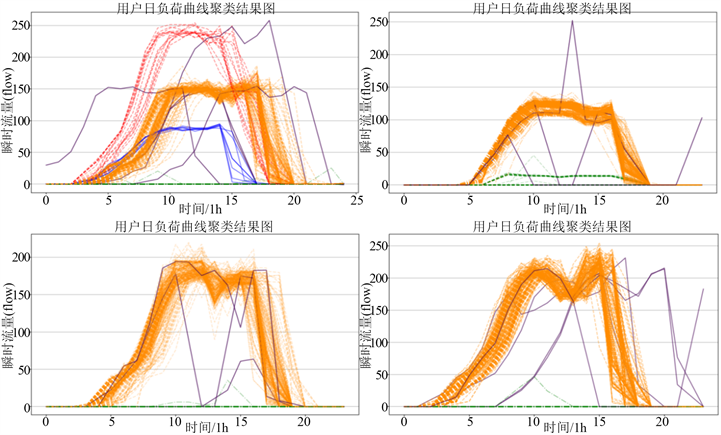
Figure 7. Clustering results of multi-user load curves
图7. 多用户负荷曲线聚类结果图
对325家工业用气用户进行测试,而且异常检测准确率达到了90%以上,其中四个案例用户的密度聚类结果如上图7所示,其中红色、橙色、绿色、蓝色曲线为正常用气行为,紫色曲线为异常用气行为;密度聚类的参数通过改进的K-近邻距离图和网格搜索法计算如表4中
所示,用户A主要分为3簇,3种主要用气行为,2种稳定的正常用气行为,1种少量用气或几乎不用气行为,簇外的紫色线段为检测出的异常用气行为,检测准确率为98.06%;用户B主要分为2簇,检测出的异常样本有3个,准确率为97.56%;用户C主要分为2簇,检测出的异常样本为3个,异常样本检测准确率为98.93%;用户D主要分为2簇,检测出的异常样本为5个,异常样本检测准确率为99.78%。
4. 结论
本文通过分析用户的日负荷曲线聚类效果的变化来识别异常曲线。对识别燃气用户用气异常提供了一些思路,且在包含噪声的异常检测问题中DBSCAN算法具有较好的优势,而且通过K-近邻距离图和网格搜索法确定DBSCAN的各项参数提高了算法的可信度,得到的参数更加精确。提升了模型的泛化性。为识别燃气用户用气异常提供了一些思路。
本文的改进算法在325家用户进行验证时发现,基于改进密度聚类算法的异常检测准确率在90%以上,说明利用密度算法进行异常检测具有一定的普适性。对智能化燃气行业异常检测有一些参考性,尤其是对于规律用户模型的训练效果和测试效果良好。图7展示的四个陶瓷工业用户的用气行为大致分为3类:大规模用气行为(日用气量超过1500 m3)、中等用气行为以及停业小幅用气或几乎不用气行为。除此之外,通过对325家陶瓷工业用户的异常曲线做分析发现,日负荷曲线存在一定的规律,相对于单一的用气负荷点来说一维曲线更能体现工业用户的用气特征。同时对于文中聚类结果的第三类停业小幅用气行为,我们也不应该忽视,因为天然气是一种危险气体,如果发生泄露极易导致火灾甚至是爆炸等危险情况发生。
随着数字化产业的发展,燃气公司走向智能化转型是必然趋势,因此对于燃气行业的流量异常的检测有待更多的研究,未来会考虑使用图像识别处理技术把异常曲线转化为图片,通过大规模训练学习异常图片,对正常用气图片和异常用气图片做二分类,来实现异常用气行为检测。
基金项目
国家自然科学基金项目(11861020)、贵州省高层次留学人才创新创业择优资助重点项目([2018]03)、贵州省科技计划项目(ZK[2021]009)和贵州省青年科技人才成长项目([2018]121)。
NOTES
*通讯作者。