1. 第1章绪论
1.1. 研究背景与意义
股票是公司在筹集资金时候的提供给出资人的一种证券,是投资者持有公司股份的证明。中国股市自1989年开始运行,经过三十多年的发展,现在已经有了上海、北京、深圳、香港、台湾五家证券交易所,也形成了较为完善的体系。股票如今在我国的地位越来越高,已经成为了人们进行投资理财的主要方式之一。
对于金融市场来说,收益和风险是成正相关关系的。股票高收益的同时也意味着较高的风险。在中国股票的市场上,个体散户仍然是主力军。由于散户很多不具备专业的知识储备和相关知识背景,使得他们的收益非常不稳定。因此,如何规避市场的高风险,同时为投资者带来收益,受到学者的广泛关注。
现如今,对于股票的研究已经有了一定的进展,但是由于股票的价格收到很多因素的影响,如公司的状况、投资者的情绪、经济发展状况、公共事件等都会影响到股票的未来走向,因此对于股票的预测研究仍然是一个具有挑战性的工作。
1.2. 文献综述
目前针对股票价格预测的相关研究已经有了大量的文献,不同学者利用不同的方法都对股票进行了相关的研究。主要大致可以分为:
利用传统逻辑回归预测方法进行分析预测,如逻辑回归、线性回归、GARCH等等。Huang (2020)运用Logistic回归,通过筛选指标构建了股票预测模型,利用文本挖掘的技术将股票的非结构化数据量化,后基于情绪得分提出了Logistic回归的改进方法,为股票价格的预测精度提供了新的方向 [1] 。张少萍(2018)通过Garch模型对招商银行每日收盘价格进行技术分析,对其进行了预测,最后得到了较为理想的预测效果 [2] 。Zevallos (2019)通过分位数回归方法预测秘鲁股市的风险,得到了较为良好的效果 [3] 。
股票作为时间序列的数据,国内外也有很多学者利用ARIMA模型对股票价格进行预测。Chi (2018)通过对短期股票的分析预测,运用ARIMA(1,2,2)模型,为投资者提供了可靠的信息,在一定程度上为投资者的决策提供了相关的参考 [4] 。黄莉霞(2020)通过对中国平安的分析,有别于以往,从市盈率出发,构建了ARIMA(0,1,1)模型,对中国平安的股票进行5日内的市盈率预测,结果显示误差只在5%左右,使股票的市盈率有了很好的预测模范 [5] 。赵庆国(2020)则说明时序权重均值模型是通过利用时间序列的相关知识,对不同时期的价格赋予不同的权重,以此减轻了滞后性,更好地反映出了价格走向 [6] 。张颖超(2019)通过对上证指数的分析预测,准确的计算了预测误差,最后选定了ARIMA(4,1,4)模型,证明了该模型可以预测短期数据 [7] 。
除此之外,很多学者在股票价格预测模型中引入了灰色关联、神经网络等其他方法,以此来提高模型预测的精度和准度。王振兴(2011)通过建立BP-RBF双神经网络模型,将组合模型和单一模型进行对比,对我国的股市进行分析预测,提高了预测的准确率 [8] 。杨琦等(2016)构建了基于ARMA-GARCH的组合模型,用GARCH去除了ARMA模型产生的异方差,达到了较好的短期价格预测能力,并且验证了ARMA-GARCH模型的可行性 [9] 。姜乐(2015)分别用传统的时间序列模型和BP神经网络模型对股票进行了价格预测,发现这两种方法可以预测股票价格的变化趋势,然后构建了ARMA-BP模型提高了预测的精度 [10] 。
综合以上文献,目前学者对于股票价格预测有多种方法,但是选取的数据往往是移动均线数据,而非每天的收盘价。由于移动均线数据具有一定的滞后效应,因此会对模型预测的精度产生影响。且部分学者预测对象是个股而非整体股市,由于股票之间存在的差异性较大,因此预测个体股票的指导效果并不强。本文选取了深股指数2019年12月30日至2022年11月18日每日的收盘指数为样本,利用R语言构建ARIMA模型对对股市未来走向进行了预测,并给出指导意见。
2. 第2章理论基础
2.1. 平稳性时间序列
2.1.1. 平稳时间序列
平稳性时间序列根据限制性条件的严格程度的不同,分为严平稳时间序列和宽平稳时间序列两种定义。严平稳是限制条件比较苛刻的一种,将序列所有的统计性质都不随着时间的推移而变化的序列定义为平稳序列;宽平稳则认为序列的统计性质主要由它的低阶矩决定,只要保证序列的低阶矩平稳,就能保证序列的主要性质近似平稳。在实际应用中,如果不特别注明为严平稳,那么就泛指宽平稳,本文所使用的序列平稳也为宽平稳。宽平稳时间序列{Xt}满足以下三个条件:
任取
,有
;
任取
,有
,
为常数;
任取
,且
,有
。
2.1.2. 平稳性检验
序列的平稳性检验有两种方法:一种是根据时序图和自相关图做出判断的图检验法,另一种是构造检验统计量进行假设检验的方法。图检验法具有一定的主观色彩,而统计检验方法能在一定的可靠性水平之下对序列的平稳性做出判别,使检验更加可信。
平稳性统计检验方法的理论思想:如果序列是平稳的,那么该序列的所以特征根都在单位圆内,反之为非平稳序列。因此,平稳性统计检验方法又叫作单位根检验。单位根检验有诸多方法,本文使用的是较为经典是ADF检验。ADF检验的假设条件如下:
原假设H0:序列存在单位根,为非平稳序列;
备择假设H1:序列不存在单位根,为平稳序列;
ADF检验统计量:
式子中,
为
的样本标准差。当
统计量小于α分位点,或者
统计量的P值小于显著性水平α时,可认为序列平稳,反之不平稳。
2.2. 非平稳时间序列
ARIMA模型又称为差分自回归移动平均模型。ARIMA(p,d,q)模型中,AR是“自回归”,p为自回归项数;MA为“移动平均”,q为移动平均项数,d为使之成为平稳序列所做的差分阶数。
果一个时间序列
的d次差分
是一个平稳ARMA的过程,我们称
为自回归滑动求和平均模型,如果
服从ARMA(p,q)模型,则称
是ARIMA(p,d,q)过程。
一般的表达方式为:
其中,
为模型系数,
,
,当d = 1时,
,则有
用观测序列表示为:
上式称为模型的差分形式,我们假设模型自t = −m开始,得到ARIMA(p,1,q)表达式为:
通过两次求和处理ARIMA(p,2,q)可以得到:
实际中,d通常取1或者2。
2.3. 纯随机性检验
2.3.1. 纯随机序列
纯随机序列,又叫白噪声序列,白噪声序列的各项序列值之间没有任何相关关系,在进行完全无序的随机波动,具有以下性质:
一旦某个序列表现出纯随机性质,那么该随机事件就不包括任何有用信息值得提取,此时对该时间序列的分析就该终止。
2.3.2. 纯随机检验
纯随机性检验也称白噪声检验,是检验序列是否为纯随机序列的一种方法。由于序列之间的变异性是绝对的,相关性是偶然的,因此,序列纯随机性检验的假设条件如下:
原假设H0:延迟期数小于或者等于m期的序列之间相互独立;
备择假设H1:延迟期数小于或者等于m期的序列之间有相关性。
LB(Ljung-Box)统计量:
式中,n为序列观察期数,m为指定延迟期数,且LB统计量近似服从自由度为m的卡方分布。
2.4. 模型显著性检验
在拟合完模型之后需要对模型的显著性进行检验,检验模型是否有效,是否充分提取了时间序列的信息。对模型的检验实际上是对模型的残差序列来进行相关性的检验,一个好的拟合模型应该能够提取观察序列中几乎所有的样本相关信息。因此,模型显著性检验就可以转化为模型拟合残差项的白噪声检验,即对拟合残差构建LB统计量(理论和前文一致),进行检验。拟合残差序列为白噪声序列,就称模型显著性有效,若拟合残差序列为非白噪声序列,则拟合模型不够有效,需选择其他模型拟合。
2.5. 参数显著性检验
模型参数的显著性检验就是要检验模型中的每一个未知参数是否显著,是模型更精简。如果模型中的某个参数不显著非零,则该模型就应该剔除该自变量。模型参数的显著性检验的假设条件如下:
原假设H0:
;
备择假设H1:
;
检验统计量t为:
上式中,T服从自由度为n-m的t分布。当该检验统计量的P值小于显著性水平α时,拒绝原假设,认为该参数显著非零。反之,不能拒绝原假设,应该剔除不显著参数。
3. 第3章ARIMA模型的建立与预测
3.1. 数据来源
本文所选取的数据是 2019年12月30日~2022年11月18日的深证日指数,共700条数据,所有的数据均可以从官网得到。
3.2. 数据预处理
首先将数据录入到软件R中,画出该数据的时序图,对数据的平稳性进行初步的判断,结果如图1所示。从图中可以看出该序列具有明显的上升和下降趋势,初步判断该序列为非平稳的。但是由于图示带有主观倾向,因此对其进行ADF检验之后,显示为显著,则拒绝原假设,认为序列为非平稳的。
对该序列进行一阶差分,差分后的序列时序图见图2。显示差分后的序列已不在具有明显的趋势,因此认定该序列具有平稳的特征ADF结果显示(见表1)无截距无趋势、有截距无趋势、有截距有趋势三种情况的ADF的P值均小于显著性水平0.05,证明该序列经过差分后变的平稳。对该序列进行纯随机性检验,结果如表2所示,P值小于显著性水平α,因此拒绝原假设,该序列非白噪声,可以进行分析。
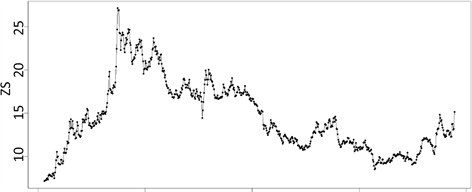
Figure 1. Shenzhen stock index time series chart
图1. 深股指数时序图
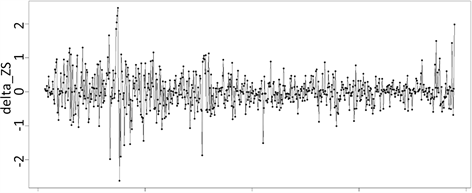
Figure 2. Differential timing chart of the Shenzhen stock index
图2. 深股指数差分后时序图

Table 1. The ADF value after the first-order differential of the Shenzhen stock index
表1. 深股指数一阶差分后ADF值
Table 2. Results of pure random test of the series after the difference of the Shenzhen stock index
表2. 深股指数差分后序列纯随机检验结果
3.3. 拟合模型
对序列进行差分之后的自相关性和偏自相关性如图3所示。自相关图一阶拖尾,偏自相关图3阶拖尾,可以拟合模型ARIMA(1,1,1)、ARIMA(0,1,1)、ARIMA(1,1,0)、ARIMA((1,3),1,0)。
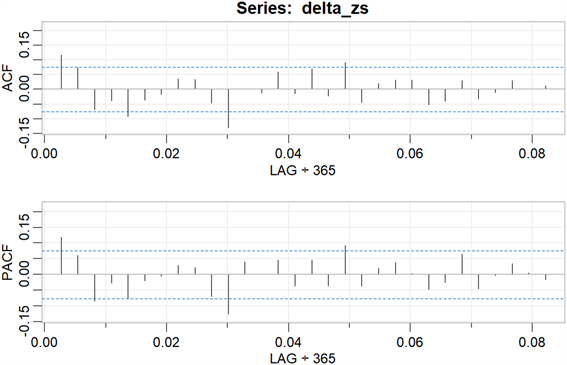
Figure 3. Autocorrelation plots and partial autocorrelation plots of the first-order difference of the Shenzhen stock index
图3. 深股指数的一阶差分的自相关图和偏自相关图
根据对以上自相关图和偏自相关图的特征,尝试对以下模型进行拟合,如表3所示。
Table 3. Model ordering and model selection
表3. 模型的定阶及模型选择
根据表3,用R拟合上述模型,得到拟合结果如表4所示。
Table 4. The results of the model fit
表4. 各模型拟合结果
由表3中模型的拟合结果,可以看到模型4的AIC值最小,因此在拟合的四个模型中,ARIMA((1,3),1,0)模型是最优的。为了避免模型定阶的主观性,再采用系统自动定阶的语句建立ARIMA模型,得到的模型为ARIMA(1,1,3)。ARIMA模型的AIC为991.84,为所有模型中最低,因此暂定为ARIMA(1,1,3)对模型进行显著性检验,结果如图4所示。
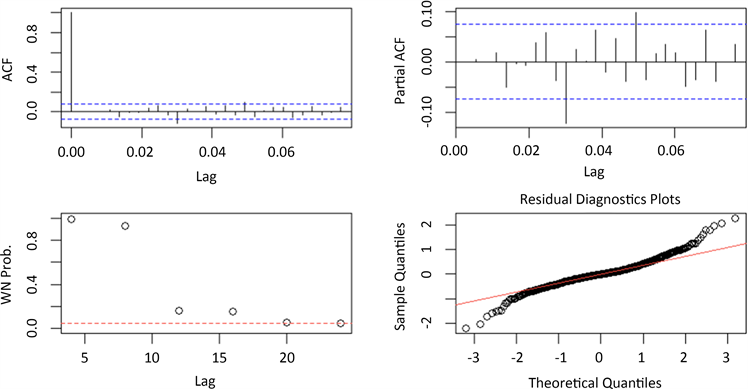
Figure 4. Test plot for significance of the DIF sequence fitting model
图4. dif序列拟合模型显著性检验图
对模型的参数显著性进行检验,结果如表5。
Table 5. Automatic ordering model results
表5. 自动定阶模型结果
模型为:
。
根据结果判断,参数的估计值大于它的两倍标准差则认为该模型可以有效。且ARIMA(1,1,3)的AIC效果最好,所以综合选择ARIMA(1,1,3)模型作为预测模型。
3.4. ARCH检验
通过对模型ARIMA(1,1,3)进行ARCH检验,结果如表6所示。
由图已知,由于p值均大于0.05,因此接受原假设,认为该模型不存在异方差。
3.5. 模型预测
对ARIMA(1,1,3)模型对后10天的深股指数进行预测,我们得到了结果如图5所示。

Figure 5. ARIMA (1,1,3) model prediction results
图5. ARIMA(1,1,3)模型预测结果
对预测数据可视化,得到图6。
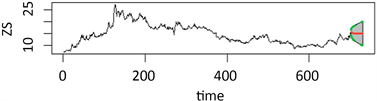
Figure 6. Shenzhen stock index forecast chart
图6. 深股指数预测图
Table 7. Comparison of prediction results
表7. 预测结果对比
由表7可知,该序列预测模型与原图一样具有稳定趋势,因此预测结果较好。
4. 结论
本文针对2019年12月到2022年11月的深股指数进行了预测分析。历史收盘指数为非平稳序列,通过一阶差分使其变为平稳序列。经过纯随机检验认为差分平稳序列非白噪声,有进一步建立模型的意义。接着通过观察一阶差分的自相关图和偏自相关图拟合了不同的模型,接着通过AIC最小原则确定了模型为ARIMA(1,1,3),拟合的模型通过了模型显著性检验和参数显著性检验。通过ARIMA(1,1,3)模型对未来十天的股市走向进行了预测和分析,结果符合以往的发展趋势,具有较强的参考意义。
参考文献